面向代價敏感的多標記不完備數據特征選擇算法
2019-01-24 09:01:26錢文彬王映龍吳兵龍
小型微型計算機系統 2018年12期
關鍵詞:特征
黃 琴,錢文彬,王映龍,吳兵龍
(江西農業大學 計算機與信息工程學院,南昌 330045)(江西省高等學校農業信息技術重點實驗室,南昌 330045)
1 引 言
由于在許多現實應用領域中,數據特征值的獲取通常是需要花費金錢、時間或其他資源作為代價成本,因此,將代價引入到數據挖掘和知識發現領域是顯得尤為必要.近年來,代價敏感學習問題作為數據挖掘領域的十大最具挑戰性問題之一[1],已受到越來越多研究者的關注,并被廣泛應用于醫學[2,3]、模式識別[4]、人臉識別[5-8]等各個研究領域.另外,特征選擇作為一種有效的數據降維方法[9-12],其目的是通過去除冗余特征,提高數據的質量,加快數據挖掘的速度.由于基于代價敏感的特征選擇算法是對特征選擇問題的擴展,從而基于代價敏感的特征選擇問題也受到了廣大研究者的關注.
近年來,基于代價敏感學習的單標記特征選擇研究取得了一些有意義的成果.Li等[13]在C4.5算法的基礎上提出了基于兩種自適應機制的代價敏感決策樹算法,一種是選擇自適應分割點機制來構建分類器,另一種機制即自適應刪除屬性機制,在選擇節點的過程中刪除冗余屬性.Zhao等[14]用啟發式算法選擇結點中的屬性,并構造了一種基于加權類分布批量刪除屬性機制的代價敏感決策樹算法.Zhao等[15]通過自適應鄰域粗糙集模型和快速回溯算法構造了一種基于自適應鄰域粒度的多級置信度的代價敏感特征選擇算法.Zhou等[16]提出基于均勻森林的代價敏感特征選擇算法,其在構建基礎決策樹過程中結合特征代價,從而生成低代價的特征子集.Fan等[17]通過測試代價構造自適應鄰域模型,從而實現對異構數據的屬性約簡.Zhao等[18]提出不同粒度下對應不同置信水平相關的數據精度,在覆蓋粗糙集模型下設計一種基于置信水平的代價敏感屬性選擇.Min等[19]提出了一種基于啟發式算法的最小化測試代價屬性約簡方法,并用四種度量方法來評價約簡算法的性能指標.Min等[20]提出基于測試代價約束問題的特征選擇算法,并用回溯法和啟發式算法進行分析.Liu等[21]通過優化F-measures函數,解決不平衡類問題,實現基于測試代價的特征選擇的算法.Dai等[22]在有效的索引能力的基礎上,提出了一種基于離散粒子群算法在測試代價敏感屬性約簡中的應用.
上述基于代價敏感的特征選擇算法研究主要面向單標記分類問題,但由于多標記高維數據廣泛存在于社會生活中[23-25].由此,在代價敏感學習下對多標記高維數據進行特征選擇值得進一步研究.同時,在現實生活應用存在大量的連續型、不完備性多標記高維數據.若需對連續型數據進行離散化處理以及缺失數據進行填充處理,將會影響數據計算的精度和增加數據計算的復雜性.
為此,本文提出了一種面向代價敏感的多標記不完備鄰域數據特征選擇算法,首先,算法在粗糙集模型上通過距離度量公式計算多標記不完備數據下的鄰域粒度,并根據多標記不完備數中特征的標準差和特征參數計算出合理的鄰域閾值,然后,通過均勻分布和正態分布為每個特征生成特征代價,在特征選擇過程中,根據歸一化后的正域和特征代價,提出了一種度量特征的重要性計算方法,并在特征核的基礎上,根據特征的重要性設計了啟發式的特征選擇算法;最后,在Mulan數據集上利用五個多標記分類器對考慮代價和不考慮代價的多標記特征選擇進行實驗比較和結果分析,實驗結果表明,本文算法解決了多標記連續型不完備數據在考慮代價情況下的特征選擇問題,可選擇出代價總和相對較低的特征子集,這為基于代價敏感的多標記不完備高維數據的分析提供了一種可借鑒的方法.
2 相關知識
在粒計算理論中,多標記數據可表示成一個多標記決策表MDT=(U,A∪D,V,f)中,U為對象集{x1,x2,…,xn},也稱為論域,A為條件特征集{a1,a2,…,am},D為多標記決策特征{l1,l2,…,lk},且A∩D=?.V為全特征集的值域,其中V=∪Va,a∈A∪D,Va表示特征a的值域,f是U×(A∪D)→V的信息函數.
定義1.當多標記決策表中存在缺失值時,記缺失值為“*”,即至少存在a∈A,x∈U,使得f(x,a)=*,此時數據稱為多標記不完備決策表IMDT=(U,A∪D,V,f).
定義2.給定多標記不完備決策表IMDT=(U,A∪D,V,f),對于任意特征子集B?A,定義特征子集B的容差關系T(B):
T(B)={(xi,xj)|(xi,xj)∈U×U,?at∈B?f(xi,at)=f(xj,at)∨f(xi,at)=*∨f(xj,at)=*}
定義3.對于N維的實數空間Ω中,Δ=RN×RN→R,?xi,xj∈RN,則稱Δ為RN上的一個度量,(Ω,Δ)為度量空間,Δ(xi,xj)為距離函數,表示元xi和xj之間的距離:
當p=1時,稱為曼哈頓距離.當p=2時,稱為歐氏距離.
3 問題描述
由于基于粗糙集的粒計算方法主要是處理名義型或符號型數據,但在現實應用領域中多標記數據的數值類型往往較復雜,當需處理數值型數據,須先對數據進行離散化,而對連續數據離散化將可能導致重要的信息丟失,從而影響分類算法的分類性能,為此需對連續型數值的多標記不完備數據開展特征選擇的研究.
定義4.[26]對于多標記不完備鄰域決策表IMDT=(U,A∪D,V,f),若有特征子集B?A,特征子集B上的鄰域粒度為
δB(xi)={x|x∈U,Δ(x,xi)≤δ}
其中,δ為鄰域的閾值大小.
下面以表1為例,若以曼哈頓距離作為鄰域度量標準,根據定義3計算各對象之間的鄰域粒度.
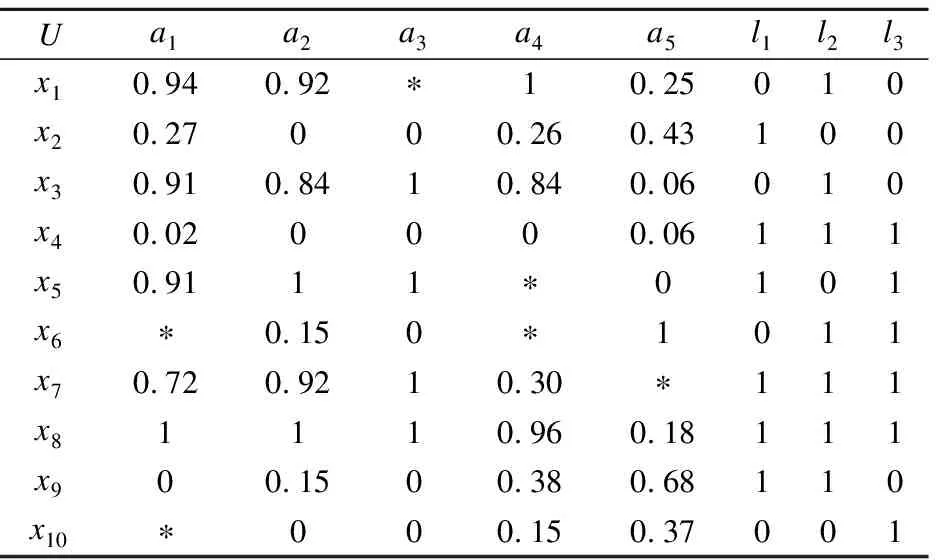
表1 多標記不完備鄰域決策表Table 1 Incomplete neighborhood multi-label decision table
利用曼哈頓距離度量公式,若特征a1、a2、a3、a4、a5的鄰域閾值分別為0.21、0.22、0.24、0.18、0.15.根據定義4計算包含所有特征的每個對象的鄰域粒度:
δA(x1)={x1,x8},δA(x2)={x2,x10},
δA(x3)={x3,x5,x8},δA(x4)={x4},
δA(x5)={x3,x5,x7,x8},δA(x6)={x6},
δA(x7)={x5,x7},δA(x8)={x1,x3,x5,x8},
δA(x9)={x9},δA(x10)={x2,x10}.
同理,可計算每個特征下每個對象的鄰域粒度.
定義5.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f)中,假設U中包含N個對象空間,對象xi對應的標記集合用yi來表示,N個對象實例所對應的向量用y=(y1,y2,…,yn)來表示.對象xi中所對應的第k個標記值用lk來表示,若lk=1,則表示yi集合中所對應的存在第lk個標記.
以表1為例,根據定義5可計算每個xi對象所對應的標記集合yi為:
y1={l2},y2={l1},y3={l2},y4={l1,l2,l3},y5={l1,l3},y6={l2,l3},y7={l1,l2,l3},y8={l1,l2,l3},y9={l1,l2},y10={l3}.
定義6.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f)中,對于?lk∈D,分別計算存在標記決策lk所對應的對象集合Dk:
Dk={[x]lk|x∈U}
以表1為例,根據定義6可計算存在標記決策lk所對應的對象集合Dk:
D1={x2,x4,x5,x7,x8,x9}
D2={x1,x3,x4,x6,x7,x8,x9}
D3={x4,x5,x6,x7,x8,x10}
定義7.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f)中,將擁有類別標記lk的對象集合用Dk表示,將對象xi所具有的標記集合用yi來表示.給定B?C,多標記不完備鄰域粗糙集的上下近似集為:
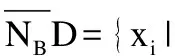
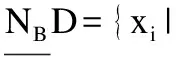
定義8.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f),有特征子集B?A,特征子集B上的正域為:
以表1為例,根據定義7和定義8可計算特征集A下的正域.具體的計算過程如下:
由于對象x1所對應的標記是l1,所以只需判斷δA(x1)?D2是否成立,若成立,則對象x1在正域范圍.因為δA(x1)={x1,x8},δA(x1)?D2,所以x1∈POSA(D).同理可得x4∈POSA(D),x6∈POSA(D), x9∈POSA(D).由此可知,POSA(D)={x1,x4,x6,x9}.
定義9.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f)中,多標記不完備鄰域決策表基于正區域核的定義為:
Core(A)={a|a∈A,POSA-{a}(D)≠POSA(D)}
以表1為例,根據定義9可計算出特征集A下的核,由計算可知:POSA-{a5}(D)≠POSA(D);由此可知,特征a5為核即Core(A)={a5}.
定義10.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f),對于特征子集B?A,特征子集B的特征依賴度為:
定義11.在多標記不完備鄰域決策表IMDT=(U,A∪D,V,f),特征子集B?A,若特征子集B是多標記不完備鄰域決策表的一個特征選擇結果,則B需滿足:
1)γB(D)=γA(D)
2)?at∈B,γB-{at}(D)<γB(D)
條件1)確保了特征子集B和全特征集A下的正域對象相同,條件2)確保了特征子集B中沒有冗余特征.
當前,由于在許多現實應用領域中,數據特征值的獲取通常是需要花費金錢、時間或其他資源作為代價成本,為此,基于代價敏感下多標記不完備鄰域數據的特征選擇問題值得進一步研究.
定義12.當多標記不完備鄰域決策表中的特征需要考慮代價時,則稱該決策表為基于代價敏感的多標記不完備鄰域決策表,其定義為:CIMDT=(U,A∪D,V,f,c),c:A→R+∪{0}是獨立測試代價函數,其中代價為非負數.
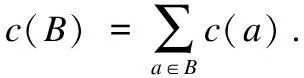
以表1為例,可給出多標記不完備鄰域決策表的測試代價向量,如表2所示.

表2 測試代價向量表Table 2 Vector of test cost table
性質1.基于代價敏感的多標記不完備鄰域決策表CIMDT=(U,A∪D,V,f,c),特征子集B?A,對于任意特征at,ai∈A-B,則基于測試代價的特征at的重要度為:
SIGcost(at,B,D)=POSB∪{at}(D)*-CostB∪{at}(D)*
為了方便性質1中對測試代價的特征at的重要度計算,先需對基于特征子集的正域個數和測試代價分別進行歸一化處理:
POSB∪{at}(D)*=
CostB∪{at}(D)*=
其中max(|POSB∪{ai}(D)|)、min(|POSB∪{ai}(D)|)分別為特征子集B中加入任意特征后的最大和最小正域個數,max(CostB∪{ai}(D))、min(CostB∪{ai}(D))分別為特征子集B中加入任意特征后所對應的最大代價和最小代價.
由定義9可知,特征a5為核,因此,先將a5加入到特征子集B中,結合表1和表2 中的數據計算出特征a1、a2、a3、a4基于測試代價的特征重要度分別為:
SIGcost(a1,B,D)=0.7;
SIGcost(a2,B,D)=0.85;
SIGcost(a3,B,D)=0.25;
SIGcost(a4,B,D)=-0.2;
由上面計算可知,特征a2的特征重要度最大,由此將a2加入到特征子集B中,通過計算可知,此時POSB(D)=POSA(D),則特征子集B={a2,a5},結合表2中給出的代價可知,此時特征子集B所需花費的測試代價是$18,而整個特征全集下的測試代價為$52.
4 特征選擇算法
根據上述分析可知,針對代價敏感的多標記不完備鄰域決策表的特征選擇算法,首先,采用均勻分布和正態分布兩種分布函數分別為每個特征生成特征代價,根據鄰域的閾值計算基于代價敏感的多標記不完備鄰域決策表中每個對象的鄰域粒度,在此基礎上,得到基于代價敏感的多標記不完備鄰域決策表的正域對象集合.然后,根據基于測試代價特征的重要度計算公式計算除特征核之外的每個條件特征的重要度,每次將特征重要度最大的特征加入當前的特征子集中并更新特征子集中正域對象集,直到特征子集下的正域對象集合等于全特征集下的正域對象集,由此設計了一種面向基于代價敏感多標記不完備鄰域決策表的特征選擇算法,算法描述如下:
輸入:基于代價敏感的多標記不完備鄰域決策表
輸出:特征子集Red.
Begin:
Step1.初始化Red←?;
Step2.對于?xi∈U,計算在特征集A下每個對象的鄰域粒度δA(xi);
Step3.對于?lk∈D,分別計算每個標記lk下的對象集合Dk;
Step4.若δA(xi)?Dk,則將對象xi存入正域POSA(D)←POSA(D)∪{xi};
Step5.對于?aj∈A,分別計算去除每個特征之后對象的正域集合POSA-{aj}(D),若POSA-{aj}(D)≠POSA(D),則將特征aj存入Red, 算法轉至Step7;
Step6.對于?aj∈A-Red,執行操作:
Step6.1.計算條件特征集Red∪aj下每個對象的鄰域粒度δRed∪aj(xi);
Step6.2.對于多標記?lk∈D且lk=1,若δRed∪aj(xi)?Dk,則POSRed∪aj(D)←POSRed∪aj(D)∪{xi};
Step6.3.若at=argmax{SIGCos t(aj,c,D)},則Red←Red∪{at},即計算加入條件特征aj的重要度SIGCos t(aj,c,D), 選擇重要度最大的條件特征at存入Red;
Step7.若POSRed(D)≠POSA(D),則算法轉至Step6,否則執行Step8;
Step8.輸出特征子集Red,算法結束;
End
算法的時間復雜度分析:
算法Step1初始化一個變量存放特征選擇后的特征子集,其時間復雜度為O(1);算法Step2在整個條件特征集下通過對象之間的比較計算得到每個對象的鄰域粒度,其時間復雜度為O(|C‖U|2);算法Step3分別計算每個標記決策下的對象集合,其時間復雜度為O(|C‖D|);算法Step4計算多標記不完備決策表的正域對象集,其時間復雜度為O(|U|2+|U‖D|);算法Step5計算特征核的時間復雜度為O(|C|);算法Step6對加入的新特征后的特征子集正域集合更新,實現對基于代價敏感的多標記不完備數據的特征選擇,最壞的時間復雜度為O(|C‖U|);算法Step7判斷約簡后的特征子集下正域與整個論域的正域是否一致,最壞的時間復雜度為O(|U|).綜述分析,本文算法的時間復雜度為O(|C‖U|2).
5 實驗與結果分析
5.1 數據集及實驗設置
為了驗證本文中所提出的基于代價敏感多標記不完備數據特征選擇算法的有效性,從Mulan數據集中選取了yeast、emotions、scenes、birds 4個真實數據集,并分別用均勻分布(Uniform Distribution)和正態分布(Normal Distribution)兩種分布函數(Cumulative Distribution Function,記為CDF)分別為這4個數據集生成測試代價,在對基于測試代價的多標記數據集進行實驗測試和分析,均勻分布的均勻數取值在0~100之間,正態分布以100為期望值,以30為標準差,4個數據集的相關信息和不同分布函數下4個數據集所對應的測試總代價分別如表3、表4所示.
本次實驗的硬件配置為CPU為Inter(R)Core(TM)i5-4590s(3.0GHz),內存8.0GB.設計算法所使用的編程語言為Python和Java,使用的開發工具分別是記事本和Eclipse 4.7.
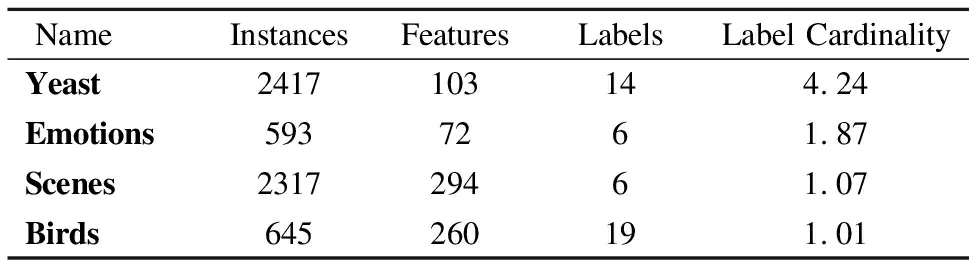
表3 多標記數據集表Table 3 Multi-label datasets table

表4 數據集總測試代價表Table 4 Cost of multi-label datasets table
5.2 性能指標
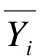
1)代價約簡率是考慮特征代價的特征子集B的代價占全特征集A總代價的比率:
2)平均精度是指在標記預測序列中,排在相關標記之前的標記仍是相關標記的比率:
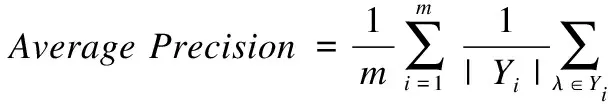
3)漢明損失是指預測出的標記與實際標記的平均差異值:
其中Δ為Yi、Zi兩個集合之間的對稱差.
4)覆蓋率是指所有對象實際包含的所有標記所需最大的排序距離:
5)1錯誤率是指預測出的標記排序最靠前的標記不在實際對象中的比率:
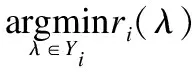
6)排序損失是指預測出的標記中實際不包含的標記比實際包含的標記排序高的比率:
其中平均分類精度越大越好,漢明損失、覆蓋率、1錯誤率、排序損失越小越好.
5.3 實驗分析與比較
由于文中的多標記數據特征選擇算法是基于代價敏感的,所以在進行實驗測試之前,需先用均勻分布和正態分布兩種分布函數分別為以上4個數據集的特征生成測試代價,通過比較基于不同分布函數的特征代價來評價測試代價對多標記數據特征選擇算法的影響.同時,文中研究的是不完備數據,因此,需用均勻函數對以上4個數據集進行5%的數據缺失處理.在實驗測試和分析的過程中,為了避免實驗結果的均勻性,采用10倍交叉驗證法對每個數據集的實驗結果進行驗證.在實驗過程中,首先利用曼哈頓距離度量方法計算鄰域粒度,同時,在特征核的基礎上,對每個數據集進行特征選擇.然后比較考慮代價和不考慮代價特征選擇的結果,通過5種多標記分類器(RAkEL、DMLkNN、IBLR_ML、BRkNN、MLkNN)驗證了算法的性能,且通過多標記的五大評價性能指標評估和對比分類器的分類性能.
5.3.1λ特征參數的確定
對于基于代價敏感的多標記不完備鄰域決策表,特征選擇的結果與特征代價直接相關,因此,在實驗過程中,對基于均勻分布和正態分布生成的兩種特征代價獲得的特征選擇結果進行對比,同時,由于鄰域參數的選擇直接關系到特征選擇的結果和分類器的分類性能.為此,在曼哈頓距離度量方法中,鄰域參數的計算方式為δ=stdai/λ,其中stdai通過本文算法進行特征選擇之后的每個特征的標準差,λ的取值直接關系到鄰域參數δ的值[27].通過實驗分析發現,λ的取值范圍從1.0到2.0的特征選擇結果所對應的分類性能較好,為此,為了詳細分析λ值對特征選擇結果和分類器的分類性能影響,在實驗過程中將λ值每次變化0.1進行實驗分析和結果對比.
下面將分析不同分布函數隨著λ變化對特征選擇結果以及代價的影響,詳細分析基于不同分布函數生成的測試代價在曼哈頓距離度量標準下λ(在圖中用Lambda表示λ)變化對于特征選擇的個數和特征子集總代價影響.圖中UDASBC、NDASBC分別表示在均勻分布和正態分布下考慮特征代價的特征選擇個數,UDAS、NDAS分別表示在均勻分布和正態分布下不考慮特征代價的特征選擇個數,UDCPBC、NDCPBC分別表示在均勻分布和正態分布下的代價約簡率,即考慮特征代價的特征子集代價占總代價的百分比(由于兩種分布函數生成的代價不同,因此兩種分布函數通過代價百分比分析),UDCP、NDCP分別表示在均勻分布和正態分布下不考慮特征代價的特征子集代價占總代價的百分比.具體實驗結果如圖1所示.
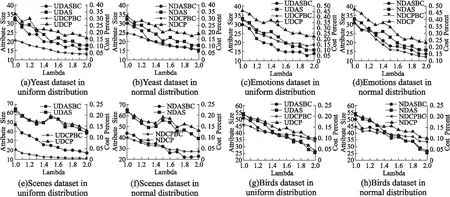
圖1 4個數據集在兩種分布函數下特征選擇的個數和代價百分比隨λ值的變化情況Fig.1 Variation of the number of feature selection and the value of the cost percentage for the four datasets under the two distribution functions with λ
由圖1可知,對于4個數據集來說,隨著λ變化,特征選擇個數和代價百分比都呈下降趨勢.考慮測試代價比不考慮測試代價的特征選擇效果更優,例如對于圖1(e)和圖1(f)中的scenes數據集,當不考慮測試代價時 ,特征選擇個數最小為39,當考慮測試代價時,均勻分布和正態分布下特征個數最小分別為17、22,分別占不考慮測試代價特征選擇結果的43%、56%;同時,考慮測試代價的代價百分比不考慮測試代價的代價百分比相對更小,當考慮測試代價時,均勻分布和正態分布下代價百分比最小分別為0.40%、3.60%,而不考慮測試代價時,均勻分布和正態分布下代價百分比最小分別為13.26%、13.19%,代價分別減少了12.86%、9.59%.另外,當代價百分比最小時,在均勻分布下代價百分比相差最為顯著的是圖1(a)中的yeast和圖1(e)中的scenes數據集,最小代價百分比相差大于11%,在正態分布下代價百分比相差較明顯的是圖1(b)中yeast、圖1(d)中的emotions和圖1(f)中的scenes數據集,最小代價百分比相差大于9%.由此可知,對于yeast和scenes數據集來說,考慮代價與不考慮代價的代價百分比的差在均勻分布下比正態分布下大.當λ取值為1.9或2.0時,特征選擇個數和代價百分比最小.
綜上可知,考慮代價的特征選擇效果優于不考慮代價的特征選擇效果,考慮特征代價的代價百分比小于不考慮特征代價的百分比.
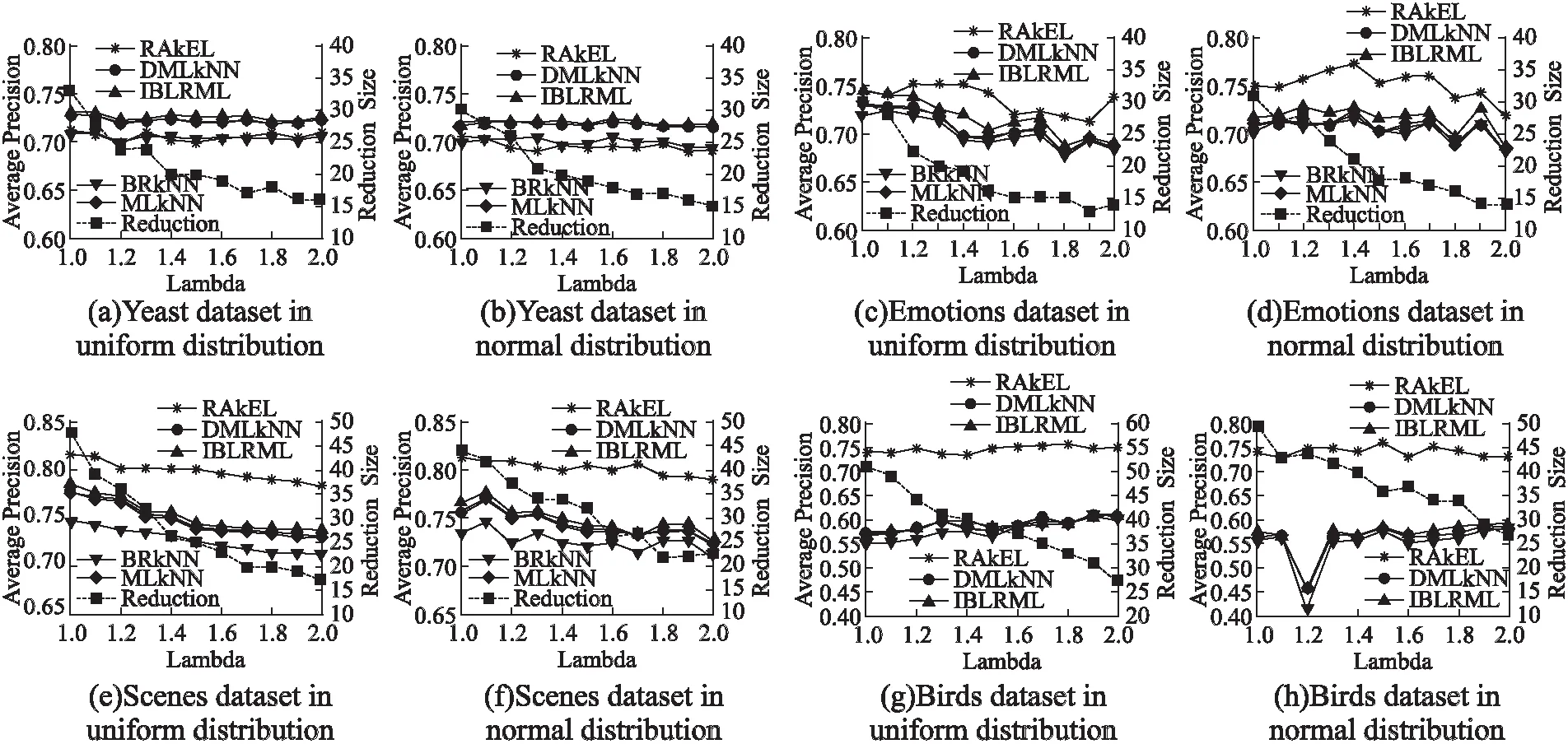
圖2 4個數據集在兩種分布函數下平均精度隨λ值的變化情況Fig.2 Variation of the average precision with the values of the four datasets under the two distribution functions with λ
由圖2可知,當λ取值在1.0-2.0之間,在兩種分布函數下,特征選擇的個數都呈下降趨勢.在均勻分布下,對于圖2(a)中的yeast、圖2(e)中的scenes和圖2(g)中的birds數據集來說,隨λ取值的變化,5個分類器的平均分類精度的變化相對不明顯,當λ=2.0時,3個數據集的特征選擇結果和分類性能較優;對于圖2(c)中的emotions數據集來說,平均精度隨λ取值的變化無明顯規律,當λ=1.2時,5個分類器的平均精度較優.在正態分布下,隨λ取值的變化,圖2(d)中的emotions數據集的平均精度的變化顯著,圖2(b)yeast和圖2(f)scenes數據集的平均精度變化較平緩,圖2(h)中的birds數據集在λ=1.2,除RAKEL分類器外,其他4個分類器的平均精度顯著下降,參數λ在變化到1.2之后的平均精度變化相對平緩.對于yeast、emotions、scenes、birds數據集來說,當λ取值分別為2.0、1.4、1.9、2.0時對應數據集的特征選擇結果和分類性能較優.
綜上可知,每個數據集在5個多標記分類器上最優的平均分類精度所對應的λ參數不盡相同,參數λ的取值也影響特征選擇的結果.
5.3.2 實驗結果和討論
為進一步驗證本文算法的有效性,下面將在4個Mulan數據集上利用兩種分布函數為特征生成測試代價,通過5個多標記性能指標在曼哈頓距離度量下進行實驗對比和分析,實驗結果如表5-表8所示,其中,λ為特征參數,AS為特征選擇的個數,PC為代價百分比,AP為分類器的平均分類精度,HL為漢明損失,Coverage為覆蓋率 、OE為1錯誤率、RL為排序損失,帶有↑的性能指標表示值越大越好,↓性能能指標表示值越小越好.另外,表中分別給出5個分類器的平均精度最優時,對應的λ參數、特征子集的大小、特征子集的代價百分比和其他4個分類性能指標的值.
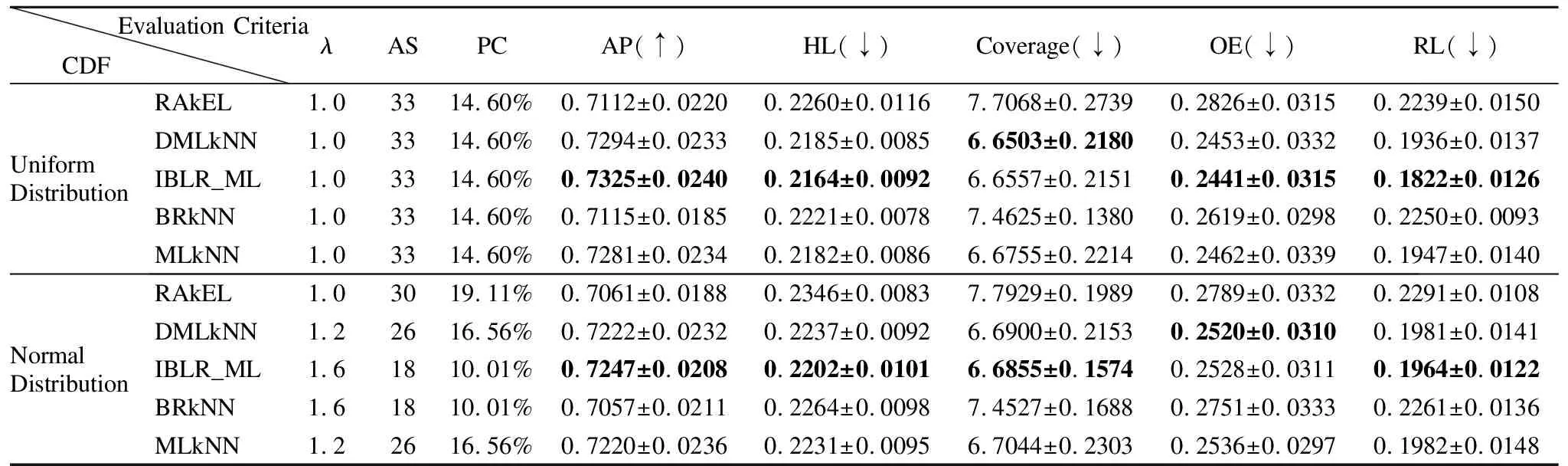
表5 兩種分布函數下Yeast數據集的分類性能指標比較Table 5 Comparison of classification performance of yeast dataset under two distribution functions
從表5-表8的實驗結果可知,當分類器的平均分類精度最優時,均勻分布與正態分布相比,4個數據集在均勻分布下,5個分類器的分類性能相對較優.在均勻分布下,yeast、emotions、scenes和birds這4個數據集所對應的5個分類器的平均特征個數分別是33、27、43、31,分別占原有特征的32.0%、27.2%、14.6%、11.9%;在正態分布下,這4個數據集所對應的平均特征個數分別是23、20、42、30,分別占原有特征的22.9%、27.8%、14.29%、11.5%.其中,在yeast數據集中,使用均勻分布比正態分布下的特征選擇算法效果提高了9.1%,而其他4個數據集特征選擇的差異并不明顯.同時,在均勻分布下,yeast、emotions、scenes和birds這4個數據集所對應的五個分類器的特征選擇結果的代價百分比分別是14.60%、33.52%、3.62%、9.94%;在正態分布下,這4個數據集所對應的特征選擇結果的代價百分比分別是14.45%、20.39%、8.89%、9.22%,由此可知,emotions和scenes數據集在不同分布函數下代價百分比的差異較大.由實驗結果可知,本文的基于代價敏感的特征選擇算法降低了多標記學習的計算時間和空間消耗,且有效地節省了成本代價.同時,由表5-表8的實驗結果對比發現,選擇的特征子集直接影響到多標記分類器的分類性能.在上述4個數據集中,由于特征子集的結果不同,導致5種分類器的分類性能也不相同.例如,在均勻分布下,birds數據集在RAkEL分類器下的平均分類精度為75.60%,而在IBLR_ML分類器下的平均分類精度為60.79%,兩個分類器的性能差異超過14%;在正態分布下,birds數據集在RAkEL分類器下的平均分類精度為76.26%,而在BRkNN分類器下的平均分類精度為58.20 %,兩個分類器的性能差異超過18%.由實驗結果可知,對于yeast數據集來說,IBLR_ML分類器的分類性能優于其他4個分類器的分類性能;對于emtions、scenes和birds數據集來說,RAkEL分類器分類性能較其他4個分類器的分類性能更優.
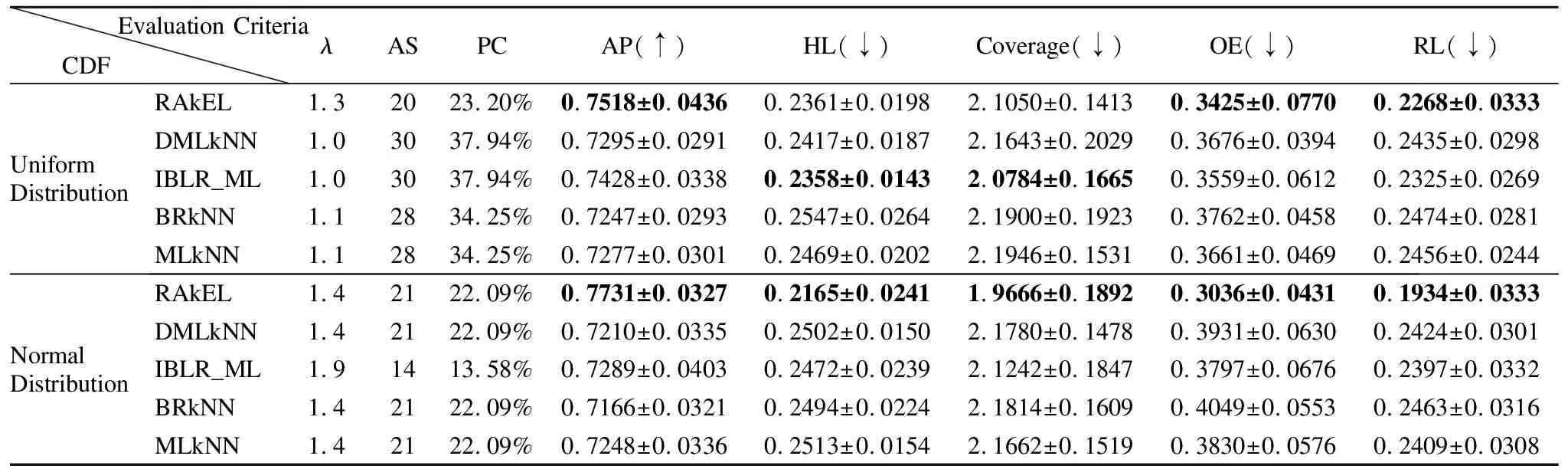
表6 兩種分布函數下Emotions數據集的分類性能指標比較Table 6 Comparison of classification performance of Emotions dataset under two distribution functions
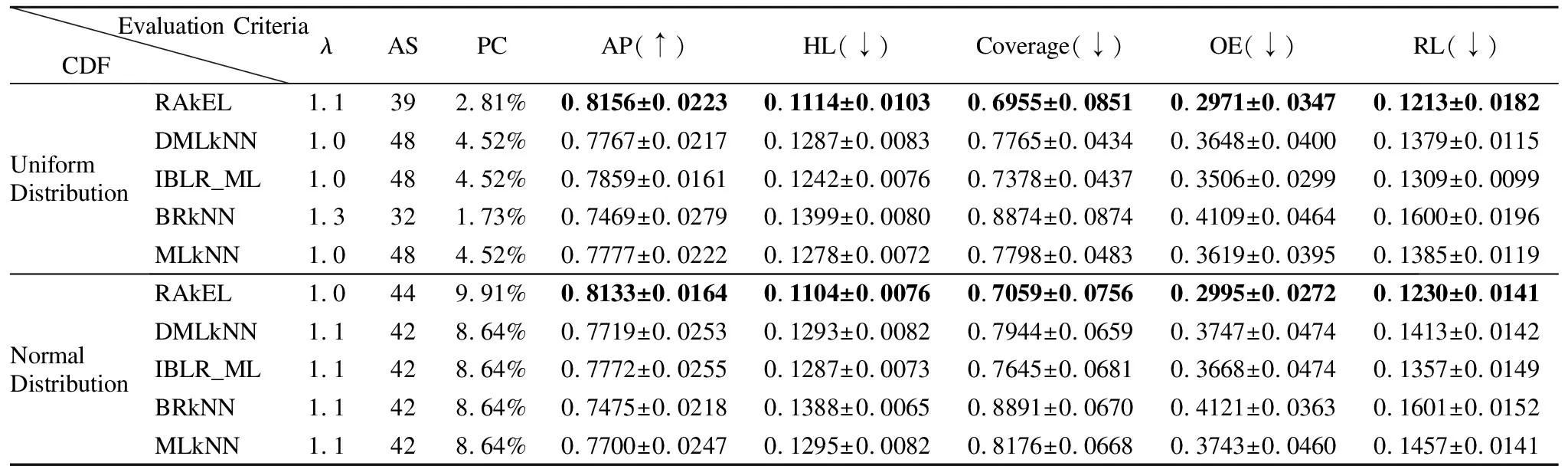
表7 兩種分布函數下Scenes數據集的分類性能指標比較Table 7 Comparison of classification performance of Scenes dataset under two distribution functions
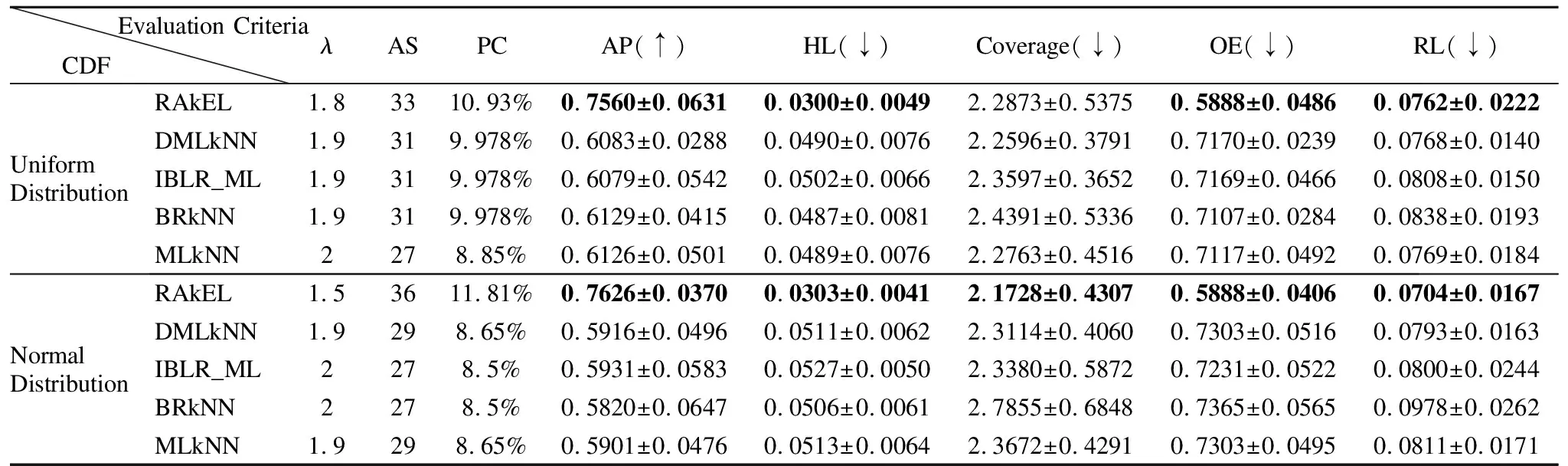
表8 兩種分布函數下Birds數據集的分類性能指標比較Table 8 Comparison of classification performance of Birds dataset under two distribution functions
綜上所述,本文算法特征選擇的結果和分類性能與特征代價、λ參數和分類器的選擇相關.通過表5-表8的實驗結果和分析可知,本文算法解決了對代價敏感下多標記不完備鄰域數據的特征選擇問題,有效剔除了數據中的冗余特征,降低特征的代價成本,提高了分類器的分類性能.
6 結束語
針對多標記高維數據中的連續值、缺失值以及特征的測試代價等問題,從代價敏感學習的視角,提出了一種面向不完備特征鄰域決策表的多標記特征選擇算法,算法利用均勻分布和正態分布兩種分布函數分別為每個數據特征生成代價,分析特征代價對特征選擇的影響;算法可直接對不完備連續型數據進行處理,無需對缺失數據進行填充及對連續數據進行離散化.算法通過距離度量對不完備特征鄰域決策表進行鄰域粒化,并根據正域計算出核特征,在此基礎上,采用啟發式搜索策略對多標記不完備決策表進行特征選擇,在實驗結果中通過對考慮特征代價和不考慮特征代價的數據集的特征選擇結果進行實驗和分析驗證了算法的有效性.由于現實生活中除需要考慮測試代價之外,還需考慮誤分類代價,下一步工作將研究基于測試代價和誤分類代價的多標記數據特征選擇問題.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
