電力通信網絡中OSPF區域劃分問題的研究
2018-02-08 08:28:34李祝紅趙燦明
微處理機 2018年1期
關鍵詞:區域
李祝紅,趙燦明
(國家電網蕪湖供電公司,蕪湖241000)
1 引言
OSPF協議作為一種基于鏈路狀態的內部網關路由協議,廣泛應用于目前的Internet廣域網和Intranet企業網中,支持區域劃分。AS(自治系統)中的路由器之間通過周期性的hello報文建立鄰居關系之后,每個OSPF路由將本地的路由信息(如路由ID,可用端口,鄰居列表信息等)通過泛洪LSA(鏈路狀態通告)的形式在自治系統內部傳播鏈路狀態信息。收到LSA的路由器將LSA信息結合本地的鏈路狀態通告信息形成LSDB(鏈路狀態數據庫),形成本地路由器對整個網絡拓撲的理解,通過SPF算法決策出最小代價的無環路由,形成本地路由選擇表。
假設電力通信網絡作為一個自治系統來運行OSPF協議,隨著電力通信網絡的進一步擴大,運行OSPF的路由器也會相應地出現數量上的增長,每個路由器維護的龐大的LSDB占用大量的內存空間,路由計算復雜度增加,路由器之間的通信量會占用大量的帶寬,導致OSPF協議路由效率低下。為了降低LSDB的數據級別并減少對網絡設備CPU和帶寬的占用,提高運行效率和網路收斂速度,需要進行合理的區域劃分。
現有關注網絡收斂速度的路由或者區域搜索技術尚未對區域劃分有一個全局的劃分方案,包括區域邊界的確定等。鄭金華等[1]提出,用數學方法難以解決函數優化中的區域劃分問題。為此,文獻[1]提出了用狹義遺傳算法實現區域劃分的方法,實現了基于自動區域劃分的分區域搜索的狹義遺傳算法,從理論上分析了算法是全局收斂的,并具有收斂速度快、搜索過程穩定性高、可控制性強等特點。張丹丹等[2]將所建立的變電站規劃模型和求解算法應用于青州地區配網高壓變電站優化規劃實際算例,算例中分析了權重調整量取值不同對最終規劃方案的影響,驗證了解耦規劃模型的合理性、可行性和PSO算法及加權K求解算法計算速度快、收斂性好等特點。肖迎杰等[3-4]在改進的ZRP路由協議中運用新的域生成算法,通過引入通信節點個數的概念,以通信節點個數較多的節點為中心生成域,減少了域的個數,避免了節點及域的重復歸屬;以域生成算法中的中心節點為簇首節點,運用改進的路由算法,由簇首節點負責路由轉發,避免了路由的冗余轉發,路由開銷也隨之減少,提高了路由效率。胡海洋等[5]提出一種虛擬分布式環境中基于密度聚類的改進型劃分算法 (DCCA)。該方法改進密度聚類中的鄰域半徑(Eps)和最小數目閾值(MinPts)因子,提出了基于移動視窗方法的密度聚類方法。楊帆等[6]分析現有面狀數據聚類算法的特點和不足,進而提出一種新的算法,該方法提出將面狀統計單元進行網格劃分,引入基于網格密度聚類算法的思想,克服現有面狀聚類的諸多缺點,進行二維空間平面的區域劃分。夏少波等[7]提出一種在無線傳感網絡中定位算法的改進機制,對網絡進行基于跳數的重新區域劃分。謝珊珊等[8]對規模較大的無線傳感器網絡容易產生冗余數據包等問題,提出基于區域劃分的連通支配集協議,RPMPR協議中每個節點針對網絡拓撲信息,對鄰居節點進行區域劃分,作為中繼轉發的選擇依據。以上所述算法對于特定的路由或其他協議進行基于區域劃分的改進,并不適合OSPF區域劃分的特性。研究提出的算法旨在通過結合電力通信網絡實際情況,通過選擇未來區域內的中心匯聚節點對鄰居節點進行區域劃分,解決區域劃分的覆蓋度和合理度問題。
2 相關描述
2.1 問題模型
OSPF協議網絡可以劃分為邏輯上互連的幾個區域,來降低前文所述的影響。路由器LSA泛洪過程在所屬區域進行,區域內部路由器只維護此區域的局部拓撲數據庫和理解局部網絡拓撲圖,當網絡拓撲變更時,會減少OSPF協議報文的傳遞數量,減少對帶寬的占用。區域之間LSA通告信息的交互,通過域間邊界路由器(ABR)完成,如圖1所示,R2,R4,R9即為ABR,同時屬于多個區域的ABR為每個區域維護各自的LSDB。OSPF協議網絡的區域類型可以簡化概括為:骨干區域和非骨干區域。如圖1中所示區域ID為A0的區域即為骨干區域,負責各個子區域間的通信;A1,A2,A3為非骨干區域。
區域的劃分由OSPF協議自動進行,并覆蓋網絡拓撲中的所有節點,防止區域邊界路由器負載過重,均衡鏈路負載,保證骨干區域能夠盡可能與子區域之間建立物理上的鏈接,以方便子區域間的通信,這是電力信息網絡OSPF區域劃分需要解決的關鍵問題。
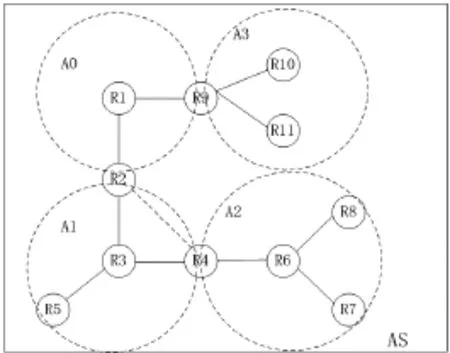
圖1 OSPF區域簡化示意圖
2.2 相關定義
電力通信網絡拓撲區域劃分問題實際上可以歸結為圖的劃分問題,即用無向圖G=(R,E)來描述電力網絡的拓撲結構,其中R表示路由節點集合,E表示節點之間的所有鏈路集合。
為方便描述,給出以下相關定義:
定義1一跳鄰居集合:無向圖G=(R,E)中,對于任意節點r∈R,節點r的一跳鄰居集合:
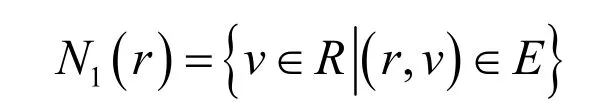
定義2E領 域:給定對象節點半徑為E的區域為該對象節點的E領域。
定義3 直接密度可達:對于節點集合R,如果節點q在p的E領域內,并且p為核心對象節點,那么節點q 從節點p直接密度可達。
定義4 兩跳密度可達:對于節點集合D,給定一串樣本節點P1,P2,P3。假如節點P2從P1直接密度可達,節點P3從P2直接密度可達,節點P3從P1兩跳密度可達。
3 基于網絡密度聚類的區域劃分算法
3.1 骨干區域的確定
通過OSPF信息交換(hello報文),每個節點獲得一跳鄰居信息(包括節點ID等信息),并周期性地與鄰居節點交換自身節點維護的一跳鄰居列表信息,每個節點也可獲得k-跳鄰居信息(包括路徑上的下一跳信息)。
骨干區域匯總各個子區域的路由信息,并負責完成子區域之間的通信,故骨干區域與各個非骨干區域之間通過物理鏈路或者虛擬鏈路直接相連。考慮電力通信網絡的實際情況,可以以網絡中核心路由器節點作為中心負責節點,以一跳鄰居節點集合為半徑范圍,作為骨干區域的初始邊界即如圖2所示,此時的可能部分成為骨干區域內部的路由器節點,部分路由器元素節點集合成為區域邊界路由器(ABR)。
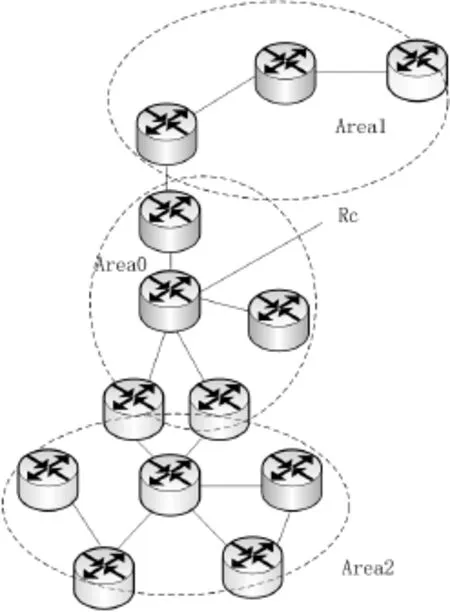
圖2 區域劃分結果示意圖
3.2 非骨干區域的確定
完成網絡拓撲的關于骨干區域的粗粒度分割后,需要對拓撲中為進行區域劃分的其他節點集合NB進行細粒度劃分。各個非骨干區域內容元素節點的確定,可以采用基于密度(網絡跳數)聚類的迭代過程實現。
3.2.1 基于密度的聚類算法
所謂聚類,就是將大量d維數據樣本聚集為k個類,使同屬一個類的樣本相似度最高,不同類中樣本的相似性最小。基于密度的聚類算法考慮將空間數據樣本中被低密度區域分割開的高密度區域聚集為類(簇),并能識別噪聲。
DBSCAN(Density-based Spatial Clustering of Applications with Noise)[9]是一種代表性的聚類算法,其基本思想為:掃描整個數據樣本集,選定一個核心點進行聚類,核心點鄰域內的所有節點與核心點同屬一個簇,并將這些節點作為下一輪擴充的種子節點,迭代聚類,直到找到所有與種子節點密度可達的點,形成一個完整的簇,重復此過程,直到所有種子節點聚類完成。對于數據樣本中未聚類的點,繼續如上過程,直到所有核心節點聚類過程完成,剩余未聚類的點成為噪聲節點。
3.2.2 電力網絡聚類算法MDBSC
電力網絡中劃分后的區域可以看作聚類算法中的簇。雖然網絡拓撲中節點密度的特征沒有那么明顯,但可以通過指定網絡跳數作為稀疏的另一種度量,即拓撲中節點之間的跳數作為衡量密度的距離指標。節點同時考慮網絡跳數和空間地理位置因素的情況下,每個路由器節點維護一組2維空間數據,表示此節點r與網絡中其他節點v 的關系。其中hops表示與目標節點的拓撲距離(網絡跳數),dist表示與目標節點的地理空間距離。為簡化節點數據取樣復雜度,當dist超過一定距離值后,dist等于1,否則dist取值為0。
MDBSC具體的算法描述如下:
1)輸入:
2)輸出:
DV={dv1,dv2,...,dvk},代表區域劃分的簇集合,以及邊界路由器集合
(1)閾值MinPts的確定。考慮鏈路負載均衡,若MinPts值過大,減少聚類的數目,每個區域集合規模過大,達不到區域劃分降低流量和快速收斂的目的。若MinPts值過小,區域數目過多,區域規模過小同樣不利于快速收斂的實現。假設電力網絡拓撲中節點個數為N ,骨干區域核心節點RC一跳相連的鄰居節點個數為M ,負載均衡值為N/M,考慮集合規模為跳的情況下,可設
(2)在區域數量不確定的情況下,選定某些節點作為聚類過程的匯聚節點,稱為核心節點(核心點)。中的所有元素均為待選舉的核心對象節點,若給定對象E領域內節點元素數量超過一定的閾值MinPts,則將該節點選作核心節點。
對于任意路由節點r∈NB,以E等于一跳鄰居距離為半徑,即采用歐幾里得距離計算方式時,值為1,計算此節點的E 領域集合E(r),若E(r)中包含的元素個數滿足核心對象節點的選舉條件,則r成為核心對象節點。
(3)核心節點r的E領域E(r)中的所有直接密度可達節點中任意節點v ,作為種子節點尋找所有與之直接密度可達的節點集合W,即W中所有節點與節點r兩跳密度可達。中間涉及一些兩跳密度可達節點的合并。
(4)重復步驟(2)中的過程,直到所有種子節點聚類過程完成。此時與節點r同屬一個區域的被標記節點中有可能包含骨干區域A0的節點,相應的這些交集節點成為區域與骨干區域的邊界路由器節點,加入邊界路由器集合。NB中未被進行區域劃分的其他節點,暫時標記為自由節點。
(5)對于NB中選舉的其他核心節點,重復步驟(2),(3),遍歷所有核心節點E領域的聚類(區域劃分)過程,所有遍歷過的節點中,與r直接密度可達或者兩跳密度可達的節點組成以r為核心節點的區域(簇)。
(6)步驟(3)中被標記為自由節點的路由器在遍歷所有k個核心節點的過程中部分可能會轉換為已聚類節點,在此過程中如果出現某一個已聚類節點同時滿足另一個核心節點的區域劃分條件,則此節點自動成為兩個區域的邊界路由器節點ABR,即同時屬于兩個區域集合。
(7)步驟(4)結束后,自由節點通過查詢自身維護的一跳鄰居集合,選中相距dist等于0的任意一個節點所屬區域(簇)dvi為 自由節點的區域(簇)。
以上算法大致描述了聚類(區域劃分)過程,完成了對整個網絡拓撲的區域劃分。返回達到密度要求的區域集合如圖2所示,形成Area1區域和Area2區域。當網絡中有新節點加入時,根據新節點與邊界路由器集合中元素拓撲距離,并比較其直接相鄰的路由器節點的主要歸屬區域,分別計算節點與計算目標區域的相關度,作為區域選擇的依據,即相關度最高的區域作為此新加入節點的歸屬區域。
4 實驗
4.1 實驗設置
模擬仿真實驗采用的網絡拓撲為蕪湖市電力通信網絡的真實廣域網拓撲,包括66個子網絡節點(支持OSPF協議的路由器節點和三層交換機節點)。實驗通過兩個步驟來驗證,首先將網絡拓撲中的節點信息初始化成為數據集合的形式,作為算法的輸入,對拓撲中的節點進行區域集合劃分。其次,依據上個步驟得到的數據集合,通過OSPF協議驗證的網絡仿真模擬器,對節點進行IP、接口、區域、網關等配置,并仿真運行OSPF協議。論文中針對協議的性能仿真主要是從路由協議網絡收斂性,協議開銷方面進行仿真分析,將為劃分區域的原始拓撲圖作為實驗比較對象。
實驗的仿真平臺基于Visio Studio 2013和OPNET Modeler 14.5,分別用來進行區域劃分和OSPF路由協議的仿真。拓撲規模設定為100km×100km大小,路由器間節點鏈接設置為100Base-T局域網鏈路,默認每個節點為100Base_TLAN邏輯子網的出口。
4.2 實驗運行結果與分析
通過對基于密度的聚類算法DBSCAN進行改進,提出電力網絡區域劃分的MDBSC算法,實驗結果如圖3、圖4及圖5。
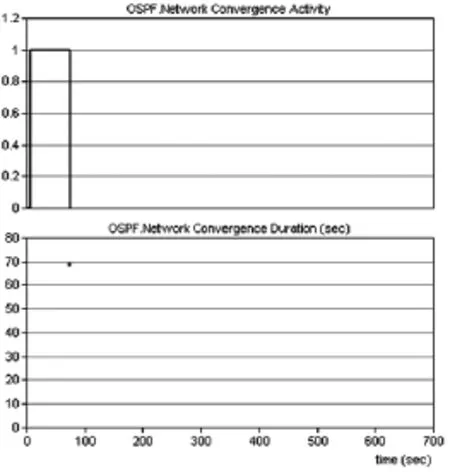
圖3 OSPF協議路由收斂仿真結果
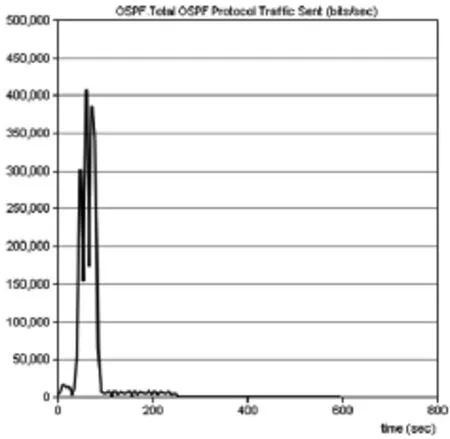
圖4 OSPF協議開銷仿真結果(區域劃分后)
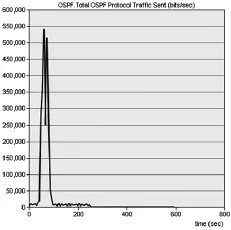
圖5 OSPF協議開銷仿真結果(區域劃分前)
結合圖3的OSPF.Total OSPF Protocol Traffic Sent和 OSPF.Network Convergence Activity可以看到,OSPF網絡在仿真進行25秒后開始,在大約100秒時結束,收斂周期大概為75秒,這與OSPF.Network Convergence Duration中顯示的大概75秒的周期是一致的,結果顯示的收斂周期對于100km×100km規模的企業網絡而言,是合理且較為高效的。
從圖4的OSPF.Total OSPF Protocol Traffic Sent中可以看出,在OSPF網絡收斂周期內,路由數據交換的數據量較大,圖4維持在300000~400000bit/s的特定區間內。圖5峰值時期數據交換量達到550000bit/s,這是因為OSPF在區域劃分的條件下區域內的路由器只需要與區域內路由通信,而不需要洪泛到整個網絡拓撲,減少了OSPF形成穩定路由過程中的協議開銷。OSPF達到收斂狀態后,數據交換量趨于穩定,維持在一個較低的水平,整體的開銷也處于一種較低的水平。從圖4、圖5的對比可以看出,區域劃分對提高網絡收斂速度,減少協議開銷方面的有利影響。
5 結束語
為解決大規模電力通信網絡中OSPF區域劃分問題,研究提出一種改進的基于網絡密度聚類的區域劃分算法,并在此基礎上實施OSPF協議。算法在大規模復雜網絡條件下能較好的實現自動區域劃分,避免了對網管經驗的過分依賴。算法首先通過周期性信息交換獲得一跳鄰居信息,然后參考網絡跳數和地理位置進行聚類分簇,完成初始區域劃分。考慮到網絡負載均衡的問題,需要對劃分進行細化。區域中節點數量閾值,仍有待于更加準確的測算。
[1]鄭金華,蔡自興.自動區域劃分的分區域搜索狹義遺傳算法[J].計算機研究與發展,2000,37(4):397-400.ZHENG Jinhua,CAI Zixing.Restricted genetic algorithm of area searching based on automatic area parting[J].Journal of ComputerResearchandDevelopment,2000,37(4):397-400.
[2]張丹丹.基于PSO-加權Kruskal算法的城市電網高壓變電站規劃[D].濟南:山東大學,2012.ZHANG Dandan.High voltage substation planning of urban electric power networks based on PSO-weighted Kruskal algorithm[D].Jinan:Shandong University,2012.
[3]肖迎杰.改進的ZRP路由協議的研究[D].山東大學,2009.XIAO Yingjie.The research based on the improved ZRP routing protocol[D].Shandong University,2009.
[4]付光輝.基于簇域機制的ZRP改進研究[D].西南大學,2011.FU Guanghui.The research of the zone routing protocol based on cluster[D].Southwest University,2011.
[5]胡海洋,許旭,胡華.虛擬環境中一種基于密度聚類的區域劃分算法[J].系統仿真學報,2012,24(9):1868-1872.HU Haiyang,XU Xu,HU hua.Density-based clustering approach for partitioning avatars in vitual environments[J].Journal of System Simulation,2012,24(9):1868-1872.
[6]楊帆,米紅.一種基于網格的空間聚類方法在區域劃分中的應用[J].測繪科學,2007,32(S1):66-69.YANG Fan,MI Hong.A grid-based spatial clustering algorithm for zone parting[J].Science of Surveying and Mapping,2007,32(S1):66-69.
[7]夏少波,連麗君,鄒建梅,等.基于區域劃分的DV-Hop定位算法的改進[J].山東科學,2015,28(3):110-116.XIA Shaobo,LIAN Lijun,ZOU Jianmei,et al.The improvement for DV-Hop localization algorithm based on regional division[J].Shandong Science,2015,28(3):110-116.
[8]謝珊珊,白光偉,曹磊.基于區域劃分的連通支配集協議[J].計算機工程與設計,2012,33(4):1319-1323.XIE Shanshan,BAI Guangwei,CAO Lei.Protocols of determining connected dominating sets based on region partition[J].Computer Engineering and Design,2012,33(4):1319-1323.
[9]Ester M,Kriegel H P,Xu X.A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]//International Conference on Knowledge Discovery and Data Mining.AAAI Press,1996:226-231.
猜你喜歡
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
科學(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農墾科技(2016年2期)2016-08-21 13:50:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
新疆財經大學學報(2015年3期)2015-12-10 03:49:15
