Narrative Science:講述隱藏在數據中的故事
2018-05-15 08:17:44陳銘徐麗芳
出版參考 2018年2期
陳銘 徐麗芳

摘要:機器擅長數據分析,人類更傾向于閱讀故事而不是去分析大量復雜的數據。Narrative Science是一家提供自然語言處理服務的科技公司,可以幫助客戶分析海量數據之間的關系,并轉化為簡明凝練、具有可讀性的文本。憑借優質的、不斷拓展更新的產品和服務,該公司超越最初的出版傳媒市場,為其他行業需要分析和理解大量數據的用戶提供基于自然語言的數據分析文本服務。毋庸置疑,隨著自然語言處理技術的突破,人工智能將進入更多高級人力勞動的領域。
關鍵詞:Narrative Science
2017年1月,麥肯錫全球研究所(Mckinsey Global Institute)發布的報告《可實現的未來:自動化、就業和生產力》顯示,目前人類所從事的一半職位有望在2055年實現自動化。隨著時代的不斷進步和發展,尤其是人工智能的出現,技術將逐漸取代一些需要思考能力和創造能力的高級人力勞動。
敘事科學(Narrative Science)是美國一家自然語言處理(NaturalLanguage Processing,NLP)服務提供商(公司Logo見圖1),但它并不只是為客戶提供簡單的自動化寫作服務。目前,計算機強大的運算能力可以將許多復雜的數據圖形化,卻很難將數據以自然語言輸出一篇人性化的故事呈現在人們眼前。Narrative Science所提供的服務是將海量數據或圖表輸出為生動有趣且極富洞察力的故事內容,其首席技術官克里斯蒂安·哈蒙德(Kristian Hammond)始終強調:“Narrative Science是在進行真正的創作,絕不是基于文本庫的生搬硬套。”毫無疑問,Narrative Science正在重新設定人們對于人工智能的期望,其先進的自然語言處理技術也意味著機器已經開始深度學習更多人腦思考的領域。
一、Narrative Science的成長與擴張
2010年,Narrative Science正式成立,其創辦靈感來源于美國西北大學創新實驗室里一項有趣的人工智能技術——統計猴(StatsMonkey)。和當下流行的寫作機器人小冰一樣,Stars Monkey可以自動撰寫報道,從網頁中抓取棒球比賽的數據信息,并在12秒內生成一篇生動的新聞故事傳達賽況、比賽得分和勝率概率等。同年,Narrative Science的創始人斯圖爾特·弗蘭克爾(Stuart Frankel)聯合哈蒙德共同研發出同名人工智能寫作軟件后,在美國中央情報局的相關機構如In-Q-Tel(美國非營利性質的風險投資機構,專門投資高新技術公司,旨在推動最新信息技術的應用以支持美國的情報處理能力)的大力支持下,公司正式開始商業運作。
Narrative Science起初只被應用于美國西北大學棒球比賽等體育賽事的即時報道,后來逐漸開展財經報道業務。2011年,NarrativeScience先后被《紐約時報》等知名媒體所報道,在科技創意公司中嶄露頭角。2014年,它獲得1000萬美元融資,投資方包括聯合服務汽車協會(Tlle United Services AutomobileAssociation)和巴特利風險投資公司(BatteryVentures)等。截至2017年4月,該公司共完成6輪3240萬美元的融資,與瑞士信貸、福布斯(Forbes)以及美國政府部門在內的機構建立了合作關系。Narrative Science最有力的競爭對手自動洞察公司( Automatedlnsights)因自感無法與Narrative Science直接展開競爭,將服務目標客戶定位于小型報刊。短短幾年,Narrative Science迅速擴張業務版圖,客戶范圍囊括北美、歐洲等全球各大地區的金融服務公司、互聯網企業和政府機構,一躍成為業界的領軍者(見圖2)。
1.技術核心:將數據變成可讀的人性化文本
數據已經滲透到當今的每一個行業和業務職能領域,并成為重要的生產因素。但是,如果數據沒有得到充分的智能化處理,人們無法有效吸收大量數據中所包含的信息和知識,那么這些數據就是無用的。目前,大多數知識工作者和消費者都面臨著處理海量數據并做出正確決策的挑戰。NarrativeScience希望借助計算機技術幫助用戶解讀數據,并將之轉化為可讀性較強的文字傳遞給用戶;即使是一些不熟悉高等數學和邏輯結構等數據分析知識的客戶,也能迅速地獲得數據中隱藏的關鍵信息。哈蒙德表示:“凡是數據存在的地方就應該有故事,寫作機器人的價值在于充當數字與故事之間的中介。”
“鵝毛筆(Quill)”是Narrative Science旗下的主要產品,具備強大的讀寫和敘事功能,可以自動將大量復雜的數據或圖表轉化為凝練且富有洞察力的自然語言,還允許客戶定制敘述故事的語氣。Quill采寫故事的過程分為四步(見圖3):首先,搜集大量高品質數據以建立一個龐大的數據庫,例如財經領域所涉及的每股收益、股價變化等數據。其次,在海量數據中借助算法篩選出具備講述價值的數據,即一些偏離常態的“異常數據”。Narrative Science內部有一個能進行編輯判斷的系統,將許多寫作的價值都內置于系統的算法中。再者,選擇故事的敘事結構,Quill會根據數據的重要性對各種可能的敘事角度進行排序,形成文章的整體架構。最后,把要描述的數據嵌入到系統提供的“元模板”中。“元模板”是由Narrative Science雇用一批訓練有素的文字工作者創造的寫作風格和手法,聯合計算機工程師一起“培訓”機器寫作能力而形成的。在利用“元模板”組織文章時,機器通過詞匯庫組建句子得到最后的故事。例如,Quill在分析一組有關易貝(Ebay)集團投資收益下降的數據時,生成的報道包含如下文本: “該公司的整體會計風險評估為業內平均水平以下,股價在過去的一個月里持續下跌,但對投資收益未來的調整可持樂觀態度。”這讓投資者可以避開那些晦澀難懂的數據和圖表,直接從Quill提供的文字中了解Ebay在會計層面的細微變化趨勢。機器擅長分析數據,人類則更擅長閱讀。Narrative Science的獨特之處就在于滿足了人們傾向于閱讀故事的心理。
2.市場定位:超越媒體市場,聚焦多領域大數據業務
好的技術本身并不足以成就一家成功的公司,它必須根植于適當的市場土壤中。Narrative Science在剛起步時致力于開拓媒體業務,和其他提供自動化寫作服務的公司一樣,專門為一些媒體機構和內容出版機構提供產品和服務。對于初創時的Narrative Science而言,出版傳媒行業就是一個現成的市場,報紙新聞、雜志甚至是在線出版物都需要自然語言處理工具,尤其是體育和財經報道,Narrative Science可以將記者從單調且重復的工作中解放出來。目前,包括福布斯網站、專門出版建筑類雜志的漢利伍德出版社( HanleyWood)以及體育新聞網站美國十大聯盟(The Big TenNetwork)在內的多家知名媒體都選擇使用NarrativeScience的產品。福布斯還在網站上專門設置了由NarrativeScience所生成的新聞網頁。
在掌握新聞報道的寫作藝術之后,Narrative Science意識到他們的技術在其他行業能擁有更大的機會。事實也是如此,任何需要分析和理解大量數據的公司都有可能是它的目標客戶。隨著一些金融服務公司和政府情報機構頻頻拋出橄欖枝,Narrative Science改變了戰略方向,將業務重心從出版傳媒市場轉移到各個領域的大數據業務。Quill所使用的自然語言處理技術依賴于大量高質量數據,而金融服務公司和政府情報機構擁有豐富的數據資源,以及改善與客戶溝通的迫切愿望。2017年2月,美國財務信息服務公司輝盛(FactSet)將Quill工具整合到其客戶報告的分析平臺中。作為一家金融服務提供商,FactSet為金融專業人士如投資銀行家等提供金融數據和分析服務。Quill的加入使其客戶端在季度財務報告發出的第一天就可以自動生成點評報告,所覆蓋的報告規模有望呈指數型增長,報告的客觀性和風格的一致性得到了很大提升。如今,Narrative Science的產品被許多國家和地區的數據服務提供商采用,其中包括業界領軍的大數據咨詢公司厄耐勒迪斯額( Analytics8)和商業智能服務提供商比茨數據( BizData)等。Narrative Science成功地從一家面向出版傳媒市場提供服務的“長尾媒體”公司轉型為一家編寫和銷售商業軟件的技術提供商,聚焦金融等領域的大數據業務,為用戶提供自然語言處理方面的創新性服務。
3.產品形態:不斷更新,提供豐富的產品服務
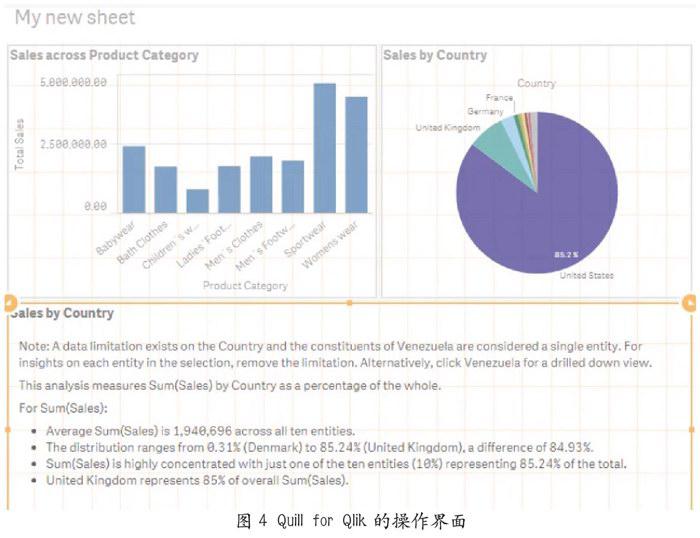
在擴大市場的同時,NarrativeScience也不斷創造和優化面向大數據服務的軟件工具,以滿足不同客戶的需求。Quill是它的第一代主流產品。2014年3月,Narrative Science在Quill的基礎上推出Quill Engage。這是一款免費的谷歌分析(Google Analytics,GA)軟件,可以簡單凝練地表達被分析對象的關鍵指標和業績表現,如網站內容的關注度、網絡訪問量等,還可以通過分析歷史數據預測行業的走向和趨勢。2016年,Narrative Science與視覺分析軟件供應商柯利克(Qlik)進行合作,推出Quill系列的第三代產品——Quill for Qlik。行業分析師塞斯·格里姆斯(Seth Grimes)表示: “這是一次商業智能領域突破性的創新。”Quillfor Qlik可以彌補可視化工具在解釋大量數據之間復雜關系時的不足,通過自然語言文本讓終端客戶更容易識別不同數據集之間的關系(見圖4)。圖4是Quill for Qlik分析各國銷售總額占比的餅狀圖。文字中條列的數據包括各類產品的銷售總額、銷售總額占比的最小值、銷售總額占比的最大值、極差和集中度等。其中,銷售總額直接反映各國的消費需求,極差反映各國銷售總額的離散幅度和波動范圍,而相對集中度則折射出各國與相對規模的差異。這些極具說服力的數據被轉化為平白淺近的文字。此外,用戶可與Qilk可視化工具生成的圖表進行交互,選擇特定的數據范圍進行重點分析。其次,這款工具可以減少原先負責生成報告和向客戶解釋數據的中層管理人員人數,讓高層管理人員直接與客戶進行互動,有利于實現公司的扁平化管理。
除了對旗下的主打產品Quill進行升級改造,Narrative Science還借助Quill的高級自然語言處理平臺推動其他面向不同客戶需求的軟件開發。微軟的PowerBI(Business Intelligence,商業智能)是一套用于分析數據和共享見解的商務分析工具,包括各種可拓展的可視化圖表。2016年,Narrative Science和微軟合作推出Narrative for Power BI。它可以從一系列數據源(包括Salesforce、Github和Adobe Analytics)中提取有效信息,自動生成書面語言。微軟PowerBI總經理尼克·卡德維爾(Nick Caldwell)認為: “Narrative for Power BI符合微軟對BI的期望,它兼具強大的數據分析和可視化功能,同時更易于理解。”2017年9月,Narrative Science與智能工具開發公司畫面軟件(TableauSoftware)聯合推出Narrative for Tableau。這是一款免費的谷歌Chrome擴展程序,可自動創建Tableau圖形的敘述性書面說明。此外,Narrative Science旗下的產品還包括服務于BI領域的套件產品等。由此可見,Narrative Science利用自然語言處理技術為各個行業中需要和數據打交道的人群提供了有力的工具。
二、自然語言處理工具的發展趨勢
通過Narrative Science的發展可以看出,自然語言生成技術已經滲透到多個領域中,孵化出諸多新形態的產品和服務。自然語言處理技術屬于人工智能的一個分支,包括自然語言理解和自然語言生成兩個方面。目前的自然語言處理工具還達不到完全取代人工的水平,人們也還不能準確預測其最終發展態勢和結果,但仍可以對其發展趨勢有一個簡單的判斷。
(1)在文本理解方面,從淺層分析邁向深度理解。由于算法的局限,機器人暫不能對文本進行準確又深入的分析。此外,不是所有文化現象都能像物理科學那樣在算法中被規則量化,即使是以挖掘最具洞察力數據聞名的Narrative Science,也不能保證每一次的文本分析都是有足夠深度的。隨著算法的不斷迭代和數據庫的不斷擴大,計算機基于深度神經網絡強大的“記憶力”以及提取復雜特征的能力,可以得出更精準的判斷。谷歌等科技巨頭也已經開始對機器人進行“閱讀理解”培訓,以深入探索自然語言理解技術,促進自然語言理解工具從淺層分析邁向深度理解。
(2)在文本生成方面,由事實性文本到情感文本。現在的自然語言生成工具大多被用來生成一些事實性的新聞報道或文字報告,因此許多自然語言處理工具背后的科學都被認為是非人性的和機械的。工程師試圖讓自動化文本變得更加人性化,就像Narrative Science的初衷——旨在利用自然語言處理工具等先進的技術來縮小人類和機器之間的交流缺口(communication gap)。一些學者在研究時,嘗試將人文主義方法和計算機算法整合為一種新的文本生成方法,將語調和情緒等交流元素與自然語言處理工具相結合,讓機器人不僅擁有推理和歸納能力,還具有明確的態度和立場,從而實現從事實性文本向富含情感、體現人性的文本轉變。
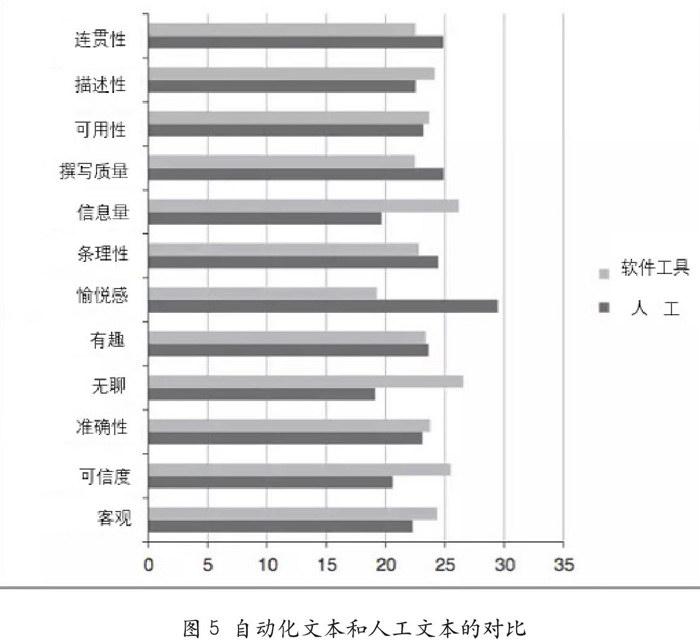
(3)人機協作將成為業界未來的發展趨勢。瑞士卡爾斯塔德大學的研究表明,自動化文本更具描述性,信息量較大且更客觀可信。但是,在可讀性方面不如人類所寫的文章質量高,閱讀的愉悅感較弱(見圖5)。雖然自然語言處理工具的進步一定會推動自動化文本朝人工文本的水準逼近,但完全替代并不是短期內能夠實現的。人工參與必不可少;而智能工具的存在,也并不完全是對人工的威脅。找到人工和機器的平衡點,兩者相互配合,才能從一個“弱人工智能時代”進入“強人工智能時代”。自然語言處理工具已經成為一種有效的信息表達手段。由計算機撰寫的文章逐漸從原先的邊緣化位置抵達各個領域的數據分析場域,即由為傳統媒體機構和出版商提供簡單重復勞動轉向社交媒體和其他領域的大數據業務。正如Narrative Science -直在做的兩件事:了解數據中的信息,并為特定受眾提供有用的可讀性文本。自然語言處理技術將越來越能勝任需要認知能力的活動。
參考文獻: 1. Narrative
Science [EB/OL]. [2017-10-22].https://narrativescience. com/.
2.Mckinsey Global Institute. A futurethat works: Automation, employment, andproductivity [EB/OL]. [2017-10-22]. https://www.mckinsey.com/.
3.Alex Woodie.Your Big Data Will Read ToYou Now[EB/OL].[2017-10-23].https://www.datanami. com/2014/10/28/big-data-will-readnow/.
4.霍伊特·朗,蘇真.文學模式識別:文本細讀與機器學習之間的現代主義[J].林懿,譯.山東社會科學,2016 (11):34-53.
5.Mike Pham.AI needs a human touch tofunction at its highest level[EB/OL]. [2017-10-23].https://venturebeat .com/2 01 7/09/21/ai-needsa -human-to uch-to-function-at-its-highestlevel/.
6.唐偉勝.認知敘事學視野中的敘事理解[J].外國語,2013 (4):28-36.
7.慧博.深度學習成NLP發展新引擎,深層次認知將是未來突破方向[EB/OL]. [2017-1031]. http://pg.jrj.com.cn/acc/Res/CN_RES/INDU S/2 017/10/31/eb94785f-92b4-448d-b2446220cef9b332.pdf.
8.李陽輝,謝明,易陽.基于深度學習的社交網絡平臺細粒度情感分析[J].計算機應用研究,2017,34(03):743-747.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
語文知識(2014年1期)2014-02-28 21:59:13
