基于擴展近鄰SMOTE過采樣的SVM分類器
2018-08-02 07:23:40宋艷白治江
現代計算機 2018年15期
宋艷,白治江
(上海海事大學信息工程學院,上海 201306)
0 引言
不平衡數據集是指數據集中某類別樣本的數量在整個數據集中占主導優勢。一般把數據集中數量較多的類標記為多數類或負類,數量處于劣勢的類標記為少數類或正類。這類數據在現實生活中普遍存在,如網站中用戶搜索行為,客戶的個人信譽評估[1]。然而使用傳統的支持向量機[2]已不足以在龐大的數據集中識別出正類樣本。因此,如何在信息時代正確地區分和預測正類樣本,成為眾多學者的研究重點。
目前,多數學者主要從算法和數據兩個層面對不平衡數據進行處理。算法層面一般通過改進分類算法提高正類樣本的識別精度,如代價敏感法[3]、集成學習[4]、主動學習等。算法改進的辦法一般只適用于某些特定分布特征的數據集,因為數據集的分布仍然保持原樣。數據層面主要以欠采樣(Under-Sampling)[5]與過采樣(Over-Sampling)[6]為原型,使原始數據集中兩類樣本數量上相近。欠采樣通過隨機刪減負類樣本使兩類樣本的數量相同,卻有可能將帶有重要信息的負類樣本舍棄,從而使分類器的學習能力下降;過采樣則以隨機復制正類樣本的方式平衡兩類樣本,但新增的樣本數據不僅需額外的計算代價并且會造成過度擬合。2002年,Chawla等人提出SMOTE算法[7],極大地改善了過學習問題,但該算法新增樣本時不加區分地在正類樣本間線性插入新樣本,限制了新增樣本的生成位置,忽略了靠近分類邊界附近的樣本才影響分類邊界的位置。
鑒于SMOTE算法插值的局限性,眾多學者在此基礎上提出了改善策略。Han等人提出了Borderline-SMOTE方法[8],其基本思想是在正類數據集的邊界樣本之間線性插值,使得平衡后的數據中更多的樣本出現在類邊界附近,致使分類邊界模糊。文獻[9]在正類樣本及其最近鄰正類樣本構成的n維球體內隨機插值,擴大了新樣本生成的區域,致使數據集邊界附近聚集過多新樣本。
基于上述分析,本文提出一種結合鄰域樣本分布特征的改進型SMOTE算法(簡稱E_SMOTE算法),其要點是探察近鄰的近鄰,即用SMOTE算法插值時充分利用K近鄰候選點的M近鄰樣本分布特征,實現對新樣本分布區域的控制,克服新樣本引起的邊界模糊問題。通過實驗表明,與其他相關算法對比,本文算法確實提升了不平衡數據集的整體分類準確性。
1 相關算法簡介
1.1 SMOTE算法
SMOTE是一種過采樣方法。具體操作如下:首先,根據不平衡度設置采樣倍率N;接著,對數據集的每個正類樣本x計算其k個同類最近鄰樣本,并在這k個樣本中隨機選擇N個,記為y1y2...yN,按公式(1)生成N個新樣本;最后,把每個正類樣本新增的N個樣本加入原始數據集中,構成新的樣本數據集。

其中rand是(0,1)內一個隨機數,NewMinority代表新合成的樣本。
1.2 支持向量機
支持向量機(Support Vector Machine,SVM)是Vap?ink等人提出的以統計學習理論原理為基礎的機器學習方法。在解決分類問題、非線性和高維模式識別中展現出獨特的優勢,同時也具備抑制局部極值和過學習的特性,從而受到廣泛的關注。傳統的SVM分類器在處理樣本數量基本相同、分布均勻的數據集時,表現出極優分類結果。然而實際應用中更可能面向不平衡數據的分類問題,這使得SVM分類結果并不理想,其結果更可能偏向負類樣本,使得正類樣本分類精度下降。
1.3 NCL(Neighborhood Cleaning Rule)
NCL基本原理:對訓練集中的每一個樣本x,計算x的3個最近鄰樣本。若x是正類樣本,且其3個最近鄰樣本中存在2或3個負類樣本,則刪除這些負類樣本,如圖1(a)所示;若x是負類樣本,且其3個最近鄰樣本中存在2或3個正類樣本,則刪除x。如圖1(b)所示。
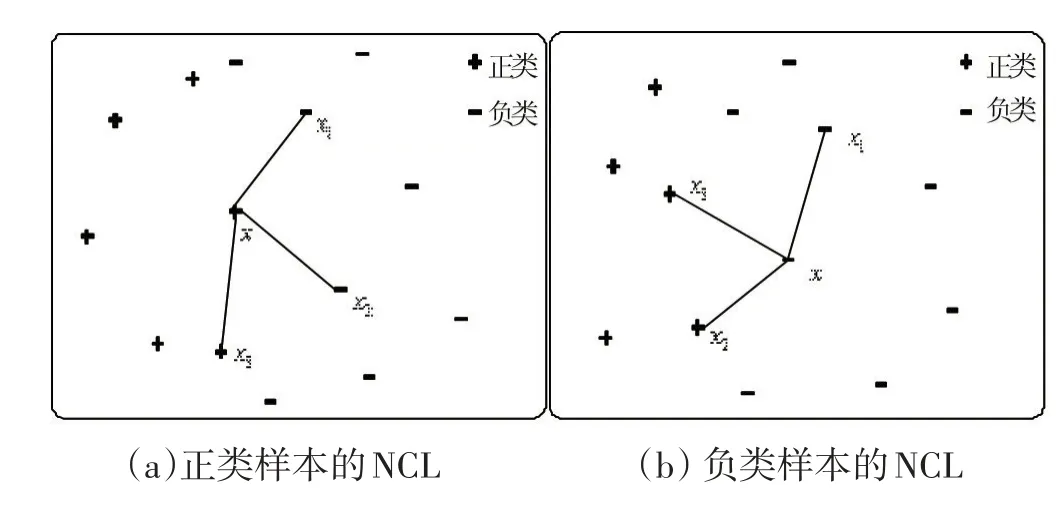
圖1 NCL原理
(a)正類樣本x的3個近鄰中,有x1和x2兩個負類樣本,所以刪除x1和x2。(b)負類樣本x的3個近鄰樣本,有x2和x3兩個正類樣本,所以刪除x。
1.4 SMOTE_NCL算法
SMOTE_NCL方法先使用SMOTE對數據集過采樣處理,然后使用NCL方法對訓練集進行欠采樣處理。該方法的缺點是當NCL清洗了一定數量的負類樣本后,可能導致兩類樣本數量再度失衡。
2 E_SMOTE算法
靠近邊界附近的樣本帶有重要信息,且決定著決策界面的位置,尤其是正類樣本稀少且寶貴。E_SMOTE算法正是通過考察正類樣本的擴展近鄰,既突出了邊界樣本的重要性,又抑制了噪聲點的干擾。為了便于描述,定義如下概念:
根據正類樣本近鄰的分布特征,把正類樣本細分[10]為安全集和非安全集兩類,具體定義如下:
定義1(安全集)S1={x|x的k近鄰樣本全部是正類樣本}。
定義2(非安全集)S2={x|x的k近鄰樣本不全是正類樣本}。
E_SMOTE算法基本思想如下:SMOTE算法對非安全集中每一個樣本x與其正類近鄰樣本xi合成新樣本時,如果 xi的 M個最近鄰樣本存在ω(M/2≤ω≤M)個負類樣本,則不做任何處理,否則在x和xi之間插入一個新樣本,重復這一過程直到非安全集中所有樣本處理完畢。該算法中M2向上取整。該線性插值過程如圖2所示,正類樣本點x屬于非安全集,假設采樣倍率N=2。
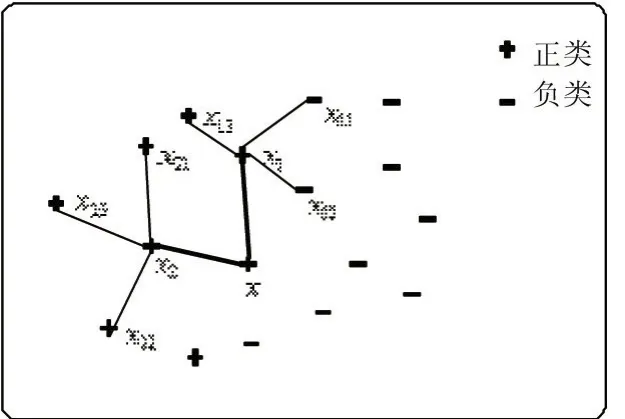
圖2 非安全集插樣示例
圖2表示,從x的同類最近鄰樣本中隨機選擇2個樣本點,這里選擇x1和x2;x1的3個最鄰近樣本存在2個負類樣本點(x11和x12),則x與x1之間不合成新樣本;而x2的3個近鄰樣本全部為正類樣本,則在x與x2之間根據SMOTE算法合成一個新樣本。
E_SMOTE算法的操作步驟如下:
①設置采樣倍率N。
②根據正類樣本的k近鄰分布,把正類樣本分為安全集S1和非安全集S2。
③對S1直接應用SMOTE算法插入新樣本。
④對S2在使用SMOTE算法合成新樣本前考慮擴展近鄰的分布特征,符合條件的才插入新樣本。
⑤用平衡后的數據集訓練SVM分類器。
3 實驗設計和結果分析
3.1 數據集及評價標準
本文選取UCI庫的6種數據集完成實驗,數據集具體信息如表1所示。對多類別數據集,選擇其中樣本數目較少的一類作為正類樣本,其他類別樣本的集合作為負類樣本。例如,Wine數據集共有3個類別,本實驗把類別1標記為少數類,其余2類合在一起作為負類。
評估標準是衡量分類器性能的準則。為了客觀、公正地評價面向不平衡數據集的SVM分類器性能,結合實際需求,本文采用G-mean和F-value作為評價標準。
本文分類器性能的評價參數依據表2所示的混淆矩陣。
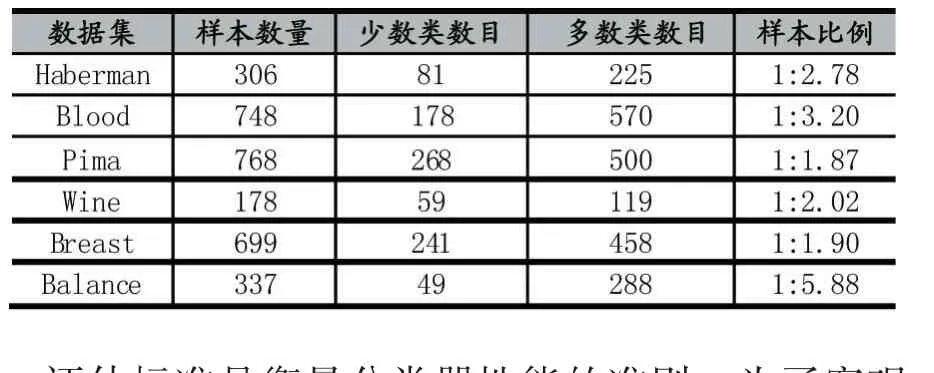
表1 數據集描述
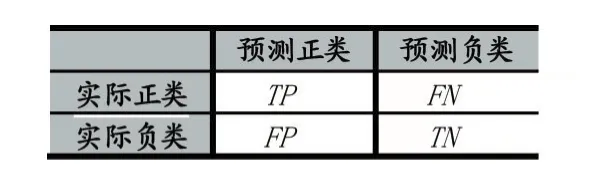
表2 混淆矩陣
利用混淆矩陣,可得:
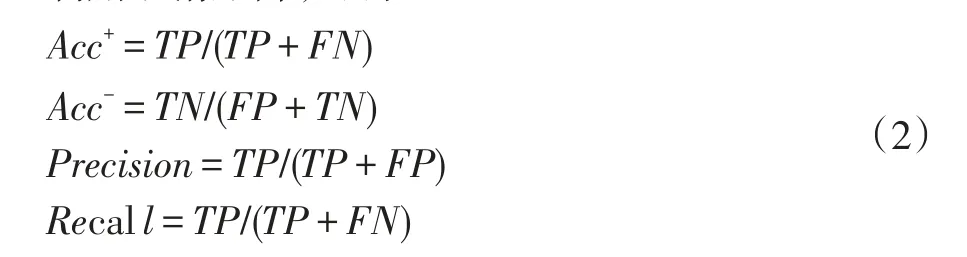
F-value標準是正類樣本的召回率(Recall)和準確率(Precision)的調和值,其值靠近Recall和Precision中的較小者。只有當兩者均較大時,F-value值才會變大。F-value計算公式如公式(3)所示:
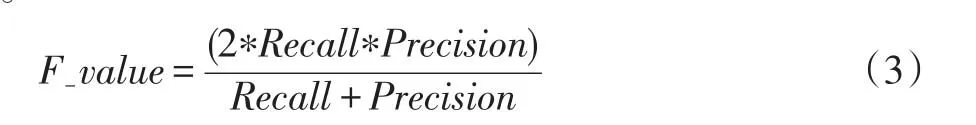
G-mean是正、負類樣本的召回率的幾何均值。當兩類的分類精度均較高時,G-mean的值才會增大。因此,采用F-value和G-mean作為衡量不平衡數據集的整體分類指標是合理的。G-mean計算公式如公式(4)所示:

3.2 實驗數據分析
本文實驗在MATLAB R2012a平臺上運行。分類器是核函數為徑向基函數(Radial Basis Function,RBF)的標準SVM。訓練分類器之前,對6個數據集分別做如下四種平衡處理進行實驗對比:①保持原樣,不做平衡處理;②用SMOTE算法過采樣;③用SMOTE_NCL算法過采樣;④用E_SMOTE算法過采樣。全部實驗對每個數據集均采用2次5折交叉驗證法,取10次分類結果的均值作為最終的分類結果,實驗結果如表3-表8所示。
實驗中SMOTE和E_SMOTE算法的近鄰參數K都設置為5,并且E_SMOTE的擴展近鄰參數M分別設置為3,4,5以便對比實驗效果。NCL數據清洗算法中近鄰參數C取3。
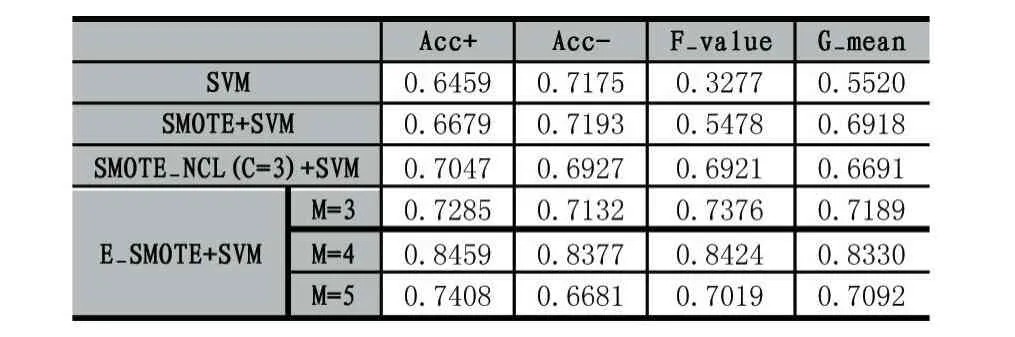
表3 Blood的分類情況
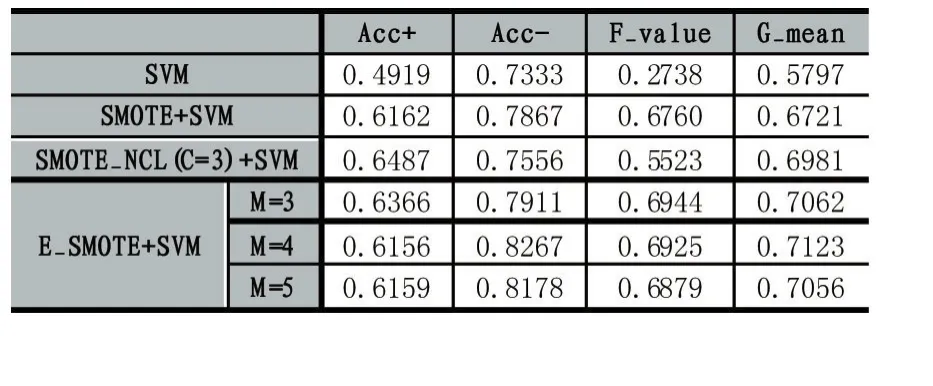
表4 Haberman的分類情況
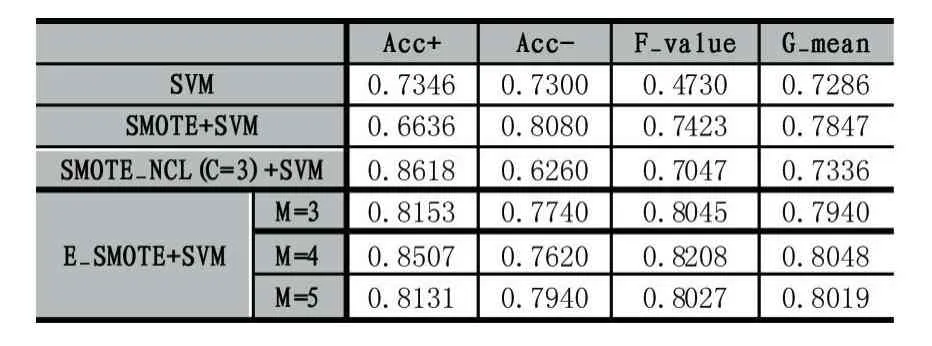
表5 Diabetes的分類情況
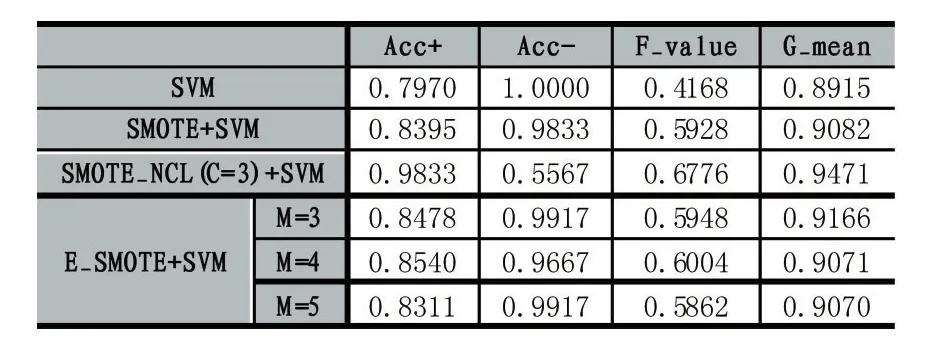
表6 Wine的分類情況
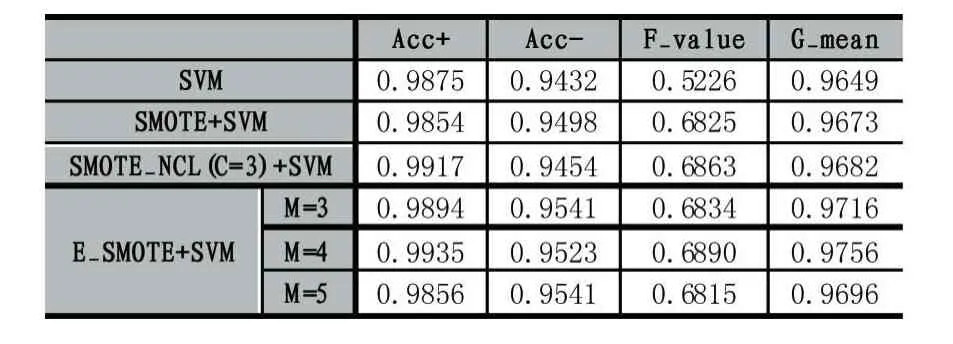
表7 Breast的分類情況
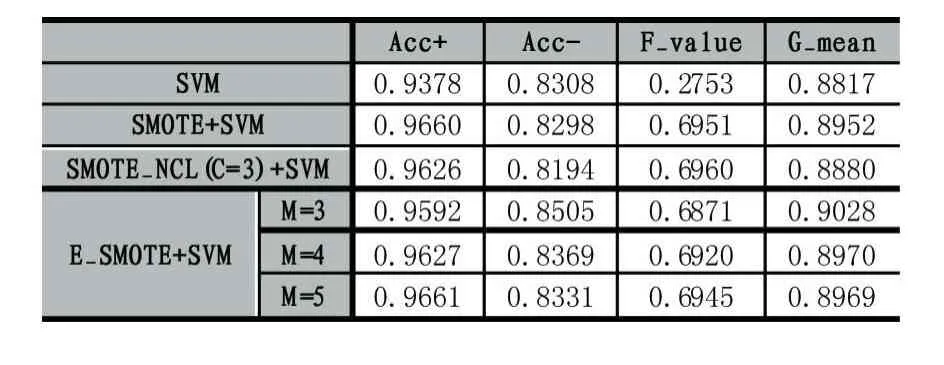
表8 Balance的分類情況
由表3-表8可知,相比在原始數據集上直接訓練SVM分類器,使用SMOTE、SMOTE_NCL和E_SMOTE算法對不平衡數據處理后提升了分類器的F-value和G-mean值。原因是對原始數據集采用SMOTE、SMOTE_NCL和E_SMOTE算法處理后,正負類樣本基本達到平衡,因此絕大部分數據集的正類樣本的識別率提升了,即 Acc+顯著增大。在 6種數據集上SMOTE_NCL較SMOTE取得更高的 Acc+值,但同時Acc-的值卻有不同程度的下降,致使SMOTE_NCL的F-value和G-mean值要么沒有顯著提高,要么略有下降,原因是在SMOTE_NCL方法中,NCL作為一種清洗式的欠采樣方法,它只按照特定的近鄰規則簡單地刪除負類樣本,使得帶有重要信息的負類樣本也可能被刪除,降低了負類樣本訓練分類器的能力。
整體上,SMOTE_NCL方法確實提升了數據集正類樣本的召回率,然而分類器的總體性能未顯著提高。當然也有例外,比如Wine數據集使用SMOTE_NCL處理后,該算法較其他算法取得更高的F-value和G-mean值,說明NCL算法并無普遍適用性,只能在具有特定分布特征的數據集上才能體現其優勢。由表3-表5可知,E_SMOTE算法比SMOTE算法獲得更高的F-value和G-mean值,這是因為E_SMOTE算法插值新樣本時綜合了擴展近鄰的分布信息,不僅能有效抑制噪聲點的影響,同時也克服了類邊界模糊的問題。而由表6-表8可以觀察到SMOTE和E_SMOTE算法整體性能基本一樣或略小,通過多次交叉驗證試驗結果對比發現,本文并沒有對相似分布特征的樣本點采取抉擇策略,而是優先選擇第一個滿足條件的近鄰樣本點,這種隨機選擇結果的差異性在表6-表8上表現較為明顯,導致整體分類精度的平均值降低。最后,6種數據集上的E_SMOTE算法比SMOTE_NCL算法的F-value和G-mean值均有不同程度的提高(除表6和表8中E_SMOTE的整體性能有微小下降)。此外,E_SMOTE算法在確保Acc+與SMOTE_NCL基本持平的情況下,其Acc-值有顯著提高。負類樣本分類精度之所以提高是因為SMOTE_NCL清洗樣本時可能刪除重要的負類樣本,而E_SMOTE方法只是針對非安全集插入新樣本時進一步考慮了擴展近鄰的分布信息,并未刪除任何負類樣本。
全部實驗中E_SMOTE算法中擴展近鄰參數M的取值設置了3,4,5三個值,可以看出,除了表6和表8中當M=3時取得最優值F-value和G-mean外,其他4個數據集都在M=4時獲得這兩個度量的最大值,說明擴展近鄰中的樣本數量要適當,既不能太多也不能太少,跟我們的直覺一致。
4 結語
平衡數據的算法是數據層面處理不平衡數據的關鍵,本文提出了一種稱作E_SMOTE的改進型過采樣算法。實驗結果表明考慮非安全集擴展近鄰的分布特征有效地提升了數據集的分類精度。本文算法的不足之處包括兩個方面,首先擴展近鄰參數M的取值只能根據實驗結果確定;其次本文使用rand函數選擇近鄰樣本,滿足M擴展近鄰即可。而沒有探察多個樣本點的M近鄰擴展分布,并引入合理的選擇機制。今后工作重點將對這兩個問題進行深入研究。
[1]李毅,姜天英,劉亞茹.基于不平衡樣本的互聯網個人信用評估研究[J].統計與信息論壇,2017,32(2):84-90.
[2]Vapnik V N.The Nature of Statistical Learning Theory[M].New York:Springer,2000:138-167.
[3]楊磊,陸慧娟,嚴珂,等.一種計算代價敏感算法分類精度的方法[J].中國計量學院學報,2017,28(1):92-96.
[4]李凱,高元,劉柏嵩.基于集成學習的標題分類算法研究[J].計算機應用研究,2017,34(4):1004-1007.
[5]李村合,唐磊.基于欠采樣支持向量機不平衡的網頁分類系統[J].計算機系統應用,2017,26(4):230-235.
[6]Batuwita R,Palade V.Efficient Resampling Methods for Training Support Vector Machines with Imbalanced Datasets[C].International Joint Conference on Neural Networks.IEEE,2010:1-8.
[7]Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:Synthetic Minority Over-Sampling Technique[J].Journal of Artificial Intelligence Research,2011,16(1):321-357.
[8]Han H,Wang W Y,Mao B H.Borderline-SMOTE:A New Over-Sampling Method in Imbalanced Data Sets Learning[C].International Conference on Intelligent Computing,icic 2005.2005:878-887.
[9]許丹丹,王勇,蔡立軍.面向不均衡數據集的ISMOTE算法[J].計算機應用,2011,31(9):2399-2401.
[10]古平,楊煬.面向不均衡數據集中少數類細分的過采樣算法[J].計算機工程,2017,43(2):241-247.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
