基于情感文本數據篩選的感知節點選擇機制①
2019-01-18 08:30:40張曉濱黃夢瑩
計算機系統應用 2019年1期
張曉濱, 黃夢瑩
(西安工程大學 計算機科學學院, 西安 710048)
引言
隨著移動智能設備的不斷普及與應用, 使得越來越多的傳感器應用到移動智能設備里, 這樣就使得人們獲取數據的方式越來越多樣化, 群智感知服務的發展也越來越普及. 群智感知服務就類似于一種眾包服務, 是將原來分配給員工做的任務包給擁有移動智能設備的群體進行完成并上傳數據實現感知服務. 當某一項研究需要收集某些數據時, 就會發布一些感知任務, 收到任務的移動感知節點根據需要完成該感知任務并上傳數據, 收集到這些數據的人員對數據進行分析處理, 從而得到研究結果. 在現有的研究中, 有很多關于群智感知應用, 感知問題面臨的挑戰以及解決辦法等方面的研究.
Xu等[1]通過收集和研究現有移動群智感知在社會感知上的應用, 提出并分析了潛在的新應用在未來方向上的一些可能. 當然, 感知應用也需要考慮到用戶成本、網絡壓力、云計算服務器架設、用戶隱私等問題[2]. 在參與者的問題上, 劉琰, 郭斌等[3]針對多感知任務并發的情況下對任務參與者的選擇問題, 提出了三種任務參與者選擇的解決方法, 同時通過實驗驗證, 這三種方法針對不同的情景能夠實現最優的參與者選擇, 達到感知服務的目的. Wang等[4]通過對感知平臺數據傳遞的問題的分析, 提出了端對端的參與者選擇模型, 來實現對參與者的選擇. 這兩者在不同程度上解決了參與者選擇上的問題, 但是基于用戶隱私問題的考慮, 大部分研究者的解決方法是對用戶采取激勵措施來降低用戶對隱私問題的顧慮, 用戶基于激勵與隱私問題的平衡來決定是否參與任務. 因此, 激勵機制是群智感知研究的一個重要問題[5], 吳垚等[5]對群智感知服務做了分析, 同時介紹了4類主要的激勵機制及其核心研究問題. 為了補償用戶參與感知任務的代價, 需要設計一種合理的激勵機制[6], 從而使得能有更多的人能參與到感知任務中. 南文倩等[7]基于感知任務用戶參與度的問題, 提出了基于跨空間的動態激勵模型, 相比較傳統的方法來說, 該方法有效地提高了用戶參與感知任務的積極性, 從而使得感知任務能順利的進行. 為了讓更多的人自愿的參與感知任務, Cai等[8]提出了一種具有多項式時間計算復雜度的近最優算法和一種關鍵的支付方案. 此方法能讓用戶在隱私與激勵上做出平衡, 從而決定參與感知任務. 另外, 為了激勵更多的參與者完成感知任務, Zhang等[9]提出了三種在線反向拍賣的激勵機制, 并取得了很好的成效. 以及Micholia等[10]說明了用戶最終參與和貢獻的不確定性, 同時提出了激勵分配問題和迭代算法, 也取得了不錯的效果.
以上研究中在參與者的選擇問題上做了許多改進,使更多的參與者能夠參與到感知任務中并完成感知任務, 但是對于任務完成的質量卻沒有保證. Luo等[11]針對激勵用戶參與感知任務以及感知數據的真實性問題,采用協同的方式解決了這兩個問題. 在數據傳輸成本問題上, 徐哲等[12]利用感知節點的社會屬性提出了多任務分發算法, 降低了數據傳輸的時間消耗成本, 實現了節點之間的高效感知與通信. Ma等[13]基于感知角度探討了如何利用人類移動的機會主義特征來高效、有效地收集數據. 這三者雖然在數據的可靠性和數據的傳輸收集效率上做了改進, 但并未對數據做出有效的篩選, 因此在后續的數據處理效率上并沒有有效的提高.
另外, 在群智感知的研究中可以利用群智感知收集的數據進行分析與研究, 找到某些數據直接的關聯,從而實現對具體事件的分析. 張佳凡等[14]基于新浪微博進行研究, 根據詞頻變化特征以及熱詞上下文語境能有效的對熱點事件進行區分, 達到事件的感知效果.李靜林等[15]分析了車聯網群智感知服務的三種感知模型, 從而提出了一種有效的感知方法解決了車聯網的高效性與時效性之間的沖突. 以上的大部分研究都是對群智感知的整體問題與挑戰進行的研究與分析, 很少有對于局部的數據的篩選問題進行解決的具體解決方法. 同時, 在傳統的數據篩選問題上都是對基礎數據,如數值數據、統計數據的篩選.
本文主要是針對群智感知環境下的情感文本數據的篩選來進行感知節點的選擇. 首先進行感知網絡模型的構建, 結合遺傳算法, 根據節點攜帶的數據進行分類, 從而根據適應度函數得到節點最終值選擇節點迭代. 同時, 對遺傳算法的復雜度進行了分析. 一般感知服務收集到的數據包含有時間、地理位置以及用戶上傳的文本等信息, 而本文主要是通過篩選出帶有情感詞的文本數據的節點, 對節點所含情感文本數據進行處理, 從而實現后續的情感分析處理. 本文提出的方法在一定程度上減少了不必要的數據獲取以及避免了較大數據量的篩選, 從而實現了數據處理效率的提高.
1 感知網絡模型
本文是利用混合群智感知服務對基于情感文本數據篩選的感知服務節點選取機制進行的研究.
圖1是混合群智感知服務的模型圖, 任務發布機構進行感知任務的發布, 任務發布之后由感知中心進行任務的分解發布給各個感知節點, 感知節點需要在感知中心進行注冊才能進行感知任務的參與和完成.感知節點完成感知任務上傳感知數據, 感知中心是對在感知中心進行注冊的感知節點上傳的數據進行處理,將數據進行集成并將數據報告上傳至任務發布機構.由于該機制是混合式的群智感知服務, 所以每個感知節點也是服務節點, 也有對數據的處理能力, 當處理能力不夠就需要在感知中心進行注冊讓感知中心進行處理. 在進行感知任務時都需要對感知節點進行選取, 本文主要是采用遺傳算法對感知節點進行選擇, 實現對特定情感文本數據的高效處理.

圖1 混合群智感知服務模型圖
2 感知節點集選擇
2.1 基于遺傳算法的編碼機制
在參與感知的服務節點集中選取符合條件的節點進行感知服務, 首先對節點進行編碼, 本文采用遺傳算法的編碼機制, 采用常用的二進制編碼. 現有服務節點集里面包含m個服務節點, 即每個節點攜帶m個數據信息, 即, 當節點被選取就將其歸到服務節點集 中, 同時將對應位置的數據信息標記為1, 否則標記為0,即:

2.2 適應度函數
在遺傳算法中需要采取適應度函數對群體中的個體進行定量篩選, 然后根據適應度函數值的大小決定該個體是否淘汰. 本文是基于情感文本的數據篩選, 所以在節點信息攜帶的過程中本文主要考慮以下幾個方面:
(1)節點攜帶的信息數據類型. 定義數據類型t, 取值為1和0. 當t=1時表示數據類型為文本類型, 當t=0時表示數據類型是非文本類型.
(2)節點攜帶的文本信息的內容是否包含情感詞.定義文本標記s, 取值為1和0. 當s=1時表示文本包含情感詞, 當s=0時表示文本不包含情感詞.
(3)節點攜帶信息內容中包含情感詞的多少. 用c表示表示包含情感詞的數量.
結合以上三個方面的考慮, 對適應度函數的設計如下:
(1)節點聯合攜帶文本數據概率. 節點聯合攜帶文本數據概率是指節點服務集中被選定的節點攜帶的信息數據中至少有一個是文本數據, 用T表示.

(2)聯合包含情感詞概率. 聯合包含情感詞概率是指節點服務集中被選定的節點攜帶的文本信息中至少有一個文本信息中包含情感詞, 用表示.
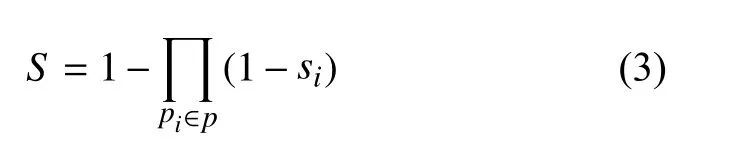
其中,
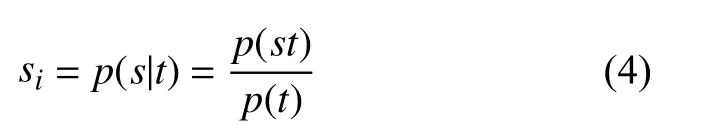
(3)節點聯合情感詞數. 節點聯合情感詞數指節點服務集中被選定的節點攜帶的文本信息中包含情感詞數量的平均值, 用表示.
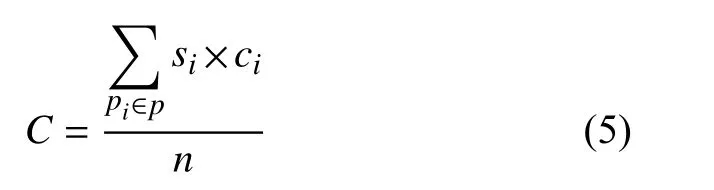
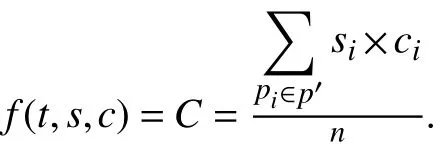
3 遺傳算法分析
3.1 遺傳算法優化過程
根據第二節提到的編碼機制和適應度函數, 基于遺傳算子操作設計的遺傳算法及其優化過程如下:
1)隨機產生M個初始個體;
2)根據式(2)-式(5)計算種群中各個個體的適應度函數值, 并判斷是否達到最大迭代次數, 若滿足終止條件, 則輸出結果, 否則, 執行步驟 3);
3)根據種群中各個個體的適應度函數值, 依此執行選擇, 交叉, 變異遺傳算子, 產生新的種群, 并執行步驟2).
具體的算子選擇如下:
1)在進行選擇操作時采用比例選擇算子, 該算子是指個體被選中的概率與適應度函數值是成正比的,即在輪盤選擇的時候, 適應度函數值越大的, 在盤面上的刻度越長.
2)交叉算子是通過交換個體之間某個基因從而產生新個體的過程. 在對父個體進行的重組操作采用的是單點交叉算子, 從而使得選取的節點冗余比較少.
3)變異運算采用基本位變異算子, 該算子是最簡單的變異算子, 即是在某一個基因位上取反操作. 在變異的操作過程中需要選擇合適的迭代次數, 從而得到最優解.
3.2 遺傳算法復雜度分析
復雜度分析包括時間復雜度分析和空間復雜度分析, 在這里忽略空間復雜度的分析, 只分析時間復雜度.遺傳算法的時間復雜度可以認為是算法的平均計算時間, 即是求適應度函數最優值的平均計算時間.
N個個體的初始化種群, 記為, 經過重組后產生的新種群記為,中的每個個體每一位以概率p取反, 產生新個體, 得到種群, 最后從中選取N個最好的個體組成下一代種群, 重復以上重組和變異操作, 直到選出滿足條件的個體結束.
4 實驗驗證
4.1 實驗準備與操作
實驗選取100個愿意上傳移動應用數據的志愿者進行實驗, 使用Matlab實現. 志愿者的年齡范圍在20~50之間, 男女比例1:1. 每個志愿者相當于一個個體, 代表著感知節點, 每個個體在100×100區域內隨機分布. 計算每個個體中每個基因是文本數據的概率, 包含情感詞的概率 和包含情感詞的數量 的值. 根據這些值算出每個個體的適應度函數值, 并將函數值降序排列, 選出前N個個體作為候選感知節點.
設置遺傳算法程序運行的參數, 初始化的種群個體數M=20, 終止進化迭代次數G=500, 交叉操作的交叉概率Pc=0.3, 變異操作的變異概率Pm=0.06, 運行程序得到實驗程序選出的個體. 再將選出的個體中的包含的文本信息數據整理出來, 同時記錄實驗所需的時間和數據量, 最后將實驗中單位時間內處理的數據量進行歸一化, 即是實驗中的數據處理效率指標. 因此實驗分為兩部分: 一是對節點的選取, 二是對選取的節點攜帶的數據進行處理. 所以, 實驗的總時間就是這兩部分時間的總和. 數據處理效率指標也就是整個實驗的處理效率指標. 另外, 算出選擇出的節點攜帶的有效數據占比, 即是文本類型又包含情感詞的數據占比.
對于傳統方法本文采用隨機選擇算法進行實驗,對于節點的選取是直到選擇符合數量的感知節點為止.后面的對數據處理的方法和本文中所用的數據處理方法一致.
4.2 實驗結果與分析
圖2是在迭代次數、交叉概率和變異概率相同,初始化種群個體數不同的情況下, 傳統的數據處理與使用本文提出的算法進行的數據處理的對比. 圖2(a)節點選取時間的倒數與初始種群個體數關系, 由圖可以看到隨著初始化種群個體數的增加, 兩種方法在節點選取所需時間上的差距越來越小, 雖然在節點選取上本文方法在時間上會有一點延時, 但是由圖2(b)可以看出, 兩者的整體處理效率上本文方法相對較好, 并且隨著初始化種群個體數的增加, 兩者的整體處理效率相差越來越明顯, 在初始化種群個體數達到90時, 差距達到最大, 相差27.6%. 因此, 該方法能夠有效的節省數據的處理時間.
圖3是在初始化種群個體數為20、交叉概率為0.03和變異概率為0.06, 迭代次數不同的情況下, 傳統的數據處理與使用本文提出的算法進行的數據處理的對比. 圖3(a)是選取的感知節點個數與迭代次數之間的關系圖, 圖3(b)是數據處理效率與迭代次數對應選出的感知節點數之間的關系圖. 由圖3(a)可以看出, 隨著迭代次數的增加, 節點選取的數量逐漸趨于穩定, 即在迭代次數達到700時, 最優的感知節點個數一定. 當最優感知節點個數達到一定時, 需要處理的數據量就是最優感知節點攜帶的數據量, 所以由圖3(b)可以看出, 在迭代次數達到700時, 數據處理的效率時趨于穩定的. 同時圖3(b)可以看出, 使用本文提出的方法, 數據處理的效率優于傳統的數據處理的效率. 圖4是在迭代次數、交叉概率和變異概率相同, 初始化種群個體數不同的情況下, 傳統的數據處理的有效數據占比與使用本文提出的算法進行的數據處理的有戲數據占比的對比. 由圖4可以看出, 隨著初始化種群個體數的增加, 兩種方法的有效數據占比相差越來越明顯, 在初始化種群個體數達到90時, 差距達到最大, 相差21%. 實驗表明, 該方法能夠有效的提高獲取的數據的有效性.
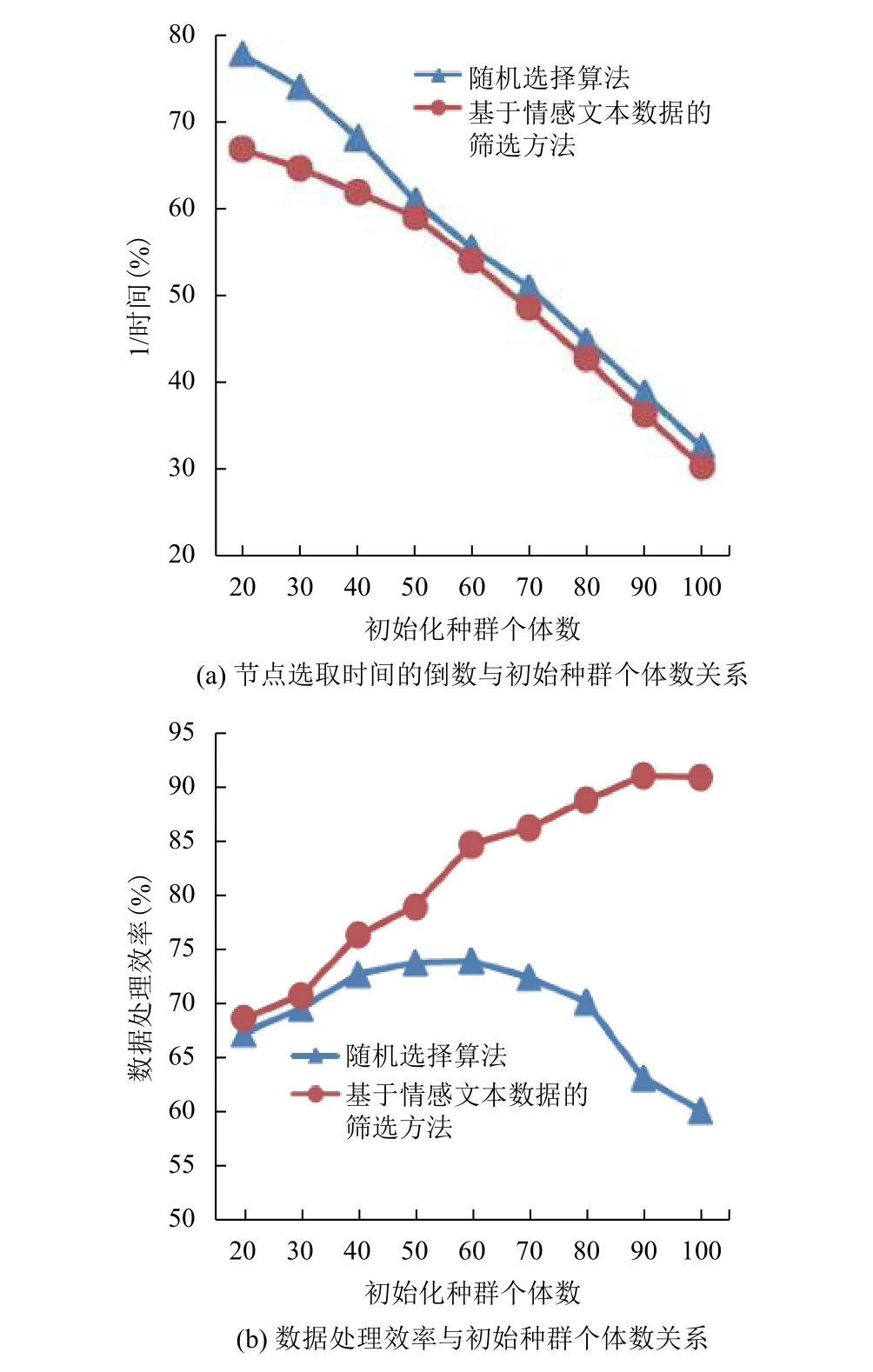
圖2 感知節點評價指標與初始種群個體數關系
5 結束語
本文通過對感知環境下節點數據的獲取方法的分析, 提出了一種新的針對基于特定的情感文本數據篩選的節點選擇機制. 基于遺傳算法的優化選擇過程, 得到所有節點集中符合優化條件的節點集, 從而實現感知服務對數據的獲取. 實驗結果表明, 本文提出的方法減少了對不必要數據的獲取, 從而減少了在后續的數據處理的工作量, 能夠提高對整體數據進行分析的效率. 在后續的研究中, 還需要根據實際情況考慮到遺傳算法中遺傳算子的選擇問題, 實現對算法的進一步優化.
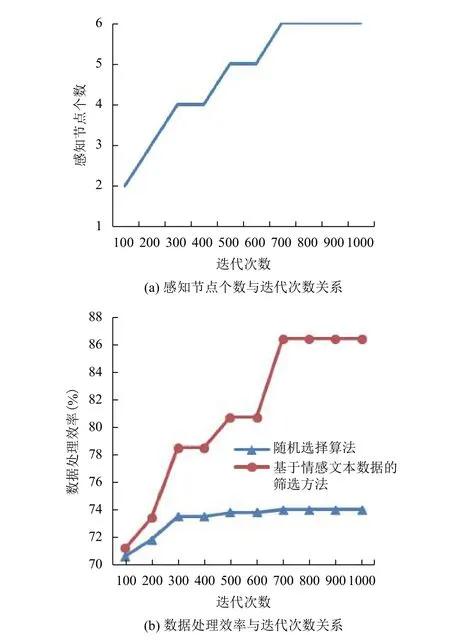
圖3 感知節點評價指標與迭代次數關系
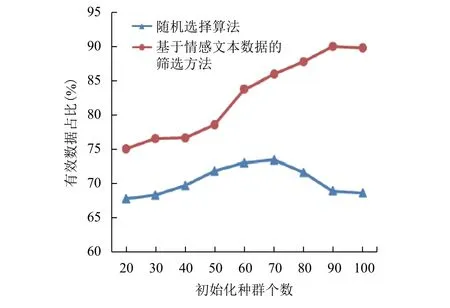
圖4 有效數據占比與初始種群個體數關系
猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
小學教學參考(2015年20期)2016-01-15 08:44:38
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
