面向領域的高質量微博用戶發現
2018-08-17 07:10:48葉永君周美林萬儀方
中文信息學報 2018年7期
葉永君,李 鵬,周美林,萬儀方,王 斌
(1. 中國科學院 信息工程研究所,北京 100093;2. 中國科學院大學,北京 100049)
0 引言
隨著信息化進程不斷加快,越來越多的普通用戶從信息的閱讀者演變成了信息的創造者與信息的傳播者。其中,微博平臺已經成了一個產生熱點事件和觀察社會言論的重要場所。據估計,Twitter平臺每天有高達五億條微博消息被人們所發布。 這些微博消息主題豐富,既包含一些普通對話,也包含特定領域相關的有價值信息。根據微博系統的功能規則,人們(follower)必須關注其他用戶(followee)才能獲取信息,這些被關注用戶(followee)發布的信息質量完全決定了關注者(follower)所獲取信息的價值。考慮到用戶價值往往集中在特定領域,選擇領域相關的高質量用戶[1]進行關注,對于微博使用者進行信息獲取具有重要價值: 一方面可以獲取更全面的信息(相關信息),另一方面也可以減輕信息(不相關信息)過載問題。
本文將高質量微博用戶發現問題拆解成兩個子任務: 領域相關用戶的檢索任務以及用戶質量排序任務。領域相關用戶檢索任務是給定領域,從海量微博用戶中找到與該領域相關的用戶;用戶排序任務是指給定用戶集合,根據用戶質量對用戶進行排序。
在具體方法上,對于領域相關用戶檢索任務,我們嘗試將領域詞與微博用戶的匹配轉化為領域詞和用戶標簽的匹配。其中,為了解決詞項失配問題,我們使用了基于維基百科的語義相似度計算方案。該方法首先將領域詞、標簽詞表示為維基百科的詞條向量,基于詞條向量來計算匹配度。該方法作為ESA(explicit semantic analysis)的一個擴展應用,相比Word2Vec或者LSA等對應的隱語義,對最后得到的結果有著良好的可解釋性。對于用戶質量排序任務,我們認為用戶質量由用戶所發消息質量所決定。進一步的統計分析發現: 含URL的消息質量更高、對用戶表征作用更強,且更容易被轉發,應該重點考慮。為此,在計算時我們只考慮含URL的消息,構造了基于用戶發布關系以及用戶轉發關系的聯合圖,通過圖迭代得到用戶質量以及消息質量得分,基于得分完成用戶排序。實驗結果表明: 該排序方法得到的用戶排序結果與基于人工標注得到的用戶排序結果具有很高的一致性。
本文后續內容組織如下: 第一節介紹相關工作;第二節介紹本文工作;第三節給出實驗和結論;第四節對全文進行總結。
1 相關工作
自微博誕生以來,度量用戶的重要性一直是一個主要研究問題。相關工作可以分為領域無關用戶重要度研究[2-7]和領域相關用戶重要度研究[1,8-9]。大部分的研究工作將用戶的重要性定義為用戶的權威度: 即所發信息更容易被轉發傳播,用戶更具有影響力。然而這些工作忽略了用戶的信息量,即用戶發布的消息數量。實際上,用戶發布的高質量消息越多,用戶被關注的重要性才越大。目前,考慮用戶消息數量的工作只有Yamaguchi[10]。Yamaguchi等人的用戶測量模型使用用戶所有的推文消息來構造 User—Twitter圖。在他們的模型中,用戶的消息數量將直接影響用戶的測量得分,即在一定程度上,用戶所發的微博數量越多,該用戶的測量得分會越高。本文與 Yamaguchi 的出發點類似,但存在兩方面的不同: 本文沒有利用用戶的全量消息,只利用“含 URL 的消息”來構建圖,減少圖上的節點數;本文將多種關系進行合并,減少了圖的連邊。這些改進可以顯著加速圖的迭代過程。
在計算用戶重要度時,相關工作利用的信息包括: 用戶的關注關系[1,6,8,10-11]、發布行為[10]、轉發行為[4,10-11],以及消息內容信息[1,4,11]。具體地,Weng[1]等人提出了TwitterRank模型。該算法利用用戶之間的關注關系構建有向圖,并在該關系圖上運行類PageRank的算法。Meeyoung等人的模型利用信息相對較多,專注于三種行為數據: ①關注,②轉發,③提及 @,并分別分析這三種行為所帶來的影響。類似地,Yamaguchi等人[10]的模型將用戶的關注關系、發布行為和轉發行為整合到同一個圖中;考慮到不同行為的內在意義不同,為不同類型的邊設置不同的權重。Gupta等人[12]的模型中也用到了關注關系,并認為用戶之間的關注代表“用戶對用戶推薦的信任”。上述研究在用戶測量時都考慮到了用戶之間的關注關系。
2 本文工作
本文方法的整體框架如圖1所示,輸入為用戶給定的領域詞,輸出為與領域相關的高質量微博用戶。
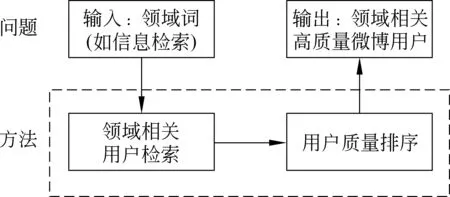
圖1 整體框架
2.1 領域相關用戶的檢索
我們使用用戶標簽來表示用戶,相關研究表明用戶標簽對于用戶興趣有很好的指示作用,如Ghosh S[13]使用 TwitterList來獲取用戶興趣。相應地,在新浪微博平臺上,每個用戶也會和一個或者一組標簽相對應,這里的標簽是用戶自主標注的,在一定程度上可以反映用戶所在領域的信息。以微博用戶“愛可可—愛生活”為例(圖2),從標簽便能直觀地反映用戶的領域。
然而利用領域詞與用戶標簽直接匹配會存在“詞項失配”問題,為了提升檢索效果,我們借鑒ESA方法[14]的思想,將標簽和領域詞映射到由維基百科詞條構成的高維概念空間中,通過詞條向量匹配得到用戶與領域的相關度。該方法可以對文本的隱含語義顯式表示,便于直觀理解向量化后的含義,得到的匹配結果也更容易解釋。

圖2 微博用戶標簽示例
2.1.1 外部資源的獲取和數據預處理
維基百科頁面分為頁面網和類別網,本文的研究工作只涉及到頁面網。我們下載了最新的 WikiDump中文資源數據,對文本進行繁簡轉換,統一轉為中文簡體,該WikiDump 數據集可以看作是一系列維基百科詞條頁面的集合。
利用上述方法,我們獲得了兩組數據。一是基于2015年10月13號的中文維基百科鏡像,原始大小為1.2GB,數據處理后得到866 180篇詞條文檔;二是基于2017年01月02號的中文維基百科鏡像,原始大小為1.4GB,數據處理后得到了 1 260 760篇詞條文檔。這些詞條涵蓋了各方面領域信息。
2.1.2 基于顯式語義分析(ESA)的用戶檢索
基于ESA的用戶檢索主要分為兩步: 一是使用ESA方法將領域詞和標簽詞表示為由維基百科概念組成的加權向量(后文稱為解釋向量);二是基于解釋向量計算領域詞與標簽詞的余弦相似度,取相似度最高的用戶作為領域相關用戶。
對于ESA方法,具體地,令T={φi}表示輸入文本,其對應的TF-IDF向量記作〈ωi〉,其中ωi是單詞φi的權重。令〈kj〉是詞ωi對應的維基百科詞條,其中kj為輸入φi與維基百科詞條Cj的關聯度,{Cj∈C1,…,CN}(其中N表示資源中維基百科詞條的總數)。這樣的話,對應文本T的語義解釋向量V是一個長度為N的向量(對應N個詞條),其中每個維基百科詞條Cj的權重被定義為∑φiωi×kj。向量V的每一維反映了對應的維基百科詞條Cj與給定文本T之間的相關性,如果詞條Cj與原始文本關聯較大,那么對應的特征權重也越大。
表1、表2給出了使用ESA得到的解釋向量。以“機器學習”為例,從中我們可以看到解釋向量能夠對原始詞條進行擴展,引入相關特征: 部分是與輸入詞相同或者相近的詞條特征,這些特征與輸入詞存在橫向關系,如詞條“人工智能”等;二是輸入詞的上位詞或者輸入詞的下位詞,這些特征與輸入詞存在縱向關系,如“特征縮放”等。顯然,通過ESA的轉換擴展,可以在一定程度上解決“詞項失配”問題。

表1 基于2015年中文維基百科得到的解釋向量示例(部分)
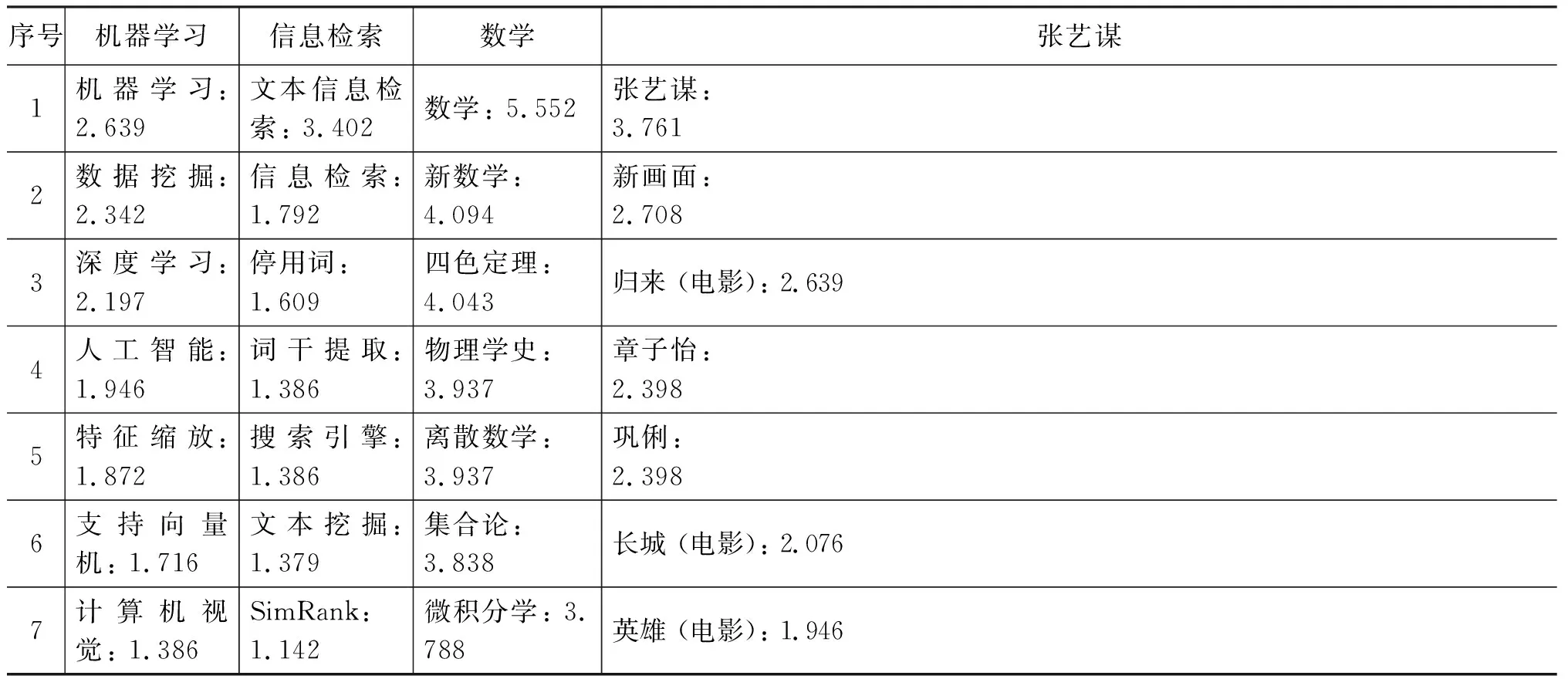
表2 基于2017年中文維基百科得到的解釋向量示例(部分)
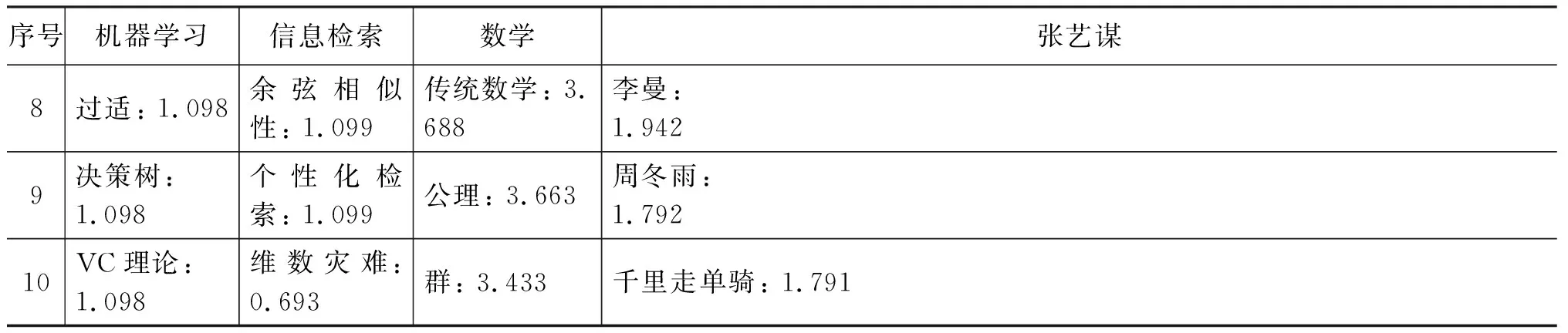
續表
表1向量化所用資源為2015年10月13號對應的866 180 條詞條文檔數據。為了說明隨著維基百科資源的擴大,詞匯量的增加可以提高向量化的效果,本文再采用2017年01月02號對應1 260 760條詞條的文檔數據進行同樣的向量化處理,得到的結果如表2所示。對比表1和表2可知,隨著資源的更新和擴充,同一輸入文本對應向量會發生些許變化,比如機器學習對應向量中詞項 top10 中新增了“數據挖掘”詞條,可見近些年,數據挖掘和機器學習兩者交叉的越來越多;特別對于輸入詞“張藝謀”向量詞項“長城(英雄)”的權重有所提升,這和“長城”電影剛上映這一熱點事件相對應。從新舊向量對比可知,隨著內容的更新和增加,新向量能在一定程度上反映一些熱點事件、新事件。后文將通過實驗來觀察新舊資源對實驗結果的影響。
2.2 用戶質量排序
該任務的輸入是2.1節返回的領域相關用戶集合,輸出是用戶質量排序結果。用戶排序可以通過計算用戶質量得分來解決。現有工作大部分利用用戶的關注關系以及消息轉發關系,通過構造相應關系圖進行圖排序得到用戶排序結果。實際上,現有方法存在以下兩方面的問題: 大部分現有方法可以識別高權威(authority)用戶,但不能識別高信息量 (hub)用戶,而對于信息獲取需求來講,用戶發布的消息數量與消息質量在衡量用戶重要度上是同等重要的; ②并不是用戶的所有消息都是高質量的,在計算用戶重要度時,簡單考慮用戶發布的所有消息會引入極大的計算量。
基于上述兩個問題,我們探索只使用含URL的用戶消息以及消息轉發關系來對用戶質量進行排序。具體地,我們首先驗證了含URL的消息相比不含URL的消息,其消息質量更高,更容易被轉發,只使用含URL消息計算用戶質量可以顯著減少計算量;接著我們提出了一種基于圖的用戶排序方法UBRank(URL biased User Rank),圖中只包含含URL的消息節點,利用消息發布以及消息轉發關系來迭代計算用戶以及消息的重要度。
2.2.1 含URL消息的統計分析
為了考察消息質量與是否包含URL的關系,我們從3.1的數據集中隨機抽樣了60個用戶(根據用戶發布的消息數量切分為六個區間,切分點為100、500、1 000、2 000、5 000,每個區間抽樣10個用戶),對每個用戶,隨機抽取20條含URL的消息以及20條不含URL的消息進行人工標注。消息質量使用三個標注級別: 0表示與用戶標簽不相關,1表示相關,2表示相關且有趣。

進一步分析發現: 對于含URL的消息,11.6%的消息被轉發;對于不含URL的消息,4%的消息被轉發。這表明含URL的消息包含更多用戶交互行為,更容易計算其質量。上述分析有效地說明了只利用含URL的消息來度量用戶重要度的合理性。
2.2.2 UBRank圖結構
在計算用戶質量得分時,我們使用如下假設: ①用戶發布消息被其他高質量用戶轉發越多,那么用戶質量也越高; ②用戶發布高質量消息越多,那么用戶質量也越高; ③消息被高質量用戶轉發越多,那么消息質量也越高。
基于上述假設,我們將“用戶—用戶”轉發圖以及“用戶—URL消息”發布圖合并為一個統一的圖,基于該圖來計算用戶質量,圖中的消息節點為包含URL的消息,而非所有的消息。
具體地,UBRank的圖結構如圖3所示。
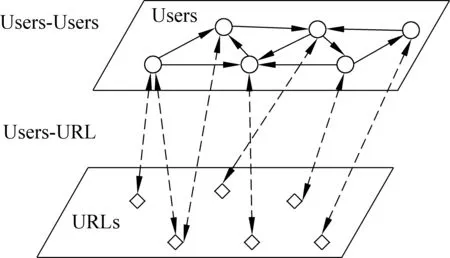
圖3 UBRank的雙層圖結構
從圖3中可以看到: ①用戶節點入度來自用戶和 URL; ②URL 節點入度來自用戶。這與我們前邊假設一致。
關于圖中邊的含義: ①用戶與用戶之間的有向邊,代表轉發關系; ②用戶與 URL 之間的雙向邊,代表發布(含轉發)關系。
2.2.3 UBRank迭代算法
假設用戶質量得分為υ=[υ(si)]m×1,消息質量得分為ν=[ν(tj)]n×1。UBRank的迭代公式如式(1)、式(2)所示。
其中矩陣U對應用戶—用戶圖,矩陣V對應用戶—URL圖。用戶的質量得分由其相鄰用戶以及發布的消息質量得分決定,含URL消息的質量僅僅由其相鄰的微博用戶決定。相應的矩陣形式可表示為式(3)、式(4)。
其中α和β分別表示來自同質節點和異質節點(類似 Hits 算法中的 Hub和 Authority節點)對最終質量得分的相對貢獻程度,α+β=1。為了保證迭代收斂,每輪迭代結束時υ和ν都要進行歸一化。
3 實驗和結論
3.1 實驗準備
為了驗證領域相關用戶檢索方法的有效性,首先需要一組微博用戶集合以及對應的用戶標簽。本文通過獲取種子用戶的兩層關注數據,采集到了 21 042個不同用戶,這些用戶屬于各個領域。通過進一步用戶分析,我們發現其中16 571(占總體用戶的78.75%)個用戶擁有標簽數據,本文使用該16 571個用戶及其標簽的集合作為本文的實驗室數據集。
3.2 領域相關用戶檢索—對比實驗設置
為了驗證本文提出的基于維基百科的顯式向量表示法的有效性,我們選擇領域查詢“機器學習”和“信息檢索”,比較不同方法得到的領域用戶集合的相關性。具體地,我們實現對比了以下幾種用戶檢索方法。
(1) 基于維基百科ESA的相似計算法: 如前面方法分析所述,利用維基百科頁面網的詞條文檔對領域詞和標簽進行向量化,這里本文有 2015-10 和 2017-01 兩份資源,分別記作維基15和維基17。其中利用倒排索引獲得對應詞條的權重后,為了去除噪音和不重要的關聯關系,按照詞條權重排序,只保留排名最高的前 80%的詞條。
(2) 基于知網的語義相似度計算法: 利用知網中的義原對詞語進行解釋,并基于義原進行相似度計算,該方法簡稱為“知網”。
(3) 基于Word2Vec+中文維基百科資源的語義相似度計算方法: 利用Word2Vec框架訓練中文維基百科資源,此處直接用最新的 2017-01 對應的維基百科資源。訓練方式選擇的CBOW,該方法簡稱為“Word2Vec”。
3.3 領域相關用戶檢索-結果與評價
正如前文所述,該部分問題是一個典型的信息檢索問題,已知領域詞,得到匹配的用戶集合。考慮到人工標注的耗時和高成本,本文僅僅使用正確率(Precision)作為評價指標。具體來說,統計各個實驗結果的P5、P50,P100和P200。實際操作層面,本文至多只需要標注各個實驗的top200即可。經過pooling后,針對領域詞“機器學習”和“信息檢索”,實際本文分別只得到了429個和447個不同的用戶,只需要人工標注這些用戶即可。評價結果如表3、表4所示。

表3 領域詞“機器學習”檢索效果/%

表4 領域詞“信息檢索”檢索效果/%
從表3和表4可以看到,維基15和維基17要優于其他方法,說明基于維基百科ESA的相似度計算方法的有效性。再對比這二者可知,2017年的數據集效果明顯優于2015年的數據集,說明隨著資源規模的擴大,檢索效果會有進一步提升。
3.4 用戶質量排序—對比實驗設置
為了驗證本文所提的UBRank排序方法的有效性,本文實現了以下五種用戶排序方法。
(1) UBRank: 如前面算法分析所述, UBRank 只關注含 URL 的消息,并基于用戶—用戶轉發圖和用戶—URL發布圖進行圖算法構建。通過訓練所知,參數α和β都設置為0.5。
(2) RTRankU: 此方法僅僅基于“含URL 消息”的轉發消息構建用戶—用戶轉發圖,此時忽略用戶—URL 發布圖。本文將在此用戶—用戶轉發圖上運行 PageRank 算法。
(3) RTRankA: 此方法基于所有消息的轉發關系構建用戶—用戶轉發圖,并依舊忽略用戶—URL發布圖。本文也在此完全的用戶—用戶轉發圖上運行 PageRank算法。
(4) TuRank: TuRank 算法考慮所有的行為數據: 關注行為、發布行為和轉發行為。圖中的節點表示用戶,用戶—消息之間的發布行為和用戶之間的轉發行為都會映射到用戶之間的邊上。并按照文獻[10]中工作對“不同關系(粉絲關系和轉發關系)邊”對應的權重進行區分設置。此方法是目前相關工作中表現最好的模型,是本文模型的重點參照對象。
(5) TwitterRank: 這個模型是文獻[1]中算法的簡化版本。本文跳過了從消息中計算用戶主題因子的過程,因為從一開始,本文挑選出的用戶集合已經限定在某個特定的主題中。該方法僅僅基于用戶之間的關注關系構建用戶—用戶關注圖。
3.5 用戶質量排序-結果與評價
為了度量算法效果,我們通過人工標記獲得用戶質量標準序,通過比對算法得到的序與標準序的差異來評估算法效果。序的度量使用Kendall’sτ[15]作為評估指標。τ值越大意味著算法得到的序越接近人工判斷。
在進行人工標注時,我們先對用戶消息進行標注,用戶質量得分等于用戶消息得分的累加和。考慮到用戶發布消息規模很大,為了降低標注量,我們對用戶消息進行分層抽樣,只對抽樣結果進行標注,基于樣本標注得分來估算用戶所有消息得分。具體地,對每個用戶,根據消息<是否含URL、轉發量>進行分組。“是否含URL”對應二類: 包含URL、不含URL,轉發量分為三個區間: [0,1), [1,5),[5,+∞),所以每個用戶的消息被劃分為六組。我們在每組抽樣五條消息進行標注,每個用戶平均有30條消息被標注。我們將消息質量劃分為三個等級: 0表示領域不相關,1表示相關,2表示相關且有趣。各算法得到的用戶排序性能如表5所示。
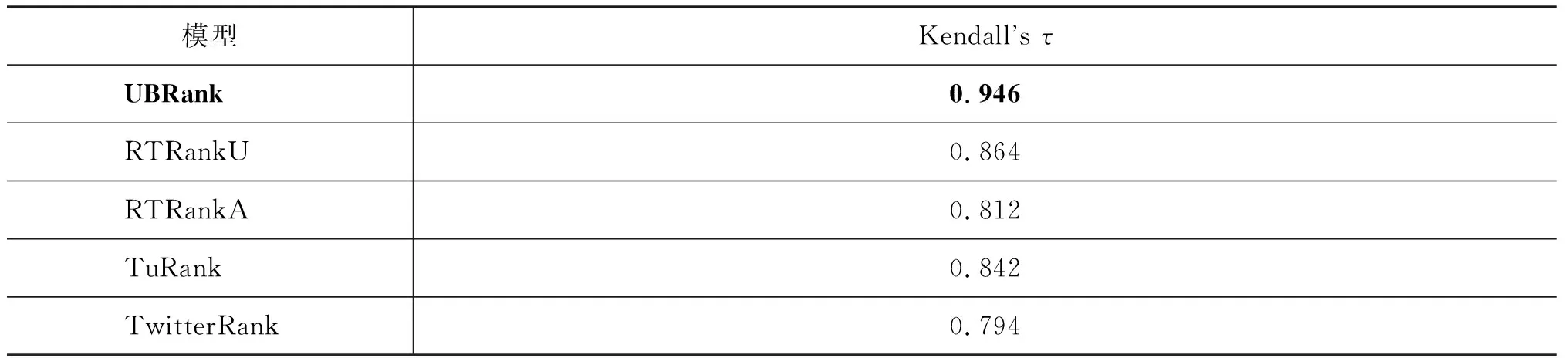
表5 Top 10用戶實驗結果對比
從表5可以發現,本文所提的 UBRank要優于其他對比實驗。RTRankU的效果要好于RTRankA,說明了 “僅使用帶 URL消息”相比使用“所有消息”在計算用戶質量排序上的優越性。具體地,在圖構建上,RTRankU只使用帶 URL 的消息,而RTRankA 使用所有消息,其中包括了那些不帶 URL 的消息。除了這點不同外,其他的過程對于兩種方法是完全相同的。這也與前面的統計分析相一致: 含 URL 的消息比不含URL 的消息質量更高;反過來說,不含 URL 的消息由于轉發量有限且話題無關,對于用戶質量測量可能引入噪音。
從表5中我們還可以發現RTRankA的實驗效果與 TwitterRank的效果相當;這表明轉發關系與關注關系在計算用戶重要度上效果相當。TuRank的實驗效果優于RTRankA、 TwitterRank,這一結果表明,通過組合關注信息和轉發信息可以提升實驗效果。RTRankU同時優于 RTRankA、TwitterRank表明: 相比利用“所有消息的轉發”和“用戶之間的關注”信息,利用“含 URL消息的轉發”信息計算用戶質量更為有效。此外,對數據集中所有用戶(21 042用戶)的所有消息進行統計,我們發現含URL的消息量只占總體消息量的20%,利用含URL消息計算用戶質量可以極大地減少計算規模。
4 總結與展望
本文研究面向領域的高質量微博用戶發現問題,并將該問題分解為兩個子問題: 領域相關用戶的檢索以及用戶質量排序。對于領域相關用戶檢索,我們使用用戶標簽來表示用戶,通過計算領域詞與用戶標簽的匹配度,取排名最高的用戶作為領域相關用戶,領域詞與用戶標簽匹配使用基于中文維基百科的顯式向量(ESA)的語義相似度計算方法,實驗驗證了ESA方法在檢索領域相關用戶方面的有效性和優越性,并通過2015年和2017年新舊資源對比,說明隨著資源的更新,匹配精度會得到進一步提升。對于用戶質量排序,我們提出了基于圖的迭代排序方法UBRank,在計算用戶質量時同時考慮用戶發布消息的數量和消息的權威度,并且只選擇含URL的消息來構建圖,實驗表明僅使用含URL的消息相比使用全部消息得到的用戶質量排序效果更好,并且引入的計算規模更小。
未來的工作包括: 通過引入更多中文資源來提升語義相似度的匹配效果、對URL做進一步過濾、考慮引入時間因素對用戶質量進行評價等。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
中國生殖健康(2019年2期)2019-08-23 08:12:08
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
