在線技術社區的用戶技能與興趣發現
2018-08-17 08:39:08張東雷林友芳萬懷宇馬語丹陸金梁
中文信息學報 2018年7期
張東雷,林友芳,萬懷宇,馬語丹,陸金梁
(北京交通大學 計算機與信息技術學院,北京 100044)
0 引言
作為一種集成化的信息與知識傳播和共享服務平臺,在線技術社區為用戶提供了技術交流、咨詢和共享空間,深受技術愛好者和從業者的青睞。用戶可以在社區發表博客或帖子來記錄或分享自己對某一問題的經驗或看法,可以瀏覽或收藏自己感興趣的內容,可以針對自己的疑問提出咨詢,也可以參與相關話題的討論。例如,全球最大的中文IT技術社區CSDN,擁有數千萬用戶,每天產生大量的博客和帖子,以及瀏覽、頂踩、評論、收藏等行為。準確地了解和掌握每個用戶的技能和興趣,對用戶進行準確的畫像,對技術社區的運營者來說十分重要,有助于他們為用戶提供精準推薦和個性化服務,從而增加用戶的黏性和社區的活躍度。例如,社區可以根據用戶的興趣為其推薦內容、好友、活動信息、技術專家等,也可以根據用戶的技能為其推薦合適的工作機會。然而,社區中通常只有少部分用戶提供了自定義的技能標簽或興趣標簽,而且標簽的可信度也存疑。因此,如何基于用戶產生的內容和行為信息,準確地發現用戶的技能和興趣,就顯得尤為必要。
以用戶技能(或興趣)建模為目的的文本挖掘近年來受到了研究者的廣泛關注[1-3],涌現出了大量的相關模型,這些模型大致可以分為有監督、無監督和半監督的用戶技能/興趣建模。有監督和半監督的建模方法[4-5]需要利用訓練語料來訓練生成文本分類器,進而對用戶進行分類,一般具有較高的準確率,然而獲取訓練樣本的昂貴代價極大地限制了此類方法的可應用性。因此以LDA[6]、AT[7]、CAT[8]和ACT[9]等話題模型為代表的無監督用戶技能/興趣建模方法近年來受到更多的關注。但是,當前這些模型主要考慮從用戶發表的文章來對其技能或興趣進行建模,沒有將用戶的技能和興趣區別開來,因此還不能更準確地同時捕獲用戶的技能和興趣。
事實上,社區用戶既是社區內容的生產者,又是消費者。生產者是指用戶以作者身份發表內容,主要體現了用戶的技能;消費者是指用戶以讀者身份去閱讀、頂踩、評論和收藏各種內容,主要體現了用戶的興趣。通常情況下,用戶的技能比較集中,而用戶的興趣則相對寬泛。基于這一假設,本文提出了一種作者—讀者—話題(author-reader-topic, ART)模型,來同時對用戶的技能和興趣進行建模。該模型在經典的LDA模型基礎上增加了作者和讀者信息,在建模文檔生成過程中,同步建模作者的話題分布和讀者的話題分布。該模型可以捕獲文檔的作者和讀者之間的關聯關系,因而能夠進一步提升話題的聚集效果,從而產生更準確的作者話題分布和讀者話題分布。
我們采用吉布斯采樣的方法對ART模型進行推導和求解,通過不斷地采樣語料庫中每個詞的主題指派和讀者指派來近似推斷語料庫中主題、詞和讀者的聯合分布。吉布斯采樣收斂后,我們就可以根據語料庫中每個詞的采樣結果來估計出作者話題分布和讀者話題分布。
我們從CSDN技術社區采集了一個真實數據集進行了實驗,并跟已有的用戶技能/興趣發現方法進行了對比和分析。實驗結果表明,本文提出的ART模型能夠更有效地發現用戶的技能和興趣,明顯優于現有的各種話題模型。
本文的主要貢獻包括以下兩點:
(1) 將在線技術社區用戶的技能和興趣區別開來,并根據用戶作為內容的生產者和消費者兩種角色,提出了一種同時對用戶技能和興趣進行建模的話題模型。
(2) 從CSDN社區采集了一個高質量的真實數據集,對提出的模型進行了大量的實驗,并通過案例分析和各種評價指標驗證了本文提出的模型的有效性。
本文的剩余部分組織如下: 第一節簡要介紹相關工作;第二節詳細描述我們提出的模型;第三節進行實驗對比和結果分析;最后在第四節對全文進行總結。
1 相關工作
以用戶技能(或興趣)建模為目的的文本挖掘近年來受到了研究者的廣泛關注[1-3],涌現出了大量的相關模型。早期研究者主要利用有監督或半監督的模型來挖掘用戶的技能或興趣,取得了較高的準確率。例如,He等人[5]通過形式概念分析技術從正例文檔中建立用戶興趣模型,并采用形式化的概念來代表用戶感興趣的話題。Yang等人[4]考慮到Twitter用戶發表微博的周期性模式,提出了利用時間序列把用戶微博進行歸類,將微博內容轉化為時間序列特征,采用時間序列的分類方法對Twitter用戶的興趣進行分類,和傳統的基于文本特征對用戶興趣進行分類的方法相比,取得了較高的分類準確率。 然而,有監督和半監督的建模方法需要大量的標注語料來訓練分類器,雖然具有較高的準確率,但是獲取訓練樣本的昂貴代價極大地限制了此類方法的可應用性。
以話題模型為代表的無監督方法避免了獲取訓練樣本的昂貴代價,因此在文本挖掘領域得到廣泛的研究和使用。LDA(latent dirichlet allocation)模型[6]是最經典的話題模型之一,由Blei等人于2003年提出,它采用了“詞袋”假設,即忽略一篇文檔的詞序、語法和句法,僅僅將其看作是一個詞集合。LDA是一種層次式的貝葉斯模型,其核心思想是將文檔看作隱話題的分布,而將每個隱話題看作詞的分布。由于LDA具有良好的數學基礎和靈活的可拓展性,目前國內外已有大量的研究者基于LDA及其拓展模型來對用戶技能或興趣進行建模。Weng等人[10]將每個用戶發表的tweets融合起來,并使用LDA來發現用戶感興趣的話題。Rosen-Zvi等人[7]提出了作者—話題(author-topic,AT)模型,將文檔的作者信息加入話題的建模過程中,同時對作者和話題進行建模,實驗表明加入作者先驗信息可以增強話題的聚集效果,從而有效地計算作者感興趣的話題分布。Hong等人[11]將AT模型應用到Twitter上,結果表明作者信息的加入有助于對Twitter用戶的興趣話題進行建模。Xu等人[12]認為用戶發表的tweets并不都能體現用戶的興趣,通過在AT模型中引入一個隱變量來指示一篇tweet是否和用戶的興趣相關,據此提出的twitter-user模型在發現用戶興趣上要優于AT模型。Li等人[13]提出用戶—話題(user-topic,UT)模型對微博中的用戶興趣進行建模,按照微博生成機制的不同將用戶的興趣分為原創興趣和轉發興趣,分別對應用戶的原創博文和轉發博文,實驗表明該模型發現的用戶興趣涵蓋的范圍更全面、更準確。Tu等人[8]在AT模型的基礎上增加論文的引用作者信息,提出了引用—作者—主題(citation-author-topic,CAT) 模型,來更好地刻畫作者的技能分布,從而服務于專家發現。Tang等人[9]在AT模型的基礎上增加了出版地信息,提出了作者—會議—主題(author-conference-topic, ACT)模型,來更好地對學術領域中的作者、話題和出版地進行建模,進而用于學術領域專家發現,取得了比其他話題模型更好的效果。
上述模型在分析用戶技能(或興趣)方面仍然存在一些不足之處。這些模型都是從內容生產者的角度考慮了用戶發表或者轉發的文檔,而沒有站在內容消費者的角度考慮用戶閱讀、評論或收藏的文檔。事實上,用戶生產的內容更多地反映了用戶的技能,而用戶消費的內容更多地反映了用戶的興趣。通常情況下,用戶的技能比較集中,而用戶的興趣則相對比較分散。因此,本文綜合考慮文檔的作者信息和讀者信息,提出了一種新穎的作者—讀者—話題(ART)模型來同時對在線技術社區用戶的技能和興趣進行建模。
2 用戶技能及興趣發現
本節首先簡單介紹兩個關于用戶技能/興趣建模的基礎模型LDA模型和AT模型,然后將詳細描述本文提出的作者—讀者—話題(ART)模型,并對模型進行推導。表1列出了本文主要使用的符號及其含義說明。
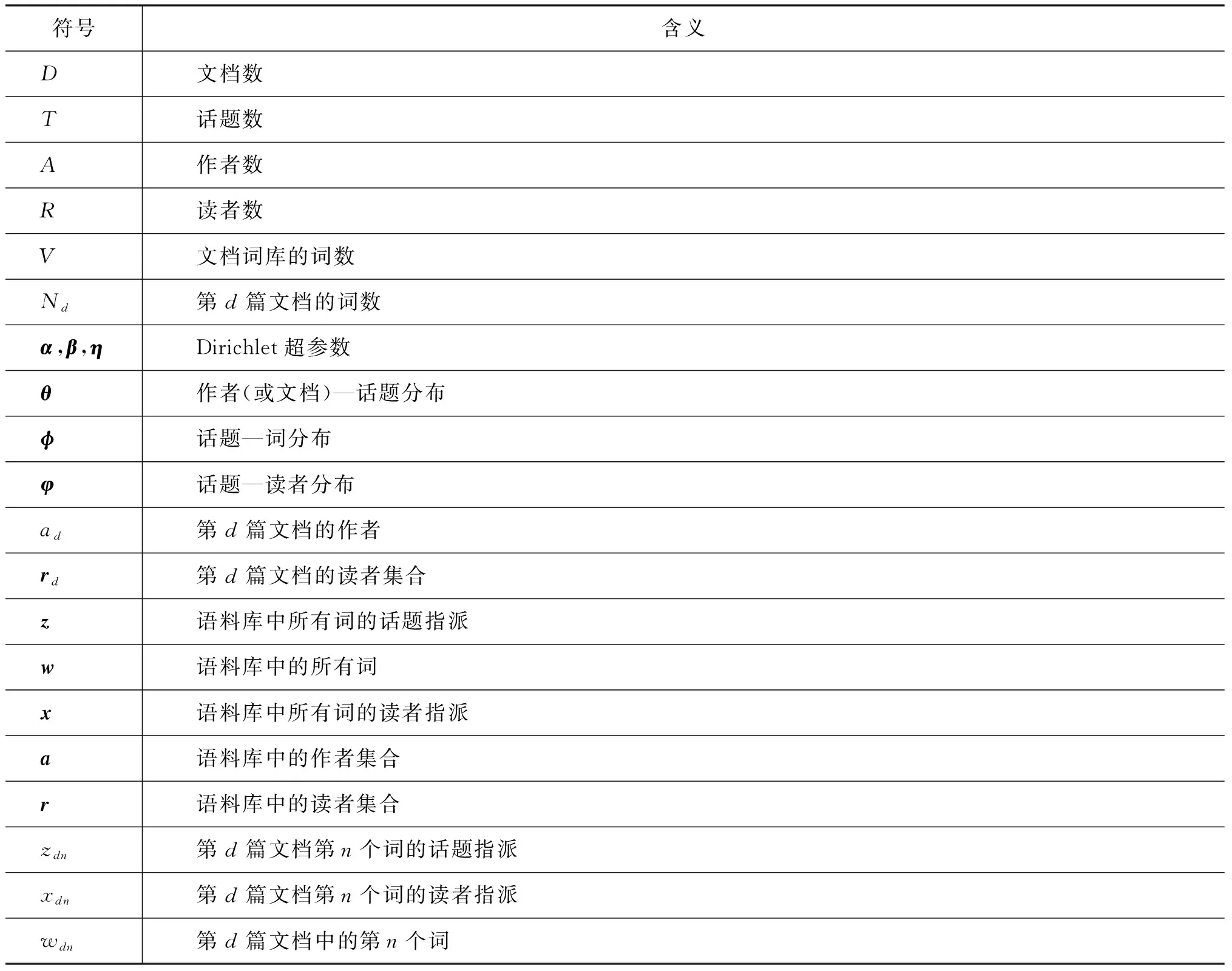
表1 相關符號說明
2.1 基礎模型
2.1.1 LDA模型
LDA模型[6]是一種層次式的貝葉斯概率模型,包含詞、話題和文檔三層結構,語料庫中的每篇文檔被建模為隱話題的多項式分布,每個話題又被建模為詞的多項式分布,每篇文檔中的每個詞都是通過“以一定概率選擇了某個話題,并從這個話題中以一定概率選擇某個詞”這樣一個過程得到。LDA模型的盤式表示如圖1所示。為了生成一篇文檔,首先根據文檔的話題分布采樣生成一個話題,然后根據該話題的詞分布采樣生成一個詞。重復上述過程直到文檔中所有詞均已生成。由于LDA模型中存在隱變量,直接求解模型參數非常困難,因此LDA模型的推導一般采用變分法或吉布斯采樣進行近似推斷[6,14]。
采用LDA進行用戶技能或興趣發現時,在模型中不考慮文檔的用戶信息,而是在求解模型得出每篇文檔的話題分布之后,對每個用戶對應的全部文檔的話題分布求平均,形成用戶的話題分布,進而根據用戶—話題分布和話題—詞分布生成用戶的技能表示或興趣表示。
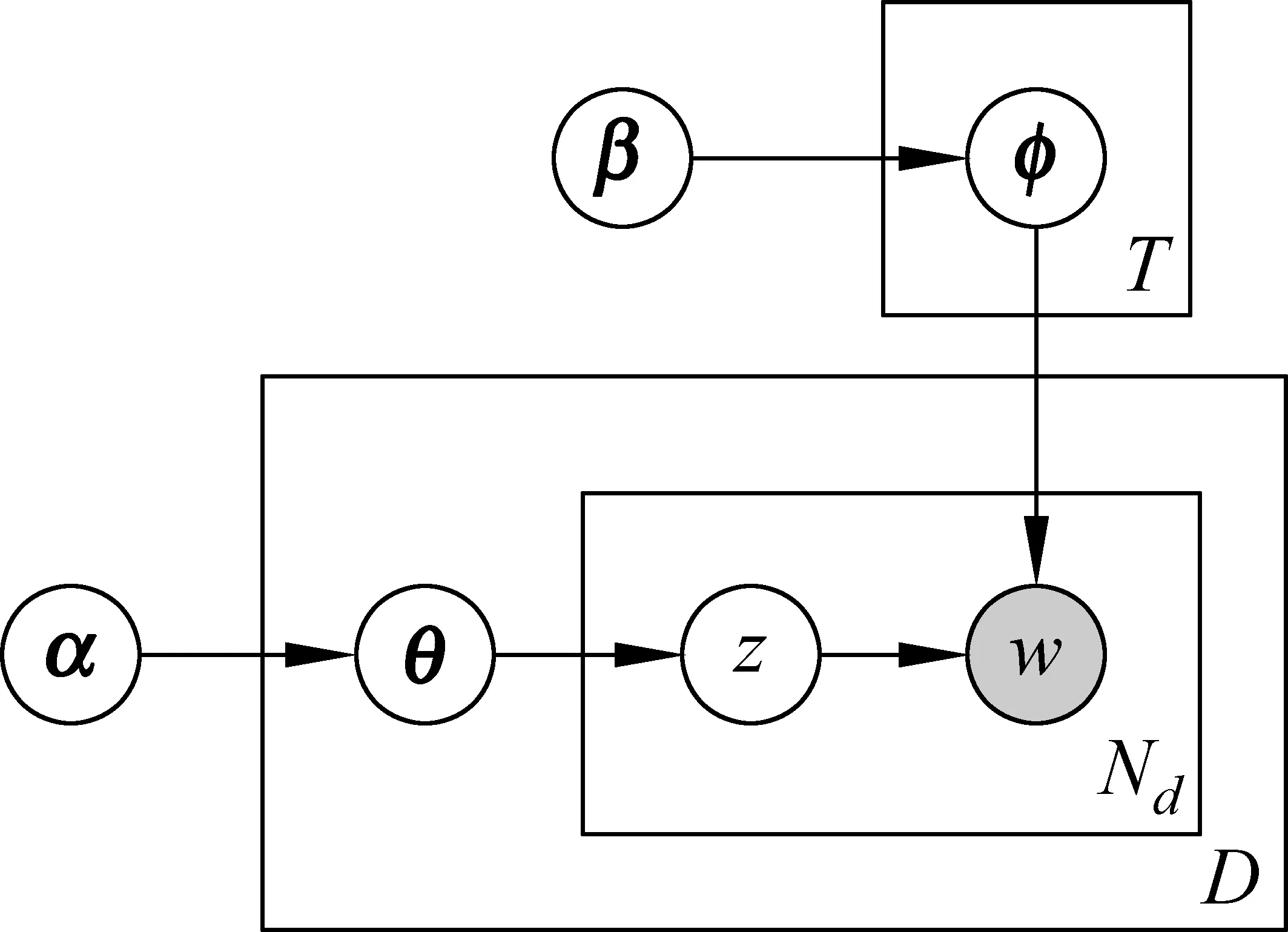
圖1 LDA模型的盤式表示
2.1.2 作者—話題模型
作者—話題(author-topic,AT)模型[7]是對LDA模型的一種拓展變形,是一種較新穎的話題模型,它包含詞、話題、文檔和作者四層結構,在建模過程中加入了文檔的作者信息。該模型假設語料庫中的每個作者都對應一個隱話題的多項式分布,每個話題都對應一個詞的多項式分布。AT模型與LDA模型的不同之處在于它用作者—話題分布替換了文檔—話題分布,并且每個詞對應兩個隱變量,即話題和作者。AT模型的盤式表示如圖2所示,其文檔生成過程與LDA的區別在于,它首先從文檔的作者集合中隨機選擇一個作者,然后根據該作者的話題分布采樣生成一個話題,最后再根據該話題的詞分布采樣生成一個詞。重復上述過程直到文檔中所有詞均已生成。同樣,AT模型的推導通常也采用變分法或吉布斯采樣進行近似推斷。
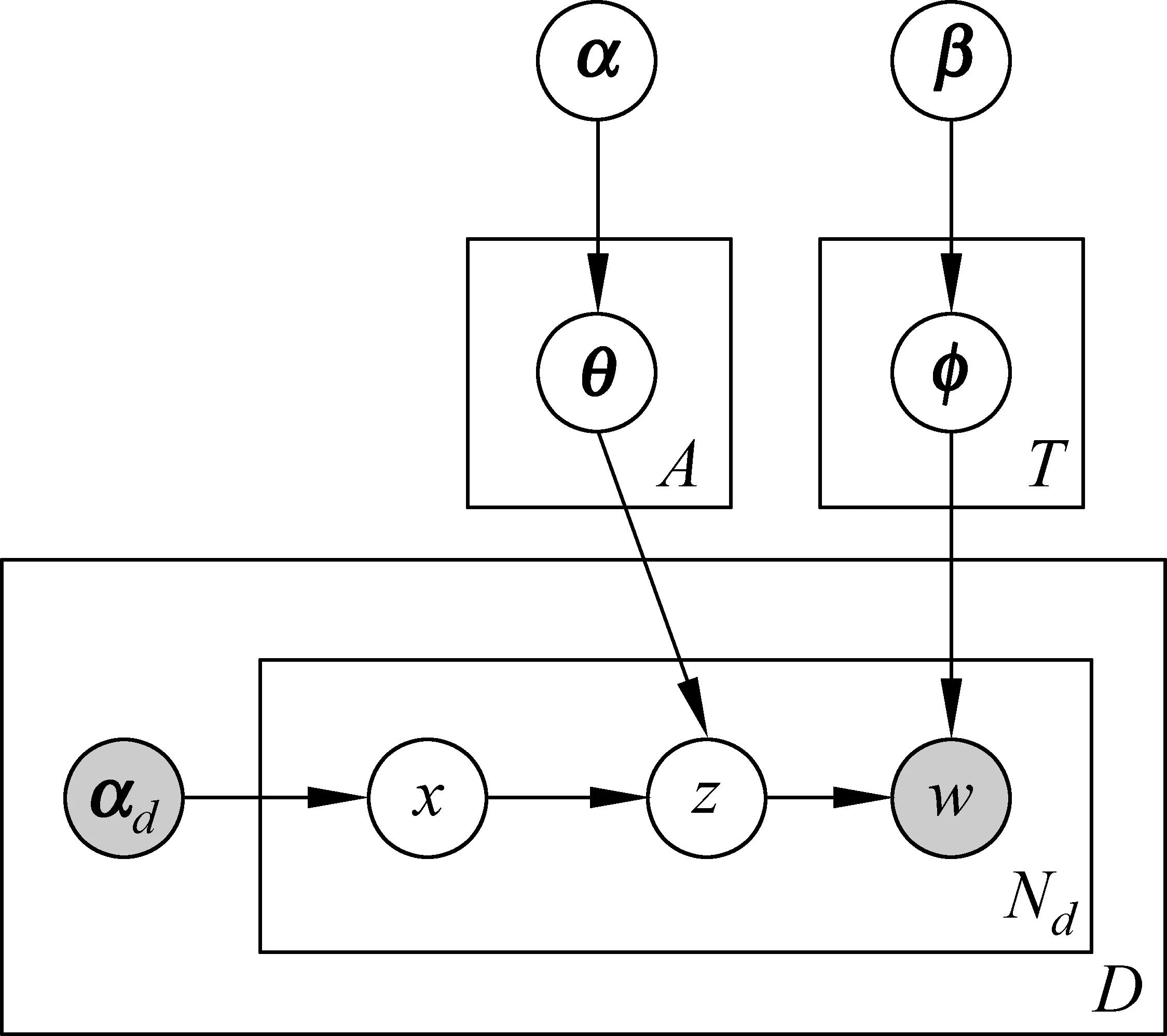
圖2 AT模型的盤式表示
AT模型由于在建模過程中加入了作者信息,通常一個作者的話題分布是比較穩定的,因此有助于增強話題的聚集效果。得益于作者信息的加入,相比LDA模型,AT模型能夠更準確地發現用戶的技能分布。AT模型雖然引入了文檔的作者信息,但沒有考慮文檔的讀者信息對話題的聚集效果,以及進一步的提升作用。此外,用戶分別作為作者和讀者時,其話題分布也是不一樣的。作為作者時對應的是其技能的話題分布,作為讀者時則對應其興趣的話題分布。因此,本文進一步提出了作者—讀者—話題模型,對用戶的技能和興趣分別進行建模。
2.2 作者—讀者—話題模型
2.2.1 模型描述
在技術社區中,用戶經常將自己的技術知識和經驗以博客或者帖子的形式發表出來,供其他用戶學習、參考或討論,此時用戶作為生產者所發表的內容通常體現了他們所具有的技能。另一方面,用戶也經常搜索、瀏覽、評論、頂踩、收藏自己感興趣的內容,此時用戶作為消費者所關注的內容則體現了他們所擁有的興趣愛好。一般情況下,用戶的技能比較集中于少量的一個或幾個話題,而用戶的興趣則可能相對比較廣泛地分布于多個話題。基于這一事實,我們提出將用戶的技能話題分布和興趣話題分布區別對待,分別使用生產者(作者)和消費者(讀者)的身份來發現用戶的技能和興趣。我們以LDA模型為基礎,同時加入文檔的作者和讀者信息,形成作者—讀者—話題(author-reader-topic,ART)模型。ART模型將用戶作為作者和讀者的兩種身份信息加入到話題的建模過程中,不僅可以進一步增強話題的聚集效果,還可以同步分別建模用戶的技能和興趣。該模型的直觀含義是: 文檔的作者決定了文檔的話題,而文檔的話題決定了詞的生成并且吸引對該話題感興趣的用戶對該文檔進行閱讀。
與AT模型類似,ART模型仍然是一種層次式的貝葉斯概率模型,它包含詞、話題、文檔、作者和讀者五層結構,其盤式表示如圖3所示。在ART模型中,每篇文檔d對應一個作者ad和多個讀者rd,每個作者a對應的話題的多項式分布為θa,每個話題t對應的詞的多項式分布為φt以及讀者的多項式分布為φt。該模型的文檔生成過程的形式化描述見算法1: 首先,根據Dirichlet超參數分別采樣作者—話題分布θ、話題—詞分布φ以及話題—讀者分布φ,其分別服從Dirichlet分布Dir(α)、Dir(β)和Dir(η);然后,對于每篇文檔中的每個詞,根據文檔對應作者的作者—話題分布θ采樣生成一個話題z,z服從多項式分布Mul(θ);接下來,基于生成的話題z分別獨立地從話題—詞分布φ和話題—讀者分布φ中采樣生成一個詞w和一個讀者x,w和x分別服從多項式分布Mul(φ)和Mul(φ)。
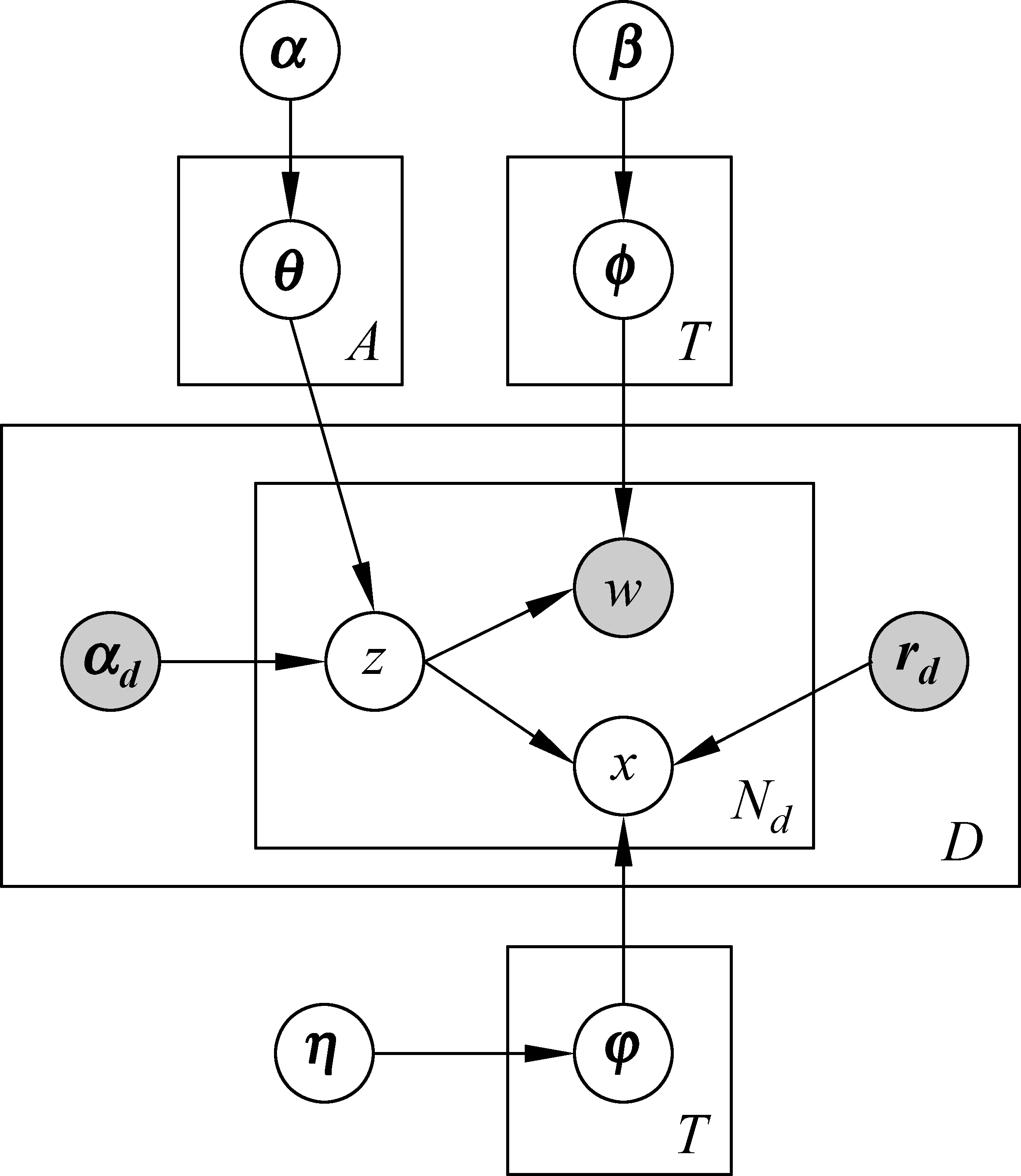
圖3 ART模型的盤式表示

算法1 ART模型的文檔生成過程for each author a∈Ado //draw a distribution over topics θa~Dir(α)end forforeach topic t∈T do //draw a distribution over words ?t~Dir(β) //draw a distribution over readers φt~Dir(η) end forforeach document d∈[1,D] and its author ad do foreach word n∈[1,Nd] do assign a topic zdn~Mul(θad); draw a word w~Mul(?zdn); draw a reader x~Mul(φzdn); end forend for
給定超參數α,β,η以及文檔d的作者ad和讀者rd,語料庫的生成概率如式(1)所示。
P(θ,φ,φ,z,w,x|α,β,η,a,r)=
(1)
2.2.2 模型推導
我們采用吉布斯采樣方法來近似推導ART模型。吉布斯采樣是一種高效的MCMC(Markov Chain Monte Carlo)采樣方法,它通過迭代采樣方式對復雜的概率分布進行推斷。為了得到參數θ、φ和φ,需要計算詞wdn的話題指派和讀者指派的條件分布p(zdn,xdn|z-dn,x-dn,w,ad,rd,α,β,η),其中,z-dn和x-dn分別指除文檔d中第n個詞以外的其他所有詞的話題指派和讀者指派(符號-dn表示排除當前詞wdn)。為了簡化公式的描述,我們引入Δ函數(the Dirichlet delta function)[15],對于含有V維的Dirichlet先驗參數δ,Δ函數定義,如式(2)所示。
(2)
其中,Γ(·)是伽瑪函數。
基于圖3中概率圖模型的獨立性假設,給定超參數,則話題、讀者和詞的聯合分布可形式化推導,如式(3)所示。
(3)

(4)
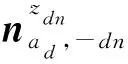
吉布斯采樣收斂后,我們就可以根據采樣的結果估計作者—話題分布θ,話題—詞分布φ以及話題—讀者分布φ,分別如式(5)~(7)所示。
ART模型的吉布斯采樣方法的詳細推導見附錄。我們使用吉布斯采樣進行參數估計的算法流程詳見算法2。

算法2 ART模型的參數估計initialize the reader and topic assignments randomly for all tokens;//Gibbs sampling over burn-in period and sampling periodwhile not finished do for all documents d∈[1,D]do for all words n∈[1,Nd] in document ddo draw xdn and zdn from Eq. (4); update nzdnad,nad,nwdnzdn,nzdn,nxdnzdn; end for end for //check convergence and read out parameters if converged and L sampling iterations since last read out then //the different parameters read outs are averaged read out parameter set θ according to Eq. (5); read out parameter set ? according to Eq. (6); read out parameter set φ according to Eq. (7); end ifend while
3 實驗
本節將詳細介紹基于CSDN技術社區數據集的實驗過程及結果分析,將本文提出的ART模型與經典的LDA模型、在技能發現方面表現最好的AT模型以及衍生的讀者—話題(RT)模型三種基準方法進行了對比,驗證了ART模型在用戶技能和興趣發現方面的優勢。
3.1 數據集
本文使用的數據集來自全球最大的中文IT技術社區CSDN。我們從CSDN采集了2015年01月至2016年7月之間部分活躍用戶產生的內容和行為記錄,其中用戶產生的內容包含用戶在該時間段內發表的所有博客,以及用戶的自定義技能標簽和興趣標簽;用戶行為記錄包括在該時間段內用戶對博客的瀏覽、頂踩、評論和收藏行為的日志記錄。其中,用戶自定義技能標簽和興趣標簽用來評估本文提出的技能與興趣發現方法的效果,用戶瀏覽、頂踩、評論和收藏過的文檔均視為該用戶讀過的文檔。值得注意的是,所有涉及用戶個人隱私的信息,均不包含在采集的數據集之中。
數據集共包含與4 357位用戶相關的27 880篇博客文檔,其中部分用戶既是作者又是讀者。我們對所有文檔進行了必要的預處理,包括去除文檔中的HTML標記、程序代碼塊以及URL鏈接,然后采用NLPIR分詞工具[16]進行分詞,并在分詞過程中使用了清華大學開放IT詞庫[17],最后去除停用詞并去除TF-IDF值較低的詞。處理后的數據集統計信息如表2所示。
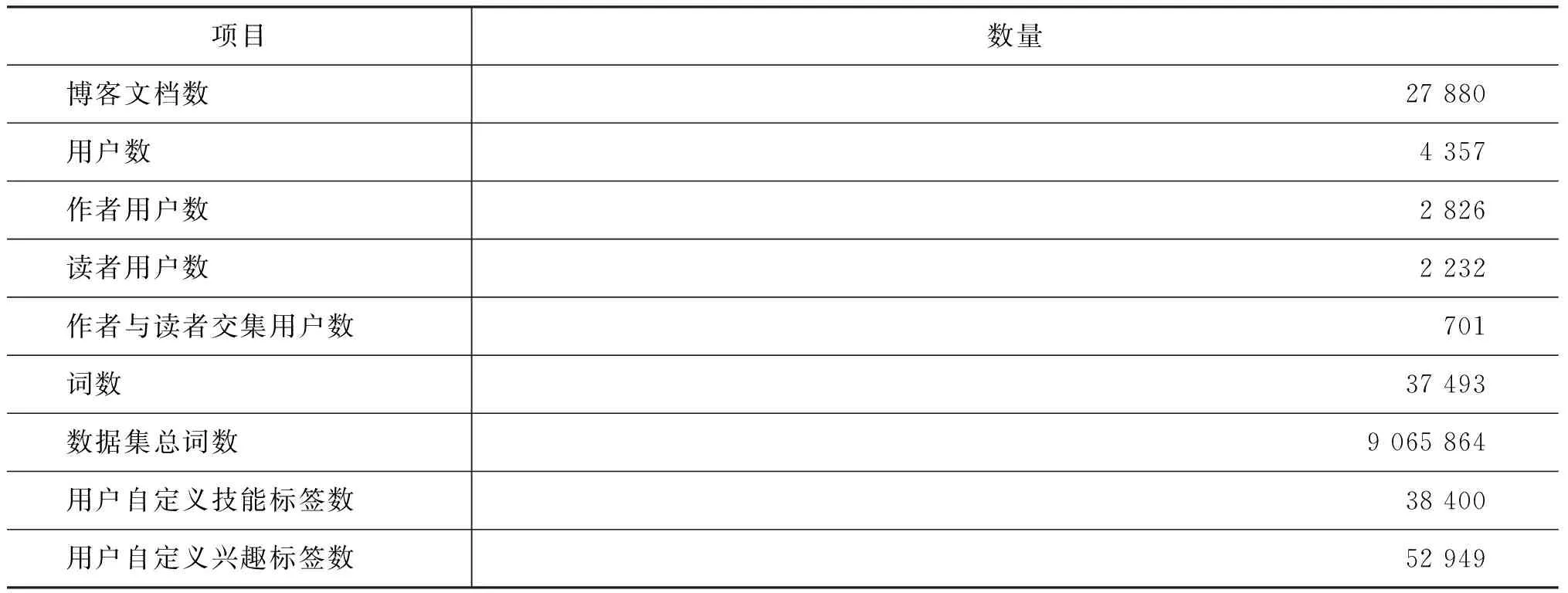
表2 數據集統計信息
3.2 基準方法
我們在實驗過程中采用三種基準方法與本文提出的ART模型進行對比。除了經典的LDA模型和當前在技能發現方面表現最好的AT模型,我們還基于AT模型和ART模型衍生出一種讀者—話題(reader-topic,RT)模型,用來單獨對用戶的興趣進行建模。RT模型的盤式表示如圖4所示,它和ART模型的區別在于沒有將文檔的作者信息加入到模型中,只保留了讀者信息,因此只用來建模用戶興趣。RT模型的文檔生成過程和ART模型類似,首先,根據Dirichlet超參數分別采樣文檔—話題分布θ、話題—詞分布φ以及話題—讀者分布φ,其分別服從Dirichlet分布Dir(α)、Dir(β)和Dir(η);然后,對于每篇文檔中的每個詞,從文檔—話題分布θ中采樣生成一個話題z,z服從多項式分布Mul(θ),進而基于生成的話題z分別獨立地從話題—詞分布φ和話題—讀者分布φ中采樣生成一個詞w和一個讀者x,w和x分別服從Mul(φ)和Mul(φ)分布。RT模型的文檔生成過程以及吉布斯采樣的推導過程和ART模型類似,本文在此不再贅述。
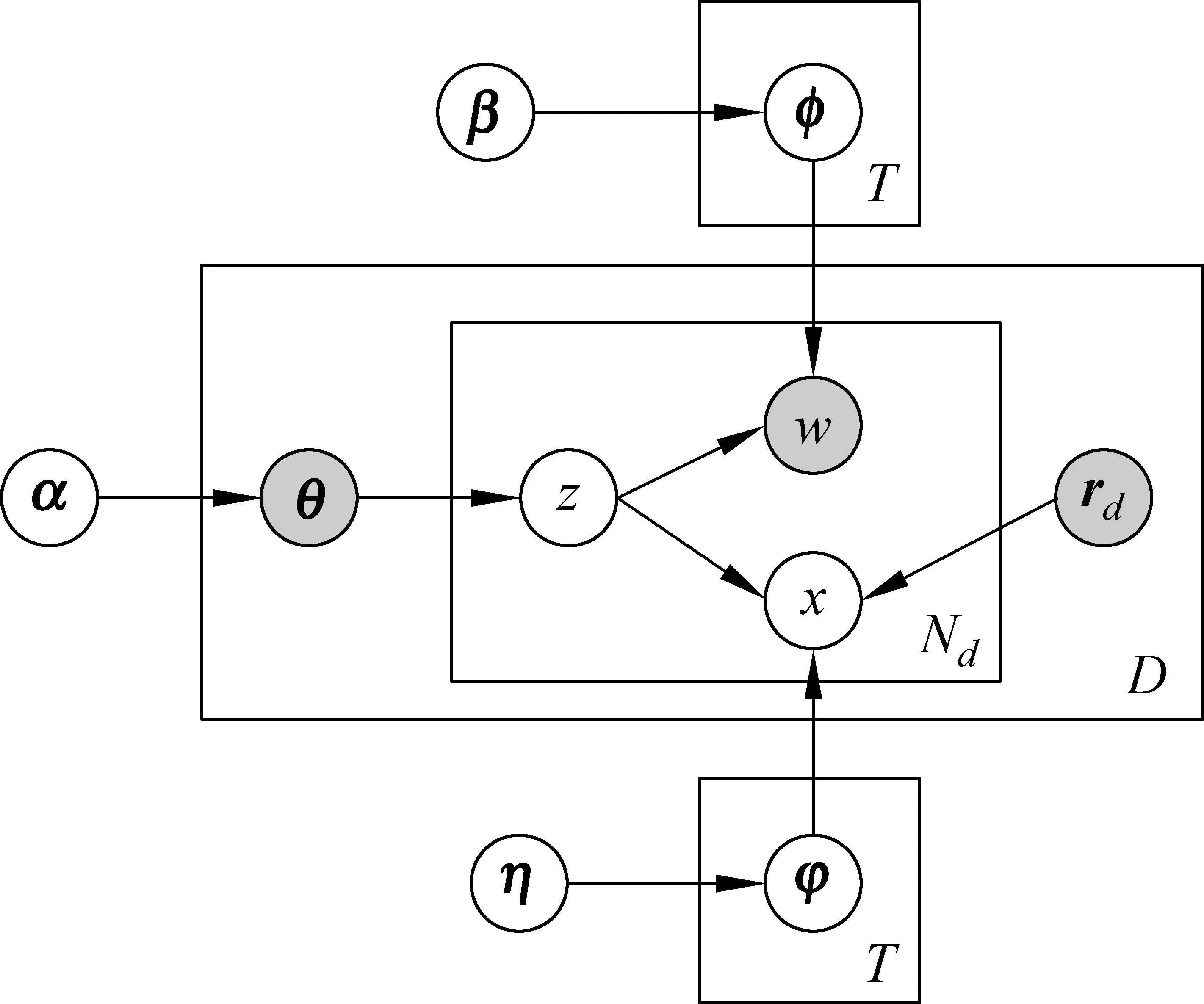
圖4 RT模型的盤式表示
3.3 實驗參數設置
在實驗過程中,為了對四種模型進行相互比較,我們對四種模型的話題數目及其他超參數進行了相同的設置。對于話題數目,我們根據數據 集 的 話 題分布情況經驗性地設置話題數T=100;對于其他超參數,我們嘗試了不同的超參數設置,發現模型效果并沒有受到超參數的較大影響,因此根據文獻[14],我們將超參數設置為固定值:α=50/T、β=0.01、η=0.1。在模型訓練過程中,我們發現模型迭代1 500次左右就基本達到收斂狀態,為了統一標準并確保所有模型都能達到收斂,我們對四種模型均設置迭代次數為2 000次。
3.4 話題聚集結果
ART模型迭代收斂后,可以利用式(6)來提取整個數據集的話題。我們首先從100個話題中篩選出10個話題,并盡量讓這些話題覆蓋不同的技術領域,然后列出每個話題的前10個詞,如表3所示。通過分析每個話題下代表性詞匯的含義,給出了每個話題的語義。我們發現,ART模型聚集出來的話題比較容易理解,每個話題下的大部分詞匯在語義上都與話題有較強的相關性。
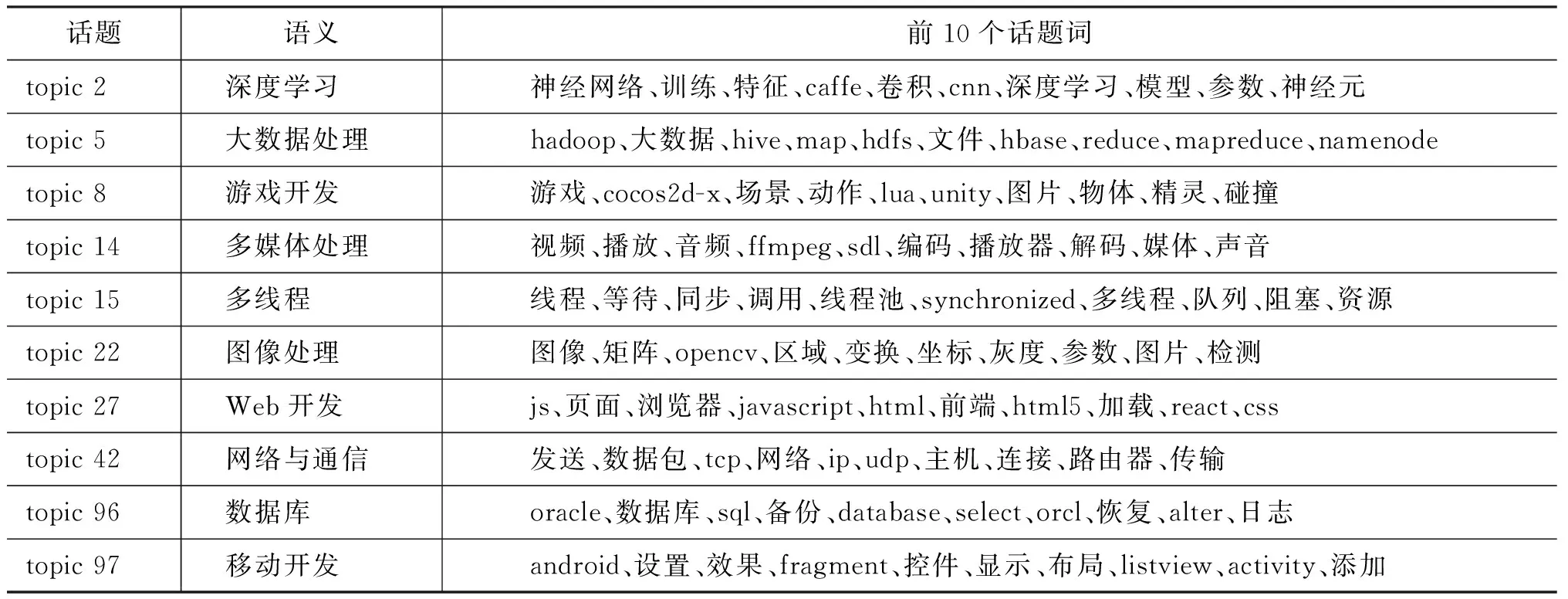
表3 數據集話題聚集結果
3.5 用戶技能詞和興趣詞提取結果
通過式(6)我們可以得到每個話題的詞分布φ,通過式(5)和(7)可以分別得到每個作者的話題分布θ和每個讀者的話題分布φ,然后通過整合作者—話題分布和話題—詞分布來計算用戶的技能詞,通過整合讀者—話題分布和話題—詞分布來計算用戶的興趣詞,形式化公式分別如式(8)和式(9)所示。計算用戶技能詞和興趣詞的核心思想在于計算作者(或讀者)、話題和詞的聯合分布的積分,式(8)中Ωaw表示作者a在技能詞w上的相關度,式(9)中Ηrw表示讀者r在興趣詞w上的相關度。
通過式(8)~(9)我們可以計算每個作者對詞匯集V中每個詞的技能相關度以及每個讀者對詞匯集V中每個詞的興趣相關度,從而得到和每個用戶相關度比較高的技能詞和興趣詞。表4和表5分別列出了四個代表性用戶的前十個技能詞和前十個興趣詞,這四個用戶的自定義技能標簽和興趣標簽如表6所示。

表4 各種模型發現的用戶技能詞

表5 各種模型發現的用戶興趣詞
續表
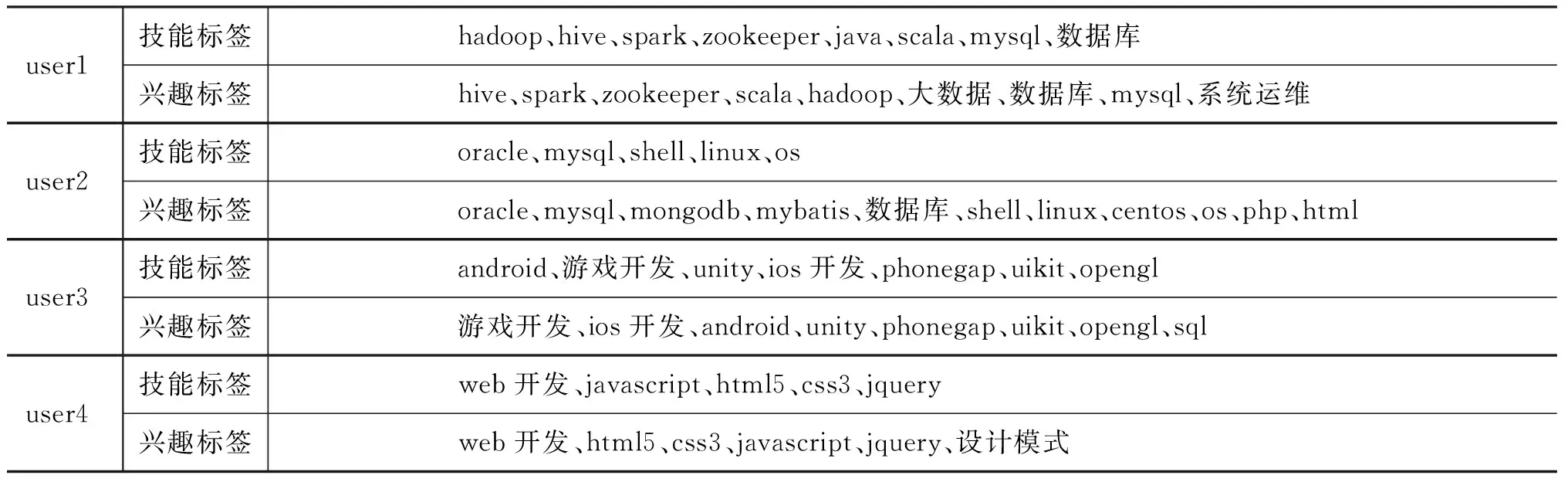
表6 用戶自定義技能和興趣標簽
將表4和表5的結果分別與用戶自定義技能標簽和興趣標簽進行比較,我們發現ART模型發現的技能詞和興趣詞與用戶的自定義標簽相關度較高。例如,user1的自定義技能和興趣標簽體現在“大數據”領域,而ART發現的諸如“hadoop”“hive”“spark”等詞與此的相關度較高;user2的自定義技能和興趣標簽體現在“數據庫”和“操作系統”領域,而ART發現的諸如“oracle”“mysql”“進程”“命令”等詞與此相關度較高;user3的自定義技能和興趣標簽體現在“移動開發”和“游戲開發”領域,而ART發現的諸如“android”“游戲”等詞與此相關度較高;user4的自定義技能和興趣標簽體現在“web開發”領域,而ART發現的諸如“javascript”“html”等詞與此相關度較高。
將表4和表5中ART模型發現的用戶技能和興趣之間進行比較,我們發現用戶的技能和興趣相似度很高,但用戶的技能更加專一,用戶的興趣則相對廣泛。例如,user1的技能和興趣都體現在“大數據”領域,但user1還對“系統運維”比較感興趣;user3的技能和興趣都體現在“游戲開發”“移動開發”領域,但user3還對“數據庫”比較感興趣;user4的技能和興趣都體現在“web開發”領域,但user4還對“設計模式”比較感興趣。為了進一步分析用戶技能分布和興趣分布之間的差異,我們分別計算作者技能分布熵(簡稱技能熵)和讀者興趣分布熵(簡稱興趣熵),如式(10)~(11)所示。
我們計算了701個既是作者又是讀者的用戶的技能熵和興趣熵,并進行了相關統計,結果如表7所示。從表中可以看出,興趣熵的平均值要高于技能熵,這進一步表明了用戶技能的專一性和用戶興趣的廣泛性。

表7 技能熵與興趣熵統計值比較
表4和表5分別列出了LDA、AT和RT三種基準方法提取的用戶技能詞和興趣詞結果,從表中可以看出,在用戶技能發現方面,相比于其他三個模型,ART模型發現的技能詞與用戶自定義技能標簽相關度更高,而且相關度高的詞排序更加靠前;同樣,在用戶興趣發現方面,ART模型也要優于其他三個模型。為了定量評價四種模型在發現用戶技能和興趣方面的優劣,我們將四種模型發現的技能詞和興趣詞分別和用戶自定義技能標簽和興趣標簽求交集,計算技能發現和興趣發現的準確率和召回率,如式(12)~(15)所示:
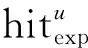
具體地,我們分別計算出各種模型發現的每個用戶的前K(K=5,10,20,50,100)個技能詞和興趣詞,與該用戶自定義技能標簽和興趣標簽求交集,計算每個用戶技能發現和興趣發現的準確率和召回率,然后對所有用戶求平均。四種模型技能發現的準確率和召回率如表8和表9所示,興趣發現的準確率和召回率如表10和表11所示。從表中可以看出,在技能發現方面,ART要顯著優于AT模型,AT模型要優于RT模型,LDA模型效果最差;在興趣發現方面,ART要顯著優于RT模型,RT模型要優于AT模型,同樣LDA模型效果最差。需要說明的是,準確率和召回率整體不高的原因,一方面是因為用戶自定義的技能標簽和興趣標簽通常更抽象,而模型發現的技能詞和興趣詞通常更具體;另一方面,用戶自定義標簽也存在更新不及時等問題,因此兩者的交集偏少,從而導致準確率和召回率偏低,但這并不會影響其作為模型評價標準的客觀性和公正性。

表8 四種模型技能發現的準確率比較 單位: %

表9 四種模型技能發現的召回率比較 單位: %

表10 四種模型興趣發現的準確率比較 單位: %

表11 四種模型興趣發現的召回率比較 單位: %
以上實驗結果證明,隨著作者信息和讀者信息的加入,ART模型提高了話題聚集效果,能夠更準確地同時對用戶的技能和興趣進行建模,顯著優于其他現有的技能或興趣發現方法。
4 結論
本文提出了一個新穎的作者—讀者—話題(ART)模型來同步發現在線技術社區中用戶的技能和興趣。該模型能夠有效地將文檔的作者信息和讀者信息關聯起來,提升話題聚集效果,產生更準確的作者技能話題分布和讀者興趣話題分布。
在CSDN社區的真實數據集上的實驗結果表明,本文提出的ART模型能夠有效地發現用戶的技能和興趣,提取的用戶技能詞和興趣詞比其他現有的技能或興趣挖掘方法更準確。與此同時,我們也驗證了用戶技能相對集中、用戶興趣相對分散的假設。本文提出的方法可以廣泛應用于在線社區的用戶技能與興趣挖掘,服務于社區運營者進行用戶畫像,向用戶提供精準推薦和個性化服務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
故事作文·高年級(2023年10期)2023-10-23 11:21:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國公路(2017年19期)2018-01-23 03:06:33
學苑創造·A版(2017年6期)2017-06-23 14:10:46
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
