統一著色架構3D引擎關鍵技術研究
2018-06-20 07:46:18韓立敏
計算機技術與發展 2018年6期
關鍵詞:引擎
鄧 藝,田 澤,韓立敏
(中航工業西安航空計算技術研究所,陜西 西安 710065)
1 概 述
統一著色架構是現代圖形處理器(graphics processing unit)的主要實現方式,是實現計算機圖形學領域眾多算法和策略的平臺,具備并行處理及快速構建2D、3D圖形,場景和渲染的能力[1]。
統一著色架構的3D引擎作為GPU的核心部件,是完成3D圖形、圖像加速計算的基礎,其架構設計如圖1所示。它通過統一架構的圖形流水線,實現圖形繪制和渲染功能,將自圖形流水線中輸入的一系列離散的頂點任務渲染為可在屏幕顯示的連續像素塊,輸出到顯示存儲單元中。
統一著色架構3D引擎基于單一著色器分時處理頂點任務或像素任務的特性,通過任務調度策略對著色器執行任務的分配和著色器資源的統一管理,實現對著色器資源的高效利用,從而提高系統處理性能。同時由于執行單元和配套資源的共享化,以及針對不同的渲染任務設計統一的執行單元、相應接口以及操作方式,在一定程度上簡化了軟、硬件開發流程。統一著色架構使GPU更加靈活,可編程性大大提升[2-3]。
統一著色架構3D引擎的并行處理通過三級層次結構組織實現[4]。在最底層,由著色器核構成流處理器(stream processor,SP),以單指令多數據(single instruction multiple data,SIMD)或單指令多線程(single instruction multiple threads,SIMT)方式執行操作。在中間層,SIMD(或SIMT)執行架構的多個SP被組織成流多處理器(stream multiprocessor,SM),其局部存儲可被組內SP快速訪問。在頂層,3D引擎由多個SM單元組成,并連接到全局圖形存儲器。
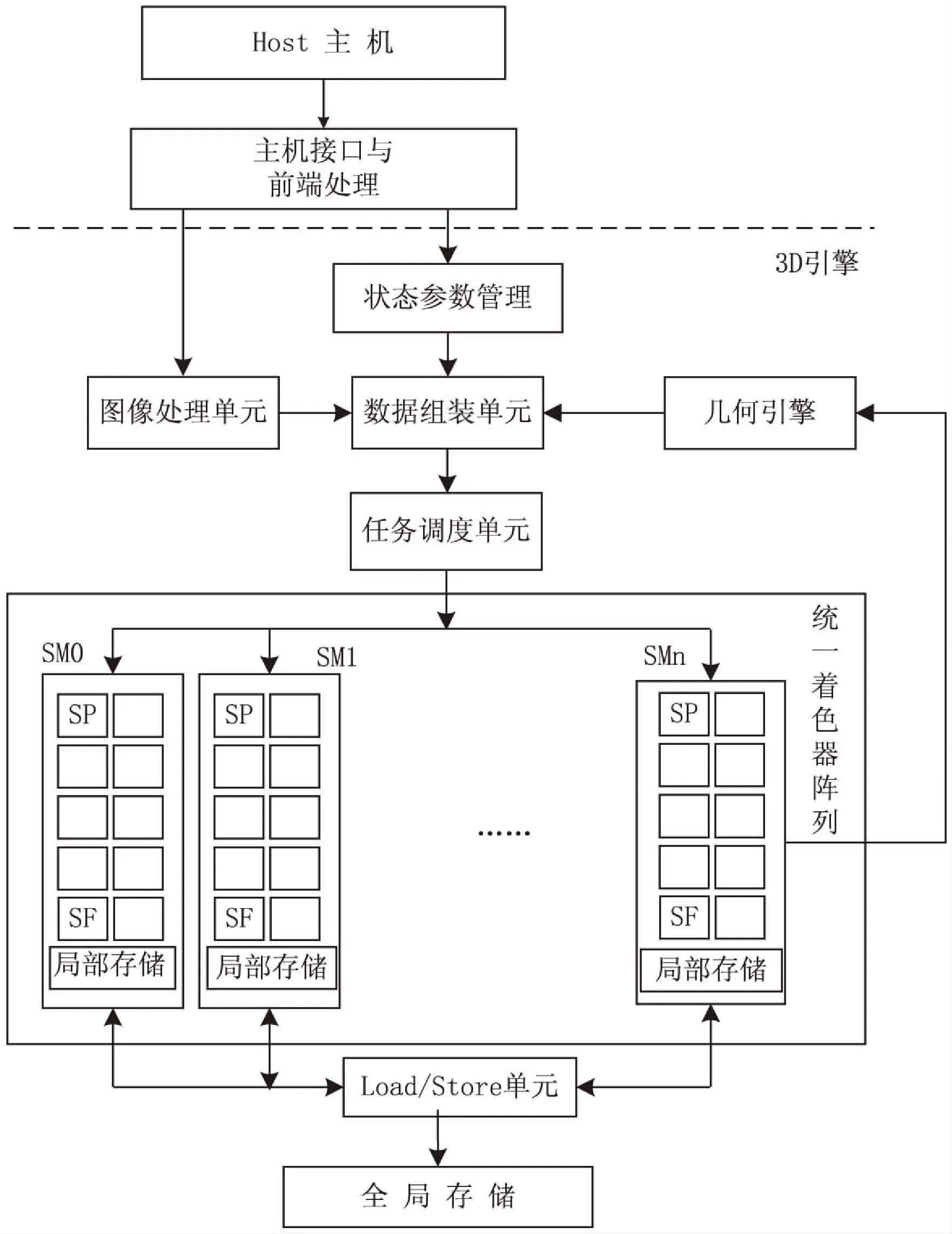
圖1 統一著色架構3D引擎架構框圖
統一著色架構的3D引擎在帶來較高圖形處理性能的同時,也對其設計提出了挑戰。首先,作為統一著色架構3D引擎最基本的計算單元,統一著色器主要完成頂點、像素的統一著色功能,是影響3D引擎計算性能的關鍵因素。眾多統一著色器的組織方式,通過多級調度策略采用著色器資源兩級分組管理、動態分配管理和統一調度實現,避免了資源分配不均,提高了性能/能耗比。此外,3D引擎多層次的存儲結構與任務調度策略中的調度資源存在映射關系,因此存儲系統的數據傳輸能力與系統整體性能密切相關。基于以上分析,多層次存儲結構設計、多級調度策略和著色器體系結構設計作為影響單個著色器處理性能發揮及整體3D引擎數據吞吐率的重要因素,成為統一著色架構GPU研究的重點。
2 統一著色架構的存儲層次
GPU的多核特性使其對存儲通路的存儲帶寬有更高的要求,因此存儲系統的數據傳輸能力與系統整體性能密切相關。統一著色架構3D引擎在提升系統處理能力的同時,也導致了更嚴重的“存儲墻”問題,對存儲系統提出了更高的要求[5]。
目前,在GPU硬件資源有限的條件下,提高存儲帶寬利用率,充分使用共享和復用減少對外部存儲器的訪問次數,成為“存儲墻”問題通用的解決方案。統一著色架構3D引擎為減少各請求源對外部存儲器的訪問頻率,減少DDR3存儲通路的帶寬壓力,采用層次化的存儲結構,存儲架構如圖2所示。
其中L0層是各請求源內部的寄存器級緩存,具有速度快、容量小的特點,訪問最頻繁;L1層主要包括單個SM級的本地存儲和L1Cache;L2層主要包括所有SM能夠共享的著色程序存儲器、紋理Cache的二級緩存;L3層是兩條數據位寬的獨立通路,組成DDR存儲訪問與控制,用以訪問片外存儲,其訪問速度最慢、容量最大[6]。
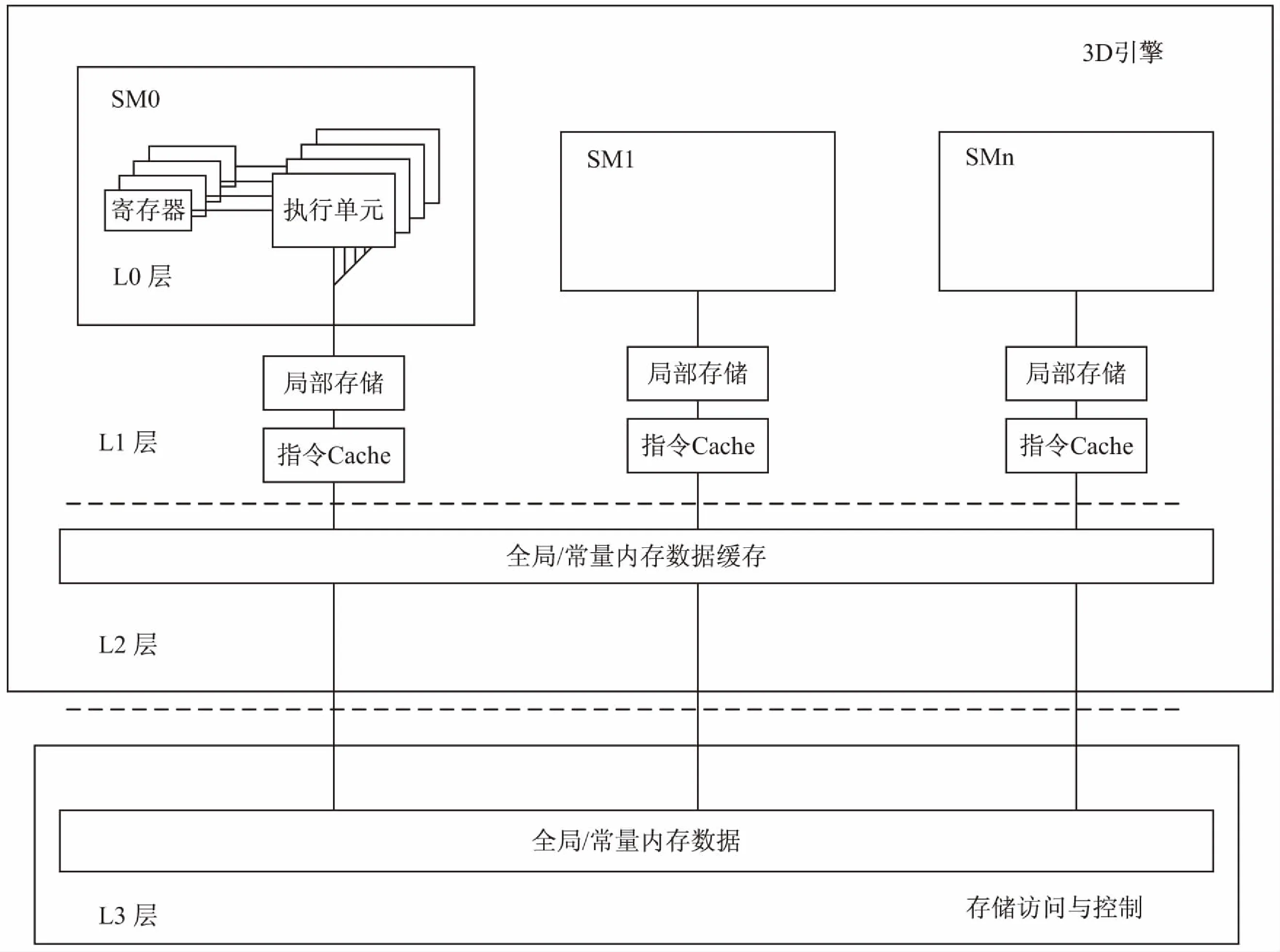
圖2 統一著色架構的多層次存儲架構
2.1 統一著色器的設計
統一著色器的設計主要包括指令集定義、數據通路設計、著色器架構、具體運算單元設計以及多個著色器的執行架構等方面。
統一著色架構的指令集定義遵循通用和高效的原則。在通用性方面,應基于OpenGL 2.0等相關通用標準,以及上文對統一著色器實現具體頂點、像素運算的內容分析,定義基本的常用運算指令、基于圖形特性的特殊函數指令以及提升著色器效率的其他指令;在高效性方面,通過指令集的優化設計提升著色器的流處理特性來發揮其強大的運算優勢[7]。
統一著色架構將統一著色器和特殊功能單元(special function unit,SFU)的數據通路相結合,其設計包括加法單元、乘法單元、乘加單元、移位單元、累加單元、浮點加法單元、浮點乘法單元等[8]。
統一著色器核主要包括取指令單元、譯碼單元、Register file、本地數據存儲器、各種運算單元及輸出寄存器,其體系結構設計如圖3所示。
為提升3D引擎的并行性及數據吞吐量,單個SM處理器內部的多個著色器的執行架構采用單指令多數據(single instruction multiple data,SIMD)或單指令多線程(single instruction multiple threads,SIMT)架構組織實現,從而最大化地實現運算單元的復用。與傳統的標量執行模式相比,SIMD和SIMT架構都能夠實現數據的并行執行操作,標量架構的執行域以單一數據為基本單位,SIMD架構的執行域以一元向量為基本單位,SIMT架構的執行域以矩陣為基本單位。
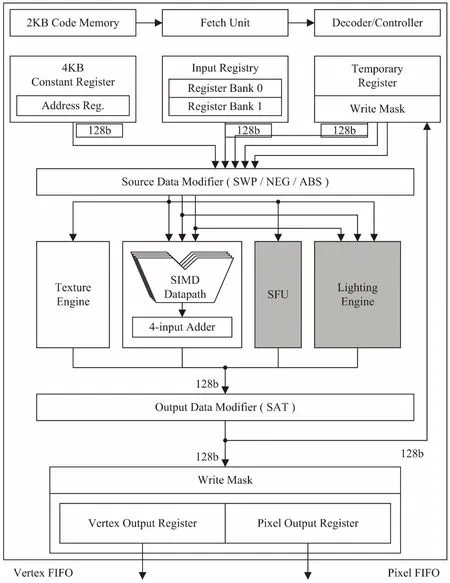
圖3 統一著色器設計架構
SIMD結構有利于對向量和數組進行數據的并行計算,但同時也制約了它進行有效的多線程計算。GPU中的“硬件多線程”主要采用少數指令對大量數據進行操作的方式實現。在商用設計領域,NVIDIA將芯片架構逐步轉向了SIMT模式。有別于AMD的SIMD架構,SIMT的優勢在于數據無需湊成合適的矢量長度,同時SIMT允許每個線程有不同的分支。由于條件跳轉會根據輸入數據不同在不同的線程中有不同表現,純粹使用SIMD無法實現并行執行有條件跳轉的函數,而SIMT架構則能夠實現。然而,SIMT架構的SM硬件設計結構較之SIMD更復雜,控制邏輯設計難度更高。AMD的SIMD架構可以用少量的晶體管構建龐大數量的流處理器,從而擁有強大的理論浮點運算能力;而NVIDIA的SIMT架構的單個流處理器所需的晶體管更多,理論浮點運算能力也更強。相較而言,AMD以數量彌補效率的不足,而NVIDIA以效率彌補數量的劣勢[9]。
2.2 統一著色架構調度策略
基于對3D引擎圖形流水線的研究,統一著色架構之前的性能瓶頸主要在于像素著色階段,即使分離可編程架構中將1∶3作為頂點與像素著色引擎的黃金比例,依然無法滿足復雜多變場景的渲染需求,因此資源利用率不足成為限制GPU性能提升的關鍵[10]。作為支持多任務的計算平臺,統一著色架構3D引擎中每個計算單元的任務處理效率可能不同,為充分利用系統資源,需要3D引擎具備監控以及動態調度計算核心的能力。同時,統一著色架構3D引擎的核心處理性能主要由其任務調度能力和各個流處理器核的執行能力表征,因而兼顧靈活、高效以及可靠的任務調度與資源分配方案是統一著色架構3D引擎的研究重點和關鍵技術。
在多任務環境下,圖形處理系統通過多任務調度框架的多級調度設計,保證整個系統高效的調度效率和良好的圖形處理性能,調度框架如圖4所示。調度的對象是經過組裝的一組固定格式的頂點或像素warp(又稱wavefront)。
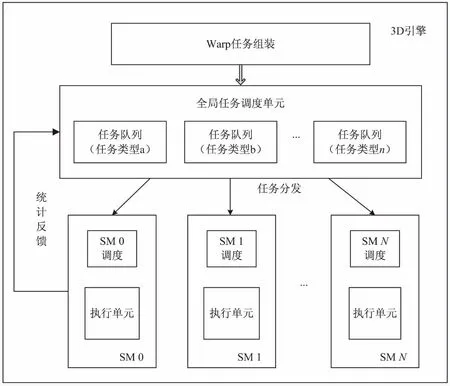
圖4 GPU的多任務調度框架
當一部分任務分發至3D引擎之前,主機接口與前端處理模塊首先接收任務輸入,并通過分析多任務間的資源競爭問題[11],完成初步的多任務隊列排序及任務的分發功能。在統一著色架構3D引擎內部,warp任務組裝單元接收來自主機接口與前端模塊的頂點任務輸入,以及來自3D引擎內部其他模塊的像素任務;全局任務調度單元接收組裝完成的warp任務輸入,對待分發任務進行統一分配、對所有執行單元任務執行狀態進行統一調度管理,并采用各流多處理器(SM)內部的調度器,完成3D引擎內部的兩級調度,最終實現對SIMD(或SIMT)架構的執行單元以及統一著色器的調度管理。同時全局任務調度層通過SM調度單元內部的統計與反饋,實現統一任務調度單元的實時、動態調度。
在多任務調度系統中,采用的調度策略主要分為以下幾類[12-14]:
第一類是基于先到先服務(first come first served,FCFS)的簡單調度策略,該調度策略便于實現,硬件資源占用較小,但無法適應統一著色架構對靈活的調度性能需求。
第二類采用完全公平調度策略(completely fair scheduling,CFS),使每個待調度任務公平地共享計算資源,同時以任務的優先級和任務運行時間作為調度的依據,在任務的優先級相同時,優先調度之前占用3D引擎執行時間較少的任務,既保證了調度的公平性又增加了靈活性,但未區分統一著色架構面向圖形類應用和非圖形類應用時不同的調度需求。
第三類采用基于分類和多優先級隊列(class priority multiple queue,CPMQ)的多任務調度系統,面向圖形應用、通用計算、實時著色等多種任務類型的調度需求,采用加權公平排隊算法(weighted fair queuing,WFQ)對待分發任務進行排序,有效降低了圖形任務的響應時間,提升了應用系統的圖形用戶體驗。
依據上文對GPU調度框架的分析,3D引擎內部的調度策略可以分為兩級,包括全局的任務調度和各SM內部的調度。全局的任務調度主要完成的功能包括對所有待處理任務的統計與排序,對待處理任務向各SM內部統一著色器的調度分發,以及對所有SM內統一著色器的執行狀態和執行類型進行管理;各SM內部的調度策略為隱藏著色器執行操作中對各級存儲的訪問延遲而設計,通過單指令多周期執行和多個warp的調度切換來實現。
3 結束語
基于統一著色架構的3D引擎是當前圖形處理技術的研究熱點,它統一了上一代分離可編程架構中分離的頂點著色器和像素著色器,打破了因資源分配不均導致的性能瓶頸,同時對統一著色器、多層次任務調度策略和多層次存儲架構等相關設計提出了更高的要求。
目前對這幾項關鍵技術的研究已取得了一定的進展,向自主研制統一著色架構GPU的方向邁進了一大步,但在統一著色器的指令集設計、面向圖形領域與通用計算領域的多任務并行調度,及統一著色架構GPU各類關鍵技術的性能評價體系等方面,仍需進行更深入的理論研究和優化設計。
參考文獻:
[1] 田 澤,張 駿,許宏杰,等.圖形處理器低功耗設計技術研究[J].計算機科學,2013,40(6A):210-216.
[2] 劉 堅.嵌入式多核GPU渲染流水線的研究與實現[D].成都:電子科技大學,2015.
[3] SHREINER D,WOO M,NEIDER J,et al.OpenGL編程指南[M].北京:人民郵電出版社,2007:23-51.
[4] PAUL B.Introduction to the direct rendering infrastructure[EB/OL].(2000-08-10)[2014-03-23].http://dri.sourceforge.net/doc/DRIintro.html.
[5] LINDHOLM E,NICKOLLS J,OBERMAN S,et al.NVIDIA Tesla:a unified graphics and computing architecture[J].IEEE Micro,2008,28(2):39-55.
[6] 盧 俊,顏 哲,田 澤.一種高效GPU存儲系統體系架構設計[J].計算機技術與發展,2015,25(4):6-9.
[7] 黃偉鈿.面向移動平臺的3D圖形處理器的設計[D].廣州:華南理工大學,2011.
[8] WOO J H,KIM H,YOO H J.A low power multimedia SoC with fully programmable 3D graphics for mobile devices[J].IEEE Computer Graphics & Applications,2009,29(5):82-90.
[9] WOO J H,SOHN J H,KIM H,et al.A 152 mW mobile multimedia SoC with fully programmable 3D graphics and MPEG4/H.264/JPE[J].IEEE Transactions on Very Large Scale Integration Systems,2009,17(9):1260-1266.
[10] WANG P H,CHEN Y M,YANG C L,et al.A predictive shutdown technique for GPU shader processor[J].IEEE Computer Architecture Letters,2009,8(1):9-12.
[11] 丑文龍,梅魁志,高增輝,等.ARM GPU的多任務調度設計與實現[J].西安交通大學學報,2014,48(12):87-92.
[12] 賓雪蓮,楊玉海,金士堯.一種基于分組與適當選取策略的實時多處理器系統的動態調度算法[J].計算機學報,2006,29(1):81-91.
[13] LIU Shuo,QUAN Gang,REN Shangping.On-line scheduling of real-time services for cloud computing[C]//Proceedings of the 2010 6th world congress on services.Washington DC,USA:IEEE Computer Society,2010:459-464.
[14] 劉加海,楊茂林,雷 航,等.共享資源約束下多核實時任務分配算法[J].浙江大學學報:工學版,2014,48(1):113-117.
猜你喜歡
江蘇安全生產(2023年10期)2023-11-14 12:12:58
江蘇安全生產(2022年8期)2022-11-01 09:14:48
房地產導刊(2020年12期)2021-01-14 09:25:04
消費導刊(2018年8期)2018-05-25 13:19:23
知識經濟·中國直銷(2018年3期)2018-04-12 06:43:21
商周刊(2017年22期)2017-11-09 05:08:31
中國水產(2017年2期)2017-02-25 07:56:29
中國衛生(2015年4期)2015-11-08 11:16:18
河南電力(2015年5期)2015-06-08 06:01:46
皖西學院學報(2015年5期)2015-02-28 17:52:46
