文本分類中基于CHI改進的特征選擇方法*
2019-01-15 05:02:20宋呈祥陳秀宏
傳感器與微系統(tǒng) 2019年2期
宋呈祥, 陳秀宏, 牛 強
(江南大學 數字媒體學院,江蘇 無錫 214122)
0 引 言
合理的特征選擇,不僅可以降低文本特征維度,還能降低分類時間復雜度,提高分類效果[1]。近年來,越來越多的特征選擇算法涌現,這些方法大多數都是基于頻率或者概率對特征詞進行權重計算,并根據排名選取TOP-K特征詞。卡方統(tǒng)計量(Chi-square statistics,CHI)是一種常用的特征選擇方法,具備更低的時間復雜度和應用便利性[2],其統(tǒng)計特征詞在文本中是否出現,但沒有考慮詞頻和特征詞分散度、集中度等信息。Galavotti L等人[3]通過研究特征詞與類別的正負相關性問題,引入一種新的相關系數方法對CHI模型進行優(yōu)化,使得模型性能有了一定的提高。Jin C等人[4]使用樣本方差計算詞的分布信息,并考慮最大詞頻信息來改進CHI方法,在三個數據集上均取得較好的結果。葉敏等人[5]通過在CHI特征選擇算法中引入分散度、頻度等特征因子,并考慮位置和詞長信息改進詞頻-逆文本頻率(term frequency-inverse document frequency,TF-IDF)賦權公式,提出一種用來描述特征詞的權重分布情況的特征選擇算法,提高特征詞的類別鑒別能力。高寶林等人[6]通過引入類內和類間分布因子,提出基于類別的CHI特征選擇方法,減少了低頻詞帶來的干擾,并且降低了特征詞在類間均勻分布時對分類帶來的負貢獻。袁磊[7]考慮不均衡文本長度的影響,對特征詞頻進行歸一化處理,同時融合特征詞的類別信息,提出了一種改進CHI特征選擇算法。但這些方法都沒有考慮分布在少數文本集合的高頻特征詞。
由于傳統(tǒng)CHI方法是在全局范圍內進行特征選擇而未考慮特征詞頻信息,且沒有考慮特征詞的出現與類負相關的情況,故本文提出一種新的基于CHI特征選擇方法,考慮位置特性而改進TF-IDF權重計算公式,并分別使用支持向量機(support vector machine,SVM)和樸素貝葉斯(naive Bayes)方法對文本分類。實驗結果表明,該方法分類效果優(yōu)于傳統(tǒng)CHI方法和文獻[6]的方法。
1 相關概念與方法
1.1 CHI
CHI是用來衡量特征詞tk和類別ci之間的相關聯(lián)程度。假設tk和ci之間符合具有一階的自由度χ2分布,則tk與ci的CHI值定義為[2]
(1)

(2)
式中m為類別數目。
1.2 特征權重計算
特征選擇后需計算各特征詞的權重大小,以衡量某個特征詞在文本中區(qū)別能力的強弱。TF-IDF是一種經典的特征權重計算方法,在信息檢索占有重要地位[8],其計算公式如下
(3)
式中nij為特征詞wi在第j篇文本中出現的頻度,|Dj|為第j篇文本的長度,n為文本集的文本總數,df(wi)為文本集中出現特征詞wi的文本數目。如果一個詞在某篇文本出現的次數多且在其他文本中包括該詞的文本數少,那么其就越和該文本主題相關,區(qū)分能力也就越強[9]。為了消除文本長度對TF-IDF值的影響,一般將其進行歸一化處理。
2 改進的文本分類方法
2.1 基于位置改進的TF-IDF權重計算公式
傳統(tǒng)的TF-IDF公式在計算特征詞權重時只考慮詞頻和包含它的文本數量,沒有考慮特征詞出現的位置,然而特征詞的位置信息從某種程度也反映了其重要性。如果特征詞出現在文本的標題、摘要或者關鍵詞處,則其應該獲得更高的權重。于是,改進的頻度 (稱為位置頻度,pos_n)為
pos_nij=nij×(1+log2(T(wi)+1))
(4)
式中T(wi)為特征詞wi出現在標題、摘要或者關鍵詞處的總次數。當T(wi)=0時,pos_nij=nij,該式值即為傳統(tǒng)的特征詞頻度。式(4)表明,如果一個特征詞在標題、摘要、關鍵詞出現的次數越多,那么它的權值應越高,也就越重要。將式(4)替換式(3)中的nij,便可得到包含特征詞位置的改進TF-IDF權重公式位置 TF-IDF (position TF-IDF,PTF-IDF)
(5)
2.2 CHI的優(yōu)化

針對傳統(tǒng)CHI全局特征選擇以及未考慮詞頻信息等問題,考慮特征分布系數(feature distribution coefficient,FDC)如下
(6)

(7)
式中N(tk,ci)為類ci出現特征tk的文本數,N(tk)為文本集中出現tk的文本總數,m為類別數。于是,當類ci中出現特征tk的文本數小于平均每個類中出現tk的文本數時,NCF值為負數,CHI值就會是負數,此時刪除與類ci負相關的特征即可避免負相關對分類的影響。最后給出改進的特征選擇公式IMPCHI(improved CHI)為
IMPCHI(tk,ci)=CHI(tk,ci)FDC(tk)NCF(tk,ci)
(8)
綜上所述,得到以下改進的特征選擇和權重計算的文本分類算法流程:
1)文本預處理。文本預處理包括詞性標注、去除特殊符號以及停用詞;只保留名詞、動詞和形容詞等重要詞語,獲取文本詞語(標題、關鍵詞、摘要、正文和類別)集合。
2)特征選擇。使用本文算法計算訓練集文本詞語集合和每個類別的NCF,CHI,FDC值,得到每個詞和對應類別的IMPCHI值;對于重復的詞,取最大值作為該詞最終的IMPCHI值。將每個詞按IMPCHI降序排序,根據語料文本特征選取TOP-K作為整個語料集的特征詞集合。
3)權重計算。對于每篇文本的詞語集合,若步驟(2)的特征詞集合含有該詞,使用考慮特征詞位置特性的PTF-IDF賦權公式計算該詞的權重,構造文本特征向量。
4)分類器訓練。利用步驟(3)得到訓練集文本特征向量,并訓練分類器。
5)測試分析。將測試集分別進行步驟(1)、步驟(3)處理獲取測試集文本特征向量,并對步驟(4)得到的分類器測試評估,輸出實驗結果。
3 實驗與結果分析
實驗數據利用網易新聞語料庫和復旦大學中文語料庫,其中網易新聞語料庫包括汽車、文化、經濟、醫(yī)藥、軍事和體育六個大類,隨機選取每個類別的300篇文本,以2∶1的比例組成訓練集和測試集;復旦大學中文語料庫,隨機選取的訓練集和測試集文本數量如表1。

表1 復旦大學中文語料庫訓練集和測試集的選取情況
實驗中,使用中科院NLPIR[10]工具對語料進行預處理。實驗分別采用TF-IDF和PTF-IDF公式對特征選擇后的特征詞計算其權重;并利用臺灣大學的Chang Chih-chung教授等人[11]開發(fā)的線性核函數SVM分類器和Weka平臺Naive Bayes分類器[12]對語料文本進行分類。
實驗性能評估使用宏F1值 (macro_F1)來度量所有類別的總體分類指標
(9)
式中m為類別個數;Pi,Ri分別為ci類的查準率(Precision,P)和查全率(Recall,R);macro_P為宏查準率;macro_R為宏查全率。
實驗中各個方法表示為:E1為傳統(tǒng)CHI特征選擇+TF-IDF權重計算的實驗;E2為傳統(tǒng)CHI 特征選擇+PTF-IDF權重計算的實驗;E3為文獻[6]提出的C-ICHI方法+TF-IDF權重計算的實驗;E4為IMPCHI特征選擇 +TF-IDF權重計算的實驗;E5為IMPCHI特征選擇 +PTF-IDF權重計算的實驗。
3.1 在不同語料庫上的SVM分類實驗
在不同語料庫的SVM分類對比實驗結果如圖1。

圖1 不同特征維度的SVM分類宏F1值
可見,當特征集合維度增大時,宏F1值也隨著變大。在網易新聞語料庫中,特征維度1 500時,E5達到宏F1值最大值87.46 %,但E1此時宏F1已經下降,E4,E5雖然宏F1值也在輕微下降,但E1,E3下降更加明顯,表明本文提出的IMPCHI方法更加穩(wěn)定,綜合性能更好。在復旦大學新聞語料庫中,特征集合維度2 500時,達到86.27 %的宏F1值,E5比E1,E3分別高出4.31 %,1.47 %,但是當特征集合維度繼續(xù)增大時,因為特征詞集合含有很多冗余特征,致使宏F1值變小。E3引入類內和類間分布因子等因素,雖然宏F1值比E1高,但低于E4,E5。因為在特征選擇時,對于位置特性、一些大量分布于少量文本集的特征等因素,對于提升CHI特征選擇的分類性能不可忽視。在計算特征權重時,本文提出的PTF-IDF權重公式,考慮特征詞位置權重,出現的位置越重要,得分越高,網易新聞語料庫和復旦大學中文語料庫中E2比E1分別提升平均1.19 %,2.85 %的宏F1值。PTF-IDF單純考慮位置特性不能達到理想的分類效果,使E2結果不如E3和E4方法。
在網易新聞語料庫和復旦大學中文語料庫中,在宏F1值分別達到最大值時分析各個類別的宏F1值,如表2、表3。各個類別宏F1值差別明顯,原因是不同文本長度對于結果的影響,如果文本較短,含有很多空值,使向量稀疏,造成分類結果較低。若文本含有詞數較多,并含有一些類別區(qū)分度高頻詞語,使宏F1值較大,本文提出的方法能有效改善傳統(tǒng)CHI和TF-IDF的缺陷,過濾掉低頻詞語,改善不同特征詞的權重,使得分類效果更好,性能更穩(wěn)定。

表2 網易新聞語料庫中特征維度1500時的不同類別的SVM分類宏F1值 %
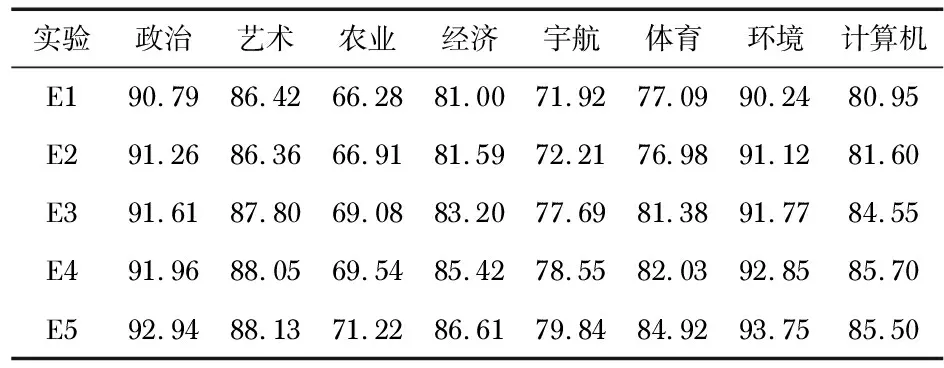
表3 復旦大學中文語料庫中特征維度2500時不同類別的SVM分類宏F1值 %
3.2 在復旦語料庫上的Naive Bayes分類實驗
為了驗證本文方法在不同分類器的可行性,Naive Bayes分類對比實驗結果如圖2所示。

圖2 復旦中文語料庫中不同特征維度的Naive Bayes分類宏F1值
由圖2可得,隨著特征維度增大,宏F1值變化比較平緩;在特征維度3 000維時,E5達到86.98 %宏F1值,而E3在2 500維達到最大值84.79 %。同時,還驗證了本文提出的方法在不同分類器上都是可行的。
4 結束語
特征選擇在文本分類過程中具有重要作用。本文提出了一種改進的CHI統(tǒng)計特征選擇方法,同時提出修正因子解決特征詞與類別負相關的困擾,并將改進后TF-IDF的權重計算方法用于特征詞的權值計算,使其分類效果有了明顯提高。在后續(xù)工作中,將考慮特征詞的語義關系,進一步進行特征降維,在減少算法時間復雜度的同時提高分類效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
