簽到數(shù)據(jù)的熱點(diǎn)區(qū)域時空模式與情感變化的可視化分析
2018-10-26 02:23:14魏寶樂周怡帆李英姿
小型微型計算機(jī)系統(tǒng) 2018年9期
蔡 莉 ,潘 俊 ,魏寶樂,周怡帆 ,李英姿
1(復(fù)旦大學(xué) 計算機(jī)科學(xué)技術(shù)學(xué)院,上海 201203)2(云南大學(xué) 軟件學(xué)院,昆明 650091)
1 引 言
當(dāng)今社會,互聯(lián)網(wǎng)已經(jīng)演變?yōu)闊o所不在的計算與信息共享的平臺.隨著計算機(jī)技術(shù)與互聯(lián)網(wǎng)技術(shù)的快速發(fā)展,微博、博客、在線社交網(wǎng)站以及論壇等網(wǎng)絡(luò)應(yīng)用迅速發(fā)展.人們使用互聯(lián)網(wǎng)的方式從簡單的信息搜尋和網(wǎng)頁瀏覽逐漸演變?yōu)榛诨ヂ?lián)網(wǎng)的社會關(guān)系的構(gòu)建和維護(hù),信息交流與共享.特別是Twitter作為知名的微博應(yīng)用從2006年在美國上線以來,基于互聯(lián)網(wǎng)的社交媒體在全球范圍內(nèi)迅速發(fā)展[1].如今,微博作為一種分享和交流平臺,因其具有原創(chuàng)性、時效性、簡潔性和平臺開放性,吸引了數(shù)量龐大的用戶群體.每天都有大量的微博內(nèi)容在互聯(lián)網(wǎng)上發(fā)布和傳播,其傳播信息的實時性和快捷性使得微博已經(jīng)超越報紙、電視等傳統(tǒng)媒體,成為人們獲得信息的一種主要方式.
近年來,對于微博數(shù)據(jù)的挖掘受到了學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注,微博數(shù)據(jù)可以反映社會的真實縮影,具有很高的研究價值.微博平臺提供了API接口,研究人員和開發(fā)人員可以方便地獲取微博數(shù)據(jù),并基于這些數(shù)據(jù)開展相關(guān)研究.
可視化分析是一門結(jié)合了計算機(jī)圖形學(xué)、心理學(xué)、數(shù)據(jù)挖掘技術(shù)和人機(jī)交互技術(shù)等技術(shù),以可視交互界面為基礎(chǔ)的分析推理的綜合性學(xué)科[2].近十年來,可視化分析技術(shù)依托計算機(jī)視覺、計算機(jī)圖形學(xué)、圖像處理、人機(jī)交互和分布式技術(shù)得到迅速發(fā)展.人們通過可視化分析技術(shù)可以快速有效的從海量數(shù)據(jù)中整合信息,檢驗預(yù)測從而探索未知的知識[3].
最近幾年,國內(nèi)外對于海量微博數(shù)據(jù)的挖掘和可視化方面都取得了一些進(jìn)展和成果.在微博數(shù)據(jù)的情感分析與主題挖掘方面,Davidiv等人[4]基于Twitter上的數(shù)據(jù),利用50個推特標(biāo)簽和15種情緒符號作為情感標(biāo)簽提出了一種有監(jiān)督的分類器,可以將推文劃分為多種情感類型.Shen Yang等人[5]將情感詞分類,建立了一個包含1342個詞的態(tài)度詞權(quán)重字典,同時還構(gòu)建否定詞、程度詞和感嘆詞詞典等來分析微博的情感傾向性,最終得到每一條微博的情感指數(shù).Bermingham等人針對微博的短文本特性,研究了微博中的情感分類技術(shù).Diakopoulos等人[6]研究了2008年美國大選時總統(tǒng)候選人演講辯論后用戶發(fā)布的推文,依靠這些數(shù)據(jù)分析選民情感.Jo 等人[7]首先提出了SLDA(Sentence-LDA)模型來發(fā)現(xiàn)評論的主題,在此基礎(chǔ)上提出ASUM模型,兩種模型用于細(xì)化分析來自電子產(chǎn)品和餐廳評論中的情感.王振飛等人[8]針對現(xiàn)有微博研究中情感分析對象較為單一的問題,通過面向多維關(guān)聯(lián)的數(shù)據(jù)進(jìn)行情感分析,融合微博主題擴(kuò)散度和主題情感傾向得到微博主題的輿情值,增強(qiáng)結(jié)果的有效性.
可視化方面,王臻皇等人[9]開發(fā)了面向微博主題的可視分析系統(tǒng),該系統(tǒng)結(jié)合了微博數(shù)據(jù)的特點(diǎn),引入微博用戶與時間因素,支持分析者從多角度對微博主題進(jìn)行全面分析.Eddi Starbird 等人[10]利用 Twitter 上的信息,通過時間線來了解紅河洪災(zāi)的發(fā)展.Panpan Xu等人[11]設(shè)計了一個擴(kuò)展主題競爭模型用于描述社交媒體上各種意見領(lǐng)袖在多個主題間的競爭,他們采用時間線視圖和主題河流的可視化形式來表現(xiàn)每個主題競爭力的增加和衰減,并利用2012年美國總統(tǒng)選舉和占領(lǐng)華爾街運(yùn)動兩個事件來驗證可視化分析的有效性.
上述研究往往更關(guān)注Twitter數(shù)據(jù)或者微博數(shù)據(jù)的文本特性而忽略其空間特性.簽到數(shù)據(jù)是一類包含較為精確的時空屬性和用戶文本的特殊微博類型.當(dāng)用戶到達(dá)某一個POI點(diǎn)時,他們可以在該位置簽到并寫下此刻的心情和感受.利用這類數(shù)據(jù),研究者一方面可以分析用戶簽到特別頻繁的POI點(diǎn)和區(qū)域,發(fā)現(xiàn)簽到地點(diǎn)的偏好,從而探索城市的熱點(diǎn)區(qū)域;另一方面,由于每個簽到點(diǎn)都有用戶文本,利用這些文本進(jìn)行情感分析就能挖掘出用戶對這些POI點(diǎn)的特定情感,如正面情感還是負(fù)面情感.對于情感的分析能讓POI點(diǎn)的所有者(如:商家、政府機(jī)構(gòu)等)及時獲得用戶評價和滿意度,更好地改進(jìn)服務(wù)質(zhì)量.鑒于此,本文以簽到數(shù)據(jù)為研究對象,利用聚類算法和文本挖掘算法分析簽到數(shù)據(jù)的時空信息和文本信息,并借助Web可視化方法開發(fā)了一個名為CIDVis的可視化系統(tǒng),該系統(tǒng)可以幫助分析者了解微博用戶簽到的熱點(diǎn)區(qū)域和用戶的情感趨向以及關(guān)注的熱點(diǎn)主題.
2 CIDVis框架概述
本文提出的CIDVis可視化系統(tǒng)框架如圖1所示.CIDVis系統(tǒng)主要由數(shù)據(jù)采集與預(yù)處理、簽到熱點(diǎn)區(qū)域挖掘、情感分析及主題挖掘和可視化分析4個模塊組成.數(shù)據(jù)采集與預(yù)處理模塊的功能包括:1)通過新浪微博API接口獲取簽到數(shù)據(jù);2)對簽到數(shù)據(jù)進(jìn)行質(zhì)量評估發(fā)現(xiàn)有問題的數(shù)據(jù);3)執(zhí)行數(shù)據(jù)清洗,刪除錯誤數(shù)據(jù)和重復(fù)數(shù)據(jù);4)將簽到數(shù)據(jù)劃分為位置數(shù)據(jù)和文本數(shù)據(jù)兩個部分.
簽到熱點(diǎn)區(qū)域挖掘模塊的功能為:1)利用本文提出的AC-DBSCAN算法對位置數(shù)據(jù)進(jìn)行聚類;2)根據(jù)聚類結(jié)果發(fā)現(xiàn)簽到熱點(diǎn)區(qū)域并分析其時空特性.
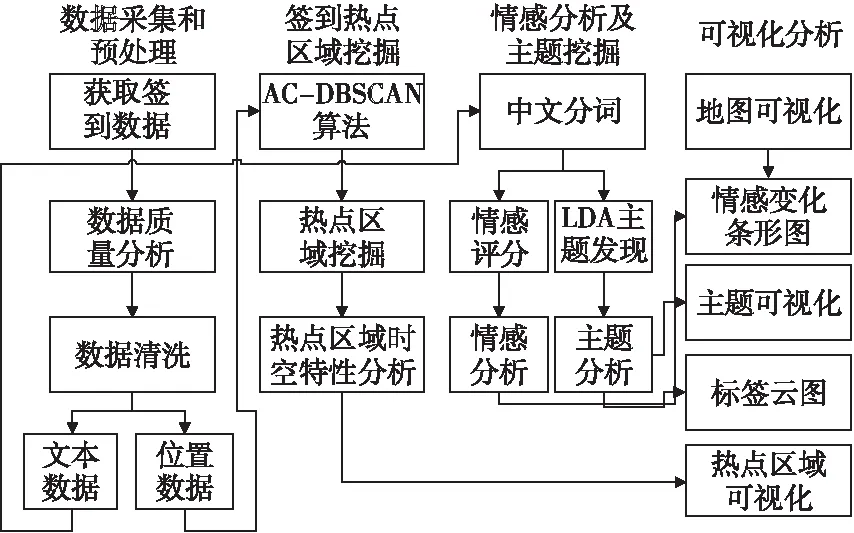
圖1 CIDVis系統(tǒng)架構(gòu)圖Fig.1 Architecture of CIDVis visualization system
情感分析及主題挖掘模塊的功能可劃分為:1)對文本數(shù)據(jù)執(zhí)行中文分詞操作,在分詞過程中會涉及詞典加載,刪除停用詞等步驟;2)將分好詞的文本進(jìn)行特征值提取并進(jìn)行情感評分以及情感傾向分析;3)運(yùn)用LDA主題發(fā)現(xiàn)模型研究微博用戶簽到文本中的主題內(nèi)容.
可視化模塊的功能為:1)加載百度地圖;2)繪制情感變化分析的條形圖,直觀地反映用戶的情感變化;3)按時間軸展示主題模型,并繪制詞頻標(biāo)簽云,展示微博用戶討論的熱點(diǎn)主題;4)將熱點(diǎn)區(qū)域加載到百度地圖上,展示不同時段下熱點(diǎn)區(qū)域的空間演變.
3 城市熱點(diǎn)挖掘
城市熱點(diǎn)區(qū)域是指交通需求旺盛、人流量較高、公共配套設(shè)施比較完善或者商業(yè)較發(fā)達(dá)的區(qū)域,也是居民出行聚集程度的體現(xiàn)[12].本節(jié)采用優(yōu)化參數(shù)選擇的AC-DBSCAN聚類算法來處理簽到數(shù)據(jù),挖掘其中蘊(yùn)含的熱點(diǎn)區(qū)域.作為經(jīng)典的基于密度的聚類算法,DBSCAN算法面臨著參數(shù)難以選擇的問題[13].盡管很多文獻(xiàn)針對其參數(shù)Eps及MinPts的選擇方法做了一定的研究,但結(jié)果還不夠理想.本文提出了一種基于截斷距離的參數(shù)自適應(yīng)方法,稱之為AC-DBSCAN.它無需人工參與確定參數(shù),而且與具體領(lǐng)域無關(guān).
截斷距離是指從排好序的距離序列中選出的一個距離值,本文用符號DC表示.基于截斷距離的參數(shù)選擇方法可以劃分為三個階段:1)數(shù)據(jù)集樣本的距離計算;2)距離值集合排序;3)根據(jù)數(shù)據(jù)占比來確定Eps和MinPts參數(shù).該方法的具體步驟如下:
Step1.對數(shù)據(jù)集S={s1,s2,…,sn}中的每一個數(shù)據(jù)點(diǎn)與其他n-1個數(shù)據(jù)點(diǎn)進(jìn)行距離運(yùn)算,得到由n(n-1)個距離值組成的集合K.
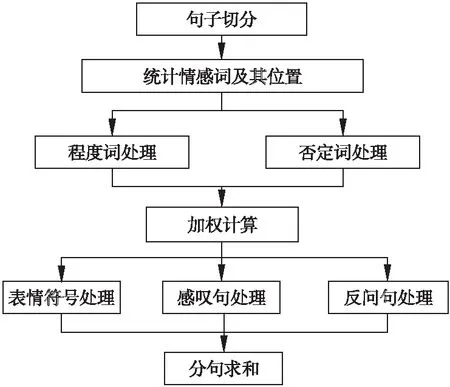
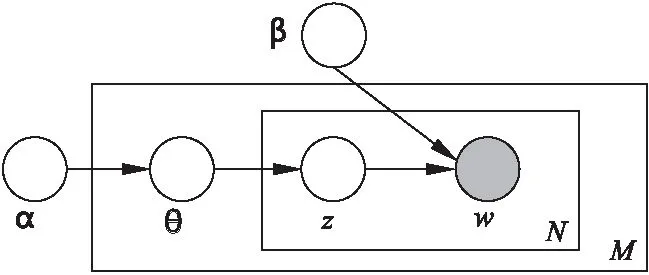
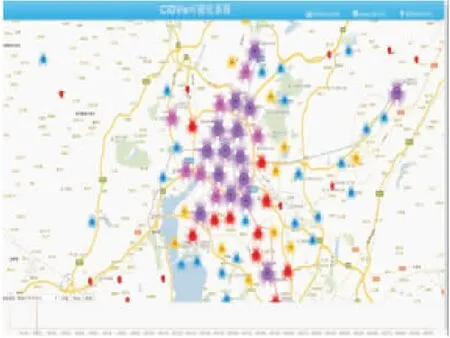
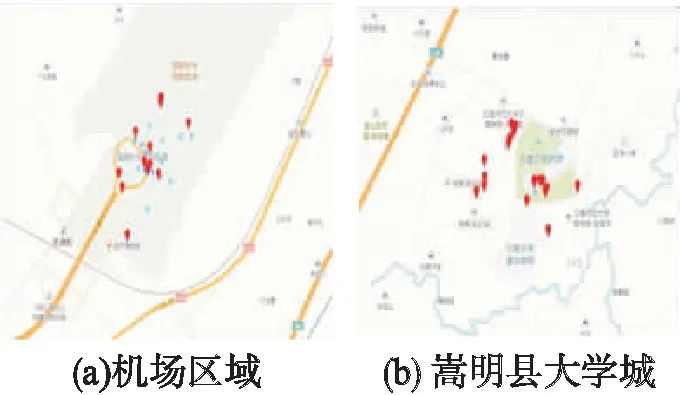
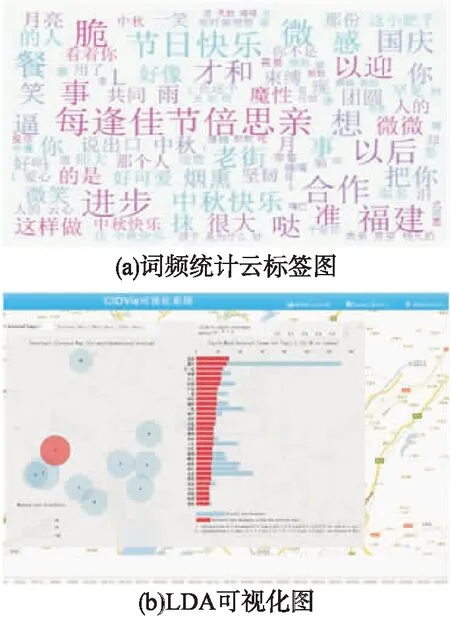
Step2.集合K中雖然有n(n-1)個元素,但是其中有一半是重復(fù)的,原因在于每個數(shù)據(jù)點(diǎn)計算了兩次.將K中的元素定義為dij(i Step3.將DC取值為dk,k∈{1,2,…,m},在距離集合K中,滿足dij Step4.將上一步得到的比例k/m定義為t,如果知道t值,就能得到k=mt,并求得DC. 確定好兩個參數(shù)后,繼續(xù)使用DBSCAN算法完成后續(xù)的熱點(diǎn)挖掘. 情感傾向反映了主體對某一客體所表現(xiàn)出的內(nèi)心喜惡,是一種內(nèi)在評價的表達(dá).它可以從情感傾向方向和情感傾向度兩個方面來衡量[14].情感傾向方向也稱為情感極性,表示用戶對某客體所表達(dá)出的主觀態(tài)度,即正面情感、中性情感和負(fù)面情感[15].情感傾向度是指主體對客體表達(dá)情感時的強(qiáng)弱程度,不同的情感程度可以通過不同的情感詞或情感語氣等來體現(xiàn),例如:喜歡、特別好等詞語就表現(xiàn)為較高的正面情感,而討厭、非常糟糕則反映了較低的負(fù)面情感.在情感傾向分析研究中,為了區(qū)分兩者往往采用給每個情感詞賦予不同權(quán)值的方式來體現(xiàn)[16]. 本文使用基于情感詞典的方法來計算微博情感傾向,其基本思想是:1)通過文本切割方式將文本數(shù)據(jù)轉(zhuǎn)變?yōu)榭梢詧?zhí)行情感評分的數(shù)據(jù)格式,然后將其與預(yù)先建好的情感詞表逐個比對,通過特征值提取來對文本的詞語進(jìn)行評分;2)通過分析情感詞的傾向和傾向度來確定句子的情感,進(jìn)而確定整個文本的情感類型.本文以知網(wǎng)的情感極性字典和臺灣大學(xué)研制的中文情感極性詞典(NTUSD)為依據(jù),同時使用jieba分詞工具并導(dǎo)入搜狗15萬詞庫實現(xiàn)文本分詞. 通常在文本分析中總會涉及到分詞與詞頻統(tǒng)計.在中文分詞過程中,一般通過TF-IDF對特征值進(jìn)行提取.TF-IDF是一種用于信息檢索與數(shù)據(jù)挖掘的常用技術(shù),用來分析某個詞語對于一個文件集或一個語料庫中的一份文件的重要程度[17]. 在一篇文章中,詞頻(Term Frequency,TF)表示一個給定的詞語在該文章中出現(xiàn)的頻率.為了防止詞頻偏向長的文章,可以對它進(jìn)行歸一化處理.假設(shè)一篇文章中存在詞語ti,則它的重要性可以用下面的公式表示: (1) 其中,變量ni,j表示詞語ti在文章dj中的出現(xiàn)次數(shù),分母表示在文件dj中所有詞語的出現(xiàn)次數(shù)之和[14]. 逆向文件頻率(Inverse Document Frequency,IDF)是一種統(tǒng)計方法,用來衡量一個詞語的重要程度.一個字詞的重要性與它在文章中出現(xiàn)的次數(shù)成正比,但與它在語料庫中出現(xiàn)的頻率成反比.一個特定詞語ti的IDF值,可以由以下公式計算得到: (2) 其中,|D|表示語料庫中文件的總量,|{j:ti∈dj}|表示出現(xiàn)詞語ti的文件數(shù)目.最后TF-IDF可以表示為: tfi,jidfi=tfi,j×idfi (3) TF-IDF技術(shù)可以計算出某一文件中出現(xiàn)的高頻率詞語,并計算該詞語在整個語料庫中的低文件頻率,進(jìn)而獲得權(quán)重較高的TF-IDF.因此,使用這一方法可以過濾掉常見詞語,只保留重要的詞語. 本文對于微博簽到文本的情感分析流程如圖2所示.基本過程為:1)選擇每條微博中的文本執(zhí)行預(yù)處理,以標(biāo)點(diǎn)符號作為劃分標(biāo)志,將每條微博劃分為多個句子;同時,依據(jù)情感詞表提取每個句子中的情感詞[18];2)以每個情感詞作為基準(zhǔn),順序?qū)ふ页霈F(xiàn)在它前方的程度副詞、否定詞,計算相應(yīng)分值;之后,計算句子中所有情感詞的得分總和;3)判斷句子是感嘆句還是反問句,是否存在表情符號?因為表情符號也代表了用戶的感情傾向.如果存在,則該分句需要在原有得分的基礎(chǔ)上加上或減去對應(yīng)的權(quán)值[19];4)最后,累加所有分句的分值就能得到該條微博的最終分?jǐn)?shù).本文根據(jù)最終分?jǐn)?shù)的高低來表示該條微博的情感趨向. 圖2 情感分析流程圖Fig.2 Flow chart of emotion analysis 文本分析常用的方法是先對文本進(jìn)行預(yù)處理即刪除本文不需要的信息,然后通過分詞系統(tǒng)將文檔進(jìn)行分詞并刪掉一些停頓詞.最后使用TF-IDF模型計算詞頻并對詞頻排序,將詞頻高的詞語作為主題中心[20].這種方法忽略了文字背后的語義關(guān)聯(lián),因為可能存在兩個文檔的共有單詞很少甚至沒有,但它們在語義上卻很相似的情況.例如:“喬布斯離我們而去.”和“蘋果價格會不會降?”這兩個句子就沒有出現(xiàn)共同的單詞,但它們表達(dá)的語義是相近的.如果按照傳統(tǒng)方法分析就會得出這兩個句子不相似的結(jié)論.所以,在判斷文檔相關(guān)性時需要考慮文檔的語義,LDA就是一種比較有效的語義挖掘模型. LDA主題模型在是由David M.Blei、Andrew Y.Ng和Michael.Jordan三人在2002年第一次提出的.他們認(rèn)為一篇文章可以劃分為若干個主題,某個主題是由一些關(guān)鍵詞構(gòu)成,每個詞在這個主題中以一定的概率分布出現(xiàn).例如,一篇文章中每個詞語出現(xiàn)的概率可以表示如下[21]: (4) LDA主題模型是一個由“文檔-主題-詞”形成的3層貝葉斯概率模型,每個文檔表示為一個或者多個主題,每個主題和對應(yīng)的詞形成一個多項式分布,LDA對應(yīng)的模型如圖3所示. 圖3 LDA模型Fig.3 Model of LDA 假設(shè)給定參數(shù)α和β,N個主題分布θ,則N個主題z和N個詞匯ω的聯(lián)合概率分布為: (5) 對于LDA模型生成的主題,本文使用了LDAvis[22]來進(jìn)行可視化分析. 本文使用Python爬蟲程序通過新浪微博開放平臺的API接口,獲取到昆明市2015年7月-11月的43萬條記錄,數(shù)據(jù)格式為Json. CIDVis的前端可視化技術(shù)采用百度地圖、JavaScript、HTML語言、Echarts可視化組件和主題開源可視化工具實現(xiàn).它提供多種交互分析工具,實現(xiàn)了熱點(diǎn)區(qū)域、用戶情感和簽到主題的實時分析和動態(tài)展示.可視化提供的功能菜單如表1所示. 表1 CIDVis可視化系統(tǒng)的功能菜單 CIDVis可以借助時間軸展示不同日期下的簽到數(shù)據(jù)在整個城市的時空分布情況,如圖4所示.圖4圓圈中的數(shù)字越大,就表示這個位置附近的簽到數(shù)量越多. 圖4 簽到數(shù)據(jù)的空間分布Fig.4 Spatial distribution of check-in data 本文使用AC-DBSCAN算法對簽到數(shù)據(jù)的經(jīng)緯度坐標(biāo)進(jìn)行聚類,再將聚類結(jié)果加載到地圖上展示,并采用不同的顏色來區(qū)分熱點(diǎn)區(qū)域.圖5(a)-圖5(b)顯示了2015年8月1日和2日數(shù)據(jù)的可視化結(jié)果,從圖5中可以直觀地看出,這兩天的簽到熱點(diǎn)在空間位置上和數(shù)量上存在一定的差異. 圖5 簽到熱點(diǎn)區(qū)域Fig.5 Hotspots formed by check-in data 接著,本文重點(diǎn)分析主城區(qū)的熱點(diǎn)區(qū)域.通過7-10月的微博熱點(diǎn)區(qū)域的可視化展示可以發(fā)現(xiàn):主城區(qū)一共有15個熱點(diǎn)區(qū)域,這些區(qū)域主要分布在商業(yè)中心區(qū)、高等院校周邊、餐飲聚集地、休閑娛樂區(qū)、旅游景點(diǎn)和產(chǎn)業(yè)園.其中,火車站、南屏街商業(yè)區(qū)、云南大學(xué)周邊、翠湖公園、南亞風(fēng)情美食城、北辰商業(yè)區(qū)等是最受微博用戶關(guān)注的地點(diǎn).除了主城區(qū)以外,還有兩個熱點(diǎn)區(qū)域,即長水機(jī)場和位于嵩明縣的大學(xué)城,如圖6所示. 嵩明縣大學(xué)城由云南師范大學(xué)文理院、云南工商學(xué)院等多所學(xué)校組成.這里與機(jī)場一樣每天都能成為簽到的熱點(diǎn)區(qū)域,說明高校學(xué)生是昆明市微博簽到用戶的主要群體. 圖6 機(jī)場與嵩明大學(xué)城簽到位置的可視化Fig.6 Visualization of airport region and university town region in Songming county 通過可視化分析,本文發(fā)現(xiàn)人流量、用戶群體類型、城市基礎(chǔ)設(shè)施的配套程度都是影響微博簽到點(diǎn)形成的主要因素. 本文對昆明市各個行政區(qū)域產(chǎn)生的簽到數(shù)據(jù)進(jìn)行情感評分,可視化效果如圖7所示.通過對行政區(qū)域的情感可視化,本文可以發(fā)現(xiàn):西山區(qū)的民族村、官渡區(qū)長水機(jī)場的情感值一直很高,這說明風(fēng)景好的景點(diǎn)或者交通樞紐可以對人們的情感產(chǎn)生積極的影響. 圖7 情感趨向的可視化Fig.7 Visualization of sentiment analysis 通過對情感變化的柱狀圖分析,本文發(fā)現(xiàn)在七夕節(jié)(8月20日)、教師節(jié)(9月10日)、中秋節(jié)(9月27日)、國慶節(jié)(10月1日)當(dāng)天的情感值都很高,表明人們在節(jié)假日的情感趨向比平常更為積極.但是,圖7(b)中可以發(fā)現(xiàn)9月3日的情感值很低,因為這天是抗戰(zhàn)勝利日,人們在回憶歷史,緬懷先烈.此外,中元節(jié)(8月28日)和重陽節(jié)(10月21日)兩天的情感分?jǐn)?shù)也向下波動. 綜上所述,本文通過情感可視化可以發(fā)現(xiàn):人們的情感趨向容易受地理環(huán)境、節(jié)假日以及傳統(tǒng)文化等因素的影響,因此會產(chǎn)生正面或者負(fù)面的情緒. 利用LDA主題模型,可以從微博用戶上傳的簽到文本中發(fā)現(xiàn)特定主題,這些主題是由一些在語義上相關(guān)而且出現(xiàn)頻率較高的單詞構(gòu)成.但是,LDA模型的難點(diǎn)在于如何合理地對合并到一起的詞語進(jìn)行主題總結(jié)[23].本文使用標(biāo)簽云和LDAvis開源軟件,設(shè)計了可視化分析功能模塊來展示簽到數(shù)據(jù)中所蘊(yùn)含的主題模型,效果如圖8所示. 圖8是以9月27日的微博簽到數(shù)據(jù)為例進(jìn)行主題發(fā)現(xiàn)的可視化分析,從圖8(a)中可以看出,傳統(tǒng)通過詞頻統(tǒng)計得到的標(biāo)簽云主題僅是單個詞語,并不能將語義相關(guān)的詞語合并成主題.在圖8(b)中,利用LDA的可視化生成了10個文本主題,并用氣泡圖表示.氣泡的大小表示主題出現(xiàn)的頻率,而氣泡相互之間的位置遠(yuǎn)近則表明主題之間的接近程度.分析者用鼠標(biāo)單擊懸浮在窗口左則的任何一個氣泡就能查看其對應(yīng)的主題,右側(cè)面板會相應(yīng)地顯示出跟這個主題相關(guān)的詞匯,總結(jié)這些詞匯的含義就可以歸納出該主題的含義. 圖8 主題發(fā)現(xiàn)的可視化結(jié)果Fig.8 Visualization of topic discovery 圖8(b)展示了9月27日10個主題中的主題6.本文發(fā)現(xiàn)這一主題包含“中秋節(jié)快樂”,“月亮”,“親人”,“回家”,“賞月”,“月餅”等詞語.從這些詞語中能夠明顯地判斷出該主題與中秋節(jié)相關(guān). 通過CIDVis系統(tǒng)提供的基于LDA模型的可視化分析功能,本文可以將不同的詞語進(jìn)行合并,從而發(fā)現(xiàn)隱含的語義與人們當(dāng)天關(guān)注的熱點(diǎn)主題. 本文以新浪微博的簽到數(shù)據(jù)為研究對象,實現(xiàn)了一個名為CIDVis的可視化分析系統(tǒng).CIDVis系統(tǒng)不僅能根據(jù)時間展示微博用戶的簽到位置,而且利用本文提出的AC-DBSCAN聚類算法對簽到數(shù)據(jù)的地理特征進(jìn)行挖掘,發(fā)現(xiàn)了昆明市微博用戶的簽到熱點(diǎn)區(qū)域及其時空變化規(guī)律.同時,利用文本挖掘技術(shù)和LDA模型對簽到內(nèi)容進(jìn)行情感分析和主題發(fā)現(xiàn),并采用多種可視化組件和前端開發(fā)技術(shù),繪制了每天微博簽到數(shù)據(jù)的熱點(diǎn)區(qū)域分布圖、簽到內(nèi)容情感趨向變化圖和簽到內(nèi)容主題發(fā)現(xiàn)圖.這些可視化分析的手段可以更好地幫助管理者和決策者充分使用微博簽到數(shù)據(jù),發(fā)現(xiàn)其中蘊(yùn)藏的規(guī)律和知識.研究成果可以為公共服務(wù)質(zhì)量評價、輿情監(jiān)測、土地價值評估、商鋪選址推薦、流量預(yù)測等應(yīng)用領(lǐng)域提供的依據(jù)和參考.今后,將增加更多的可視化分析圖表,向用戶提供更好地決策支持.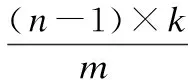
4 中文情感分析
4.1 情感傾向
4.2 TF-IDF模型與詞頻統(tǒng)計
4.3 CIDVis的情感趨向分析
5 主題發(fā)現(xiàn)
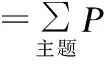
6 CIDVis可視化系統(tǒng)實現(xiàn)
6.1 CIDVis可視化系統(tǒng)開發(fā)
Table 1 Menu of CIDVis system
6.2 簽到熱點(diǎn)區(qū)域可視化

6.3 CIDVis可視化系統(tǒng)展示情感趨向

6.4 CIDVis可視化系統(tǒng)展示主題發(fā)現(xiàn)
7 總 結(jié)
猜你喜歡
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50云南化工(2021年8期)2021-12-21 06:37:54海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08傳媒評論(2019年4期)2019-07-13 05:49:14電子制作(2018年18期)2018-11-14 01:48:06中國科技博覽(2016年2期)2016-04-25 20:32:39小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38電測與儀表(2015年5期)2015-04-09 11:30:52
