融合評(píng)分-評(píng)價(jià)一致性和多維時(shí)間序列的虛假評(píng)論識(shí)別方法
2018-10-26 02:42:44房有麗
小型微型計(jì)算機(jī)系統(tǒng) 2018年9期
房有麗,王 紅,3
1(山東師范大學(xué) 信息科學(xué)與工程學(xué)院,濟(jì)南250358 )2(山東省分布式計(jì)算軟件新技術(shù)重點(diǎn)實(shí)驗(yàn)室,濟(jì)南250014)3(山東師范大學(xué) 生命科學(xué)研究院,濟(jì)南250014)
1 引 言
網(wǎng)上購物迎合了當(dāng)今快速的生活節(jié)奏,給人們生活帶來便捷.但是,虛假評(píng)論的存在,為營(yíng)造公平公正的網(wǎng)絡(luò)購物環(huán)境帶來了巨大挑戰(zhàn).網(wǎng)上購物使得用戶無法親身感受到商品質(zhì)地和性能,所以,在線評(píng)論成為顧客了解商店與商品的重要渠道,他們通常先參考商品的評(píng)論與評(píng)分,再?zèng)Q定是否購買.好的評(píng)論可以提升產(chǎn)品的信譽(yù),引導(dǎo)更多的顧客購買;相反,差的評(píng)論會(huì)影響信譽(yù),降低銷售量.因此,由于利益的驅(qū)動(dòng),商家開始雇傭水軍冒充普通顧客偽造評(píng)論.一方面對(duì)自己的商品進(jìn)行好評(píng),另一方面對(duì)于競(jìng)爭(zhēng)者惡意詆毀.因此,如何有效發(fā)現(xiàn)這些虛假評(píng)論成為亟待解決的問題.
先前的工作大多分別利用評(píng)分或評(píng)論來檢測(cè)虛假評(píng)論,如1-2分代表差評(píng),3分代表中評(píng),4-5分代表好評(píng),這些方法存在不足:第一,分別利用評(píng)分或評(píng)論檢測(cè)虛假評(píng)論,而沒有考慮二者的一致性問題,只利用評(píng)分或評(píng)論不能準(zhǔn)確檢測(cè)出虛假評(píng)論,因?yàn)樵u(píng)論與評(píng)分有時(shí)會(huì)不一致,評(píng)分不能完全代表評(píng)論者的真實(shí)情感.其中本文提到的一致性是指評(píng)論文本的情感極性與其評(píng)分都是一致積極或者消極,呈現(xiàn)正相關(guān),如表1所示,A、B表示不一致,C表示一致;第二,忽略了虛假評(píng)論在不同的時(shí)間的不同表現(xiàn).一般來說,在一段時(shí)間內(nèi)評(píng)論數(shù)量激增及評(píng)分突然上升或下降,就可能存在不真實(shí)的評(píng)論.針對(duì)上述問題,本文提出了基于評(píng)分-評(píng)價(jià)一致性和多維時(shí)間序列的虛假評(píng)論識(shí)別方法.

表1 評(píng)論-評(píng)分一致性對(duì)比表Table 1 Comment-rating Consistency comparison
本文的主要貢獻(xiàn)包括:
1)提出了判斷評(píng)論與其評(píng)分差異性的方案,綜合利用評(píng)分和評(píng)論檢測(cè)虛假評(píng)論.給出分析感情極性并判斷與其評(píng)分的一致性算法.
2)研究虛假評(píng)論在時(shí)間維的表現(xiàn),提出了針對(duì)評(píng)論與評(píng)分的多模態(tài)時(shí)間統(tǒng)計(jì)檢測(cè)方法,檢測(cè)一段時(shí)間內(nèi)評(píng)論與評(píng)分突變的相關(guān)性,而不是傳統(tǒng)的靜態(tài)評(píng)論集合檢測(cè)方法.
2 相關(guān)工作
近年來,研究者們?cè)诶W(wǎng)頁[1]與垃圾郵件[2]的識(shí)別研究上做了大量工作,獲得了較好效果.近來,虛假評(píng)論的檢測(cè)成為一個(gè)研究熱點(diǎn).Jindal等[3]發(fā)現(xiàn)了虛假評(píng)論廣泛的存在于商品中,但是這些評(píng)論本質(zhì)上與垃圾網(wǎng)頁和垃圾郵件不同,他們利用商品的評(píng)論數(shù)據(jù)、融合評(píng)論文本內(nèi)容和商品的特征因素進(jìn)行建模來區(qū)分復(fù)制觀點(diǎn)和非復(fù)制觀點(diǎn),檢測(cè)出是復(fù)制觀點(diǎn)時(shí)則判為虛假評(píng)論.
Xie等[4]發(fā)現(xiàn)了單一評(píng)論是虛假評(píng)論的重要組成部分.正常的評(píng)論比較穩(wěn)定、相關(guān)低.相比之下,虛假的評(píng)論相關(guān)性高且突發(fā)性,表達(dá)情感極性強(qiáng).因此提出時(shí)間模式,構(gòu)建基于多維聚合的時(shí)間序列統(tǒng)計(jì)以此挖掘虛假評(píng)論的相關(guān)性.
OTT等[5]利用眾包平臺(tái)實(shí)現(xiàn)了第一個(gè)虛假評(píng)論的“黃金”數(shù)據(jù)集,其中包含真實(shí)評(píng)論跟虛假評(píng)論.在基于計(jì)算機(jī)語言學(xué)的基礎(chǔ)上,把虛假評(píng)論的檢測(cè)問題轉(zhuǎn)化為文本分類問題.Li等[6]通過網(wǎng)絡(luò)獲取大量產(chǎn)品的評(píng)論,然后手動(dòng)標(biāo)注語料庫,利用協(xié)同算法來檢測(cè)虛假評(píng)論.
任亞峰等[7]提出基于語言結(jié)構(gòu)和情感極性的虛假評(píng)論識(shí)別方法,并利用自然語言處理技術(shù)分析正面和負(fù)面情感極性對(duì)評(píng)論的影響.然后利用遺傳算法,通過復(fù)制、交叉和變異實(shí)現(xiàn)種群的進(jìn)化,從而提高準(zhǔn)確率.Li等[8]利用語義和情感檢測(cè),并給出了構(gòu)建每個(gè)特征的模型和算法,實(shí)驗(yàn)表明,提出的模型,算法和特征在檢測(cè)任務(wù)中比基于內(nèi)容,評(píng)論者信息和行為的傳統(tǒng)方法有效.
Peng等[9]為了解決情感對(duì)商品的影響度,提出了基于自然語言處理技術(shù)對(duì)于情感的評(píng)分,并通過觀察建立規(guī)則來判別虛假評(píng)論,實(shí)驗(yàn)表明,他們所提出的方法在分析情感的精確度上取得了良好的效果.
Chang等[10]利用重要的屬性詞,具體的量詞和名詞動(dòng)詞比例來構(gòu)建虛假模型,結(jié)果說明更加獨(dú)特的詞匯和具體的量詞和名詞包含在內(nèi),假冒的可能性就越小.Li[11]等通過集體無標(biāo)記的學(xué)習(xí)來識(shí)別虛假的評(píng)論.
通過總結(jié)前人的工作發(fā)現(xiàn),研究者分別從評(píng)分和評(píng)論兩個(gè)方面進(jìn)行研究.一方面從商品評(píng)分著手,通過聚類算法進(jìn)行分組,識(shí)別出虛假的評(píng)論;另一方面是基于自然語言分析文本.本文提出融合情感分析、評(píng)分與評(píng)論一致性、以及時(shí)間序列的動(dòng)態(tài)多維模型來檢測(cè)虛假評(píng)論.
3 方法與模型
本文的目標(biāo)是利用情感技術(shù)及多維時(shí)間序列更加準(zhǔn)確的檢測(cè)虛假評(píng)論,為了實(shí)現(xiàn)這個(gè)目標(biāo),有3個(gè)問題需要解決.第一,如何判斷評(píng)論文本的情感極性與其評(píng)分的一致性,第二,如何利用時(shí)間序列模型檢測(cè)在一段時(shí)間內(nèi)評(píng)論數(shù)量與評(píng)分突變的相關(guān)性,進(jìn)行虛假評(píng)論識(shí)別;第三,如何通過機(jī)器學(xué)習(xí)模型發(fā)現(xiàn)虛假評(píng)論的影響因素,并揭示這些因素與識(shí)別虛假評(píng)論的關(guān)系.
3.1 評(píng)論文本情感極性分析
評(píng)論文本的情感傾向分析是通過挖掘和分析評(píng)論文本中的立場(chǎng)、觀點(diǎn)情緒等主觀信息,分析得出評(píng)論者的正面或者負(fù)面情感傾向.Dewang等[12]提出了一套新的詞匯和句法特征集,并應(yīng)用監(jiān)督算法對(duì)假評(píng)論數(shù)據(jù)集(黃金標(biāo)準(zhǔn))進(jìn)行分類.邸鵬等[13]提出對(duì)轉(zhuǎn)折句式文本分析算法,主要針對(duì)長(zhǎng)文本的情感分析,所以考慮上下文的轉(zhuǎn)折關(guān)系是有效的.但是他們直接對(duì)短文本分析效果并不佳,因?yàn)闊o法考慮上下文信息.本文提出了不同的計(jì)算方法:分別利用情感強(qiáng)度、特征權(quán)重對(duì)虛假評(píng)論的影響,提出了感情極性與其評(píng)分的一致性算法,如算法1所示.為了方便計(jì)算,符號(hào)表示如表2所示.
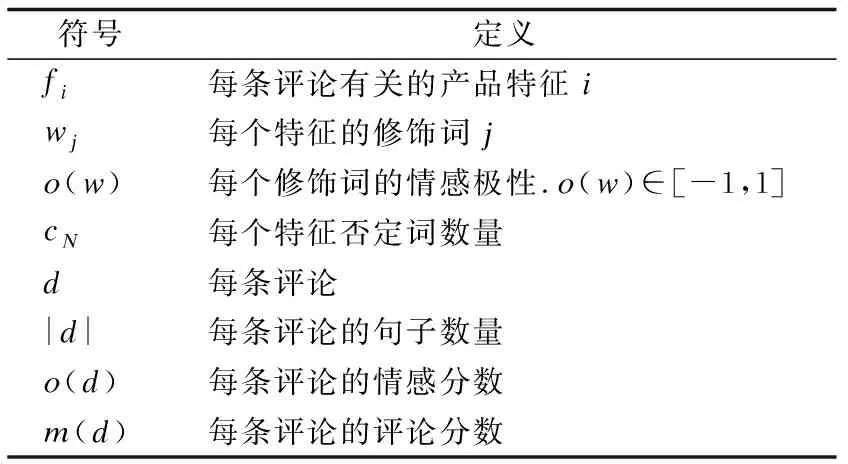
表2 符號(hào)定義表Table 2 Symbol definition
定義f(d)代表語義情感分?jǐn)?shù)和評(píng)分之間的差異度,如公式(1)所示,若m(d)與o(d)的乘積大于0,則表明它們之間沒有太大的差異;若是二者乘積小于0,則說明它們的差異過大是虛假評(píng)論.
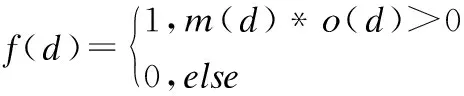
(1)
1)情感強(qiáng)度.情感強(qiáng)度是指情感詞通過距離對(duì)特征的影響度.當(dāng)特征與情感詞距離較近時(shí),情感強(qiáng)度加強(qiáng),反之亦然.定義s(f)代表所有特征詞匯情感度,用dis(wi,f)表示兩者的距離,計(jì)算情感詞對(duì)特征的影響度如公式(2)所示.
(2)
在公式(2)中,o(wj)表示情感極性的詞匯,當(dāng)是積極性詞匯時(shí),情感極性用+1表示;當(dāng)是消極性詞匯時(shí),情感極性用-1表示.cN表示每個(gè)特征否定詞的數(shù)量,如果沒有否定詞,cN等于0;若有奇數(shù)個(gè)否定字,極性情緒為-1,否則為+1.
2)特征影響度.特征影響度是指利用不同特征判斷虛假評(píng)論的準(zhǔn)確度.在評(píng)論里有很多特征對(duì)判斷虛假評(píng)論都有影響,但影響程度不同.權(quán)重較大的特征判斷虛假評(píng)論精確度會(huì)更高;相反,權(quán)重較小的特征甚至影響虛假評(píng)論的判別.定義o(d)代表每條評(píng)論的情感分?jǐn)?shù),如公式(3)所示.
(3)
Algorithm1.Review Analysis
1.INPUT:Review Text:
2.OUTPUT:Review Orientation
3.rt←{Review Text};
4.While(rt.read())
5. For all j∈rt.Length DO
6. IF(rt.wordi∈NegDictionary) THEN
7. IF(num/2!=1)THEN
8.o(wj)←o(wj)
9. ELSEo(wj)←-o(wj)
10.END FOR;
∥emotional intensity calculation
∥emotional score calculation
∥evaluation and score consistency judgment
13. FORfielement ind
14. IFm(d)*o(d)>0
15.f(d)=1∥the two are consistent
16. ELSE 0∥the two are inconsistent
17. END FOR
18.END WHILE;
19.RETURNf(d)
3.2 基于多維時(shí)間序列異常檢測(cè)
商家雇傭水軍冒充普通顧客偽造評(píng)論,會(huì)造成一段時(shí)間內(nèi)評(píng)論數(shù)量激增及評(píng)分突然上升或下降.最早提出利用時(shí)間序列檢測(cè)虛假評(píng)論的是文獻(xiàn)[14],但是存在著不足,他們僅基于評(píng)分建立評(píng)價(jià)指標(biāo),不夠準(zhǔn)確,因此,本文提出利用多維時(shí)間序列關(guān)于評(píng)論及評(píng)分異常模式檢測(cè)方法.
3.2.1 時(shí)間序列結(jié)構(gòu)
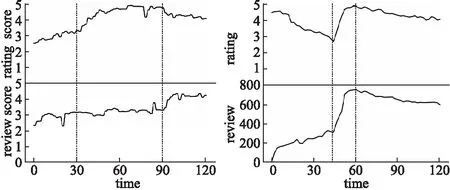
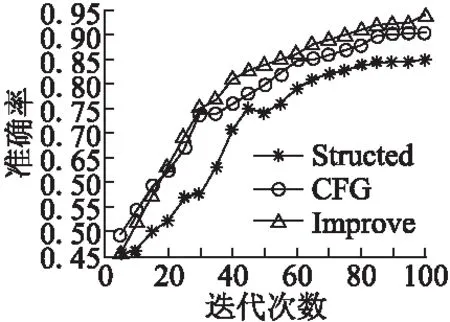
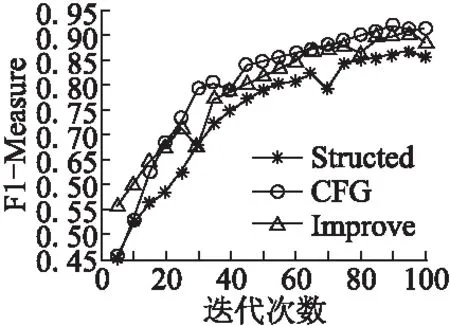
檢測(cè)方法是基于時(shí)間序列,包括評(píng)論數(shù)量、平均評(píng)分.每個(gè)商店都有一系列按照發(fā)布時(shí)間升序排序的評(píng)論數(shù)量及評(píng)分.其中,R(s)={r1,…,rns} 和TS(s)={ts1,…,tsns}分別表示評(píng)論與其對(duì)應(yīng)的時(shí)間,ns是商店的評(píng)論數(shù)量,tsi是評(píng)論ri的評(píng)論時(shí)間,tsi≤tsj當(dāng)1≤i (4) f1(In)=|{rj:tsj∈In}| (5) (6) 檢測(cè)虛假評(píng)論的思想如下:給定兩個(gè)時(shí)間序列的商店,我們?cè)趦蓚€(gè)序列中找出評(píng)分及評(píng)論數(shù)量相關(guān)的異常段.具體步驟如下所示. 第1步.首先,在每個(gè)維度上,我們采用貝葉斯變化點(diǎn)檢測(cè)算法[15],使用時(shí)間序列擬合曲線. 第2步.將簡(jiǎn)單的模板匹配算法應(yīng)用于擬合曲線以檢測(cè)突發(fā)模式.令C={c1,c2}表示時(shí)間序列二維的擬合曲線,并使用類似函數(shù)的模板來表示值的突然v={v1,…,v5},如果擬合曲線上的段c={c1,c2,…,cn}∈C與模板函數(shù)匹配,從而發(fā)現(xiàn)曲線上的異常段. 第3步.滑動(dòng)窗口在時(shí)間序列的所有維度中找出對(duì)應(yīng)于聯(lián)合突發(fā)的時(shí)間序列段.可以通過c滑動(dòng)窗口來獲得所有段,落入窗口中的所有段定義為b={ci1,…,cin},并求在兩個(gè)序列v、b之間進(jìn)行匹配.其中兩個(gè)序列之間的匹配是根據(jù)一個(gè)序列中的點(diǎn)與另一個(gè)序列匹配,通過兩個(gè)點(diǎn)之間的“匹配”,兩個(gè)點(diǎn)的絕對(duì)值之的差小閾值ε,L(i,j)記錄子序列之間的匹配數(shù)量匹配公式如(7) (7) 3.2.2 異常檢測(cè)算法 前文進(jìn)行了多維時(shí)間序列相關(guān)異常模式檢測(cè)構(gòu)建,如算法2所示. Algorithm2.Correlated Abnormal Patterns Detection in Multidimensional Time Series 1.Input:Multidimensional-curvesC, 2.window sizeΔt,time spanI. 3.Output:Periods when correlatea nomalies appear, 4.Detected time of spam activities 5.Initialize time setS0={I},scaleη=0 6.n=length ofC,w=time frame length 7.S=φ//set of periods tor return 8.forb=1→n-w+1 do 9.S=S∪{[b,b+w-1]} if 10. |{x∈Li:i=1,2,x∈[b,b+w-1]}==2| 11.End for 12.WhileΔtnot small enough do η=η+1,St=φ. 13. ForI∈Sη-1 do Fit a curveF(I,Δt) 14.Sη=Sη∪C 15. End for 16.End while 17.ReturnSη 特征選擇是從原有的特征集中選出貢獻(xiàn)率較大的特征子集.任亞峰等人使用遺傳算法對(duì)特征進(jìn)行選擇,但是該算法存在缺點(diǎn):有許多參數(shù),如交叉率和變異率,并且這些參數(shù)的選擇嚴(yán)重影響解的品質(zhì),而目前這些參數(shù)的選擇大部分是依靠經(jīng)驗(yàn),因此本文提出借助于信息增益進(jìn)行選擇,最后利用似然比檢驗(yàn)使用的邏輯回歸模型是否有效. 3.3.1 變量選取標(biāo)準(zhǔn)-信息增益 信息增益(IG,Information Gain)是非常有效的特征選擇方法.在信息增益中,重要性的衡量標(biāo)準(zhǔn)就是看特征可以為分類系統(tǒng)帶來多少信息,帶來的信息越多,該特征越重要.其計(jì)算虛假評(píng)論如公式(8)、公式(9)所示. (8) G(t)=entropy(D)-entropy(c|t) (9) 3.3.2 評(píng)論文本特征選擇 影響虛假評(píng)論的特征有很多,本文提出最可能影響的11個(gè)特征如下所示,并用信息增益計(jì)算影響度較大的特征. F1:文本復(fù)制.評(píng)論者為了盡快完成評(píng)論,經(jīng)常復(fù)制一些雷同的文本以不同身份評(píng)論,從而達(dá)到虛假攻擊. F2:情感度.情感度是指評(píng)論者對(duì)評(píng)論的情感極性度.虛假評(píng)論者比較片面,而正常用戶相對(duì)客觀. F3:文本長(zhǎng)度.虛假評(píng)論者相比正常評(píng)論者相對(duì)較長(zhǎng). F4:用戶信譽(yù).用戶發(fā)表的評(píng)論被其他用戶采納的數(shù)量越多,則信譽(yù)越高越真實(shí). F5:追評(píng)時(shí)間.正常客戶一般再使用一段時(shí)間后進(jìn)行追評(píng),而虛假評(píng)論者幾乎跟初評(píng)同時(shí)完成. F6:專業(yè)術(shù)語.正常用戶在進(jìn)行評(píng)論時(shí)比較白化,而虛假評(píng)論者使用詞匯較專業(yè). F7:否定詞.正常用戶在評(píng)論部分性能或許使用否定詞,而虛假評(píng)論者幾乎不用. F8:一致性.文本評(píng)論的情感極性與給出評(píng)分的相似度,相似性越低越可能是虛假評(píng)論,是檢測(cè)虛假評(píng)論重要特征. F9:相關(guān)度.相關(guān)度是指評(píng)論內(nèi)容與商品屬性的關(guān)聯(lián)程度,有些虛假評(píng)論者為了快速評(píng)論便復(fù)制一些與商品不相關(guān)的內(nèi)容. F10:圖片.普通用戶一般很少上傳照片,但是虛假評(píng)論者通常上傳照片提高商品信譽(yù). F11:轉(zhuǎn)折詞.虛假評(píng)論者的情感極性高度一致,很少使用轉(zhuǎn)折詞.但普通用戶或許會(huì)對(duì)部分性能表示不滿. 其中sw(re)表示評(píng)論中情感詞集合,tw(re)表示評(píng)論中所有詞語集合,l(r),f(r)分別為始末評(píng)論時(shí)間.特征F2,F(xiàn)5,F(xiàn)6計(jì)算如公式(10)-公式(12)所示. (10) (11) (12) 虛假評(píng)論的影響因素有很多,但是哪些因素對(duì)檢測(cè)虛假評(píng)論更加明顯,這其實(shí)就是回歸問題.自變量X是影響因素,由于自變量是離散的,無法直接用線性回歸方法解決,因此最佳的解決方法是Logistic回歸模型.Logistic分析原理就是利用一組數(shù)據(jù)擬合一個(gè)Logistic回歸模型,然后借助于這個(gè)模型揭示總體中若干自變量與一個(gè)因變量取某個(gè)值的概率之間的關(guān)系.概率P與自變量的關(guān)系如公式(13)、公式(14)所示. Y′=θ0+θ1X1+θ2X2+…+θmXm (13) (14) 在上述公式中自變量為X1…Xn,θ0常數(shù)項(xiàng),θ1…θn等為偏回歸系數(shù),P表示在n個(gè)自變量共同作用下發(fā)生的概率.因變量Y是二分類的值,所以取值為 現(xiàn)在把研究Y與X關(guān)系轉(zhuǎn)換成分析當(dāng)Y取某個(gè)值時(shí)的概率P與X的關(guān)系.當(dāng)Y是0時(shí)為虛假評(píng)論,X為虛假評(píng)論的影響因素.這樣研究虛假評(píng)論的攻擊率P與X的關(guān)系就簡(jiǎn)單了很多. 本文的數(shù)據(jù)集主要來自Xie等[16]12402條評(píng)論,其中包含6492條真實(shí)評(píng)論,5910條虛假評(píng)論.其中在一段時(shí)間內(nèi)突然激增,如表3所示. 表3 數(shù)據(jù)分析表Table 3 Data analysis table 為了選取對(duì)邏輯回歸模型影響較顯著的自變量,我們利用前文給出的公式(8)(9)計(jì)算每個(gè)自變量的信息增益,其結(jié)果如表4所示. 表4 候選特征及其信息增益值表Table 4 Candidate features and information gains 為了檢驗(yàn)?zāi)P椭兴凶宰兞空w是否與所有研究事件的信息增益存在線性關(guān)系,本文用似然比檢驗(yàn).其原理是通過分析模型中變量變化對(duì)似然比的影響,依次判斷增加或者刪除某個(gè)變量是否對(duì)因變量有顯著影響,如公式(15)所示. G=-2(ln(Lp)-ln(Lk)) (15) 在公式(15)中:ln(Lp)表示不包含檢驗(yàn)變量時(shí)模型的對(duì)數(shù)似然值,ln(Lk)表示包含.當(dāng)樣本量較大時(shí),G近似服從自由度為待檢驗(yàn)因素個(gè)數(shù)的χ2分布.當(dāng)G大于臨界值時(shí),接受H1,拒絕無效假設(shè),表示該影響因素對(duì)Logistic模型有意義.本文計(jì)算7個(gè)特征的似然比,在p值等于0.05條件下,計(jì)算結(jié)果如表5所示. 表5 似然比測(cè)試表Table 5 Likelihood ratio text 本文首先借助于情感分析利用情感強(qiáng)度、特征權(quán)重對(duì)虛假文本評(píng)論的影響計(jì)算出每條評(píng)論的近似分?jǐn)?shù),然后再與評(píng)論者給出與其相對(duì)應(yīng)的評(píng)分進(jìn)行比較,結(jié)果如圖1所示,實(shí)驗(yàn)結(jié)果發(fā)現(xiàn)在所有給出的評(píng)論中前30天是趨向于正相關(guān)的,評(píng)分與評(píng)價(jià)基本一致,在(2010.5.15-2010.7.15)逐漸趨向于負(fù)相關(guān),兩者不再一致,說明該時(shí)間段內(nèi)出現(xiàn)大量虛假評(píng)論,原因是商店為了提高效率,大量水軍復(fù)制與內(nèi)容不符的評(píng)論文本,導(dǎo)致與實(shí)際評(píng)分出現(xiàn)誤差,但整體評(píng)分趨向于上升趨勢(shì),因?yàn)樯碳夜蛡虻暮迷u(píng)水軍數(shù)量大于惡意的詆毀者.通過實(shí)驗(yàn)說明評(píng)分與評(píng)價(jià)一致性表現(xiàn)出了不錯(cuò)的性能. 圖1 評(píng)論-評(píng)分一致性對(duì)比圖Fig.1 Comment-rating consistency comparison圖2 評(píng)論和評(píng)分的時(shí)間序圖Fig.2 Reviews and scoring time 同時(shí),我們預(yù)先故意選取數(shù)據(jù)了(2010.5.15-2010.7.15)確定包含大量水軍的評(píng)論,基于多維時(shí)間序列從審查數(shù)據(jù)中檢測(cè)到更多的突發(fā)細(xì)節(jié)的時(shí)間段.我們?cè)O(shè)置窗口大小為15天,發(fā)現(xiàn)評(píng)分與評(píng)論數(shù)量在(20→30)急劇增加的可疑活動(dòng),如圖2所示,這與事先選取的實(shí)際評(píng)論情況相吻合,此結(jié)果揭示多維時(shí)間序列論識(shí)別方法是檢測(cè)虛假評(píng)論的重要性能. 本文利用情感極性、多維時(shí)間序列,并通過邏輯回歸模型檢測(cè)虛假評(píng)論,并采用十折交叉驗(yàn)證,通過與邵珠峰[17]提出的基于情感特征和用戶關(guān)系的方法(圖3中Structed標(biāo)記)與Feng[18]提出的基于句法結(jié)構(gòu)的檢測(cè)算法(圖3中CFG標(biāo)記)對(duì)比驗(yàn)證本文方法的有效性.本文采用最為通用3個(gè)評(píng)判指標(biāo)來判斷虛假檢測(cè)的優(yōu)劣:準(zhǔn)確率、召回率、F1值.從圖3中可以看出融合評(píng)分-評(píng)價(jià)一致性和多維時(shí)間序列的虛假評(píng)論識(shí)別方法取得了較好的結(jié)果. 圖3 準(zhǔn)確率比較圖Fig.3 Comparison of accuracy 邵珠峰等人分析虛假評(píng)論者和真實(shí)評(píng)論者在情感極性上存在著差異,通過評(píng)論者的情感差異構(gòu)建特征模型,并結(jié)合用戶之間的關(guān)系構(gòu)造多邊圖模型,最后計(jì)算出用戶評(píng)分來識(shí)別虛假評(píng)論.該方法準(zhǔn)確率有所提高,主要因?yàn)榭紤]情感極性差異,融合了評(píng)論文本較為重要的8個(gè)特征和其權(quán)重.但也存在著缺點(diǎn),通過人工標(biāo)記數(shù)據(jù)存在著一定偏差,只考慮初末時(shí)間.F1指數(shù)對(duì)比與召回率對(duì)比如圖4、圖5所示. 圖4 F1指數(shù)比較圖Fig.4 F1_Measure comparison Feng等人提出的于句法結(jié)構(gòu)的檢測(cè)算法分析了淺層次句法模式的缺點(diǎn),主要研究深層次的句法模式.他們?cè)谙惹把芯空叩墓ぷ骰A(chǔ)上加入特殊句法模式構(gòu)建語義樹并提取語義特征,此方法的準(zhǔn)確率達(dá)到91.2%.該方法優(yōu)越于邵珠峰的主要原因是,對(duì)于不同規(guī)則的書寫模式可以利用語義樹挖掘深層的句法關(guān)系,構(gòu)建專門的語義樹,但邵珠峰提出的方法受到限制. 本文相比較邵珠峰和Feng的準(zhǔn)確率有所提高,但F1值比Feng的稍差一點(diǎn).本文,首先,借助自然語言處理通過情感技術(shù)分析評(píng)論的情感極性并判斷與其評(píng)分的一致性;其次,建立時(shí)間序列進(jìn)行評(píng)論識(shí)別;最后,通過抽取7個(gè)特征并使用邏輯回歸進(jìn)行虛假檢測(cè).但我們發(fā)現(xiàn)準(zhǔn)去率提高的同時(shí)F1值有所下降,可能原因在于在加入特征后一些評(píng)論不存在否定詞. 隨著電子商務(wù)的蓬勃發(fā)展,研究者們對(duì)虛假評(píng)論檢測(cè)作出了不懈的努力.基于情感極性和多維時(shí)間序列,首先根據(jù)在線商品評(píng)論的特點(diǎn),提出通過分析評(píng)論的情感極性,判斷與其評(píng)分的一致性算法;其次,考慮時(shí)間對(duì)評(píng)分及評(píng)論數(shù)量的影響,構(gòu)建基于多維時(shí)間序列的虛假評(píng)論識(shí)別方法;最后,通過抽取不同特征,建立邏輯回歸模型,進(jìn)行不真實(shí)的或虛假的評(píng)論檢測(cè),通過對(duì)比試驗(yàn)證實(shí)了本文算法取得了較好的效果.但該方法還需有待改進(jìn),第一,冷啟動(dòng)問題,沒有動(dòng)態(tài)的考慮評(píng)論情況,在沒有評(píng)論或者僅僅少數(shù)評(píng)論的前提下該怎樣獲取評(píng)論信息;第二,評(píng)論文本中還隱藏其他重要特征可以提高精度.未來工作主要集中在這兩方面.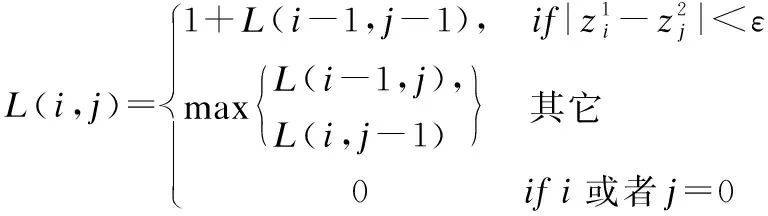
3.3 虛假評(píng)論特征選擇
3.4 邏輯回歸模型

4 實(shí)驗(yàn)分析
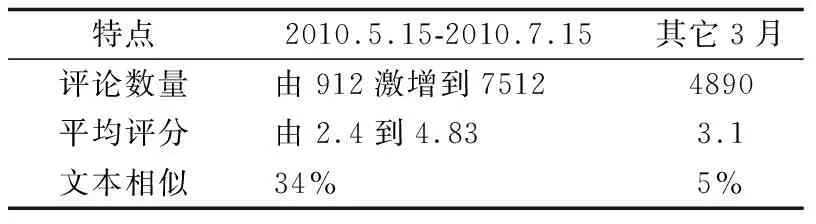
4.1 數(shù)據(jù)集
4.2 自變量計(jì)算-信息增益

4.3 方法與模型檢測(cè)


4.4 實(shí)驗(yàn)分析
5 結(jié)束語
猜你喜歡
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(bào)(2019年10期)2019-11-04 02:57:59
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
