基于機器學習的高效惡意軟件分類系統
2019-01-18 05:59:56李東寶
沈陽師范大學學報(自然科學版) 2018年6期
屈 巍, 侍 嘯, 李東寶
(沈陽師范大學 科信軟件學院, 沈陽 110034)
0 引 言
近年來,惡意軟件技術的不斷發展對現代信息技術與個人信息安全造成了極大的威脅,這使得人類對反惡意軟件技術的需求日益月滋[1]。2017年5月12日,全球范圍內多所高校、企業、政府機構被名為“WannaCry”的勒索病毒攻擊[2]。各大反惡意軟件廠商緊急采取措施減少損失。但隨之而來的“WannaCry”的變種使用多種手段躲避查殺,并且借助新的安全漏洞進行大規模傳播。“WannaCry”變種的出現只是一個例子,隨著惡意軟件技術的發展,其逐漸能夠以成熟的技術避開傳統的保護機制,成為非法活動的強大工具。
為了躲避檢測,惡意軟件作者不斷修改和混淆原本的惡意軟件[3],這是惡意軟件數量迅速增長的一個重要因素。根據2017macfee的Q3季度惡意軟件報告,Q3季度變種惡意軟件數量同比Q2季度增長了約10%。而大量的新變種的出現意味著研究人員需要分析這些大量的樣本以尋求應對的措施。被使用不同策略進行修改與模糊處理,看起來各不相同的代碼,實際上擁有相似的惡意特征的樣本群,稱為一個惡意軟件“家族”。研究者需要分析新出現的惡意軟件樣本,發掘和匯總其中的特征。但近幾年,大量的新樣本使得人工分析的缺口愈加嚴重。所以將具有相似特征的樣本一同分析,可以減輕研究人員的負擔,也會更容易發現某一家族的隱含特征。因此惡意軟件的分類在惡意軟件分析中扮演著重要角色。但在機器學習概念成熟之前,普遍采用人力輔以簡單的靜態匹配分類。而混淆多態策略會讓靜態匹配技術的效果大打折扣。近年來,隨著機器學習的興起,越來越多研究者嘗試使用機器學習的方式建立分類系統,它具有自動特征提取,和人工干預較少的特點。
1 相關工作
在惡意軟件的特征指紋的確定過程中,為了獲取和理解其可能的來源和潛在的威脅方向,研究人員需要對一個新的惡意軟件樣本進行分析和分類。
靜態分析指在不運行程序的情況下對程序的分析。在靜態分析前研究人員需要盡可能地去除代碼中的混淆和加密手段[4],以防止靜態特征受到干擾。但是隨著惡意軟件多態化技術的發展,惡意軟件作者開始使用各種多態化方法以回避靜態分析[5]。
動態分析指在可控的模擬環境下運行惡意代碼,觀察其行為,進而確定其意圖。與靜態分析相比,動態分析無需反匯編,也不需要解密或解壓。但由于需要運行,動態分析在消耗上要大于靜態分析,且由于模擬環境的模式單一,惡意代碼的各個分支難以被遍歷。
繼Schultz[6]首次將數據挖掘引入到惡意軟件的檢測中,許多人在這一方面做出了創新和改進工作。Nataraj[7]提出了一種將惡意代碼圖片化后提取圖像特征的機器學習算法;Kong[8]構建了一個以函數調用圖為特征的機器學習框架;n-gram被廣泛使用在惡意代碼檢測中[9]。單一的選擇某種特征,會忽略掉很多重要的信息,并且如n-gram這樣的特征在提取時會占用大量的系統資源,運行速度較慢,因此本文提出了多特征選擇融合的方法。
本文提出的方法的主要優點有:
1) 提取數據方便,自動化分類,
2) 使用了惡意軟件自身信息作為部分字符串特征,
3) 僅需提取一些簡單的特征,實現方法簡單,
4) 分類系統誤差較小且運行速度極快。
2 基于機器學習的多特征融合的高效惡意軟件自動分類系統
本文提出了一種基于機器學習的多特征融合的高效惡意軟件自動分類系統,其分類步驟如圖1所示。

圖1 系統分類步驟Fig.1 System classification steps
2.1 惡意代碼表現形式
本文使用惡意軟件的字節碼和反匯編代碼這2種最常見的表現形式作為的數據。
字節碼是分析惡意軟件的一種常見形式,它易于獲取,無需獲取樣本文件本身,通過一些內存查看工具就可以獲得內存中惡意代碼的最直接的表現形式,如圖2所示。
對于編譯型語言而言,反匯編代碼是借助反匯編工具,針對編譯時的目標代碼生成步驟對二進制可執行程序進行逆向工程的產物,其主要表現為匯編語言代碼,如圖3所示。
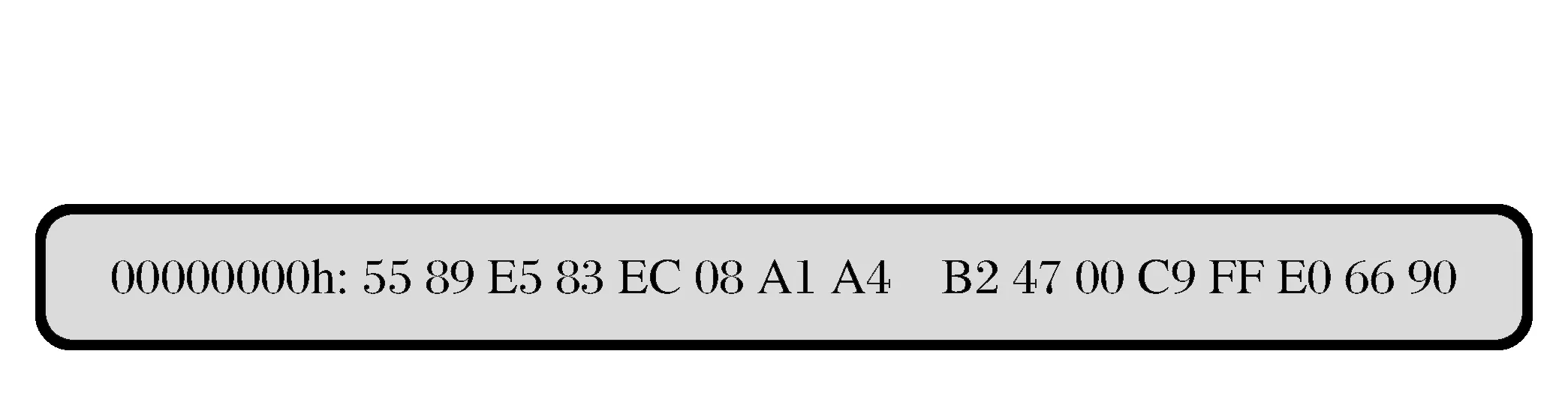
圖2 十六進制視圖Fig.2 Hexadecimal view

圖3 反匯編視圖Fig.3 Disassembly view
本文使用UPX加殼工具和一些修復檢測工具,如UPX Packer、UPXfix等,對大量樣本進行了UPX程序殼的簡單去除
2.2 特 征
為了達到高性能且高效率的最終目的,本文嘗試多種特征并擇優使用。這些特征更容表現出惡意軟件的體系結構與惡意行為。
2.2.1 文件屬性
文件屬性(fp)對惡意軟件分類非常有用,壓縮率可以很大程度上描述文件的類型,本文提取了字節文件與反匯編文件大小和壓縮率,并且獲取了他們的比值。
圖4描述了對于每類家族字節文件壓縮率的分布,其中0~8分別代表9類惡意軟件家族,顏色較深處為樣本集中處。
2.2.2 反匯編文件關鍵字
在匯編代碼中,軟件的行為通常由一些代碼關鍵字符或者字符串(key)決定[10]。程序節、操作碼、應用編程接口調用和動態鏈接庫在很大程度上描述了一個軟件的行為與目的[11],這些屬性的數量與分布具有一定的規律,本文統計了他們出現的頻率,與其占的比例。
本文還統計了一些特殊字符如@,+,*,?在文件中出現的頻率,和一些有意義且與軟件行為相關的字符串的頻率與其占的比例,其中一部分是從微軟Windows Defender Security Intelligenc獲取了關于這些惡意軟件家族描述中提及的注冊表鍵等字符串。
2.2.3 熵
熵(ent)是信息不確定性的一個測度,熵越大則表示信息的不確定程度越高[12]。本文壓縮了字節文件中每4kB塊的字節,使用香農公式計算每塊的熵e作為特征:
(1)
其中,p(i)代表這一塊中字節i的頻率;m代表窗口內不同字節的數量。
信息熵描述了信息的不確定程度,同時也能表現出代碼文件之間的邏輯,盡管惡意軟件代碼改變了軟件原有的目的,但是其很難改變軟件原有的信息量。在惡意軟件變種的過程中,會通過一些簡單的手段隱藏惡意行為,卻難以改變整個文件信息之間的邏輯,并且信息熵在描述信息分布的同時,也同時會描述出信息分布的變化,可以有效分析出惡意軟件隱藏的惡意行為。
2.2.4 N-gram
N-gram是NLP領域中非常重要的一個概念,N-gram的一個主要作用是評估2段文字之間的差異程度[13],是模糊匹配中最常用的一種手段。一連串的十六進制代碼可以通過N-gram有效的分析,捕獲到代碼中的關鍵信息。1-gram有256個特征,2-gram有65 536個特征,本文對于1-gram(1gram)提取所有詞的頻率,而2-gram(2gram)僅考慮最受歡迎的600詞與特殊字符串的前2個字節。這些特殊字符串在2.2.2節中考慮過,但由于編碼的問題,一部分在反匯編文件中不可見,于是再次使用。本文還將將字節文件的一行作為1-gram(flgram),本文選取了1 000個文件中最常出現的一些行作為gram。
一個字節文件中獲取的1-gram、2-gram與整行的1-gram例子如圖5所示。

圖5 N-gram應用在字節碼中Fig.5 N-gram applied in byte code
2.2.5 圖像特征
惡意軟件可以通過將每個字節解釋為圖像中的一個像素而把字節文件形象轉化為灰度圖像[7],將字節表示為像素,很容易可以得到圖像的像素強度,因此提取圖像的前300~600像素強度(img)作為特征。同時,借用文獻[7]的思路,本文在asm文件中也進行了應用。
將代碼轉換為圖像,可以獲得非常精致的紋理,這些紋理很大程度地描述了代碼之間的相似程度以及代碼的函數結構和代碼之間的文件結構,惡意軟件相似的行為也通常包括相同的代碼或相同的函數調用,并且部分惡意軟件作者通過將代碼改為相似的格式用于隱藏部分惡意信息,將代碼轉為肉眼可見的圖像,可以有效地分析代碼在惡意行為上的相似之處。
圖6中,圖6a與圖6b分別是Ramnit家族中一例惡意軟件將字節碼與反匯編代碼轉化成的灰度圖像,圖6c與圖6d是Gatak家族。可以看出,不同家族的灰度圖紋理上有較大差異。

(a)—Ramnlt家族asm文件樣例; (b)—Ramnlt家族bytes文件樣例; (c)—Garak家族asm文件樣例; (d)—Garak家族bytes文件樣例
2.3 分類器
本文選取了3種算法進行了考慮分別是常用的ExtraTreesClassifier、支持向量機和一種漸進回歸樹的優化算法xgboost[14],對比多種分類器,最終實驗使用多分類器融合,使用80%的xgboost和20%的ExtraTreesClassifier作為分類算法。
3 實 驗
3.1 數 據
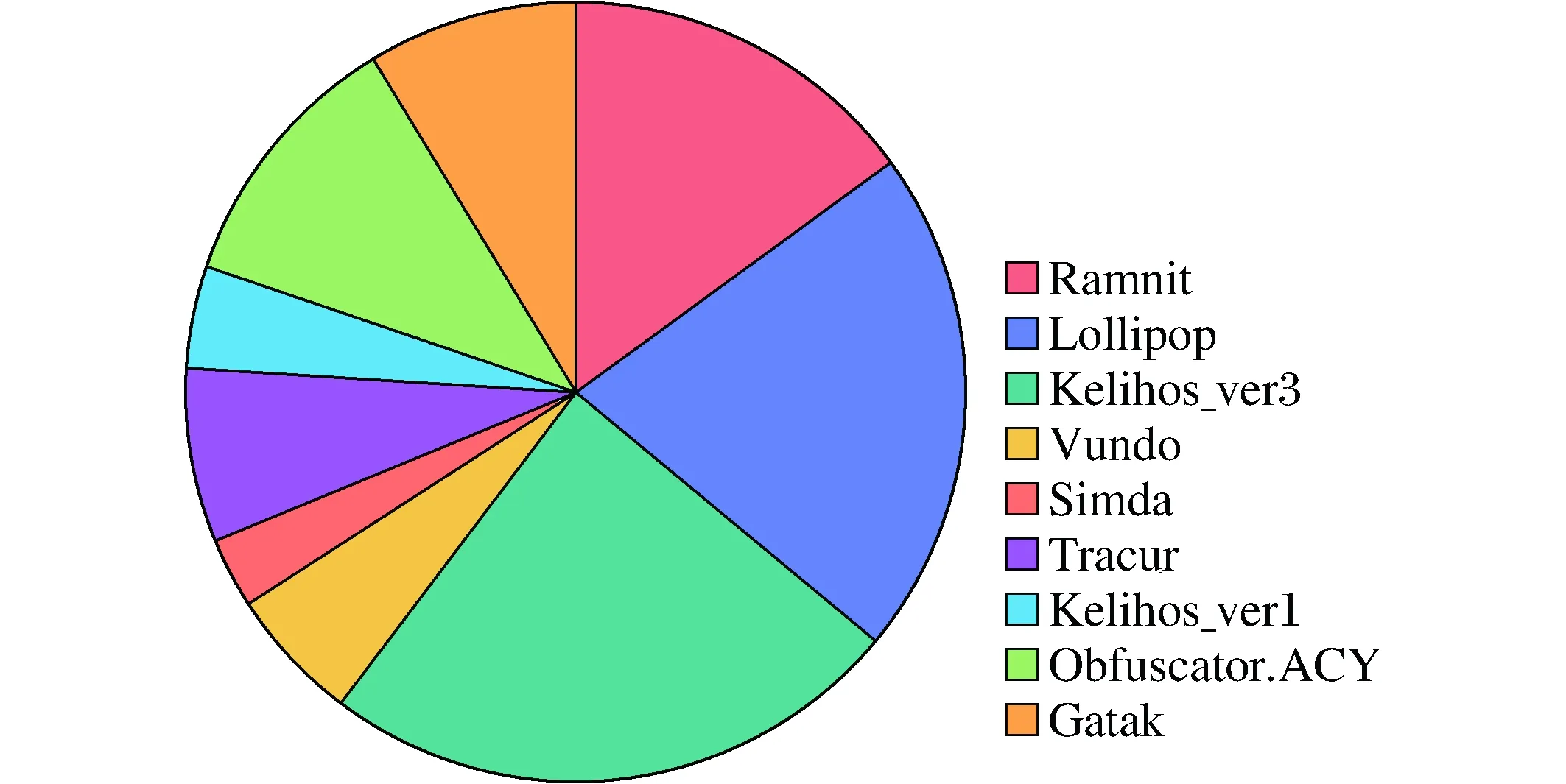
圖7 數據分布餅狀圖Fig.7 Data Distribution Pie Chart
微軟在2015年在kaggle平臺上發布了一組近0.3T的帶有標簽的樣本供各界惡意軟件研究者研究學習。考慮到數據的代表性,我們在VirusTotal等相關惡意軟件交流平臺中又收集了近0.1T的近期數據。這些數據被分成9個家族(0~8),分別是Ramnit, Lollipop, Kelihos_ver3, Vundo, Simda, Tracur, Kelihos_ver1, Obfuscator.ACY和Gatak(如圖7)。
3.2 評估方法
本文使用對數損失作為分類系統的性能的評估方法,對數損失公式:
(2)
式(2)中N和M分別代表樣本的數量與惡意軟件家族的數量,yij表示樣本i是否被預測為j類,而pij則表示為樣本i被預測為j類的概率。
3.3 結果與分析
本系統在一臺四核2.60 GHz處理器,8 G內存的個人筆記本上運行。
將所有的樣本選進行了多次交叉驗證,取平均值作為最終結果,最終logloss為0.006 4。最終模型多次交叉評估后對應的對數混淆矩陣如圖8所示。圖9是本文選取的各個特征提取所需的平均時間,將其相加,即可得到系統總的特征提取平均時間6.5 s。
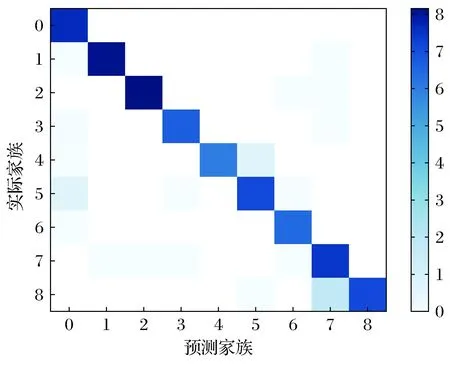
圖8 對數混淆矩陣Fig.8 Logarithmic confusion matrix
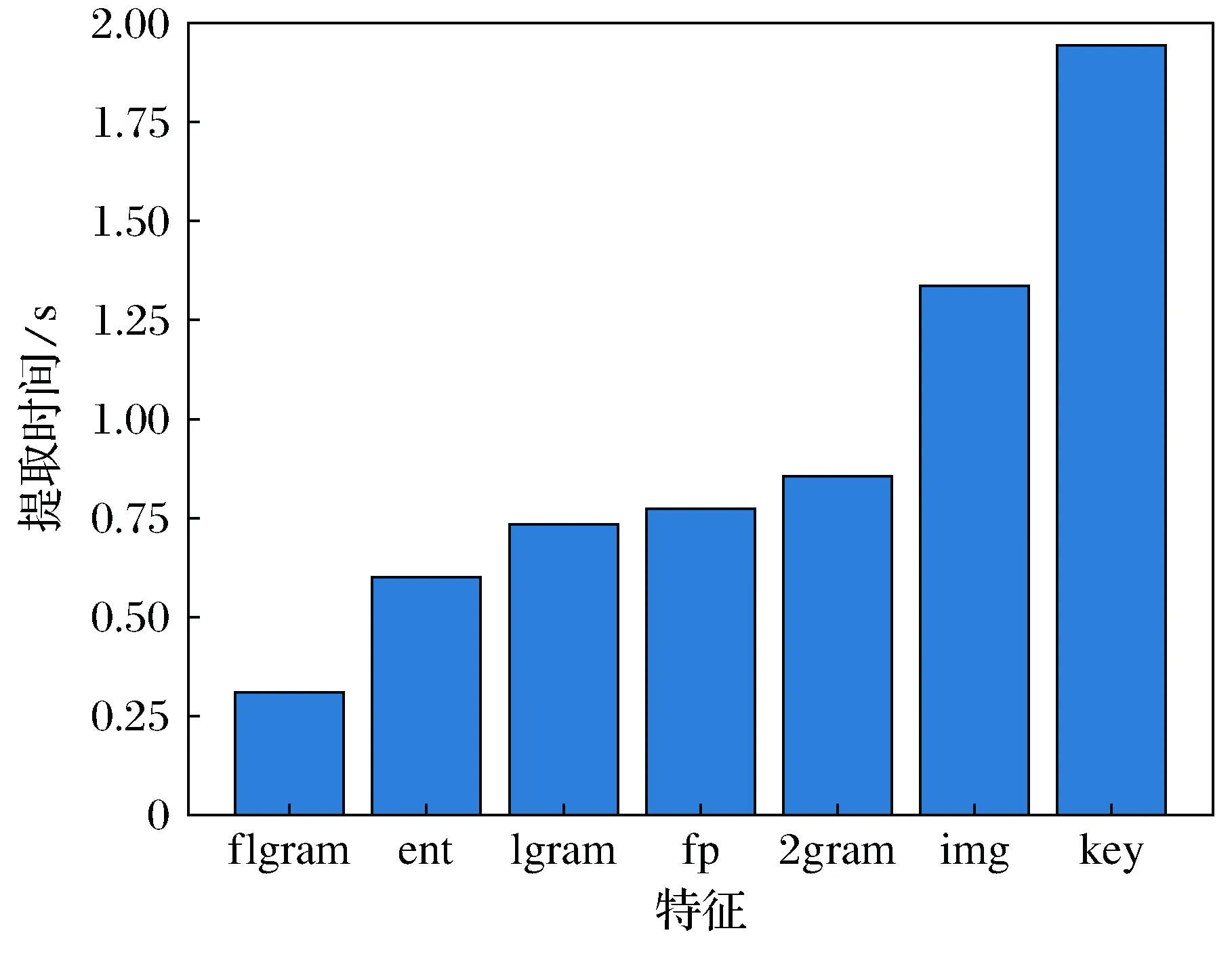
圖9 各特征所需平均時間Fig.9 The average time for each feature

模型名稱特征組成Logloss模型0key+fp+ent0.0128模型1img0.2473模型21gram+2gram+flgram0.0227模型3模型0+img0.0103模型4模型0+模型20.0088模型5模型5+img0.0064

表2 與其他系統性能對比Tab.2 Compared with other system performance
從圖9中可以看出,將整行字節碼作為1gram的方法,提取時間極短,而關鍵字特征提取時間長是因為關鍵字特征中包含多種類型關鍵字,并且在系統中也發揮了很好的效果。
3.3.1 不同模型
表1是本文選取的特征不同組合情況下所得到的logloss情況,根據圖中不同組合情況下的結果能看出,圖片特征單獨使用時表現僅達到了0.247 3的logloss,但是與其他特征搭配使用是卻能有效的將logloss減少至0.006 4,并且僅搭配匯編關鍵字與文件屬性等特征就能減少到0.010 3的logloss,輔以其他特征,可以達到非常理想的效果。
3.3.2 與其他系統對比
本文簡單復現了一些已被提出的方法(表2),并且與本文的系統比較,其中Hu, X的做法收集與還原了文件的中大量的信息作為特征,得到了0.025 8的logloss,并且未曾考慮過效率問題。Mikhail的做法采用了諸如10-gram等復雜度極高的特征,已無法在個人PC中運行。而本文在提取時間6.5 s的情況下,得到0.006 4的較低logloss,即使對比于Mansour的融合方法也有效的縮短了3.5 s的提取時間,并優化了約0.003 0的logloss。
4 總 結
由于現代惡意軟件通過變形和多態的方式躲避檢測,惡意軟件數目爆發式增長。因此對于大量的惡意軟件,高效自動的惡意軟件分類系統對研究人員的工作有巨大的幫助。基于這些,本文提出了一種基于機器學習方法的多種特征選擇融合的高性能、高效率的惡意軟件自動分類系統。通過對比實驗,本文分析了已有方法的缺點與本文的優勢,證明本文提出的系統在效率與性能上明顯優于已有的方法。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22