基于NLTK的中文文本內容抽取方法①
2019-01-18 08:30:42劉衛國
計算機系統應用 2019年1期
李 晨, 劉衛國
(中南大學 信息科學與工程學院, 長沙 410083)
NLTK的默認處理對象是英文文本, 處理中文文本存在一定的局限性, 主要體現在以下兩點:
(1) NLTK素材語料庫中缺少中文語料庫, 在NLTK模塊中包含數十種完整的語料庫, 例如布朗語料庫、古騰堡語料庫等, 但沒有中文語料庫. 另外, NLTK也沒有中文停用詞語料庫, 在文本預處理中, 特別是在進行頻率統計之前需要使用停用詞語料庫對文本進行過濾清洗, NLTK沒有提供針對中文的停用詞庫, 使用針對英文的過濾方法是無法完成中文文本的停詞過濾.
(2)在英文文本中, 文本的分割可以由單詞之間的空格完成, 但是中文文本的分割依靠NLTK是無法完成的, 中文分詞工作需要借助分詞工具來完成, 已有的一些中文分詞工具有結巴分詞(jieba)、斯坦福中文分詞器等.
本文應用NLTK對中文文本進行信息抽取.
1 NLTK文本內容抽取框架
使用NLTK對自然語言文本中詞句內容進行提取與分析, 可以概括為篩選、提取、統計、解釋的過程[1,2]. 抽取方法首先對其中無實際含義的詞匯進行篩選過濾, 使用概率統計方法提取出高頻詞集, 接著識別出文本的關鍵詞, 選定研究詞匯. 以該詞匯作為目標詞,查找其所在的句子, 對段落、篇章內的詞匯進行計數統計與篇章分析, 解釋文本內容與研究問題. 為此將以上過程簡化為三個階段, 分別是預處理、分析以及輸出階段, 如圖1所示.

圖1 NLTK抽取框架
1.1 預處理階段
預處理階段是確定文本并對文本進行簡單處理的過程, 預處理方法主要有分塊與分詞、清洗過濾. 分塊與分詞是對文本進行切分的操作, 由于分析階段各方法調用對象的不同, 文本需要劃分成不同子單位的文本, 例如以詞為最小單位的文本、以句為最小單位的文本. 清洗過濾是對文本分詞處理后刪去文本中無實際意義的詞匯符號的過程.
1.2 分析階段
分析階段是抽取過程的核心, 涉及到文本的一系列處理操作. 文本經預處理階段以詞、句、篇章為基本單位進行切分后, 在這三個維度上使用不同的分析方法. 經分詞處理后, 針對單個詞匯進行的操作有雙連詞提取、同語境詞提取. 在單個句子上可執行的操作有詞性標注、句法分析. 在篇章中可以進行篇章分析[3]與統計分析, 其中統計分析是最常使用的工具. 例如,在對布朗語料庫[4]的研究中, 以概率統計的方法得到不同文體中情態動詞的頻率分布, 歸納總結出情態動詞在文體中的分布規律, 從而對文本的文體進行判斷.
1.3 輸出階段
文本的抽取結果分為兩大類, 一類是將提取出詞與句子等結果作為原始依據, 對文本內容含義進行解釋; 第二類是以可視化的形式展示數據結果, 更加直觀地體現詞匯頻率的對比.
2 NLTK對文本的處理方法
2.1 預處理方法
2.1.1 對原始文本分詞與分句
在NLTK中, 分詞分句操作可以將文本處理成可以單獨調用的詞或句子. 分詞是將句子序列或字符串構成的文本劃分成單個的詞. 分句是將文本中的篇章段落劃分成單個的句子. 使用nltk.word_tokenize()、nltk.sent_tokenize()進行分詞與分句操作. 分詞處理后文本中的詞匯、符號轉化為單一標識符, 這是進行后續分析工作的關鍵.
2.1.2 對原始文本進行清洗過濾
清洗與過濾實際上是一個分類的過程, 使用正則表達式匹配需要過濾掉的數字與符號, 對文檔中的純文本內容進行提取. 然后, 利用停用詞語料庫對文本實現過濾, 停用詞語料庫中包含無實際意義的高頻詞匯,例如 a, to 等.
以下的命令定義了一個過濾英文停用詞的函數,將文本中的詞匯歸一化處理為小寫并提取, 從停用詞語料庫中提取出英語停用詞, 使用詞匯運算符將文本進行區分.

2.2 分析方法
2.2.1 同語境詞查找
NLTK中使用函數similar()查找與目標詞匯出現在相似上下文位置的詞, 即在文本中可用作替換的詞匯.在《白鯨記》中使用text.similar("captain")找到以下同語境詞: whale ship sea boat deck world other. 可以發現得到的詞匯與目標詞匯詞性均為名詞.
2.2.2 統計分析
概率統計作為最常用的數學分析手段, 用于文本中數據的處理分析. 在Python中借助NLTK頻率分布類中的函數, 對文本中出現的單詞、搭配、常用表達、符號進行頻率統計、長度計算等相關操作, 使用fdist= nltk.FreqDist()對研究文本創建頻率分布, 函數fdist['target word']查找頻率分布內目標詞匯的出現次數, fdist. most_common(n)從頻率分布中提取出高頻詞匯, 其中參數n為提取詞匯的數量.
2.2.3 篇章分析
對篇章內容的分析也是使用NLTK對文本內容進行抽取的方法之一. 布朗語料庫以文體作為分類標準.根據這一特點, 利用布朗語料庫探索詞匯在不同文體中的使用情況. 使用條件概率的方法, 選擇布朗語料庫中6個不同的文體類型分別統計wh-詞的使用情況. 命令如下:

命令執行后, 以表格的形式打印所得結果如圖2所示.

圖2 頻率統計結果
從結果上來看, 在religion與news文體中which和who出現次數較多, hobbies文體中when、which、who出現較多, 而在science_fiction與humor文體中wh-詞出現的次數較為均勻, 在romance文體中what、when、which出現次數較多. 使用條件概率的方法找到文體中同類型詞使用差異, 以表格的形式展示結果[5].
抽取過程中疊加使用分析方法, 將獲得的結果作為分析的原始素材進行二次加工處理.
2.3 輸出方法
利用Python的第三方圖表模塊對數據進行二次處理. Matplotlib是Python中用于可視化處理的模塊,該模塊對結構化數據繪制統計圖表, 例如柱狀圖、扇形圖、折線圖、直方圖等圖形[6]. 導入Matploylib庫,并引入上一階段獲得的數據. 函數fdist.plot(n, cumulative=True/False)在建立概率分布的基礎上對統計結果繪制頻率折線圖, 其中參數n表示折線圖展示的詞匯數, cumulative表示是否對統計結果逐詞累加. 經函數text.dispersion_plot()處理后獲得離散圖, 橫坐標為文本詞匯排序, 縱坐標為研究詞匯, 詞匯對應的每一行代表整個文本, 一行中的一條豎線表示一個單詞, 以豎線的排列表示詞匯在文本中的位置.
3 實證分析
以2018年政府工作報告為案例素材進行分析. 在網絡上通過爬蟲工具得到2018年政府工作報告, 總字數為20 257. 根據本文提出的方法步驟, 使用NLTK對文本內容進行抽取.
3.1 方法描述
對目標素材所在網頁進行內容提取. 使用Scrapy獲取網頁上的報告內容, Scrapy是用于獲取網頁內容的Python第三方模塊, 多用于爬取網頁上的圖片以及結構化的文本內容. 將爬取得到的文本內容保存在txt文件中, 過濾文本中的標點符號、數字與停用詞等.以目標詞匯為中心進行二次分析, 使用到同語境詞查找, 雙連詞查找等方法. 使用概率統計對高頻出現的詞匯進行查找輸出, 最后以折線圖、離散圖等可視化的形式展示結果. 實例分析流程如圖3所示.
在預處理階段, 使用正則表達式清理爬取內容中的符號、數字以及英文字母, 保留中文文本. join(re.findall(r'[u4e00-u9fa5]', raw_text)). 采用 Jieba 中文分詞工具對中文文本分詞jieba.lcut().
分析階段查找 “民生” 所在的句子以及查找與 “發展” 位于相同位置的詞匯:

3.2 結果展示
應用matplotlib對結果進行可視化, 輸出離散圖展示不同高頻詞在文本中的位置:
text.dispersion_plot(['經濟','企業','工作','社會'])
輸出離散圖展示“經濟”, “企業”, “工作”, “社會” 四個詞在文本中的位置, 結果如圖4所示.
對去除停用詞后的文本, 進行頻率統計. 將前20個高頻詞以折線圖的形式輸出, 結果如圖5所示.
在中文文本的分析中, 出現可視化結果無法顯示中文的問題, 對此解決的方法是增加部分代碼, 指定默認中文字體. 命令如下.

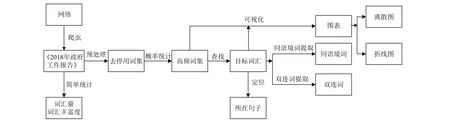
圖3 實例驗證流程圖

圖4 展示不同詞在文本中的位置
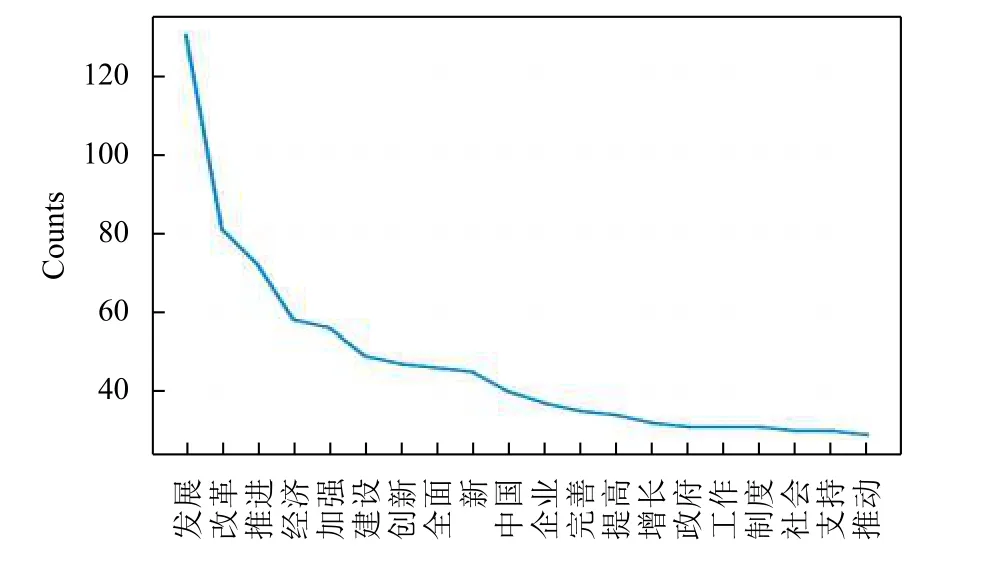
圖5 前20個高頻詞折線圖
3.3 分析與啟示
從概率統計的結果中, 發現提取出的詞匯具有兩個特征: 集中在名詞與形容詞; 詞匯含義與文本主題相關. 從離散圖 (圖 4)來看, “經濟” 一詞的在全文中不同位置均有出現, 且在前一部分相對集中分布; “社會”一詞在報告的全文中均勻分布, 可以看出關注社會、關注經濟體現在整篇工作報告當中. 對比 “改革”與 “社會”, 可以發現“改革”的出現頻度超過“社會”, 也印證了圖5的頻率統計結果. 在高頻折線圖中(圖5)排在前兩位的詞是“發展” 以及“改革”, 這與“進一步深化改革”保持一致; 在前十個高頻詞中“經濟”作為出現次數最多的名詞, 也說明了經濟的重要性. 在報告抽取結果中找到了反映政府工作報告的語料內容, 達到了理解語料庫的目的.
4 結束語
由于中英文文本有不同的分詞方法, 使得NLTK在中文文本處理上存在不足, 中文文本不能通過簡單的字符分隔來達到語義分隔的目的, 需要由分詞工具來完成, 并且可能存在歧義.
本文加入爬蟲工具與NLTK協同作用, 對爬蟲得到的文本使用分詞工具、正則表達式完成對中文文本中詞匯與句子等內容的預處理工作, 并在NLTK中完成對中文文本的統計與分析, 抽取出與主題相關的文本內容, 實現NLTK對中文文本上的處理, 達到對中文文本信息抽取的目的.
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
語文知識(2014年1期)2014-02-28 21:59:13
