智慧交通運行狀態數據分析系統的應用研究
2018-09-21 05:28:46王少山
機電信息 2018年27期
王少山
(山西交控集團,山西太原030000)
0 引言
隨著人們生活水平的不斷提高,越來越多的人開始購買汽車作為其日常出行的交通工具,造成機動車數量的迅猛增加,給城市道路交通系統帶來了極大的壓力,各個城市均面臨著快速發展的交通系統與滯后的城市交通道路建設之間的矛盾。對于越來越頻發的交通擁堵、運輸效率低下等問題,傳統的靠人力指揮疏通的方式已經無法滿足對現代高速發展的交通系統的通行要求,因此,能夠科學合理地對路面交通進行監控、指揮的智慧交通系統應運而生,極大地提升了城市交通的管理水平,確保了交通安全,提升了運輸效率[1]。但隨著時代的快速進步,現代智慧交通系統面臨著數據信息量大,對關鍵信息的識別、處理困難等難題,因此如何對大量、復雜、繁瑣的交通數據信息進行快速分類處理,將其轉化為可快速識別的信息,用于對交通系統進行管理,便成了迫切需要研究的課題。
1 智慧交通運行狀態數據分析系統的架構
智慧交通運行狀態數據分析系統的整體結構如圖1所示,該分析控制系統主要包括數據儲存層、數據準備層、算法工具層、分析邏輯層及應用層。數據儲存層主要用于匯總、儲存智慧交通系統所收集到的各類的監測數據;數據準備層主要用于對系統設定的各指定數據進行專門的打包分類及初步處理;算法工具層主要用于對存儲隔離在數據準備層內的各類信息按照系統設定的算法工具進行邏輯運算,轉換為合成數據;分析邏輯層則用于對各合成數據和系統設定的原始控制數據進行分析對比,確認各合成數據的邏輯工作狀態;應用層主要用于根據邏輯分析結果在智慧交通的末端執行相應的控制,例如紅綠燈控制、堵塞路段數據信息播報及導航等功能。
2 Apriori算法原理
在該數據分析系統中,最主要的為算法工具層,為了確保對各類數據信息分析的準確性,本文采用了Apriori算法工具[2],該算法的基本思想為先對所有數據中的頻繁項集合進行標記,然后在各分析數據之間形成相應的關聯規則,確保在一個數據迭代流程內完成所有數據的錄入和檢索。
在實際運算時Apriori算法采用的是一種類似逐層確認的迭代算法,其核心是利用標定的頻繁項集合,先產生頻繁項集合1#,然后利用該產生的頻繁項集合尋找下一個標定的頻繁項集合2#,以此類推,直到尋找到系統中所有的頻繁項集合。在該項算法中也應用了先驗原則,即一個頻繁項子集一定是一個頻繁項集合,由此也可推斷其逆反命題:一個非頻繁項集的所有超集一定是非頻繁項集。Apriori的算法流程如圖2所示。
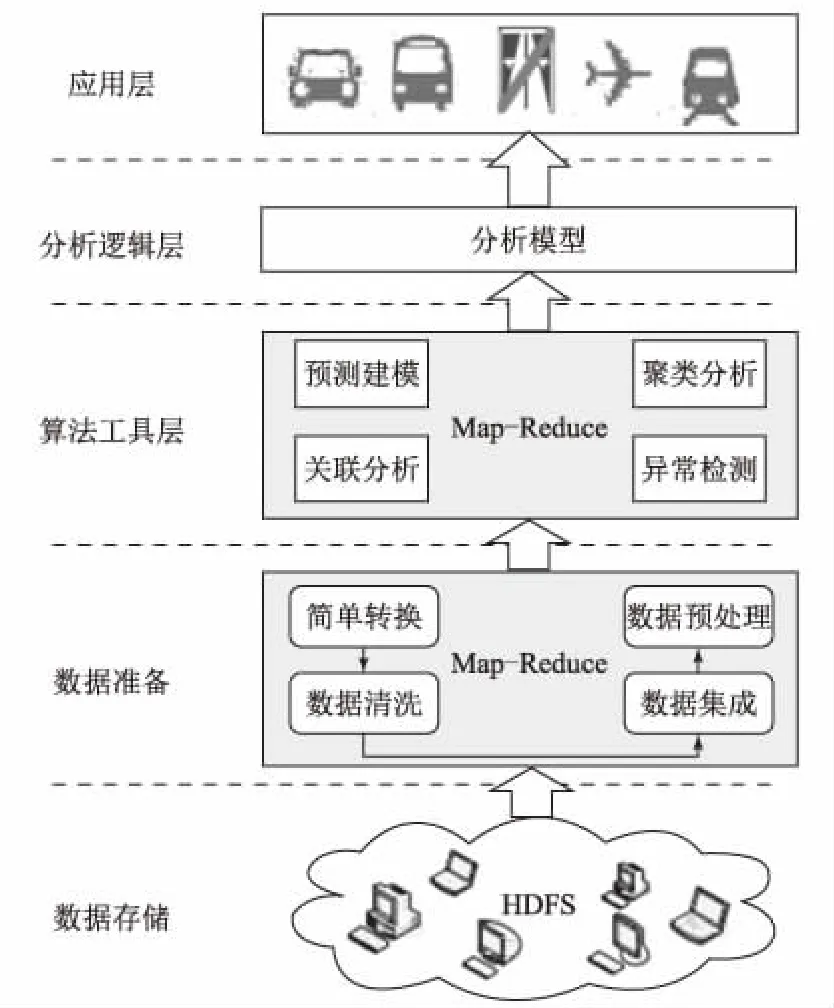
圖1 智慧交通運行狀態數據分析系統整體結構
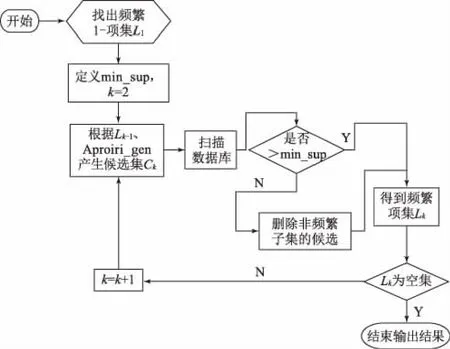
圖2 Apriori算法流程圖
3 數據分析處理系統的試驗驗證
為驗證該數據分析系統的實際使用效果,本文隨機選取了一組2018年6月某市交通系統實際監測到的數據信息對其進行檢驗,原始數據信息如表1所示。
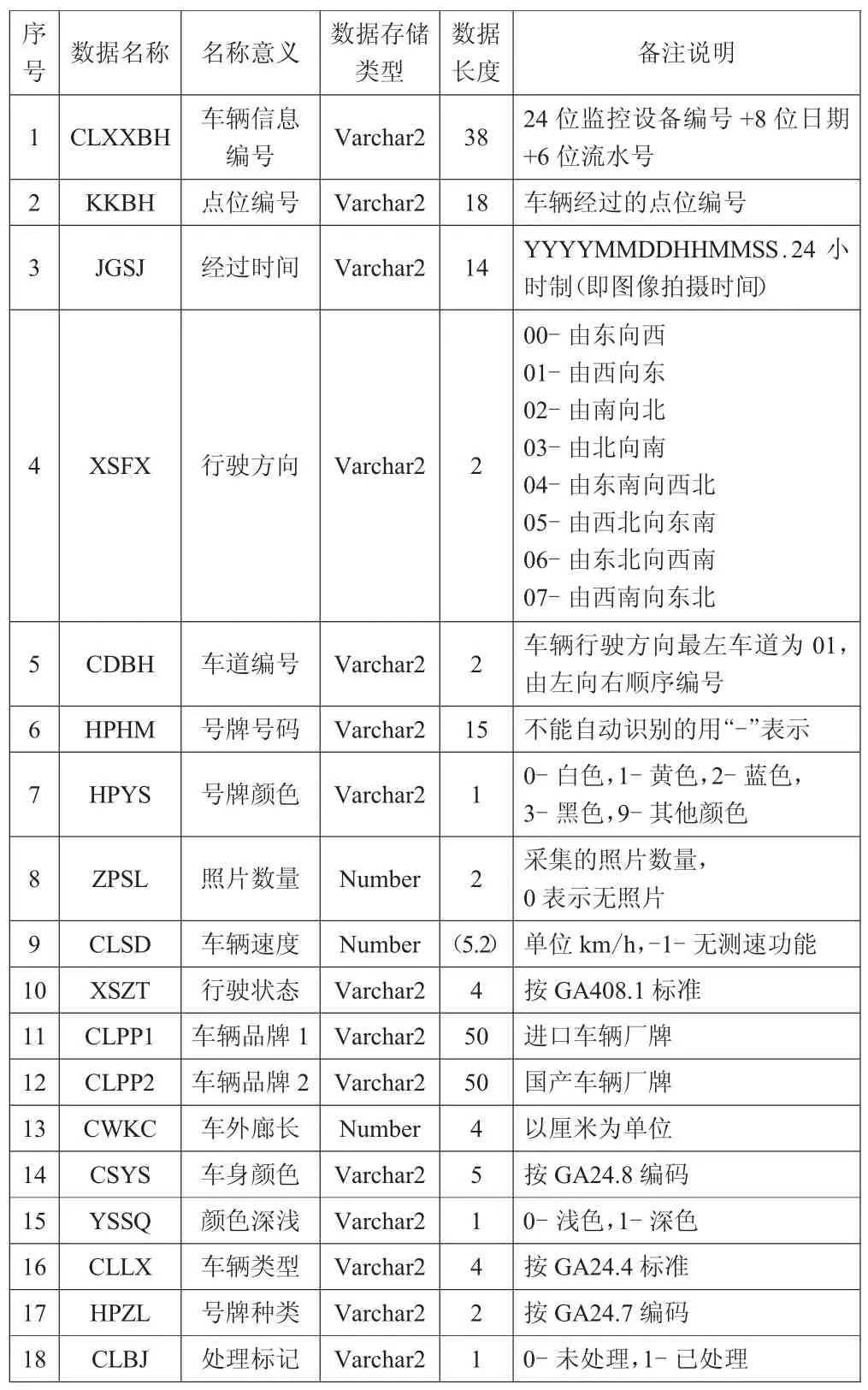
表1 原始交通監測信息數據統計表
在該試驗驗證中,主要是針對交通工具的超速和路況情況進行分析。在對路況情況進行分析時,本文將對某一個時間段內通過某個交通路口的所有車輛的基本情況進行分析,確定車流量最大的點位和方向。在對車輛行進超速情況進行分析時,本文主要是統計在某一個時間段內通過某個交通路口的車輛的基本行駛速度,獲取超速嚴重的時間點和路段,然后系統分配交通管理人員進行人工干預處理。在進行驗證時,設定運行速度超過40 km/h即為超速,模擬試驗輸出結果如表2、表3所示。
由表2分析可知,在第一個和第五個站點間由北到南的車流量最大,因此在實際工作時系統將自動優先為該站點之間安排交通管理人員,避免發生長時間堵塞現象。
由表3分析可知,在第一個站點和第13個站點處超速現象最多,但結合表2分析可知,這兩個站點在單位時間內的車流量最大,因此平均超速率較低,結合超速置信度可知,在第10和第11個站點間的車輛的單位平均超速率最高,因此系統將自動優先為該站點之間安排交通管理人員,避免發生交通事故,同時分析該處道路結構是否合理,為交管部門提出優化建議。

表2 車流量統計分析結果
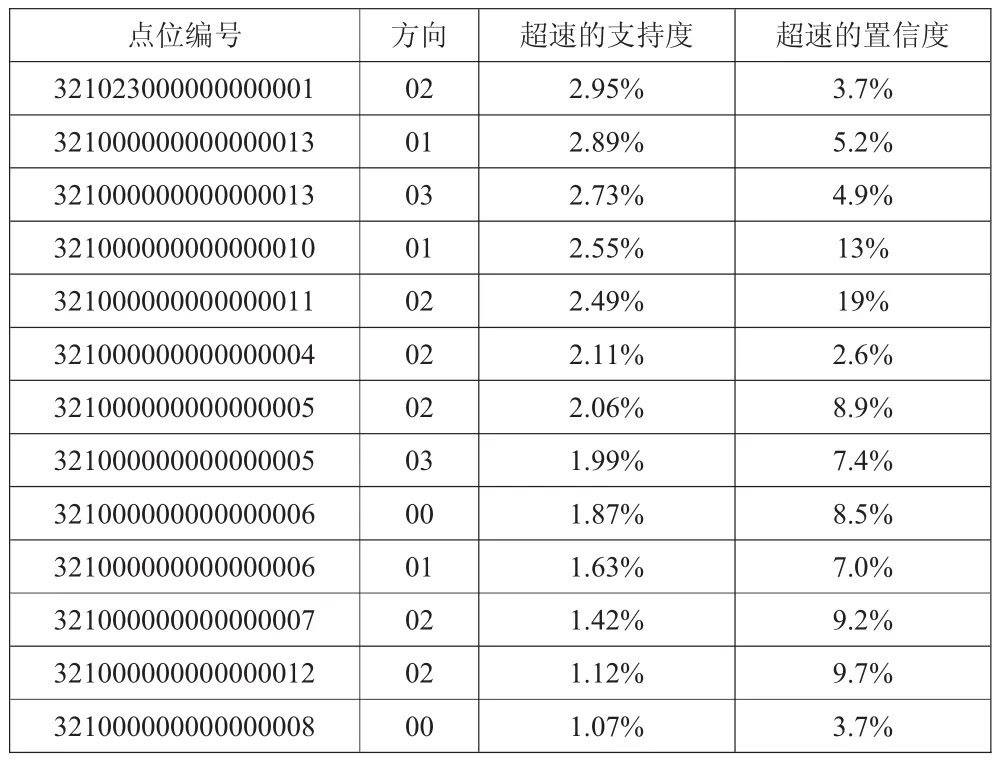
表3 超速量統計分析結果
4 結語
本文根據現有智慧交通的特點,提出了新的運行狀態數據分析系統,對系統結構和算法流程進行了闡述,并進行了模擬試驗驗證,結果表明,該數據分析系統能夠對海量數據進行快速準確的處理,能夠極大地優化交管部門的管理流程,提高交通管理水平。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
山東工業技術(2016年15期)2016-12-01 05:31:22
中外會展(2014年4期)2014-11-27 07:46:46
小天使·一年級語數英綜合(2014年6期)2014-07-22 23:32:38
智慧與創想(2013年7期)2013-11-18 08:06:04
網球俱樂部(2009年9期)2009-07-16 09:33:54
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
