基于大數據的實驗室安全風險評估
2018-04-13 06:36:32王揚
現代電子技術 2018年8期
王揚
摘 要: 傳統實驗室安全風險評估法常使用數據評估與人為評估相結合的形式進行評估,易造成理論數據與實踐數據相違背的問題,于是提出基于大數據的實驗室安全風險評估方法。通過構建實驗室安全風險評估總體框架,完善各模塊間的協作效應,并給出評估流程圖,引入大數據評估方法,利用數據貼合度,重新確立肯特指數,通過評估參數預設,確立三項指標,實現實驗室安全風險的評估。實驗結果表明,采用改進評估方法進行實驗室安全風險評估時,其風險評估精度較高,耗時短具有一定的優勢。
關鍵詞: 大數據; 實驗室安全; 風險評估; 貼合度; 評估精度; 肯特指數
中圖分類號: TN919?34; TP393 文獻標識碼: A 文章編號: 1004?373X(2018)08?0113?03
Abstract: In the traditional laboratory safety risk assessment method, the form of data assessment and artificial assessment combination is often used for assessment, which can easily result in violation of theoretical data from practical data. Therefore, a laboratory safety risk assessment method based on big data is proposed. The coordination effect between various modules is improved by constructing the overall framework of laboratory safety risk assessment. The diagram of assessment process is given. The big data assessment method is introduced to reestablish the Kent index by using the data fit degree. Laboratory safety risk assessment is realized by assessing parameter presupposition and establishing three indices. The experimental results show that the improved assessment method for laboratory safety risk assessment has certain advantages with high risk assessment accuracy and short time consumption.
Keywords: big data; laboratory safety; risk assessment; fit degree; assessment accuracy; Kent index
0 引 言
試驗室進行試驗過程中,許多試驗數據是不可控制的,會伴隨極大的未知性、突發性。特別是針對物理、化學等專業性較強的試驗,發生突發事件的可能性較大,一旦發生安全隱患可能是極其嚴重事故 [1]。傳統實驗室安全風險評估方法,使用的是理論數據與人為實踐數據相結合的方式,進行風險評估,由于理論數據在一定范圍內,而實踐數據是執行數據,因此會產生一定的偏差,產生評估數據間隙,最終導致評估結果有誤。針對上述問題,提出基于大數據的實驗室安全風險評估方法。利用大數據的數據堆積性進行數據的填充,改變傳統方法的理論數據與實際數據相違背的情況,大數據使用過程帶有一定的數據躍遷性,對肯特指數法進行改進,完成實驗全風險評估。為了驗證設計方法的有效性,模擬使用環境進行仿真試驗,試驗數據表明,設計的實驗室安全風險評估方法能對實驗室進行高精度的安全風險評估。
1 實驗室安全風險評估方法總體構建
改進實驗室安全風險評估方法,采用大數據能夠更好地評估安全風險中的“不確定性”以及“未知性”[2?3],大量的大數據在決策過程中起到數據參考、信息參評的作用。將預先知道的事件用數據形式進行概率和條件的轉換,符合對實驗室的評估決策的流程,并且簡化了推算的過程[4]。通過改進評估方法對整體框架進行設計,導入大數據后,對肯特指數法進行改進,方便大數據評估使用,通過建立實驗室安全風險評估體系,能夠實現實驗室安全評估。改進實驗室安全風險評估方法的流程如圖1所示。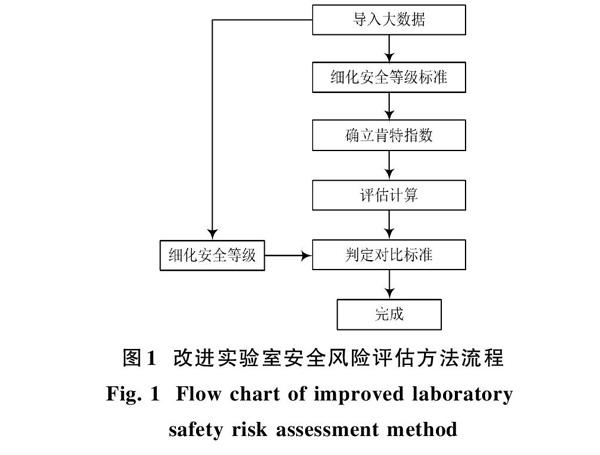
1.1 數據貼合度的計算
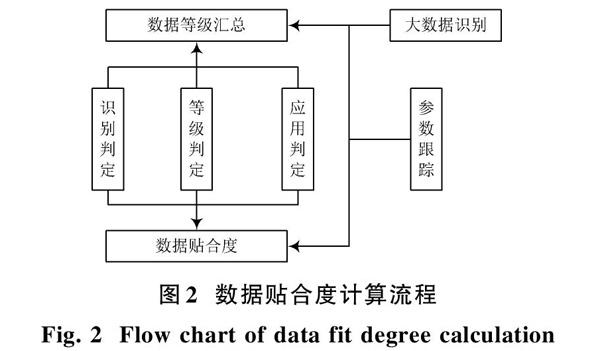
大數據在安全審核過程中,能夠提供安全規范以外的數據,相當于在對實驗室的安全條例進行補充,導入的大數據在一定使用范圍內填充理論數據與實踐數據間的空白[5?6]。引入大數據自身是一個數據集合,其中包括安全級別數據、安全章程數據、安全執行數據。
安全級別數據將安全等級進行劃分,不同實驗室安全等級也不同,作為院校級的試驗室安全等級為一級;國家試驗室為特級,以此類推[7]。不同等級下要求安全章程數據是不同的,引入大數據中包含安全章程數據根據,安全等級進行數據匯總。安全章程數據過程表征量表示如下:
1.2 肯特指數的優化
在實驗室安全風險評估過程中,傳統的實驗室風險值計算方法是:風險概率值乘以風險損失得到最終結果。在改進實驗室安全風險評估方法中已不適用,結合本文安全風險評估方法的特點,對肯特指數法進行優化。大數據的引入細化了數據的安全等級以及風險事項,肯特指數需要通過細化的數據對優化的安全等級數據進行優化,肯特指數是以安全等級為標準,對基礎數據進一步更新,自身攜帶的細節數據將肯特指數中基礎數據進一步細化分析。執行過程中數據為了避免發生數據脫離,需要貼合新安全數據標準,重新對肯特指數進行設定,肯特指數計算如下: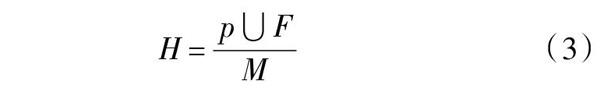
1.3 實驗室安全風險評估
經過上述大數據的引入、肯特指數的優化,能夠實現實驗室安全風險評估。實驗室安全風險評估首先對三項指標進行確認,其中包括硬性指標、非控指標、人為指標。硬性指標是通過實驗室自身配備所得出的,一般與評估流程評估方法無關。非控指標是由突發事件所形成,一般非控指標在計算過程中是一個集合量,本文設計的實驗室安全風險評估流程如圖4所示。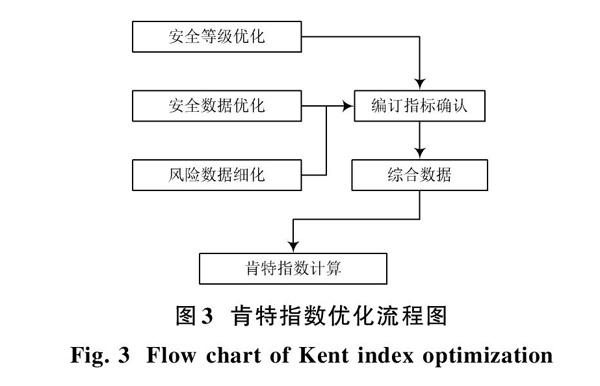
通過圖4可看出,本文設計的基于大數據的實驗室安全風險評估方法能夠細化安全數據的級別,將原有簡單概率乘以損失率的計算過程變得細化,同時評估的結果也是以數據的形式體現,方便對照結果。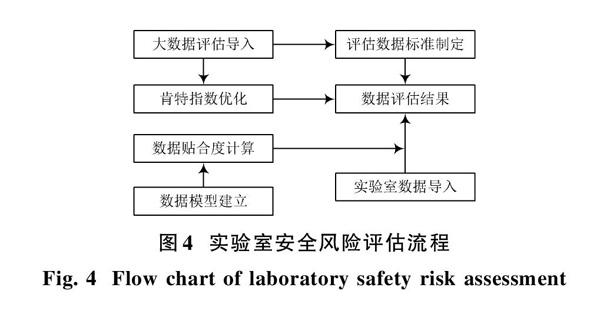
2 試驗分析
2.1 試驗參數設定
為了驗證改進實驗室安全風險評估并且驗證設計評估方法的有效性,以高科試驗室為研究對象,分別設計了兩組實驗。在第一組實驗中,使用傳統評估方法與改進評估方法相比較,在不同實驗環境下驗證評估精準度。在第二組實驗中,驗證的是本文設計的基于大數據的實驗室安全風險評估方法的有效性,以碰撞物理實驗為例,模擬實驗每組執行10次,每次試驗對機械軸承進行碰撞試驗。分析過程,觀察每次實驗中評估風險結果,以此判斷本文設計方法的有效性。為了試驗的嚴謹性,對實驗數據進行設置,結果如表1所示。![]()
2.2 試驗結果分析
2.2.1 對比試驗
本文分別從試驗風險程度以及試驗安全系數上進行評估,使用傳統實驗室安全風險評估方法與本文設計安全風險評估方法進行比較,對不同的試驗參數下,分別記錄評估GTRF函數的變化以及在三種試驗流程下的試驗評估結果,如表2所示。
2.2.2 有效性試驗
表3是在不同試驗流程條件下,對本文設計的基于大數據的實驗室安全風險評估方法進行有效性的測試,觀察評估過程體系數據變化、可能性數據變化、損失性變化。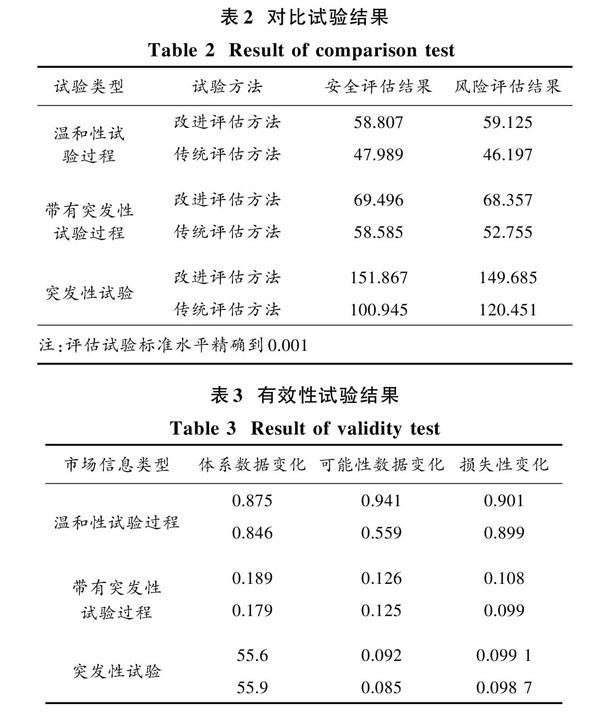
通過表3的數據可以看出,本文設計的評估方法在對象評估數據上都是連續的,并帶有一定承接關系,說明評估過程中是有效的。在多數據的堆砌下,通過體系數據變化、可能性數據變化的數據能夠說明該方法在適用度上具有較高的有效性。
3 結 語
本文設計的基于大數據的實驗室安全風險評估方法在導入大數據后,改變傳統數據分析過程,對肯特指數法進行改進,實現實驗室安全風險評估。希望通過本文的研究能夠提升實驗室安全性。
參考文獻
[1] 陳紅倩,方藝,楊倩玉,等.一種針對農殘檢測數據的時序分組可視化方法[J].系統仿真學報,2016,28(10):2510?2518.
CHEN Hongqian, FANG Yi, YANG Qianyu, et al. Temporal group visualization method for pesticide residue detection data [J]. Journal of system simulation, 2016, 28(10): 2510?2518.
[2] 黃天恩,孫宏斌,郭慶來,等.基于電網運行大數據的在線分布式安全特征選擇[J].電力系統自動化,2016,40(4):32?40.
HUANG Tianen, SUN Hongbin, GUO Qinglai, et al. Online distributed security feature selection based on big data in power system operation [J]. Automation of electric power systems, 2016, 40(4): 32?40.
[3] 孫宏斌,黃天恩,郭慶來,等.基于仿真大數據的電網智能型超前安全預警技術[J].南方電網技術,2016,10(3):42?46.
SUN Hongbin, HUANG Tianen, GUO Qinglai, et al. Power grid intelligent security early warning technology based on big simulation data [J]. Southern power system technology, 2016, 10(3): 42?46.
[4] 趙國朕,宋金晶,葛燕,等.基于生理大數據的情緒識別研究進展[J].計算機研究與發展,2016,53(1):80?92.
ZHAO Guozhen, SONG Jinjing, GE Yan, et al. Advances in emotion recognition based on physiological big data [J]. Journal of computer research and development, 2016, 53(1): 80?92.
[5] 琚安康,郭淵博,朱泰銘.基于開源工具集的大數據網絡安全態勢感知及預警架構[J].計算機科學,2017,44(5):125?131.
JU Ankang, GUO Yuanbo, ZHU Taiming. Framework for big data network security situational awareness and threat warning based on open source toolset [J]. Computer science, 2017, 44(5): 125?131.
[6] DENG Z, ZHU X, CHENG D, et al. Efficient kNN classification algorithm for big data [J]. Neurocomputing, 2016, 195(C): 143?148.
[7] DADDABBO A, MAGLIETTA R. Parallel selective sampling method for imbalanced and large data classification [J]. Pattern recognition letters, 2015, 62(C): 61?67.
[8] REBENTROST P, MOHSENI M, LLOYD S. Quantum support vector machine for big data classification [J]. Physical review letters, 2014, 113(13): 1?5.
[9] WANG Kun. Research and implementation of classification parallel algorithm based on GPU [J]. Electronic design engineering, 2014, 23(18): 39?41.
[10] LUO Xiaolin. A new classification algorithm by training with authentic virtual samples [J]. Bulletin of science and technology, 2013, 32(6): 107?109.
猜你喜歡
中國科技博覽(2017年2期)2017-03-30 20:57:59
軟件導刊(2017年1期)2017-03-06 23:54:58
教育教學論壇(2016年43期)2016-11-22 14:37:16
文理導航(2016年30期)2016-11-12 14:48:49
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
電腦知識與技術(2016年8期)2016-05-19 13:56:11
