基于潛在興趣和地理因素的個性化興趣點推薦研究
2018-08-02 07:23:50王亞男
現代計算機 2018年15期
王亞男
(重慶大學計算機學院,重慶 400030)
0 引言
近年來,隨著定位技術的民用化,基于位置的社交網絡服務迅速發展,興趣點呈爆炸式增長,所以一個旨在幫助用戶過濾興趣點,減少其抉擇時間的推薦系統成為了迫切需要的服務。目前存在很多關于興趣點推薦的研究。舉個例子,Zheng等[1]首次運用基于用戶的協同過濾方法進行興趣點推薦。Hu等[2]對包含簽到興趣點和未簽到興趣點兩類數據的矩陣進行矩陣分解。Cheng等人[3]把用戶在位置上的簽到概率模型模擬為多中心高斯模型來捕獲地理因素,繼而把社交信息和地理信息融入到一個廣義的矩陣分解模型中。Ye等人[4]綜合基于用戶的協同過濾、基于好友的協同過濾和基于地理信息的推薦方法提出混合協同過濾算法,大大提高了推薦精度。
目前存在的關于興趣點的推薦(如Ye[4]、Cheng[5]、Gao[6])幾乎全部采用傳統的基于內存或基于模型的協同過濾技術。但是,由于用戶數據的稀疏性,這些技術都遭受嚴重的冷啟動問題。
為了應對興趣點推薦中的冷啟動,本文對現存的興趣點推薦算法進行研究,發現用戶的簽到行為在很大程度上受到相關用戶的影響。例如,Gao等[7]表示社交好友、簽到行為相似的用戶均會影響用戶的簽到行為;Li等[8]對Foursquare中的數據進行了分析,發現“兩個用戶的活動中心越接近,簽到興趣點重合度越高,即和用戶在地理位置上相近的用戶(例如鄰居)的行為會影響到用戶的簽到行為。因此,本文提出了一個能夠利用相關用戶的推薦框架,關于相關用戶會在下文給出詳細的定義。
1 相關用戶
給定用戶i,為該用戶定義了三類相關用戶:地理相關用戶、社交相關用戶、簽到相似相關用戶。
定義1(地理相關用戶):根據用戶i的歷史簽到數據,計算出用戶i的“活動中心”,地理相關用戶是和用戶i的“活動中心”距離最小的f個用戶,表示為 f(Fig),關于用戶的“活動中心”,在用戶歷史數據集上應用聚類算法來獲得。需要注意的是,在應用聚類算法之前,需要去掉那些明顯偏離的興趣點。
定義2(社交相關用戶):用戶i的社交相關用戶是數據集中直接給出的,表示為
定義3(簽到行為相似的相關用戶):計算用戶i和其余用戶的簽到相似度,在計算用戶簽到相似度時把時間因素融合到算法中,簽到行為相似相關用戶是f個和目標用戶i簽到相似度(合并時間因素)最高的用戶,表示為在下文中,將會給出如何把時間因素融入到相似度的計算中。
2 PC-Geo推薦模型
2.1 相關用戶建模
用戶的簽到行為容易受到相關聯用戶的影響,本文為每個用戶選取了三類相關用戶,并使用這些相關用戶來學習目標用戶的潛在興趣。前面已經獲得了社交相關用戶和地理相關用戶,現在還需獲得簽到相似(合并時間因素)相關用戶。
時間因素在興趣點推薦中起著重要的作用,因為用戶傾向于在一天的不同時段訪問不同的興趣點。例如,用戶習慣上午9點左右去上班,中午11點吃午飯,晚上十點左右和朋友去酒吧,人類的簽到活動表現出了明顯的時間性。因此,在計算簽到相似度時把時間作為一個影響因素考慮進去能更好地了解人類的移動行為,設計精確度更高的推薦系統。
為了證明時間因素確實會影響用戶的簽到行為,實驗時,從Foursquare中隨機選擇多個用戶,對其簽到行為隨時間的變化進行了統計分析,圖1顯示了其中一個用戶的簽到頻率隨時間的變化,從圖中可以看出,該用戶發生的大部分簽到行為集中在少數的時間段內,很多時段基本沒有簽到行為,其余的用戶也呈現類似的趨勢。因此,用戶的簽到行為呈現出很明顯的時間模式。
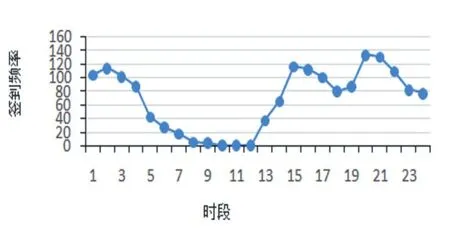
圖1 簽到頻率在每個時間狀態上的分布
從上面的分析來看,時間因素確實是影響用戶簽到行為的一個重要因素,因此,本文在考慮用戶簽到的相似度的時候增加了時間因素,采用把時間離散化的手段進行研究。首先,把一天分為多個離散時間段,定義為T。然后,把原始的用戶-興趣點矩陣按照簽到時間分成24個時段-用戶-興趣點矩陣。基于時段-用戶-興趣點矩陣,兩個用戶基于時間的相似性表示為:
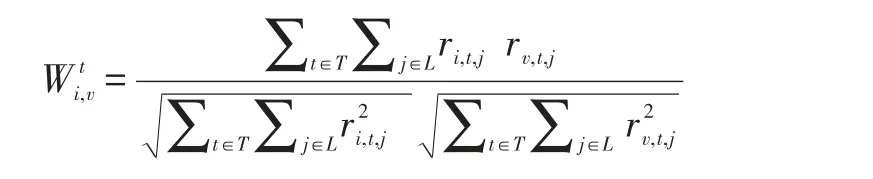
然而,原始的用戶-興趣點矩陣就是一個稀疏矩陣,經過時間處理之后得到的時段-用戶-興趣點矩陣更加稀疏。因此,不能直接使用時段-用戶-興趣點矩陣去計算兩個用戶之間的相似度。可以先利用Yuan等[9]中的方式對矩陣平移,然后在進行相似度的計算。平移過程如下所示:
給定目標用戶i,用戶i在t∈T的簽到向量為:ri,t={ri,t,1,..ri,t,L}。計算該用戶在任意兩個時段的簽到向量的相似性,取數據集中所有用戶在這兩個時段的相似值的平均值作為這兩個時段相似度,表示如下:
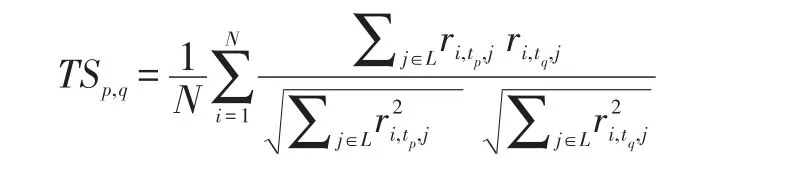
利用時段簽到相似矩陣TS來對時間-用戶-興趣點矩陣進行平移,具體平移公式如下:
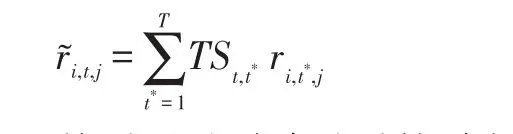
然后通過平移過后的時段-用戶-興趣點矩陣就可以進行用戶簽到相似度的計算了。
最后,把f個簽到相似相關用戶和f個地理相關用戶和社交相關用戶求并集作為目標用戶的相關用戶。
2.2 地理信息建模
不同于傳統的非空間物品的推薦,在LBSN中,每個興趣點都有獨特的地理位置,用戶在在消費產品或者享受服務的同時需要和興趣點有位置上的交互,地理因素是影響用戶簽到行為的一個重要的內容。
現存的興趣點推薦的研究中,設計到基于地理信息的興趣點推薦大多只是簡單地利用用戶的歷史位置和待訪問的興趣點之間在距離上呈現的反比關系進行推薦,或者將同一用戶簽到過的任意兩個興趣點間的距離視為冪率分布或多中心的高斯分布進行推薦。但這些方法均存在很多局限。首先,用戶訪問興趣點的概率不是距離上的單調,因為訪問的概率不僅受距離的影響還受位置固有屬性的影響。其次,每個用戶的簽到行為是獨特的,采用通用的分布函數不能體現用戶的個性化特征。本文采用核密度估計捕獲地理模型,通過該算法可以為每個用戶學習到獨特的概率密度函數,體現出用戶的個性化。
采用核密度估計捕獲地理模型方法簡述如下:首先,對于目標用戶i,其歷史簽到數據表示為Li={l1,l2,……ln}。用戶i對興趣點j的偏好度表示為Wi={w1,w2,……wn}。興趣點的位置表示為lj:(xj,yj)。論文使用高斯分布作為核密度估計中的中心函數,最終本文的核密估計函數如下:
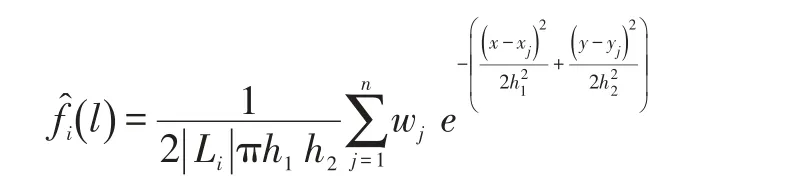
其中,h1,h2是固定帶寬,h是根據用戶i的歷史簽到數據的標準差σ得到的。
但是,只有固定的帶寬并不能反映這樣一個事實:密集的城市地區有較高的簽到密度,人口稀少的農村地區將會有較低的簽到密度,所以可以增加一個可調節的局部帶寬,這個局部帶寬hj的計算方式如下:
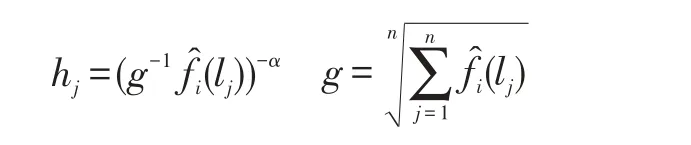
其中,α∈[0,1]是一個靈敏度參數,g是幾何平均數,因此,最終的核密度公式如下:
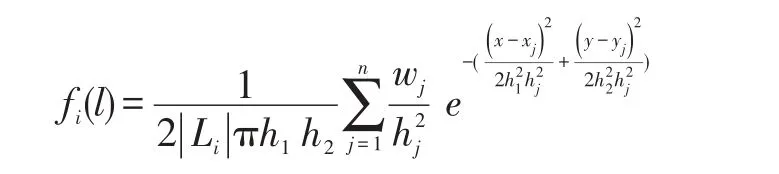
至此,完成了通過核密度估計算法為每個用戶學習到獨特的概率密度函數,通過學習到的概率密度函數,可以捕捉地理信息對于用戶簽到的影響。
2.3 用戶的潛在興趣選擇策略
在獲得用戶的相關用戶之后,把相關用戶簽到過但用戶并未簽到過的部分興趣點作為用戶的潛在興趣。但是由于待選擇的興趣點太多,本文采用線性合并用戶興趣和地理因素的算法去衡量用戶對興趣點的偏好:
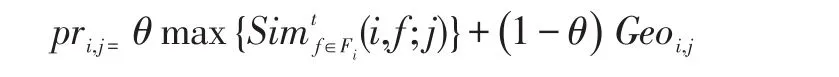
θ是控制用戶偏好和地理因素比例的調和參數。是用戶i和其相關用戶就興趣點j偏好的相似性。Geoi,j是地理對用戶簽到行為的影響,使用fi(l)進行計算。最終,選擇s個 pri,j值最大的興趣點作為用戶i的潛在興趣點。
2.4 矩陣分解和地理因素的融合
矩陣分解是一種在推薦算法中被廣泛使用的技術,不同于原始的矩陣分解,本文需要先把用戶潛在興趣點合并到用戶-興趣點矩陣中,緩解矩陣的稀疏性之后,在通過矩陣分解技術[10]構建推薦模型。對于每個用戶i,把興趣點分為三類:Li是用戶簽到過的興趣點集合。Pi是用戶潛在興趣點集合。Ui是用戶沒有簽到過且非潛在興趣點的集合,新的用戶-興趣點矩陣和權重矩陣如下所示:
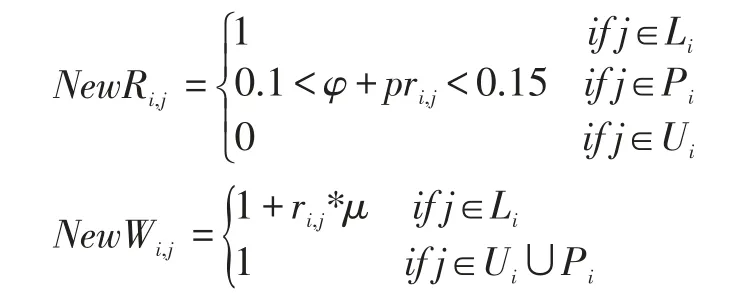
φ,μ∈[0,1]都屬于調節參數。φ+pri,j是潛在興趣點的概率,設置的過小,和未簽到興趣點的區別就不明顯了,設置的過大,會造成噪聲,所以設置它的值在0.1到0.15之間。最后本文的矩陣分解模型如下:
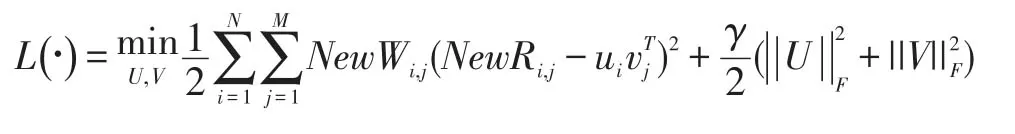
為了最小化損失函數,并且保證比快速收斂,本文采用隨機梯度下降算法,算法如表1所示:

表1 梯度下降算法
最后,本文合并地理因素對用戶簽到影響到矩陣分解中,獲得推薦模型如下所示:
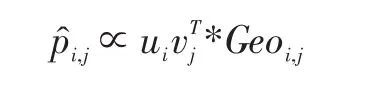
3 實驗設計
3.1 數據集

表2 Foursquare數據集統計信息
本文采用真實的數據集Foursquare,該數據集共包含兩個文件,一個是關于用戶的社交關系,表示為:〈用戶ID,好友用戶ID〉;一個是用戶的簽到日志表示為:〈簽到序號,用戶ID,簽到時間戳,興趣點ID(經度,緯度,區域),主題〉。數據集中所有的興趣點都在加利福尼亞范圍內,表2給出了數據集的詳細信息。
從表2可以看到,用戶-興趣點矩陣的簽到稀疏度為5.34×10-4,是一個非常低的值。該矩陣的稀疏導致大多數主流的興趣點推薦算法的精度普遍不高。所以,基于比較低的用戶-興趣點矩陣密度,最終得到普遍偏低的預測準確率和召回率是合理的。
本文從簽到記錄中隨機抽取80%作為訓練集,訓練隱興趣矩陣U和V,利用剩余的20%作測試集來驗證PC-Geo模型的推薦性能。為了提高實驗的可靠性,實驗采取交叉驗證的策略。
3.2 評價標準
本文采用推薦系統中常使用的評價標準準確率和召回率作為評價指標,具定義如下:
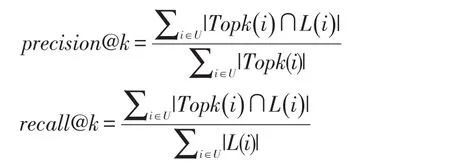
其中,L(i)表示用戶簽到過的位置集合,Topk(i)表示向用戶推薦的位置集合。實驗中,k值設置為5,10。隱式空間的維度設置為10,相關用戶的個數f設置為10,用戶潛在興趣點s設置為300,重構矩陣的調節參數φ為0.1μ為0.3。在梯度下降中,學習速率設置為0.002,用戶和興趣點的權重設置為相同的0.02。
3.3 不同推薦算法的對比
本文選定三個優秀的推薦算法進行對比。
BaseMF:對原始的用戶-興趣點矩陣進行矩陣分解[11]。DRW:基于動態隨機游走模型,融合用戶社會關系、類別信息和流行度信息進行推薦[12]。LRT:把用戶簽到的時序模式合并到矩陣分解中進行推薦[6]。
3.4 實驗結果
圖2表示模型PC-Geo與上述三種推薦模型在準確率和召回率的對比結果。
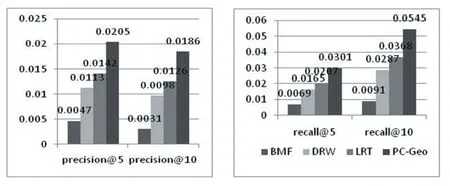
圖2 PC-Geo和其他推薦算法對比
BMF:這種方法已經被廣泛的應用在推薦系統中了,通常會通過最小化目標函數來獲得局部最優解。然而,由于用戶簽到矩陣的稀疏性,這種直接矩陣分解的方法會導致最后的推薦精度很低。
DRW:這種方法采用動態的隨機游走模型,融合了用戶的社交關系、相關類別信息以及流行度信息,但是,該方法沒有考慮地理位置因素對于用戶簽到行為的影響。因此,它最終體現出較差的推薦效果。
LRT:這種方法引入了用戶簽到行為的兩個時間特性:1非統一性,即用戶在一天內的不同時間段展現出不同的簽到偏好;2連續性,即用戶在一天內連續時間段上的簽到偏好比非連續時間段上的偏好更加相似。LRT是在矩陣分解的基礎上加入了用戶社會行為的時模式,在模型中反映出簽到偏好隨時間狀態的遷移。但是,這種方法僅僅考慮了時間因素對用戶簽到行為的影響,并沒有考慮到其他的情景因素(地理,社交)用戶簽到行為的影響,因此,它的推薦精度也較差。
PC-Geo:該模型在精度和召回率上都取得了最好效果,原因總結如下:
(1)充分利用相關用戶會對用戶的簽到行為產生影響這一事實,利用相關用戶學習目標用戶的潛在興趣,這能在一定程度上緩解冷啟動問題。
(2)使用核密度估計方法捕獲地理因素對用戶簽到行為的影響,為每個用戶獲得獨特的密度函數。
(3)一個額外的優勢是容易把時間因素融入到推薦模型中,用戶的簽到行為具有時間模式,因此融入時間因素,也可以在一定程度上提高推薦模型的質量。
圖3展示了PC模型(只合并了潛在興趣到用戶-興趣點矩陣中,并沒有合并最后的地理因素對用戶簽到行為的影響)和PC-Geo模型準確率和召回率的對比。結果表示在基于社交網絡的興趣點推薦中考慮地理因素對用戶簽到行為的影響是必要的。
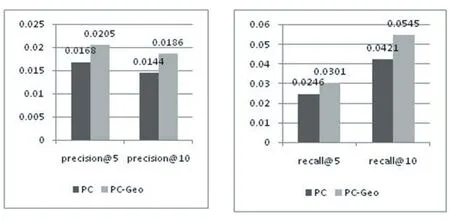
圖3 PC-Geo和PC的對比
3 結語
本文提出了一個對于興趣點的推薦框架:首先,使用情境信息(空間信息、時間信息、社交信息)來為目標用戶定義相關用戶;其次,設計一個結合用戶興趣和地理信息的算法,利用相關用戶的歷史簽到數據,使用該算法學習目標用戶的潛在興趣,緩解簽到矩陣的稀疏性。接著,把地理信息和矩陣分解的結果融合,最后完成對用戶的推薦。在未來的工作中,希望能把用戶的評論添加到框架中,以提高推薦效率。
[1]Zheng Y,Zhang L,Ma Z,et al.Recommending Friends and Locations Based on Individual Location History[J].ACM Transactions on the Web,2011,5(1):5.
[2]Hu Y,Koren Y,Volinsky C.Collaborative Filtering for Implicit Feedback Datasets[C].Eighth IEEE International Conference on Data Mining.IEEE,2009:263-272.
[3]Cheng C,Yang H,King I,et al.Fused Matrix Factorization with Geographical and Social Influence in Location-Based Social Networks[C].AAAI Conference on Artificial Intelligence,2012.
[4]Ye M,Yin P,Lee W C,et al.Exploiting Geographical Influence for Collaborative Point-of-Interest Recommendation[C].ACM,2011:325-334.
[5]Cheng C,Yang H,Lyu M R,et al.Where You Like to Go Next:Successive Point-of-Interest Recommendation[C].International Joint Conference on Artificial Intelligence.AAAI Press,2013.
[6]Gao H,Tang J,Hu X,et al.Exploring Temporal Effects for Location Recommendation on Location-based Social Networks[C].ACM Conference on Recommender Systems.ACM,2013:93-100.
[7]Gao H,Liu H.Data Analysis on Location-Based Social Networks[J].2014:165-194.
[8]Li H,Ge Y,Zhu H,et al.Point-of-Interest Recommendations:Learning Potential Check-ins from Friends[C].ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016:975-984.
[9]Yuan Q,Cong G,Ma Z,et al.Time-aware Point-of-Interest Recommendation[C].International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2013:363-372.
[10]Koren Y,Bell R,Volinsky C.Matrix Factorization Techniques for Recommender Systems[J].Computer,2009,42(8):30-37.
[11]Salakhutdinov R,Mnih A.Bayesian Probabilistic Matrix Factorization using Markov Chain Monte Carlo[C].International Conference on Machine Learning.ACM,2008:880-887.
[12]Ying J C,Kuo W N,Tseng V S,et al.Mining User Check-In Behavior with a Random Walk for Urban Point-of-Interest Recommendations[J].ACM Transactions on Intelligent Systems&Technology,2014,5(3):1-26.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:36:04
當代陜西(2021年12期)2021-08-05 07:45:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
冰雪運動(2016年4期)2016-04-16 05:54:56
