基于SVM-BiLSTM-CRF模型的財產糾紛命名實體識別方法①
2019-01-18 08:30:36周曉磊趙薛蛟1劉堂亮宗子瀟王其樂里劍橋
計算機系統應用 2019年1期
關鍵詞:模型
周曉磊, 趙薛蛟1,, 劉堂亮, 宗子瀟, 王其樂, 里劍橋
1(中國科學院大學, 北京 100049)
2(中國科學院 沈陽計算技術研究所, 沈陽 110168)
3(遼寧省人民檢察院沈陽鐵路運輸分院, 沈陽 110001)
4(東北大學, 沈陽 110000)
5(沈陽市第三十一中學, 沈陽 110021)
6(大連理工大學, 大連 116621)
隨著國家法制建設不斷進步, 人們的法律意識不斷增強, 在遇到社會、經濟生活中的糾紛時會自然的訴諸于法律審判. 這類案件雖然簡單易斷, 但由于數量急劇增多使得基層法院承受著十分沉重的工作壓力.因此對于簡單的財產糾紛案件做到自動審判不但可以緩解基層法官的工作壓力使得同類型案件審判一致,更能增強民眾用法律武器維護自身權利的動力. 而財產糾紛案件中命名實體的正確識別是完成自動化審判的非常重要的一步.
命名實體識別的目標是從語料中準確識別出專有名詞或有意義的數量短語并加以歸類[1]. 早期的命名實體識別主要是基于規則和字典的, 這種方法在處理復雜場景時會耗費人們的大量精力而且移植性差. 為了解決這些問題, 又出現了基于機器學習的方法, 但這些方法對特征選取的要求比較高. 而相比于上述的兩類方法, 深度學習方法兼具泛化性和較少依賴人工特征的特點, 因此近年來, 深度學習在通用的命名實體識別領域運用廣泛. CNN-CRF例如: Collobert等[2]提出了一種模型, 在CNN結構上運用CRF算法將標簽轉移得分加入到目標函數中. 在CONLL2003語料上取得了比較好的成績. Huang等[3]通過人工設計拼寫特征提出訓練了一種BiLSTM-CRF模型, 該模型在CONLL2003語料上的F1值達到了88.83%.
財產糾紛裁判文書的關鍵實體主要包括案件涉及的財產形式、財產數額等. 經過分析實際的裁判文書后發現, 難點主要在于: (1)糾紛涉及財產形式多樣.(2)裁判文書中包含法院認定的涉及糾紛的財產在整篇文書中出現比重較小. (3)財產描述形式多樣. 由于BiLSTM-CRF模型在通用領域的效果突出, 于是使用該模型對樣本進行了模型訓練, 但結果發現實際的輸出并不理想. 在分析原因后發現是由于上述第二個難點導致了訓練數據的不平衡. 為了解決這一問題, 本文提出一種基于SVM-BiLSTM-CRF的財產糾紛裁判文書命名實體識別模型. 以提高對財產糾紛裁判文書中涉案財產的識別精度.
1 數據集構建
本文通過從中國裁判文書網下載大量財產糾紛裁判文書, 在進行適當的數據預處理并手工標注后構建財產糾紛的語料庫. 其中一半作為訓練集進行模型訓練, 另一半則作為測試集用于評價模型的性能.
1.1 數據預處理
裁判文書是一種半結構化的文本, 通常的結構如圖1所示.

圖1 裁判文書的結構圖
由于審判結果和審理查明的事實與證據存在直接關系, 所以從審理查明的事實和證據中提取的財產命名實體具有研究價值. 通過統計發現, 在審判文書中描述審理查明的事實的起始句包含以下說明詞: “經審理查明”, “經審理認定”, “經開庭審理查明”, “經開庭審理認定”, “審理中查明”, “審理中認定”, “確定如下事實”,“認定如下事實”, “認定以下事實”, “查明如下事實”,“查明以下事實”, “本案事實如下”, “查明事實如下”,“確定事實如下”等. 同時, 在需要說明的問題部分起始句包含“本院認為”, 審判結果部分起始句包含“判決如下”. 通過這些觸發詞, 將審理查明的事實提取出來進行分句、分詞、去停用詞等處理.
1.2 數據標注
1.2.1 財產類別
我國的《民法通則》對財產有如下定義:財產是指擁有的金錢、物資、房屋、土地等物質財富:國家財產、私人財產, 具有金錢價值、并受到法律保護的權利的總稱[4]. 根據上述定義, 將財產分為三種, 即動產,不動產和知識財產. 據此, 本文將審判案件中涉及的財產分別標注為以下幾個類別:
動產: 由于財產糾紛案件涉及金錢糾紛比例較大,所以將動產的標注類別細分為money與nonmoney.
不動產: 標注為realestate
知識財產: 標注為intelpropert.
1.2.2 四詞位法
在漢語語言文字中, 每個詞都是由一個或多個字組成的. 例如: “現金”是兩字詞, “上轎禮”是三字詞. 組成詞語的每一個漢字在一個特定的詞語中都占據一個特定的構詞位置, 即詞位. 詞位的種類根據研究的需要可以自行定義. 在已有的工作中常用的有四詞位標注集(B、M、E、S)和六詞位標注集(B、B1、B2、M、E、S)[5]. 在本文中, 采用的是四詞位集, 用B表示詞的開始, M表示詞的中部, E表示詞的結尾, O表示其他非財產的字, 并結合財產類別進行標注. 表1是一個標注例子.
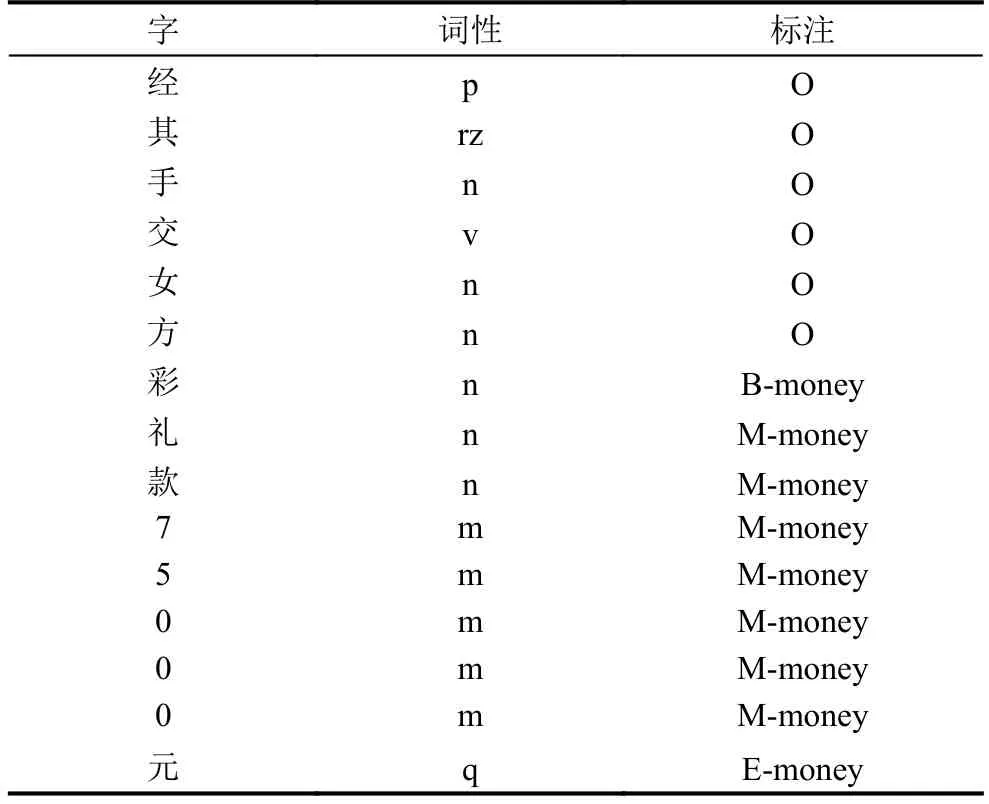
表1 標注實例
2 SVM-BiLSTM-CRF模型
2.1 模型整體框架
SVM-BiLSTM-CRF模型由三個模塊組成: SVM模塊、BiLSTM模塊和CRF模塊. 整體模型框架圖如圖2所示. 首先通過查詢詞向量表將輸入的語句轉換成相應的詞向量序列, 然后輸入SVM進行判斷. 如果不含財產實體, 則將所有的字標記為O, 否則則通過查詢字符向量表獲得相應的字符向量序列. 并將這些字符向量序列輸入BiLSTM進行實體識別. 最后CRF模塊將BiLSTM的輸出進行處理得出一個最優的標記序列.
2.2 SVM模塊
支持向量機(SVM)是在VC維理論和結構風險最小化原理基礎上建立起來的機器學習方法[6]. 它的基本模型是在特征空間中尋找間隔最大化的分離超平面的線性分類器, 在解決小樣本、非線性和高維模式識別問題方面表現出特有優勢[7]. 因此, 為了解決包含財產實體的句子占案件描述句子的比重不高的問題, 本文使用SVM將無用的句子直接篩除, 使得包含財產實體的句子中進行進一步的標注訓練可以保持訓練數據的平衡.

圖2 財產糾紛案件命名實體識別的SVM-BiLSTM-CRF模型
在訓練開始, 首先將訓練樣本經過分詞, 去停用詞,在不影響分類精度的情況下利用tf-idf進行特征降維形成詞向量表=特征維度. 對于一個句子句子長度, 經過詞向量表處理, 形成一個特征向量, 利用核函數與標簽一起加入到式(1)中.
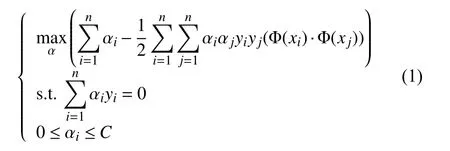
其中,C是懲罰系數,為拉格朗日乘子向量. 這是線性不可分的線性支持向量機的學習問題轉化而成的對偶問題. 但是由于求解復雜度過高, 本文采用SMO算法來進行求解.
SMO是John C. Platt于1996年提出一種啟發式算法, 其思想是要將原問題分解成一系列小規模凸二次規劃問題, 從而獲得原問題最優解的方法. SMO算法在每次迭代時選擇兩個拉格朗日乘子并同時固定其他乘子, 針對選擇的乘子構建一個目標函數值更小的二次規劃問題, 因為子問題可以通過解析方法求解, 所以可以大大提高整個算法的運算速度. SMO算法的偽代碼如算法1.

算法1. SMO算法1) 創建一個并初始化為0向量.2) 當迭代次數小于最大迭代次數時執行循環, 否則跳出循環返回結果.3) 循環遍歷數據集中的每一個數據向量, 如果該向量可以被優化, 則隨機選擇另外一個數據向量, 并同時優化這兩個向量. 如果兩個向量不能被優化, 則退出循環.4) 如果所有向量都沒有被優化, 則增加迭代次數, 進入下一次循環.否則將迭代次數置0, 重新進行迭代.
2.3 BiLSTM模塊
長短時記憶網絡(Long Short-Term Memory, LSTM)是由Schmidhuber于1997年提出的. 它是一種具有特殊結構的RNN網絡, 但是與傳統RNN不同, 它解決了由于序列過長而產生的的長程依賴(long-term dependencies)問題. 網絡模塊示意圖如圖3所示. 其中包含四層神經網絡, 最上面的一條線貫穿所有串聯在一起的LSTM單元, 使得LSTM狀態從第一個單元開始一直移動到最后一個單元, 在這個過程中只存在少量的線性干預和改變. LSTM采用獨特的門結構來控制LSTM單元對信息流中信息的添加和刪減. 門結構一共有三類, 分別是輸入門 (input gates), 忘記門 (forget gates)和輸出門(output gates)[8]. 如果t時刻用、、、分別表示三種門和細胞狀態, 則有:


圖3 LSTM網絡模塊示意圖
而雙向長短時記憶網絡(Bidirectional Long short-Term Memory, BiLSTM), 其原理是將兩個時序方向相反的長短時記憶網絡結構連接到同一輸出, 以此來獲取歷史和未來信息. 因此相比于其他的RNN網絡需要等到后面的時間節點才能獲取未來信息, 該網絡結構可以更充分的利用上下文信息. 我們利用該網絡結構這一優勢, 用LSTM對每個句子進行前向和后向的計算, 然后將得到的兩個結果向量進行拼接得到最終的隱層表示.
2.4 CRF模塊
由于單獨使用BiLSTM生成的結果可能在標注序列并不是全局最優, 為方便后續通過標注提取完整的命名實體, 提高實體識別的正確率和召回率, 所以本文在BiLSTM層上加上一個線性CRF模塊. 通過分析相鄰標簽的關系以獲得一個全局最優的標記序列. 對于一個經過BiLSTM處理后的輸出矩陣P,P的大小是, 其中是句子中包含的詞數,表示標簽的種類.其中為該句第i個詞映射到的非歸一化概率, 然后引入狀態轉移矩陣, 其中表示時序上從第i個狀態轉移到第個狀態的概率, 則對于一個觀測序列的對應的標記序列, 定義分數為:
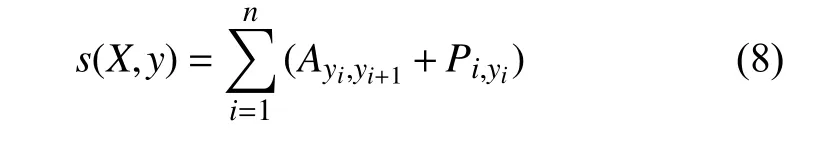
3 結果
3.1 評價指標
本文分別使用準確率、召回率和F1值三個評價指標來對實驗結果進行評價. 三種評價指標的表達式分別為:

其中, 準確率(Precision)為測試樣本中識別正確的命名實體數量占總的命名實體數量的比例. 召回率(Recall)為正確識別為財產命名實體的數目占實際財產命名實體總數的比例.F1值則是當beta為1時對上述兩個評價指標的加權平均.
3.2 實驗比較
為了有效驗證本文提出模型的合理性并證明模型中每個模塊的必要性, 在仿真實驗中得到SVMBiLSTM-CRF模型的相關數據后, 又分別進行了BiLSTM-CRF模型、SVM-LSTM-CRF模型以及SVM-BiLSTM模型在測試集上的性能評價實驗. 并通過整合四次實驗的結果, 進行了數據對比. 對比結果如表2所示.

表2 對比實驗結果(單位: %)
3.3 結果分析
(1) 移除SVM模塊結果分析
由于提取出的財產糾紛案情包含財物命名實體的比例并不大, 所以會有大量標注為O的實體存在, 在未包含SVM模塊的模型中, 訓練得到的模型由于標注為O的實體占比過多, 造成了雖然準確率非常高但是召回率很低的情況. 而本文提出的模型比不包含SVM模塊的模型的F1值高出36%, 精確度高出13%.
充分證明SVM模塊在本模型中的重要作用.
(2) 替換BiLSTM模塊結果分析
從SVM-LSTM-CRF模型與SVM-BiLSTM-CRF模型的結果數據對比中可以看到, 本文所提出的模型比使用LSTM的模型準確度高4%, 召回率高7%. 結果表明雙向長短時記憶網絡通過提取句子的上下文信息, 對結果產生了積極作用.
(3) 移除CRF模塊結果分析
在本文提出的模型中, 線性CRF模塊的主要作用就是根據相鄰標簽之間的關系優化神經網絡輸出的結果標簽. 從實驗數據中可以看到, 有CRF模塊會比無CRF模塊F1高2%, 召回率高4%. 在結果分析中發現,CRF對長度較大或帶有形容詞的實體識別性能較高,諸如“彩禮人民幣九萬九千五百元”、“‘海爾’牌電冰箱一臺”等都能被SVM-BiLSTM-CRF正確識別, 但是SVM-BiLSTM則無法正確識別. 由此可見線性CRF模塊的加入有助于提高模型的識別精度.
4 結論
本文針對財產糾紛審判文書中的財產實體識別問題進行了研究, 提出了通過SVM首先進行篩選判斷是否包含財產實體, 然后通過神經網絡和CRF進行進一步識別的方法. 為了訓練模型和驗證模型的有效性, 構建了裁判文書標注數據集. 實驗最后的結果表明, 本文提出的SVM-BiLSTM-CRF模型在對財產糾紛審判文書中的關鍵實體識別有非常高的準確率和召回率, 從而能夠為后續的財產糾紛審判案例自動判決工作奠定基礎.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
