點云無損壓縮并行算法研究
2018-10-26 02:42:44劉振亮孫煜東
小型微型計算機系統 2018年9期
關鍵詞:實驗
劉振亮,孫煜東,閆 華
(太原理工大學 信息化管理與建設中心,太原 030024)
1 引 言
近年來,隨著激光雷達(LiDAR,Light Detection And Ranging)掃描技術的不斷進步,掃描精度逐漸提高,掃描獲得的數據以指數級增長,如果直接進行數據傳輸或存儲,不僅成本高、實施難度大,而且很難實現,需要進行數據壓縮等預處理再進行傳輸.
常見的點云壓縮算法一般分為兩類:第一類是基于幾何學壓縮.首先對點云數據預處理,獲得網格模型,再對其進行壓縮.典型算法有三角網格剖分法[1]、頂點聚類算法[2]、邊折疊法、小波分解法等.該類方法需要在網絡拓撲的基礎上根據采樣點對網格進行重構,進一步簡化.簡化效果好,但是需要構造和維護龐大的拓撲信息,計算量大,效率較低.第二類是基于點云數據本身的壓縮,直接對點云數據進行處理,典型算法有比例壓縮法、基于八叉樹的壓縮算法[3]、基于特征點的壓縮算法[4]和基于預測模式的壓縮算法[5].這類方法直接對點云數據進行簡化,操作簡單,尤其是以LASzip[6]、LASCompression[7]等為代表的預測模式算法應用最為廣泛.本文選取LASzip無損壓縮作為研究對象.
然而,單純依靠壓縮算法遠遠不能實現數據實時處理的目標.隨著多核并行技術的不斷發展,僅僅依賴單核對數據進行壓縮,并不能很好的解決壓縮速度慢的問題,并行處理技術是提高LASzip壓縮算法壓縮、解壓縮速度的有效方法,目前高性能計算有兩大趨勢,并行計算集群和CPU處理器與GPU顯卡的異構混合計算.在GPU加速方面[8],利用GPU計算能力,將訓練數據傳到GPU端進行計算提高訓練速度.盧敏等人[9]以地形因子計算為例,分析并測試了基于共享內存模型的CPU多核并行模式與基于流處理器模型的GPU眾核并行模式的計算性能,在此基礎上實現了負載均衡的設備間任務劃分,進行CPU與GPU異構混合的并行技術改良研究.另一方面,多核CPU加速也是一個較熱的并行研究領域,宋剛等人[10]提出一種基于共享存儲的并行壓縮策略.通過Beowulf集群測試,并行化的gzip程序取得了極大的性能提升,壓縮速度顯著提升.
本文對傳統的LASzip壓縮算法進行介紹,分析其耗時部分,結合該算法特點,比較不同核數和不同數據量分塊單元的串并行算法執行時間及壓縮比,通過OpenMP技術優化LASzip壓縮算法壓縮、解壓縮過程,實現了多核CPU并行加速.并將該算法在臺式機四核機器上進行實驗.實驗發現,OMP-LASzip并行壓縮算法通過損失少量壓縮比,換取數據壓縮、解壓縮速度的大幅提高,充分發揮了多核處理器的性能,在實時性傳輸和節省存儲空間上有很大的應用空間.
2 背景知識
2.1 LAS格式
LAS文本格式從2003年發布至今,經過數次修訂,目前已更新到LAS1.4版1.

表1 LAS1.4版本格式結構Table 1 Structure and format of the LAS1.4
2.2 LASzip算法
LASzip算法是一種針對特定點云格式las開發的無損壓縮算法,采用預測模式進行編碼,僅保存預測錯誤的數據項.LASzip對點數據記錄區按組成項目分塊壓縮,每一項都有獨立的版本號和壓縮模型,方便后續las數據類型的擴展,壓縮方案也各不相同.LASzip算法以50,000個點為單位編碼,由于壓縮后每塊大小不同,壓縮器在文件末尾存儲一個塊列表明確每個數據塊的起始字節.當開始一個新塊時,LASzip壓縮器存儲第一個點作為原始字節,然后初始化熵編碼器,并將該點作為預測模式的初始值.接下來的點一項項由下面的壓縮模式順序壓縮.LASzip串行壓縮算法執行步驟描述如下:
Step1.對于las文件中的公共頭文件區和變長記錄區(包括擴展變長記錄區)的內容并不進行壓縮,僅拷貝到壓縮后的輸出文件laz中.并將點類型的值增加128,以防las讀取器直接讀取laz文件.
Step2.點云數據分塊編碼.
Step3.POINT10數據項壓縮
1)壓縮器編碼6位掩碼用以指定強度、返回值、分類值、掃描角等級、用戶信息、點資源ID等屬性值與之前處理過的點屬性相比是否改變;
2)壓縮器對預測錯誤(點屬性發生改變)的值進行編碼.
Step4.GPSTIME10數據項壓縮
將雙精度浮點數GPSTIME10視為有符號64比特整型數,存儲當前數據之前連續四個壓縮完成的GPSTIME10值取delta平均值.
Step5.RGB12數據項壓縮
1)las點云數據用16位無符號整型數記錄R,G,B通道.用256乘以8位顏色值,此時較低的8位為0;
2)LASzip對每個顏色通道的高位和低位分別壓縮:首先熵編碼6位指定哪些字節已經作為符號轉變.對于所有字節都發生變化的,與前一個壓縮完成的數據項差分取模256進行熵編碼.
Step6.WAVEPACKET13數據項壓縮
LASzip簡單的熵編碼波形描述符索引,如果該數據點沒有波形信息和索引,則記為一個字節的無符號數0,否則表示可變長記錄區已經記錄波形信息.
Step7.BYTE數據項壓縮
一個las文件可能存在“額外的字節”,這是因為las頭文件定義的字節數大于各自的點類型字節數.此時對每一個BYTE數據項進行上下文熵編碼作為前一項BYTE數據項模256的差分.
2.3 OpenMP介紹
隨著多核處理器性能不斷提升,為了提高多核處理器利用率,決定引入OpenMP并行設計技術,設計人員只需研究系統瓶頸,重構算法即可提升算法性能.OpenMP是高效的多核編程處理方案,以線程為基礎,通過編譯指導語句實現并行,在CPU核數擴展性、方便性和可移植性上都有很大的優勢.使得串行應用程序在多核共享存儲系統上,并行加速效率獲得大幅提升.
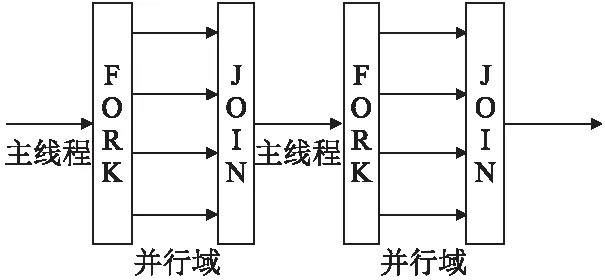
圖1 Fork-Join執行模式流程圖Fig.1 Executive flow of Fork-Join
OpenMP技術根據fork-join模式,對可并行的部分利用OpenMP子句和命令創建多個子線程實現并行.在并行域階段,主線程和子線程同時工作;并行結束后,子線程隨之結束或掛起,程序返回主線程繼續執行,并行算法中fork-join流程如圖1所示.
3 基于OpenMP的點云壓縮算法OMP-LASzip多核并行設計及實現
3.1 多核并行壓縮模型
基于OpenMP的多核并行技術為點云數據的并行壓縮處理提供了很好的平臺,為了改變原始串行算法,使其更好發揮作用,根據多核環境并行特性,借助Intel軟件工具VTune[12]對算法性能進行分析,建立基于OpenMP技術和LASzip算法的多核并行設計模型OMP-LASzip.VTune是Intel一個比較強大的性能分析軟件,主要包括三個小工具:
1)Performance Analyzer:性能分析,找到軟件性能比較熱的部分,即性能瓶頸的關鍵點,幫助收集數據發現問題.
2)Intel Threading Checker:用于查找線程錯誤,檢測資源競爭、線程死鎖等問題.程序在并行化后,可以通過Threading Checker檢測是否存在多線程相關的錯誤.
3)Intel Threading Profiler:線程性能檢測工具,多線程化可能存在負載不平衡,同步開銷過大等線程相關的性能問題.
該工具可以幫助監測任一線程任何時刻的運行狀態.
具體建立并行壓縮模型步驟如下:
Step1.使用Intel軟件工具VTune性能分析LASzip串行算法,發現熱點代碼;
Step2.分析串行算法耗時部分及熱點代碼的并行化可行性;
Step3.并行建模,實現并行LASzip算法;
Step4.使用Intel Threading Checker 和 Intel Threading Profiler對OMP-LASzip多核并行設計模型進行調試,優化代碼;
Step5.檢測算法執行性能,包括是否達到負載平衡,加速比、多核利用率、線程運行效率等情況;
Step6.使用Intel Threading Checker進一步檢查算法性能和潛在漏洞;
Step7.若存在漏洞,則返回Step 3優化算法.
在算法并行過程中,首先要找到程序耗時部分,因為這部分代碼一旦能夠實現并行處理,將大幅度提高算法執行效率.當然,除了熱點代碼,執行時間較長或執行頻率較高的算法實現并行也對提高系統運行效率、提高加速比起到促進作用.
3.2 OMP-LASzip算法基本原理
由2.2節LASzip串行算法步驟可知串行算法基本流程.大場景點云數據在壓縮過程中按數據項不同分塊壓縮,壓縮方式也各不相同.為了引入OpenMP技術,現從算法實現流程進行分析.考慮到壓縮過程中連續數據之間雖然有一定程度的相關性,但是由于數據分塊壓縮時以50,000個數據點為一個單元,且壓縮過程中不涉及數據競爭問題,因此可以直接并行化.通過將數據分為n組,同時分配樣本數據給n個線程,每組數據使用一個線程來實現LASzip算法的并行壓縮.采用OpenMP相關語句和命令來給并行壓縮的數據分配多個線程.
本文利用OpenMP多核并行技術對LASzip算法進行并行化研究.分析LASzip串行程序中耗時部分,同時分析耗時部分的可并行性,通過OpenMP添加并行語句對原有串行程序進行并行化,提出基于OpenMP的點云無損并行壓縮算法OMP-LASzip.
3.3 OMP-LASzip算法實現
LASzip算法只對點數據記錄區進行壓縮,對公共頭文件區、變長記錄區和擴展變長記錄區并不進行壓縮,僅拷貝到輸出文件中,因此計劃LASzip算法執行分兩部分進行:
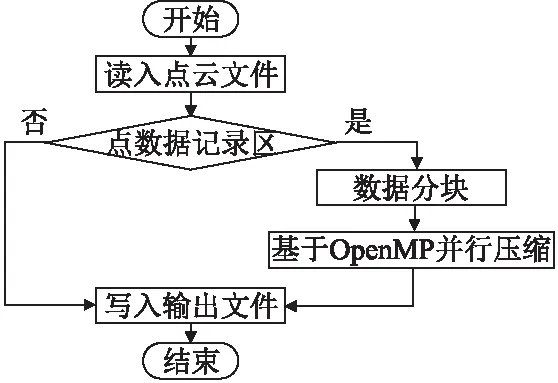
圖2 OMP-LASzip算法流程圖Fig.2 Flow of OMP-LASzip algorithm
1)讀入點云文件.僅保留點數據記錄區內容,將不需要壓縮的其他數據項直接寫入輸出文件;
2)壓縮點云數據.為了減少壓縮算法運行時間,提高點云數據處理效率,需要對壓縮過程實現OpenMP并行化.串行傳播的過程是點云數據分塊后順序壓縮的過程,使用并行語句后,數據分組并行壓縮提高壓縮效率.調用lasmerge函數對數據以n個點為單位進行分塊,分配給多個線程并行壓縮.
采用一個讀線程,一個寫線程,多個壓縮線同時工作.其中讀線程負責讀數據,循環檢測緩沖區,將空緩沖區填滿;寫線程負責寫數據,將壓縮完的數據按照讀的順序寫到輸出文件.為了保證讀寫順序一致,即壓縮文件按順序寫入輸出文件,引入讀寫順序隊列機制.當讀線程檢測到一個緩沖區為空,就從原文件中讀一塊數據加入到緩沖區中,同時將該緩沖區的序號加入到讀寫順序隊列中,這樣,寫線程就必須按著讀寫順序隊列里面存儲的緩沖區序號寫輸出文件,由于緩沖區和輸出隊列一一對應,這個序號也就是輸出隊列的序號,寫線程就可以從這個序號對應的輸出隊列中取得數據,寫入輸出文件,從而保證寫文件時保持原文件的順序.同時保證每個文件(除了最后一個)數據量近似相等,多核運行時負載均衡.下圖為對點數據記錄區OMP-LASzip算法數據壓縮部分詳細流程圖(見圖3):
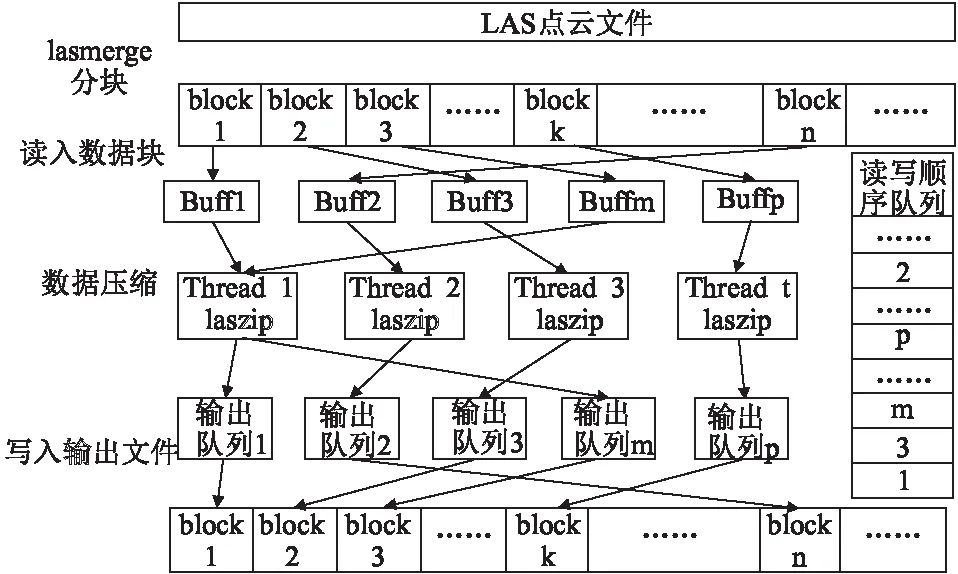
圖3 OMP-LASzip算法數據壓縮部分詳細流程圖Fig.3 Flow of partial details of OMP-LASzip algorithm
解壓過程原理相同,調用lasmerge函數對帶解壓文件以n個點為單位分塊,運用OpenMP技術,對數據塊并行解壓縮,以下是并行順序壓縮的偽代碼:
#pragma omp parallel for
//OpenMP的for循環并行語句
for(i=0;i<(totalnum/n);i++)
//totalnum為點云總數,n為每塊點云包含的數量,i為點云塊數
{
OMP-LASzipPOINT( ) ;//POINT10數據項壓縮
OMP-LASzipGPSTIME();//GPSTIME10數據項壓縮
OMP-LASzipRGB ( ) ;//RGB12數據項壓縮
OMP-LASzipWAVEPACKET( ) ;//WAVEPACKET13數據項壓縮
OMP-LASzipBYTE( ) ;//BYTE數據項壓縮
}
在并行設計模型和OMP-LASzip算法實現之后,考慮到如果串行編程存在錯誤,勢必會影響到并行算法的實現,因此還需要對結果進行調試與優化,以保證計算性能達到最優效果.采用多線程并行完成工作雖然可以提高系統運行效率,但是也提高了程序設計錯誤的風險.因此,在算法并行化完成后,對處理結果進行進一步的調試與優化十分必要.
4 實驗結果與分析
本文的實驗數據來源文獻2,選取5個數據量大于2G的點云數據集,數據分別按5,000,000、7,500,000、10,000,000、12,500,000、15,000,000個點為單位分塊壓縮.實驗平臺為臺式機Intel(R) Core i7-4770四核八線程處理器,主頻3.50GHz.開發環境是在Windows 7 Professional X64位系統上安裝Microsoft Visual Studio 2013,OpenMP直接在Microsoft Visual Studio 2013中配置.由于算法引入讀寫線程,則并行壓縮線程數最多為6.為保證LASzip算法在串行設計時的正確性,確保并行實現的順利進行,實驗計劃先對OMP-LASzip算法串行程序進行測試,并將實驗數據在并行環境中進行實驗,表2為OMP-LASzip算法壓縮結果性能比較,定義壓縮比:
(1)
其中s′為壓縮后文件大小,s為原始文件大小.統計10次取平均值得到并行多核LASzip壓縮算法相對串行算法的壓縮比誤差:
e=|kn-k|
(2)
其中,kn表示以n個點為單位的點云數據壓縮比,k表示原始點云文件壓縮比.

表2 OMP-LASzip算法壓縮結果性能比較Table 2 Comparison of the compress result of OMP-LASzip
實驗發現,數據分塊后壓縮較原串行壓縮,壓縮比有所下降,這是因為數據分塊后每個數據塊的起始數據無法使用預測模式進行編碼, 因此造成壓縮比降低, 但從結果可知誤差維持在1%以內, 驗證了并行算法的可行性.實際上,并行壓縮就是在損失少量壓縮比的前提下換取壓縮速度的提高.以CA_042_NE_PtCl.las實驗結果為例,以下為多線程點云數據并行分塊壓縮的時間.
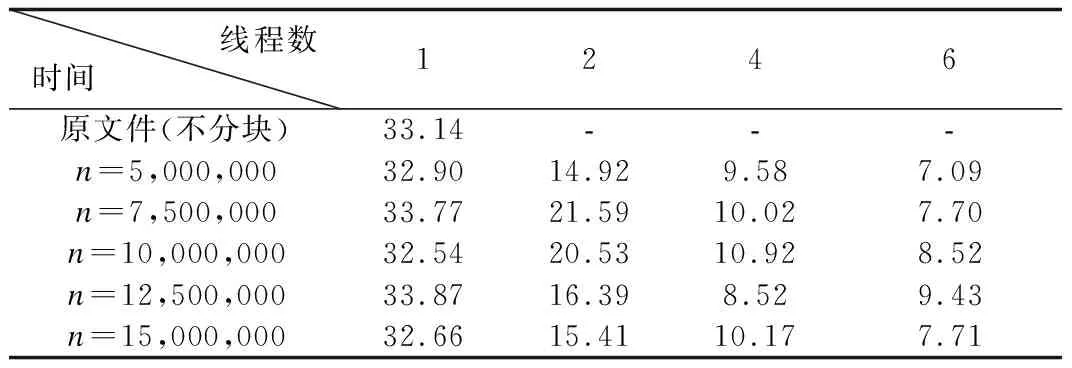
表3 多線程下點云數據并行分塊壓縮時間(單位:s)Table 3 Time of the compression of OMP-LASzip in multi-thread
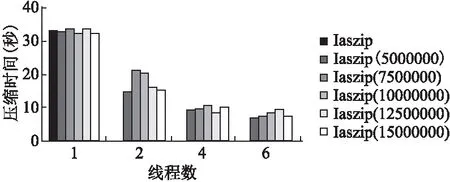
圖4 多線程點云數據并行分塊壓縮時間示意圖Fig.4 Diagram of compress time in multi-thread of point cloud data
加速比是衡量并行程序的指標,即用最優執行時間除以并行執行時間所得到的比值,加速比可以描述程序并行后獲得的性能收益,公式如下:
(3)
其中,s(p)為加速比,t1為最優串行算法執行時間,ti為線程數為i時的并行算法執行時間.從表4可知當n=5,000,000時,線程數為2時,理想加速比為2,但實驗發現此時加速比達到2.21,出現了“超線性加速比現象”.理論上講,當在p個處理器上運行的并行程序,其理想的運行速度應為串行程序運行速度的p倍,但是由于通信延遲,負載不均衡等原因,很難達到理想加速比.然而實驗顯示,線程數為2時,加速比達到2.21,超過理想加速比2,這是因為并行程序完成了較少的工作,即一般情況下,并行執行時所要訪問的數據都駐留在每個處理器的cache中,而順序執行時必須訪問存儲器系統中運行較慢的部分,因此由于并行程序所完成的工作量比串行程序的少,從而出現了超線性加速比現象.
從表4可以看出,當分塊點數量恒定時,加速比與線程數呈正相關.實驗發現,當線程數為6時與線程數為4相比加速比提高并不理想,這是由于系統硬件條件的限制,即使所有線程都分配到任務,系統CPU接近100%,壓縮程序的執行效率并不會有很大提升,因為線程的增加必然會提高系統開銷,影響程序性能.
同時實驗可以看到當線程數恒定時, 隨著單位塊內點云數量的增加, 加速比并沒有相應增加,而是出現了小幅波動甚至下降的結果,這是因為隨著單位點云數量增多,數據量增
大,點云塊數量減少,容易造成負載不均衡反而降低算法運行效率.由表4可以看出,當單位點云數量n=5,000,000時隨著線程數增加,加速比隨之升高,與其他單位點云數量相比性能提升最優.同時,當線程數為4時(考慮到讀寫線程,實際運

表4 多線程加速比實驗結果Table 4 Data chart of different thread of speed-up ratio
行線程數為6),加速比達到3以上,最高達到3.98,優化效果顯著;當線程數增加到6時,加速比較線程數為4時略有提高,此時8線程全部運行,CPU利用率過高,不利于系統正常運行,因此決定采用1個讀線程,1個寫線程,4個壓縮線程共同操作,保證各壓縮線程負載平衡,達到最優運行效果.
5 結 論
在對大量旅游景點數據進行三維重建過程中,對采集到的點云數據進行實時處理、壓縮、傳輸,對于提高建模效率、保證數據真實性、完整性具有重要意義.本文針對LASzip算法,分析其耗時部分,引入OpenMP技術,實現點云數據分塊并行壓縮OMP-LASzip算法,提高點云數據處理效率.實驗結果表明,與原串行算法相比,并行算法在損失少量壓縮率的情況下,壓縮速度顯著提升,保持負載均衡,同時隨著核數增加,加速比也在增加.實驗結果顯示,當單位點云數量n=5,000,000,壓縮線程為4時運行效果最佳,驗證了該算法的可行性、有效性和可擴展性,解決了現有點云壓縮方法處理效率低、實時性差的問題.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
