面向選擇類題型求解的相似問題發現研究
2018-08-01 07:46:06鄭雨晴鄭德權趙姍姍
計算機工程與應用 2018年15期
于 鳳,鄭雨晴,鄭德權,,趙姍姍
1.哈爾濱商業大學 計算機與信息工程學院,哈爾濱 150028
2.哈爾濱工業大學 計算機科學與技術學院,哈爾濱 150001
1 引言
在人工智能火熱的今天,智能解題逐漸成為一大研究熱點,人們熱衷于讓人工智能參加各種“測試”,并與人類選手進行比試,從而衡量目前人工智能系統的“智力”水平。
目前,在世界范圍內已有多家研究機構正在從事這一方面的研究。例如,日本國立情報學研究所開發的AI機器人“東Robo君”,他們讓機器人挑戰大學試題,目標是2021年能夠考上東京大學[1]。艾倫人工智能研究所(Allen Institute for Artificial Intelligence)也舉辦了一項比賽,來自全世界的幾千個團隊紛紛提交了自己的軟件系統來挑戰8年級的科學題目,最終,該比賽的第一名達到59%的正確率[2]。在我國,國家科技部2015年也啟動了“高考機器人”項目(863計劃中的類人智能項目),讓人工智能系統和全國的文科考生一樣,挑戰2017年高考語文、數學、文綜三項科目,研究相關類人答題系統,超過30多家高校和科研機構(清華大學、中科院自動化所、哈工大等)聯合參與了該項目。此外,在智能解題方面,文獻[3]提出通過動詞分類來解決較簡單的算術問題;文獻[4]通過句子邊界來構造和求解一個線性方程組;南京大學的研究人員針對歷史選擇問題,在維基百科中檢索與問題相關的頁面,通過對頁面進行排序、過濾、評價,求得最終結果[5]。
2011年,IBM Watson超級計算機在電視智力競賽節目《Jeopardy!》中戰勝人類而一舉成名[6],AlphaGo戰勝世界圍棋頂尖高手,這些都代表著科學技術向認知系統的進步。而類似的知識問答系統,如中國科學院自動化研究所開發的百科知識問答系統、百度的小度機器人、微軟小冰等,在現代生活中應用也日趨廣泛。
通過深入了解上述各相關系統,發現它們的關鍵技術一般都包括知識處理、信息檢索、語義理解等部分。類比上述這些系統,可以考慮將此類技術應用到基礎教育領域。利用當前大數據特性以及自然語言處理技術,研究多源知識的識別、抽取、發現等問題,構建面向基礎教育領域的關聯類與推理類問題的求解系統。本文主要針對選擇類題型求解的相同或相似性問題發現展開研究。
本文是根據已有的問題和知識庫求解新問題,由于自然語言語義表達的多樣性,當從已有問題中查找相似問題時,相似不僅代表問題內容的相似,還有可能是內容不同但語義卻相似,這給問題檢索帶來了一定的困難,現階段主要圍繞語義相似度進行研究。
本文在求解題目時,同樣核心點落在從已有題庫中求解相似問題,具體過程是:首先對新問題進行關鍵詞抽取及擴展,完成多源知識搜索;其次根據擴展后的關鍵詞完成關聯問題的檢索;再根據關聯問題計算相似度;最后獲得各個候選項的打分,完成答案選擇。
2 問題理解與分析
2.1 選擇題及知識點關系分析
本文以地理問題為研究對象,通過搜集各類地理教材、地理題目及歷年高考地理大綱等,發現考查基本內容、知識點變化不大,而每年考題的多樣性重在對知識點的靈活應用,且題目都有一定的規律。以人教版高中地理課本為例,共有3本必修,7本選修,包含250個左右的知識點,包含自然地理、人文地理、中國地理、世界地理等部分。再分析從各個網站下載的題目發現,在有限的知識點下,每類知識點對應的題目卻非常多。表1是根據某網站的題庫,統計的若干具體的知識點與其現有的題目數量分析。

表1 知識點與現有的部分題目數量關系
因此本文通過分析題目相關的知識點,然后從題庫中查找相同或相似知識點的若干題目,再通過分析這些相似知識點的題目,來求解新問題。
2.2 問題發現分析
問題發現可以分為兩步完成:問題分析和相似問題發現。問題分析又稱問題理解,主要完成對新問題預處理,生成適當的檢索項,為下一步相似問題發現提供輸入。相似問題發現則主要根據問題分析結果應用不同的相似度分析方法從已有題庫中查找部分相似問題。
本文在問題分析時對問題的處理包括關鍵詞提取和擴展兩部分。關鍵詞提取包括有監督的、無監督兩種方法。有監督方法中,文獻[7]提出了使用向量空間模型(Vector Space Model,VSM)提取關鍵詞;文獻[8]提出了使用樸素貝葉斯模型的關鍵詞提取方法。無監督方法中,最簡單易用的關鍵詞抽取算法是TF-IDF(Term Frequency-Inverse Document Frequency),文獻[9]和文獻[10]提出使用類似于PageRank的算法TextRank抽取關鍵詞,文獻[11]提出使用LDA(Latent Dirichlet Allocation)主題模型的方法來抽取關鍵詞。
考慮到地理問題一般都是一句話或者若干單句組成的復合語句,本文使用TextRank和詞性標注兩種方法來標注關鍵詞。關鍵詞提取之后,使用Word2Vec對關鍵詞進行聚類,然后根據聚類后的結果擴展關鍵詞。
目前問題相似度計算方法大致分為三類:基于詞匯、基于句法特征以及基于語義特征的問題相似度計算方法。基于詞匯的相似度計算方法主要是基于詞袋模型(bag of word),該模型忽略了詞匯之間的順序、句法、語法及語義信息,將一個文本看作若干詞匯組成的集合,認為詞的分布或者服從0-1分布或者服從多項式分布。傳統基于詞袋的檢索模型有VSM[12]、BM25模型(Best Match25)[13]。這兩個模型都是基于TF-IDF來計算,不同點在于BM25模型中加入了對句子長度的分析。此外,根據編輯距離和最長公共子序列來計算相似度也是一種簡單可行的方法。根據句法特征計算問句相似度,主要是應用現有的句法分析工具獲得問句句法結構,然后從句法結構中抽取問題特征,進行相似度計算。文獻[14]中使用依存句法分析樹,根據樹中節點的依存關系及節點路徑信息來分析句子的相似度;文獻[15]使用短語句法樹核的方法,通過分析句法樹中子樹的相似度來計算兩個問題的相似度。漢語語言中經常有語義相同特征詞卻不同,或者特征詞相同而語義卻不同的句子,因此又引入了基于語義的相似度分析,現有的語義相似度研究方法中一般借助《知網》、主題模型等來分析[16-17]。

表2 兩種方法的關鍵詞抽取結果
由于本文主要是為了求解知識點類似的地理題目,而且地理題目結構內容靈活,句法分析技術并不是十分適用,因此本文主要從詞法和語義兩方面研究:詞法上,主要對新問題的關鍵詞擴展,然后根據Lucene中TFIDF機制獲得初始候選問題;語義上,使用word2vec分析詞語的語義相似度,進而研究兩個句子的相似度。在分析相似度時根據不同的關鍵詞抽取方法和相似度計算方法間的組合,來獲得最佳結果。
2.3 word2vec分析使用
近年來隨著深度學習(Deep Learning,DL)在計算機視覺和語音識別領域的廣泛應用,在自然語言處理領域的應用也逐漸展開。Tomas Mikolov等人在2013年建立了word2vector模型,將單詞轉換成詞向量的形式[18]。不同于傳統的使用One-hot Representation來表示詞向量,word2vec是將詞用Distributed Representation表示成一種低維實數向量。Google開源了word2vec學習工具,該工具包含了對兩種語言模型的訓練,即連續詞袋模型(Continuous Bag-Of-Words Model,CBOW)和 Skipgram(Continuous Skip-Gram Model)。詞向量是在訓練語言模型的同時得到的副產品,并沒有直接的模型來訓練獲得。針對這兩種模型,又有兩種不同的學習方法,即HS(Hierarchical Softmax)和NS(Negative Sampling)。
本文在訓練詞向量時,使用的是維基百科中英文語料,語言模型使用Skip-gram,訓練使用NS負采樣方法。在此基礎上采用譜聚類算法[19-20]對關鍵詞聚類,以便在關鍵詞擴展的時候使用。計算相似度采用基于word2vec生成的詞向量來設計不同的相似度計算方法。
3 相似性問題發現
3.1 關鍵詞提取
本文使用兩種方法抽取關鍵詞,一種方法是參照TextRank算法,另一種方法是使用詞性標注(Part Of Speech,POS)的結果。
TextRank算法是類比PageRank實現的,將每個單詞作為PageRank的一個節點,設定窗口大小后,認為窗口中任兩個單詞對應的節點之間存在一個無向無權的邊,然后根據構成的圖計算出每個單詞節點的重要性,按照重要性的大小得到關鍵詞。另一種方法是使用FudanNLP分詞器對問題進行詞性標注,從標注結果中提取出具有名詞、地名、專名、形容詞等詞性的詞,然后給每個詞賦予不同的權值,得到關鍵詞集合。表2給出了上述兩種方法對于2個例句的關鍵詞抽取結果。
在進行關鍵詞擴展時,先使用word2vec生成詞向量,然后再對詞聚類。為了減小噪聲,避免關鍵詞中噪聲過大,對詞的聚類并沒有使用維基百科語料,而是使用題庫中已有題目作為語料訓練詞向量,使用文獻[21]中提出的基于全局K-means的譜聚類算法完成對詞聚類。表3給出了4組詞聚類中詞頻較高的樣例。

表3 詞聚類結果
3.2 相似度計算
3.2.1 基于改進的BM25方法
BM25算法是二元獨立模型的擴展,在信息檢索中通常用來作為搜索相關性評分。其主要思想是,對用戶查詢進行解析,生成語素qi,然后再計算每個語素qi與檢索到的文檔D的相關性得分,最后將每個qi與文檔D的相關性進行加權求和,進而得到Query和文檔D的相關性得分,其計算公式如公式(1)所示:

其中,Wi=IDF(qi)是語素qi的逆文檔頻率,代表其權重,而語素qi與文檔的相關性表示如公式(2)所示:
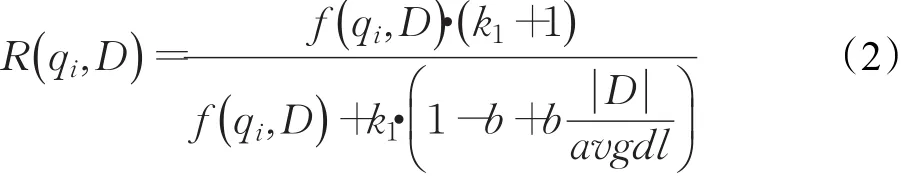
其中,f( )
qi,D 表示語素qi在文檔D中的詞頻,k1和b為調節因子, ||D表示文檔長度,avgdl表示所有文檔的平均長度。BM25算法的優點在于可以靈活改變各部分內容,對算法進行改進。
為了有效模擬人類求解問題的過程,往往需要更多考慮問題知識點,因此可以嘗試將一個問題分解為多個關鍵詞,代表不同知識點,然后再判斷每個關鍵詞與已有問題的相似性,再對各個關鍵詞與問題的相似性進行加權求和。因此可以對上述算法的兩部分進行更改,得到求解兩個地理問題相似度的方法,如公式(3)所示:
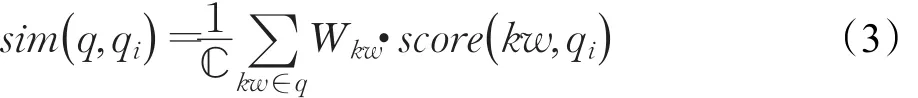
其中,kw代表一個關鍵詞,?為歸一化因子,wkw代表關鍵詞權重,score(k w ,qi)代表關鍵字kw與已有問題qi的得分,計算方法如公式(4)所示:
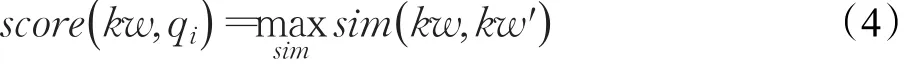
其中,kw'為qi的關鍵詞。
之所以采用公式(3)描述的計算方法,主要是考慮到地理題往往是一個短文本,問題中每個關鍵詞的頻率一般為1,而傳統的BM25算法根據詞頻計算,所以在此過程中并不適用。而兩個地理題的相似更多的是偏重于某個知識點的相似,因此關鍵詞kw與問題qi的相似度求的是問題qi中與kw最相似詞的相似度。表4中給出了2個例句及其相似度計算的結果。

表4 相似度計算的2個例句
根據改進后的BM25算法,分別使用兩種不同的關鍵詞抽取方法得到的相似度均為1.0,這證明了該方法的可行性。該方法中主要計算每個單詞與候選問題的相似度,因此后文中也將其稱為基于詞的相似度計算方法(byWord)。
3.2.2 基于詞項向量加權的方法
word2vec值得注意的另一個特性是可以對訓練得出的詞向量進行加減組合運算,進而得到與這些詞語相關的詞語信息。在3.2.1小節中是將新問題的各個關鍵詞分別與已有問題計算相似度,在本小節中考慮在基于句子級別上分析兩個句子的相似度。首先求得問題的關鍵詞及其權重,然后對各個關鍵詞進行加權求和得到問題向量,最后再用余弦相似度來計算兩個問題的相似度,具體的計算公式如下:

此處求解問題向量時并沒有進行歸一化計算,因為即使有歸一化因子,在后邊計算余弦相似度過程中也會被約掉。
使用該算法對3.2.1小節中的2個例句求相似度時,使用TextRank抽取關鍵詞得到的相似度為0.7,使用詞性標注結果抽取關鍵詞相似度為0.9。雖然此處相似度值與3.2.1小節結果有差距,但是實驗結果證明,使用該方法效果也較好。該方法最終是將句子轉為句子向量來求解,因此后文中也將其稱為基于句子的相似度計算方法(bySent)。
3.2.3 基于改進編輯距離的方法
編輯距離是指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數。編輯操作包括對一個字符的增加、刪除和修改。傳統的編輯距離計算時是對單個字符執行編輯操作,且認為每一次操作的代價為1。本文中,將單個詞,每一次的操作代價r(w ,w')與兩個詞語的相似度sim(w ,w')成反比,記為1-sim(w ,w')。做了上述改進之后,根據動態規劃的思想,算法迭代式如下所示:
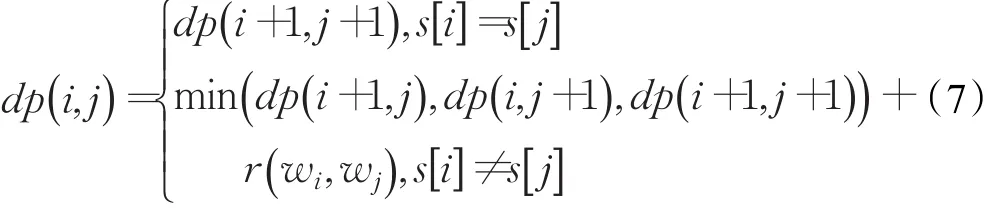
根據此算法求出兩個問題的編輯距離dp(q ,qi),再對編輯距離規范化,使其范圍在0~1之間,且使編輯距離與兩個問題的相似度成反比,具體公式如下:
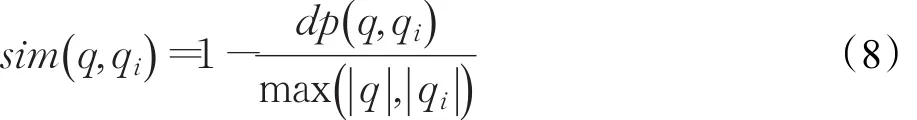
其中, ||q和 ||qi為兩個問題的長度。
實驗發現使用該算法時,相似度計算值浮動較大。給定第5個例句如下:
例句5:“對西歐海洋性氣候的形成有巨大作用的洋流是北大西洋暖流”
對3.2.1小節中的例句3和例句5分別使用兩種關鍵詞抽取方法得到的相似度在0.8左右;而對3.2.1小節中的例句3和例句4計算相似度時值卻在0.38左右,這表明該算法對句子中語義相似詞的位置比較敏感。但是實驗結果證明,該方法在求解關聯推理的地理題時也有一定效果,分析可能是由于地理關聯推理類題目往往是局限在地理知識點內的。后文中也將該方法稱為基于編輯距離的相似度計算方法(byEdit)。
4 實驗結果與分析
4.1 數據來源
本文以地理選擇題的求解為處理對象,所用題庫分為兩部分:一部分是從互聯網上下載的題目,總共大約有10萬多題,其中選擇題共有6萬多,去除選擇題中的圖表分析題和組合選擇題,共剩余26 000左右,將這部分作為檢索庫;另一部分是人工錄入的歷年高考題,大約3 700多題,去除其中的非選擇題、圖表題、組合選擇題和計算題,剩余340題左右,將這部分題作為測試集使用。對檢索庫中的題集僅保留問題和答案,并采用Lucene對其創建索引。
4.2 word2vec模型訓練語料
在學習詞向量時,word2vec的訓練語料使用維基百科數據,共800 MB左右,而對詞聚類時,因為本文主要是為了擴展地理方面的詞匯,為了避免關鍵詞類中噪聲過大,對詞的聚類并沒有使用維基百科語料,而是使用題庫中已有題目作為語料,生成關鍵詞聚類,結果如表3所示。此外,word2vec的訓練語料需要提前分詞,本文使用FudanNLP分詞器,并加入從維基百科中抽取的地理專業詞匯,完成對語料的分詞。
4.3 實驗設計
本文以地理選擇題作為實驗數據,對問題的求解主要是根據相似度對問題的各個候選項打分,共分為4個步驟實現,流程如圖1所示。
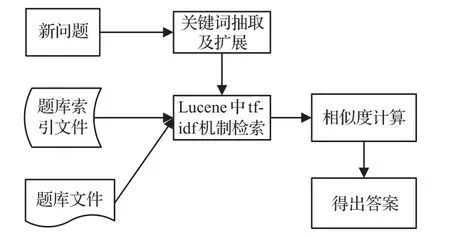
圖1 問題求解的流程
步驟1分析問題,形成檢索項。首先將問題與各個選項組合成一句話(以表5中例題為例,首先將其合成一句話“貯煤地層的巖石類型,一般是沉積巖”);其次對每句話使用FudanNLP分詞器進行詞性標注;然后根據兩種方法抽取關鍵詞;最后利用已有的詞聚類結果擴展關鍵詞。
步驟2采用Lucene系統,根據擴展后的關鍵詞集合從題庫檢索候選問題得到候選集合。
步驟3融入word2vec生成的詞向量,計算相似度。采用不同的相似度計算方法,對檢索出的候選問題與檢索前的句子求相似度,據此得出問題和各個選項的得分。
步驟4根據相似度的計算結果,以各個選項中得分最大的選項作為最終答案。

表5 地理選擇題示例
4.4 結果及分析
本文使用最終求解問題的準確率作為對各個方法的評價。在關鍵詞抽取時使用了TextRank和詞性標注兩種方法。在計算相似度時分別使用了改進的BM25方法、詞項向量方法、改進的編輯距離等三種方法。將兩種關鍵詞抽取和三種相似度計算方法進行組合,共產生六種不同的求解方法。
在測試集上,為了驗證各個相似度計算方法的準確性,在檢索集上進行了10次封閉測試,每次從檢索集中隨機選擇200道題作為測試集,計算各個求解方法的準確率,求10詞的平均準確率(Average Precision,AP)。然后再使用手工錄入的高考題作為測試集,計算求解各個方法準確率。因為從Web中下載的題目與高考題目會有重復,所以最后又對檢索庫中的問題進行10次交叉測試。檢索庫中大約有26 000道題,每次隨機選取260道作為測試集,剩余的作為檢索庫,求出平均準確率。具體的實驗結果如表6所示。

表6 幾種方法的實驗結果對比
圖2是對表6的直觀表示。
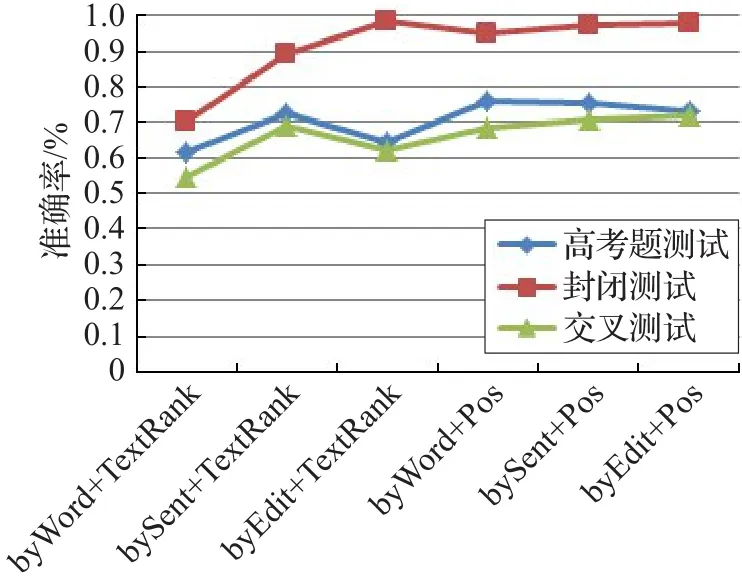
圖2 幾種方法的實驗結果對比圖
從圖2中可以發現,TextRank抽取關鍵字整體效果不是特別好,分析主要是因為地理題目一般都比較簡短,而TextRank對長文本更加有效。其中基于改進的BM25方法,在采用TextRank抽取關鍵詞方法上的效果最不好,主要因為基于改進的BM25方法是基于詞的計算,所以效果不理想。觀察基于改進的編輯距離方法在兩種關鍵詞抽取方法上的效果相差不大,分析是因為它是根據詞序計算編輯距離,而且句子短時效果更好,因此詞數目的減少對其影響不是很大。基于詞項向量方法,在使用基于詞性的關鍵詞抽取方法上與采用改進的編輯距離的結果不分上下。總體看,在地理選擇題目求解時,采用詞性標注方法抽取關鍵詞,要比基于TextRank的方法好一些;而相似度計算上采用改進編輯距離的方法較好一些,但是使用不同的關鍵詞抽取方法,采用詞項向量的方法也能夠取得較好的結果。
5 結語及展望
本文主要通過對問題進行關鍵詞抽取與擴展,然后融入word2vec生成的詞向量的語義信息,再使用基于改進的BM25方法、基于詞項向量方法和基于改進的編輯距離三種計算相似度方法,完成了基于題庫的選擇類問題求解。實驗結果表明,采用檢索題庫中相似問題完成對地理知識關聯、推理類問題的求解也是可行的。
由于本文中的方法主要集中在相似度的計算上,考慮語義時僅僅使用了word2vec,下一步可以加入更多的語義分析,并加入事件的抽取,進而來比較兩個知識點類似的高考題表述的事件是否一致,同時也可以考慮引入深度學習的方法。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
