離散螢火蟲算法在高速列車運行調整中的應用
2018-08-01 07:46:26段少楠戴勝華
計算機工程與應用 2018年15期
段少楠,戴勝華
北京交通大學 電子信息工程學院,北京 100044
1 引言
列車運行調整是鐵路行車指揮工作的基礎和核心[1]。列車在運行過程中,不可避免地受到各種因素的影響使列車運行偏離計劃線,擾亂行車秩序,影響行車效率。我國高速鐵路采用“高中速混跑”運營模式,列車采取分級調整策略[2],并且高速鐵路列車運行速度快、行車密度大,對運行調整的實時性和動態性提出了更高的要求,因此,需要采用科學的優化方法對列車運行圖進行調整。
列車運行調整是一類NP完全問題,目前求解這類問題的主要方法是最優化方法和智能計算方法[3]。線性規劃、非線性規劃、混合整數規劃、分枝定界法、拉格朗日松弛法等最優化方法都已在求解過程中得到應用[4]。但采用最優化算法解決列車運行調整問題必須對復雜模型進行簡化,因此計算結果與實際有較大偏差,且計算量極為龐大。解決這一問題常用的智能計算方法有遺傳算法、粒子群算法和普通啟發式算法等。遺傳算法雖然適用性強,計算效果較好,但是編碼相對復雜,運算過程繁瑣且尋優耗時多,求解速度慢。由于列車運行調整約束眾多,搜索空間龐大,可行解范圍狹小,粒子群算法搜索緩慢易陷入死循環,難以得到最優解[3]。普通的啟發式算法雖然計算量較小,但對全局最優解的搜索能力不強,易陷入局部最優解。
螢火蟲算法是模擬自然界中螢火蟲的發光特性而發展起來的一種新型智能優化算法,具有較高的尋優精度和收斂速度,是一種可行有效的優化方法,為智能優化提供了新思路[5]。本文針對運行圖調整問題的特點,將標準螢火蟲算法進行離散化處理,通過調整列車在給定站的發車次序來對列車運行進行調整。經過計算對比,該算法可以準確、快速地得到目標函數最優解。
2 模型建立
本次研究選擇雙線自動閉塞高速鐵路單一方向線路為研究目標。為了反映列車在區間和車站內晚點情況以及在程序設計中易于處理相關約束條件,將列車運行圖的計劃線用到達和出發兩條線表示,并且以時間軸的形式給出,以分鐘為單位,到達線和出發線可以分成1 440個點[6]。如圖1所示。
2.1 變量定義
針對某一調度區段,對于列車調整模型給出如下定義:
(1)列車總列數為L。
(2)車站總數為N,則區間總數為K=N-1。
(3)Ai,k、Si,k分別為第 i(i∈{1 ,2,…,L})列車在第k(k∈{1 ,2,…,N})個車站的到達、出發時刻,則相應的定義、為原定計劃時刻。
(5)列車等級優先級為 μ(i),i∈{1 ,2,…,L} ,其值越大表明列車等級越高,優先級越高,反之則優先級越低。不同等級列車對應的列車運行調整權重為w(i),i∈{1 ,2,…,L},不同等級列車在車站的作業時間為t(i),i∈{1 ,2,…,L}。不同等級的列車在車站k與車站k+1之間的最小運行時間用表示,不同等級列車在車站k的最小作業時間用εi,k表示。
(7)定義布爾變量ψi,k表明列車通過車站的作業類型。

2.2 目標函數
對調整策略的優劣進行評價有多種標準,這是由于列車晚點情況是有差異的,運行調整策略也需要做出相應的變動[7]。本文選擇按站調整的方式,以每個車站的列車發車順序為變化量,選擇列車在調整站點的下一站加權到達晚點時間最小為目標函數。

2.3 約束條件
為保障行車安全及運輸效率,列車運行調整的范圍要受到車站最小作業時間、最小區間運行時間、列車到達間隔、列車出發間隔等約束[8],具體描述如下所示:
(1)越行條件:只有滿足以下條件,列車 j才可以越行列車i(其中i為前車,j為后車):
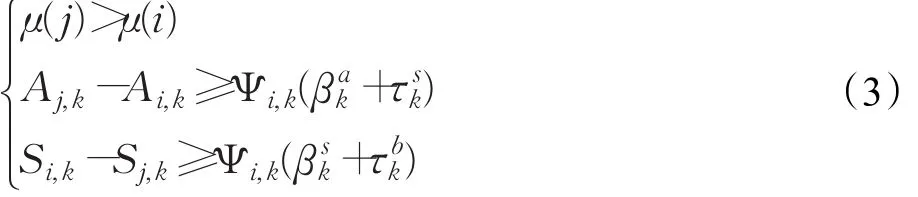
(2)列車在兩站之間的運行時間,需滿足列車在區間的最小運行時分,且考慮列車的起、停附加時間:
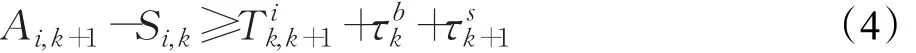
(3)若列車在車站停車,作業時間不得小于規定的在該車站的最小作業時間:
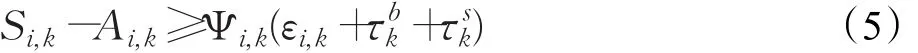
(4)所有列車發車時間不得早于固定的發車時間;

(5)在同一個車站,前后兩列車的到達、出發時間間隔要滿足最小到達、出發時間間隔的約束[3]。
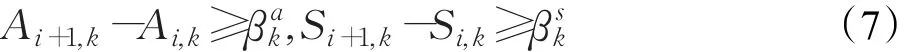
3 離散螢火蟲優化算法
3.1 標準螢火蟲算法
2008年,Yang通過對螢火蟲個體相互吸引和移動過程的研究,提出了一種新型群體智能優化算法,即螢火蟲算法(Firefly Algorithm,FA)[9]。
螢火蟲算法將搜索空間中的點模擬成自然界的螢火蟲個體,將搜索和優化的過程模擬成螢火蟲個體之間的吸引和移動過程,用求解問題的目標函數值來表示螢火蟲當前位置的優劣,將個體的優勝劣汰過程類比為搜索和優化過程中用較好可行解取代較差可行解的迭代過程。算法涉及兩個關鍵因素:螢火蟲的發光亮度和相互吸引度。螢火蟲發光亮度取決于自身所在位置的目標值,發光亮的螢火蟲會吸引發光弱的螢火蟲向它移動,最終大多數螢火蟲會聚集在最亮的螢火蟲附近。發光越亮的螢火蟲對周圍螢火蟲的吸引度越高,若發光亮度一樣,則螢火蟲做隨機運動。吸引度與距離成反比,即距離越大吸引度越小[10]。
算法描述如下:
首先建立螢火蟲i的絕對亮度Ii和目標函數值之間的關系,一般直接用目標函數值來代表螢火蟲的絕對亮度,即:
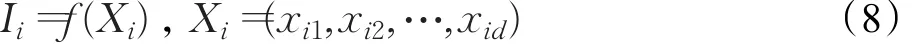
假設螢火蟲i絕對亮度大于螢火蟲 j,則螢火蟲 j被螢火蟲i吸引而向螢火蟲i移動。螢火蟲i對螢火蟲j的吸引力βi,j為:

其中,β0為最大吸引力,通常為1;γ為光吸收系數,γ∈[0 . 01,100];ri,j為螢火蟲i到螢火蟲 j的笛卡爾距離,即:
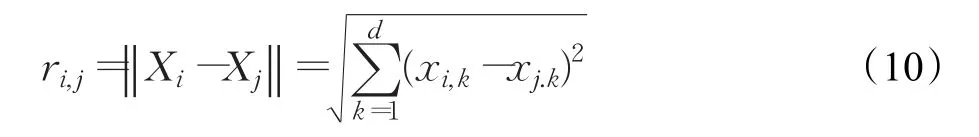
其中d為變量的維數。
由于螢火蟲 j被螢火蟲i吸引而向螢火蟲i移動,則螢火蟲 j的位置更新公式為:
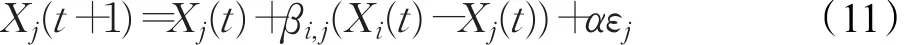
其中t為迭代次數;Xi、Xj為螢火蟲i和 j所處的空間位置;α為步長因子,是[0 , 1]上的常數;εj是均勻分布的隨機數向量,用于加大搜索區域,避免過早陷入局部最優[11]。
3.2 算法離散化
標準螢火蟲算法采用笛卡爾距離,適用于連續空間中的尋優,本文通過優化列車發車順序來得到目標函數最優解,屬于組合優化問題,因此需要對算法進行離散化處理,主要從距離計算、移動方式和擾動機制三方面進行改動。
對于每一個需要優化的站點,用總加權到站晚點時間的倒數作為螢火蟲的絕對亮度,每個螢火蟲表示本站所有列車的一種可能的發車順序,如Xi=[1 , 2,3,4,5]。在離散螢火蟲算法中,使用漢明距離來度量兩個螢火蟲序列之間的距離,即序列中相同位置元素不同的個數。例如Xi=[1 , 2,3,4,5],Xj=[1 , 2,4,3,5],其漢明距離為2。對于兩個相互吸引的螢火蟲個體,在進行移動時需要先將其相同位置元素相同的值對應保存下來,對兩者元素不相同的位置,每次生成一個[0,1]區間內的隨機數r,如果r<β,則該位置取亮度高的螢火蟲的元素,否則取亮度低的螢火蟲的元素,其中β為螢火蟲之間的吸引力。如果所選取元素和前面已選元素重復,則先將該位置留空,直到序列全部選擇完畢,再將剩余未選擇元素,依次分配給這些留空的位置[12]。
3.3 變鄰域擾動機制
為了避免螢火蟲算法陷入局部最優,需要在螢火蟲移動之后加入擾動量。本文參考螢火蟲算法在TSP問題中的應用,在搜索過程中采用變鄰域的擾動機制,系統地改變螢火蟲的鄰域,從而拓展搜索范圍[13]。
根據運行圖調整的求解特點,文中應用了兩種鄰域結構:
(1)Insert鄰域,在解序列中隨機選取不同車次的列車x和y,其中x<y,把列車x的發車次序插入列車y的發車次序之后,得到新的次序排列。例如Xi=[1,2,3,4,5],隨機得到x=2,y=4,則調整之后Xi=[1,3,4,2,5]。
(2)Swap鄰域,在解序列中隨機選擇不同車次的列車x和y,互換這兩次列車的發車次序。例如Xi=[1,2,3,4,5],隨機得到x=2,y=4,則調整之后Xi=[1,4,3,2,5]。
3.4 算法流程
應用離散螢火蟲算法求解運行圖調整問題的基本步驟如下:
步驟1按站進行查詢,對比實際到站時間和計劃到站時間,得到首次晚點車站k和首次晚點列車序號i。
步驟2針對該存在晚點情況的車站,初始化算法基本參數,包括螢火蟲數目m、光強吸收系數γ、最大迭代次數Tmax。隨機初始化每只螢火蟲的初始解序列,即保持正點列車發車順序不變,對首次晚點列車及其后所有列車的發車順序進行隨機設置。
步驟3按照約束條件(1)對每只螢火蟲對應的發車次序進行重新調整,然后按照調整后的發車順序和約束條件(3)、(4)、(5)計算所有列車在該車站的實際發車時間 Si,k,i∈{1,2,…,L}。
步驟4根據列車在車站k的實際發車時間Si,k和計劃發車時間確定晚點列車,在車站k和k+1之間的區間,晚點列車按照最小區間運行時分運行,其余列車正常運行,最后按照約束條件(2)、(5)計算得到所有列車在k+1站的實際到站時間Ai,k+1,i∈{1,2,…,L}。
步驟5 根據w(i),i∈{1,2,…,L}、Ai,k+1,i∈{1,2,…,L}計算調整后的每個發車順序對應的函數值,并按照吸引和移動原則進行移動。
步驟6對移動后的螢火蟲進行變鄰域搜索,選擇兩種鄰域中的一種進行隨機擾動,重復執行n次,選擇目標函數值最優的位置作為螢火蟲的當前位置。
步驟7對更新后的所有螢火蟲的目標函數值進行排序,并與當前最優解進行比較,如果更優則更新最優解。
步驟8如果最優解滿足結束條件,則跳出循環,輸出本站的調整結果,對下一站點進行調整,否則跳到步驟5繼續搜索。
步驟9如果調整執行到最后一個車站或者最優解為0則調整結束,否則對下一個車站繼續步驟2。
4 算例分析
4.1 數據整理
為了驗證離散螢火蟲算法的先進性,本文選取文獻[14]提供的算例,利用本文所提出的算法對文獻[14]中的算例進行重新計算,將得到的結果與文獻[14]提出的啟發式算法進行對比。
文獻[14]算例中計劃運行時刻表如表1所示。針對晚點情況設定了3個參數:首次晚點發生的區間m,該區間初始晚點的列車n以及列車晚點時間s。這里的晚點時間表示的是列車在區間運行過程中的實際運行時分比計劃運行時分多出的部分。本次算例,設置m=3,n=6,s=25。采用文獻[14]中提到的啟發式算法得到的晚點發生后的列車運行時刻表如表2所示。
該算例的已知條件如下:
有4種等級的14輛列車,對應的等級矩陣為μ(i)=[2,2,2,3,3,4,4,4,4,4,1,1,1,1]。14輛車對應權重為w(i)=[0.3,0.3,0.3,0.2,0.2,0.1,0.1,0.1,0.1,0.1,0.4,0.4,0.4,0.4]。為了便于計算,設第一個站的第一列車發車時間為0,后續時間以“min”為單位。例如,按照計劃運行圖,列車在5號站點計劃與實際到站時間分別為:=[109,115,121,156,162,204,210,216,222,228,261,267,273,279],Ai,5=[109,115,121,156,162,221,227,233,239,245,261,267,273,279]。各車站最小出發時間間隔=6 min;各車站最小到達時間間隔=6 min;4種等級的列車在5個區間的最小運行時間矩陣以及在6個站的最小作業時間矩陣分別為:

4.2 算例設計
列車運行圖調整有按站調整和按車調整兩種方式,本文以及文獻[14]均是采用按站調整的方法,即重新設置經過某個車站的所有列車的到達時刻與出發時刻,通過區間的調整冗余度來降低晚點列車所受到的影響[15]。
對于每一個車站,如果所有列車進站時間及站內作業時間已知,一旦確定各個列車的發車順序,即可知道每列車的發車時間。將發車時間和計劃發車時間進行比較之后得到晚點列車車次,然后晚點的列車通過在區間的快速運行來減少或者消除晚點,最終使運行圖恢復計劃狀態。
本次研究的目標函數是調整站點的下一站加權到達晚點時間最小。本次算例選取6個站中的某一個站,例如利用第5站的到站時間計算第5站的發車順序然后得到第5站的發車時間和第6站的到達時間。其他站的情況類似,在文章中不再贅述。

表1 計劃時刻表
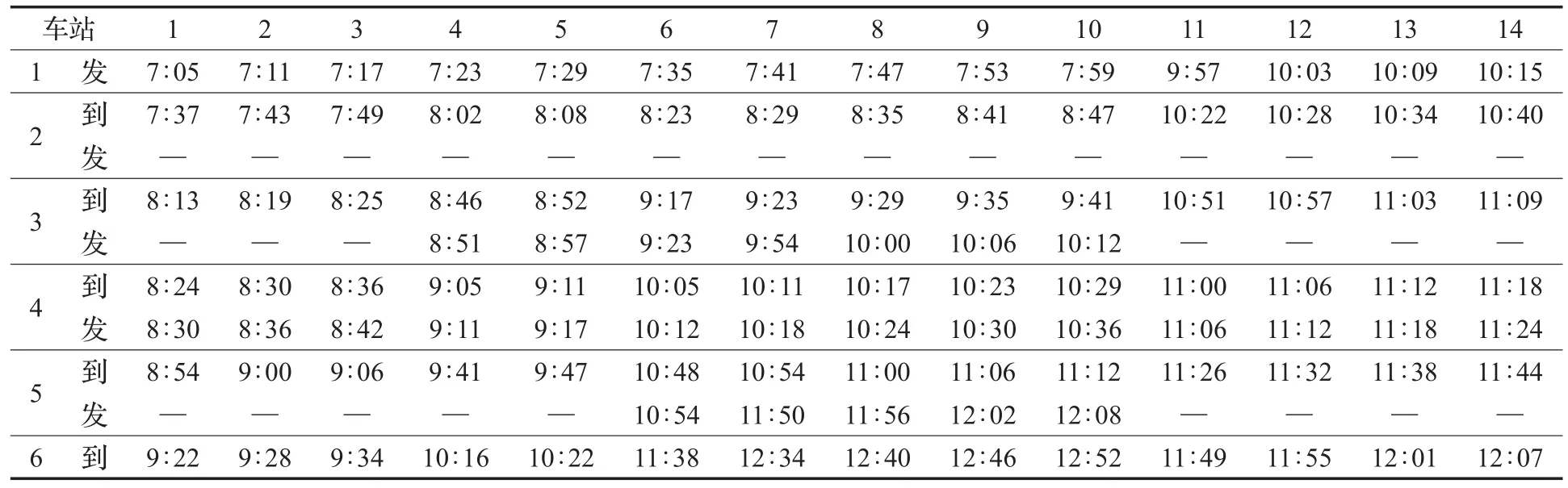
表2 啟發式算法調整結果

表3 啟發式算法和螢火蟲算法在第五站的計算結果
4.3 計算結果對比
4.3.1 啟發式算法
通過表1和表2對比可得,在第5站共有5輛列車發生晚點,需要在該站點對發車順序進行調整使得在6號站點總加權晚點時間最小。按照文獻[14]中提出的啟發式算法的計算結果如表3所示。
根據第5站計劃發車次序和實際發車次序,可以看到為了降低晚點時間,高優先級的11、12、13、14號列車對低優先級的8、9、10號列車進行了站內越行。目標函數為6號站點的加權到達晚點時間,由實際到達時間和計劃到達時間計算得到。
4.3.2 離散螢火蟲算法
由于高等級的列車可以站內越行低等級的列車,因此在5號站點對列車的發車次序進行改變可以得到不同的目標函數值。利用離散螢火蟲算法對解空間進行搜索可以得到最優的發車順序。
算法參數設置:螢火蟲數目m=30,最大迭代次數Tmax=20,最大吸引力β0=1,光強吸收系數γ=1,變鄰域搜索中兩種鄰域選用概率相同,均為0.5,變鄰域搜索執行次數n=4,得到計算結果如表3所示。
4.3.3 結果分析
通過表3的對比,可以看到使用離散螢火蟲算法計算之后,高等級的11、12、13、14號列車只對9、10號列車進行了站內越行,而沒有對晚點20 min的8號低等級列車進行越行。該算法計算得到的目標函數值優于普通啟發式算法,準確找到的問題的最優解。為了驗證算法的穩定性,作者還對該算例使用離散螢火蟲算法進行多次計算,結果表明計算結果均可以在較少的迭代次數內達到收斂,得到該問題的最優解。
5 結束語
本文針對列車運行調整這類特殊的NP完全問題,建立對應的數學模型,通過對標準螢火蟲算法進行改進,提出一種離散的螢火蟲算法(DFA)對列車運行調整模型進行求解。采用Matlab編程,通過對比普通啟發式算法和離散螢火蟲算法的目標函數值,發現離散螢火蟲算法收斂速度快、目標函數的最優解精度高,從而證明了該算法對解決列車運行調整問題具有一定優勢。
