公共衛生大數據研究進展
——生物信息的新領域
2018-01-17 02:52:41馬天有王麗娜杜建強吳曉明
生物信息學 2017年4期
馬天有,胡 曦, 王麗娜,杜建強,吳曉明*
(1. 環境與疾病相關基因教育部重點實驗室(西安交通大學),西安710061;2. 生物醫學信息工程教育部重點實驗室(西安交通大學),西安710049)
目前健康相關的檢測和測試手段,產生了大量數據,這些數據包括來自醫院的門診和臨床數據、家庭小型便攜式設備的檢測監護數據、醫療保險機構的就醫數據,可穿戴設備產生的個人健康數據、以及來自公共平臺的人口、微生物分布、食品保健、產品銷售等信息。這些信息能從不同角度對公共衛生相關情況進行呈現。通過利用并開發合適的數據處理和挖掘方法,能發現公共衛生數據中隱含的信息,并形成指導改善公共健康的方案和措施。但是由于信息的多元化和不確定性,此類數據如何進行有效利用,需要政策、技術、資金、算法、數據管理等多方面的支撐。
通訊網絡不斷深入到日常生活,將成為獲取和傳播公共衛生數據的重要手段。對其進行合理利用,可將信息采集功能拓展到更廣泛的領域,也有助于提高傳染病、突發事件監測的準確性,以便科學合理地實現快速響應,降低疾病和公共衛生事件的危害。基因數據和健康數據涉及生命活動機理,對其進行挖掘和分析,也可以提供更為準確的風險評估及個體化干預措施,人們可就此改變不良生活習慣,減少危險因素[1]。進行公共衛生數據分析將在健康領域發揮重要作用。本文對公共衛生大數據研究的方法、技術和前景進行探討,認為需要從政策、人才、硬件等方面形成支持,同時對數據進行收集、管理、分析和挖掘,最終形成個人和社會的受益。
1 公共衛生數據來源廣泛
用于公共衛生研究的數據有非常廣泛的來源,它們互相補充,相互支撐,能體現群體性健康問題的各種特征,數據的種類可以包括以下幾方面:
1)醫療數據。醫療機構擁有患者個人的多種信息,其中的臨床數據是和個人健康密切相關的信息。當作為整體進行考察時,能夠體現同大規模公共衛生事件相關的信息。隨著中國推進分級診療和家庭醫生簽約服務,家庭醫生更能夠對患者進行健康監測,形成健康數據,會成為公共衛生數據的重要源頭。
2)家庭護理和便攜式設備檢測數據。家用智能健康測量裝置均可產生和記錄健康相關數據。一些產品已經面市,包括智能體重秤、藍牙血糖儀、電子血壓計等。智能手環、計步器、專門測量呼吸的運動背心等,也可產生大量健康數據。如WellDoc公司研發的基于手機App和云端大數據的糖尿病管理平臺,是獲得美國食品和藥品管理局批準的手機應用,用戶可以通過手機實時記錄、存儲和利用糖尿病數據。通過進行實時挖掘分析,可為患者提供個性化反饋,指導患者進行改變生活方式,并為醫生的診療提供有效依據[1-2]。這些數據的特點是數據量大、種類繁多,但準確性較差,需進行有效的校準和過濾方可使用。
3)地理信息數據。由于公共衛生數據大都具有空間屬性,進行大數據分析時也常結合地理信息系統(GIS)來分析研究其空間特征和規律[3]。通過結合地理位置、行政區域、氣象條件等,數據的空間特點可以進一步體現。
4)生物醫學數據庫和政府基礎平臺。互聯網的各類公共生物數據庫提供了有關生物分子、微生物分類等的詳細信息[4]。中國最新建設的“國家人口與健康科學數據共享平臺”(http://www.ncmi.cn/1),也已經包含237個數據集,數據量達到49.1 TB,覆蓋包括生物醫學、基礎醫學、臨床、公共衛生、中醫藥學、藥學、人口與生殖健康七大類,將帶動生物醫學數據資源整合與共享,為實現健康中國2030年的戰略目標發揮作用。
5)其他數據。氣象、輿情、疫情、農作物和食品安全等數據,均可用于公共衛生研究。未來,數據的種類和數量將會繼續增加。事實上,所有可用于進行公共衛生狀況分析的數據,都應該被考慮,并被廣泛收集,從而形成全面的數據支撐。但是,這些數據存在非常高的異質性,數據中有價值信息少,含金量不高,需要采用合適的數據管理和分析方法才能夠達到對數據的有效利用。
2 數據的復雜性和有效管理面臨的挑戰
當數據不斷的被收集整理之后,隨之而來產生了對大數據管理的軟硬件系統和管理模式的需求,而數據的復雜性為有效解決這個問題提出新的挑戰。圖1是進行公共衛生大數據分析研究的典型框架。公共衛生大數據來源廣泛,其種類和格式也在隨技術進步不斷變化,數據規模均不相同,需要開發相應的存取技術和數據管理方式。傳統數據庫MySQL,新型非關系化數據庫Mongodb,內存數據庫TimesTen等,能夠在一定程度上對數據進行管理,但當數據規模和種類更大時,需要分布式數據庫來實現。目前的技術能夠實現數據的管理,例如支持淘寶的Oceanbase,能夠管理數百T的數據,但需要多臺服務器,成本高昂。對數據管理的瓶頸是數據的異質性,不同類型的數據需要有針對性的過濾、導入、檢索模塊,通過合適的接口,把數據轉換成為標準的形式,對軟件開發提出了很高的要求。
3 生物信息數據庫提供廣泛支持
生物領域有多種實驗數據,已經有完備的數據庫系統進行數據管理,也提供給公眾進行免費訪問和數據檢索,它們能對公共衛生數據的管理和應用提供借鑒。例如,許多生物數據庫提供數據分析功能。利用NCBI的blast(ncbi.nlm.nih.gov/blast/)能夠進行序列比對和檢索,Lynx等數據庫提供富集分析等功能,Reactome提供網絡可視化功能[5],UCSC Xena(http://xena.ucsc.edu/)也提供針對多種臨床數據結合基因數據的分析方法。廣泛的生物數據庫形成了解讀生命活動規律的知識庫,對于公共衛生數據分析提供的重要支撐。同時,生物數據庫也正在走向廣泛集成和存貯、分析并重的方向,其技術手段和分析流程也為公共衛生數據分析提供借鑒。
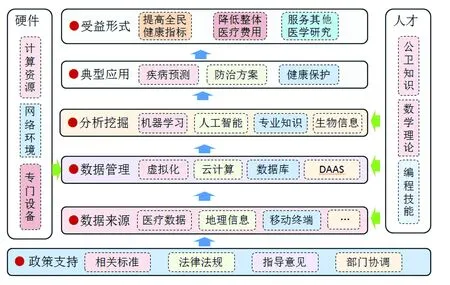
圖1 公共衛生大數據研究框架及其應用Fig.1 Framework of public health big data research and its application
4 數據挖掘方法不斷創新
通過數據挖掘能獲取數據中和公共衛生相關的信息,而分析方法的選擇對于獲取有效結果非常關鍵。傳統的統計學手段將繼續發揮重要作用,而基于機器學習和人工智能的方法,能夠包容多種不同的數據形式,并形成對數據的深度分析。基于神經網絡、HMM模型、動態規劃、貝葉斯推斷、隨機森林的分析方法,也普遍應用于醫療、衛生數據的分析[6-7]。這也對軟件開發、計算資源的使用提出了更高的要求。
網絡是對復雜系統建模的基本工具[8]。公共衛生中的數據可以通過網絡進行表示,利用網絡模塊識別技術,可找出模塊之間的關聯,并發現普遍存在于復雜系統中的高階信息組織和協調方式,非常適合對流行病傳播等公共衛生問題進行描述。
公共衛生數據往往涉及不同來源、不同類型的數據,而異構圖(heterogeneous graph)、貝葉斯網絡(Bayesian network)等可以表示不同信息之間的聯系。通過圖的挖掘、聚類、排序、分割、可視化,可以對不同類型的公共衛生數據進行融合分析,獲取傳統方法難以得到結果[9]。
研究表明,通過大數據分析,發現傳統體檢數據包含同心血管疾病,死亡率相關信息,而智能工具可作為評估總體健康狀況的手段[10];利用谷歌趨勢搜索(trends.google.com),根據各地區感染病例情況建立動態預測模型,可以對zika病毒的傳播進行預測和防范[11]。
在2014年的Ebola疫情控制中,專家利用流行病學數據建立了相關模型,預測了Ebola疫情的嚴重后果[12-13]。同時,人工智能、機器學習被證明非常具有潛力。谷歌的深度網平臺TensorFlow 已在醫學影像識別和疾病判斷方面取得很好的成果,甚至能夠輔助臨床診斷[14],在多個研究中發揮作用。通過設定場景模式,新的公共衛生大數據分析方法將借助人工智能平臺而出現。
5 計算平臺提供支持
公共衛生大數據分析也需要大量的計算資源,可從3個層次進行配置。
1)傳統的以云計算、分布存儲和高性能計算為主體的計算平臺。這種方式通過增加硬件,以及軟件虛擬化的技術,管理大規模計算資源,提供分析和計算服務。目前的大數據處理平臺和工具中,MapReduce提供計算的分解和整合,Hadoop提供可擴展的平臺支持,HDFS技術提供分布式的大數據存儲,Hive提供數據庫的分布式管理和檢索。此種平臺的優點是適用性好、技術成熟、軟件配置靈活。缺點是成本高、能耗高。
2)專門硬件的使用。基于GPU、FPGA的專門硬件,在一個芯片上可以部署上千計算單元或邏輯電路,能夠大大加速計算過程,對于需要進行反復迭代、包含大量簡單操作的計算而言,是最佳的選擇,其優點是性能高、成本低、能耗低,缺點是開發難度大、適用范圍窄,適合對特定問題的解決。目前已經有專門芯片,進行癲癇的及時預測[15]。在生物信息領域,基于FPGA的技術在序列比對方面,也顯示出功耗低、速度快的特點[16]。更多的專門芯片也將會有越來越多的應用于醫療和公共衛生方面。
3)超級計算及下一代計算技術。大規模的并行計算能夠成倍的提高計算速度,實現海量數據存貯,使大規模的數據處理成為可能。中國開發的天河二號由16 000個節點組成,每個節點有2顆Xeon處理器和3個Xeon Phi處理器。持續計算速度每秒3.39億億次雙精度浮點運算。2016年6月,使用中國自主芯片“SW26010”制造的“神威太湖之光”,包含40 960個處理器,浮點運算速度為每秒9.3億億次,取代天河二號登上超算榜首。這些計算能力足以同時處理大量數據。在超算平臺,許多難以求解的問題都可以得到快速處理,通過并行的方式,實現高復雜度問題的求解。
6 網絡技術推動應用的普及
移動互聯網目前已經有很大的覆蓋面,骨干互聯網也已經實現高速的互聯互通,為多種公共衛生大數據的收集提供技術支持。借助物聯網技術,各種便攜式終端、嵌入式設備借助低功耗通訊技術,可以實現地理區域大跨度、長時間的數據采集和獲取。
大數據分析可從兩個維度實現。一是計算機的角度,利用計算能力和人工智能,進行數據分析處理。另一維度以人作為分析主體,進行人機交互,將人所具備的認知能力融入分析過程中[17]。此時,數據的交互可視化尤為重要。基于網絡,可通過瀏覽器收集用戶分析需求,利用后臺服務器實現分析結果,然后通過可視化界面顯示給用戶,實現交互處理和分析,大大提高獲取分析結果的效率。HTML5包含有豐富的網頁對象表示方式,獲得了廣泛的支持,為網絡應用的開發提供了很好的支持。PHP(hypertext preprocessor)超文本處理程序,能實現數據庫處理,響應用戶請求。AJAX(asynchronous JavaScript and XML)能實現網頁和服務器之間的交互操作,并能達到實時響應的效果。借助D3.js,vis.js,CartoDB等工具能夠增強數據的可視化效果,可以形成的顯示方式包括層次數據、空間映射、時變數據、地理信息、空間標量等,凸顯分析結果。R、Python能夠實現多種數據的統計分析,是服務器端分析程序的最佳選擇,這些技術的綜合運行,能形成基于網絡的可視化。
生物信息領域的可借鑒平臺是Galaxy,它實現基于網絡的數據分析過程人機交互,大大方便了數據分析流程[18]。Biomart數據庫平臺本身提供數據分析服務,同時能夠連接多個后臺數據庫,提供隔離的訪問;Ensemble包含基因組信息也提供了互聯網服務器,利用標準SQL語句實現數據訪問。對于公共衛生數據,此類數據管理方法仍舊可行。通過開發公共衛生數據處理模塊和網絡分析接口,用戶可以自行選擇分析模塊,組建分析流程,實現交互式的數據分析,將會極大的推進公共衛生大數據的分析和應用。
7 有效的專業知識發揮重要作用
數據之間的聯系,有些通過專業知識可被推理和演繹,揭示隱含信息,因此,把已知知識融合到數據分析中非常有效,但也具有相當大的挑戰。針對公共衛生領域,宏觀的疾病流行程度、群體健康狀況,針對個體的體檢指標、精神、心理、慢性病數據等,都需要用專業的術語和特定的統計方式進行表示。在生物信息領域,許多知識已經整理和校對,形成基礎知識庫,并利用生物信息的方法進行表示和處理。例如KEGG和Reactome都包含代謝網絡等分子互作信息,利用網絡的形式表示分子之間聯系的生物學知識;Uniprot包含有已知蛋白質的修飾、結構域知識,這些基礎為生命科學研究提供了重要支撐。作為類比,公共衛生領域有藥品分類信息等,ICD10分類系統(http://www.icd10data.com/),MeSH醫學主題詞系統(https://www.nlm.nih.gov/mesh/),但此類知識庫還非常少。當分析結果能夠同專業知識庫結合時,才能達到對公共衛生信息的最佳應用,因此構建公共衛生知識庫將是重要的發展領域。
8 網絡安全和防護不可或缺
2017年5月,勒索病毒WannaCry 利用微軟SMB服務漏洞(MS17-010)開始在全球大范圍傳播,充分說明網絡安全的重要性。云平臺相對于個人計算機,安全性有非常大的提高,但由于操作系統的漏洞不能被全部檢測出來,因此未知漏洞的防范,已知漏洞的修補,以及安全措施的設置都是非常關鍵的。而大數據的4V(大數據量、高速、多樣性、真實性)和1C(復雜性)特征,在公共衛生領域同樣存在,新的措施和方法應該被開發出來消除安全威脅與挑戰。
采用Linux平臺能夠有更好的安全措施,但更重要的是需要對安全有高度的認識。中國《網絡安全法》于2017年6月1日起施行,對網絡運行安全提出了要求,對網絡信息安全提出了規定,對違反法規的各類行為提出了懲治措施,這也從法律上實現了數據安全。
與此同時,在進行科研數據共享之前,需要執行個人信息的去隱私,保證個人及家庭的數據信息安全。其思路是對每個數據集提供唯一標識,并為數據提供者創立數字認證。對于個人數據,需要移除姓名地址等關鍵信息,實現個人隱私安全。只有能夠全面保護個人隱私,才能更好的實現數據的共享和利用。
9 應用前景
公共衛生大數據分析可以服務于多個不同的方向,為公眾衛生水平的提升提供技術指導和數據支持。可預見的應用體現在以下方面。
9.1 大規模流行病預測
通過對大量數據的分析,能夠對疾病流行、發展情況進行評估和預測。研究表明,2015年,全球范圍內11.5%的死亡原因可歸咎于吸煙,而其中52.2%的死亡發生在中國、印度、美國、俄羅斯等4個國家。控煙能產生很好的效果,但也需要全球各個國家的共同努力[19]。心血管疾病中,高血壓是重要的因素,而體質指數升高、體力活動減少都是重要誘因。而飲食結構和生活方式改變、快速城市化和工業化則可能是導致中國心血管病劇增的因素[20]。這些結果為制定相關的應對措施提供重要支撐。
2013出現的H7N9流感病毒包含的氨基酸突變,具有哺乳動物的受體結合能力。通過對病毒傳播的監測,以及對序列進行的進化分析表明,該病毒可能始于家鴨H7病毒,并同H9N2病毒株發生重組,進而發生廣泛的傳播[21]。實際上,病毒傳播之前,會有一些線索在各個層次顯示出來,例如在小范圍內會形成病例增加等現象。應用大數據技術分析活禽交易網絡數據,結合H7N9毒株的血凝素基因核酸序列構建系統進化樹,可推斷禽流感疫情在各省及城市間的傳播情況,具有較高的應用價值[22]。通過進行大尺度傳染疾病的實時監控統計,實現時、空、事件類別的大數據分析好實時監控,能及時提出疫情預報,進而可采取補救措施,分析流行原因,切斷傳播途徑。
9.2 典型疾病的防治
通過公共衛生大數據分析,能夠提前預知特定疾病發生、流行的規律,這樣就能有效識傳播規律,進行有效防治。寨卡病毒被認為是伊蚊傳播,引起新生兒小頭畸形。通過防止蚊子叮咬、去除蚊蟲滋生環境可以進行有效防控。大骨節病是典型的具有地域特點的慢性病,通過對遺傳因素、地理環境、飲食結構、基因表達等多層次的研究,識別疾病誘因,可對該病的防治提供科學有益的指導[23-24]。
9.3 健康影響因素的識別
飲食習慣、生活環境會對群體的健康有很大影響,通過大數據分析,可識別影響疾病健康的主要因素。銀屑病患者具有較高的代謝病發生率,代謝情況改變同該疾病的病因和治療、癥狀密切相關,不良生活習慣,如吸煙、運動減少、 肥胖等會增加伴發代謝綜合征的概率以及銀屑病的病情,導致惡性循環。通過對代謝譜的檢測,發現了同疾病相關的差異血清代謝譜,提示在治療的同時,通過改善飲食結構、生活習慣可減緩疾病的癥狀[25]。通過大數據分析,不僅能識別疾病的相關因素,還能識別改善措施的效果。AD(老年性癡呆)會隨著年齡增長而風險增加。通過對藏族人群AD疾病狀態的統計和分析,發現藏族特有的宗教行為,包括磕長頭、念經、撥念珠等都是AD患病的保護因素。這些活動在增加了精細運動和整體運動的強度,使大腦得到了鍛煉,加強了神經元之間的聯系[26]。每年有56萬人因不吃水果而死于心血管病,其中20萬人在70歲前死亡。研究人員對45萬中國健康人進行了跟蹤隨訪,發現每天都吃水果的人不但血壓和血糖較低,而且得心血管病的人也較少[27]。這些結果使本文有信心對公共衛生大數據進行深入挖掘以識別有效的健康保護因素。
9.4 個人健康保健干預
個人的健康狀況影響因素被識別出來后,就可以采取措施,實現更好的健康管理,減少醫療花費,提高生活水平。大規模數據監測有助于制定合理的措施來保護公共健康。1999年的全國碘營養監測結果發現,兒童尿碘水平為306 μg/L,處于偏高水平。2000年中國將生產環節的碘含量出廠不低于40 mg/kg下調為平均35 mg/kg。這樣既能向人群提供足夠的碘,又把副作用的危險性降至最低水平。缺碘和富碘都會導致甲狀腺疾病,沿海地區和內地的膳食中碘攝入量也不同,隨著經濟社會的不斷發展,讓民眾在知情的前提下進行自由選擇,是防治碘缺乏病的有力手段。
代謝是非常關鍵的生命活動,許多疾病同攝入食品的成分密切相關,糖尿病人不宜多吃甜食是眾所周知的,但其他代謝成分對人體的健康并不為人所知。不同食物的成分和存在的化合物對于慢性病干預和膳食指導也非常關鍵;當涉及到食品安全問題時候,比如人們攝入被污染或者農藥殘留超標的食品,將會導致各種急性和慢性疾病。通過大數據的分析,能夠及時發現和個人健康相關的影響因素,減少環境因素對身體產生的影響,能及時挖掘到營養素與慢性病之間的關系,及早預防慢性病。
10 遇到的問題和挑戰
當前公共衛生大數據的更廣泛應用還面臨很多問題需要解決,主要體現在以下方面。
1)數據收集。數據的碎片化形式和數據的混雜性特征是數據收集的重要困難。例如,在進行疾病研究時,生存時間是評價治療效果的重要指標。然而病人的復查信息或身體狀態信息往往難以被傳遞到相應機構,導致隨訪數據缺失;有些數據需進行提取或格式轉換才能用于公共衛生研究,而這時往往缺失統一標準,也難以采用自動化的處理方式,導致數據獲取效率低下。智能軟件的應用會在數據收集方面提供幫助。
2)隱私保護和數據共享。通常需要合并多個機構的不同數據進行分析,才能獲得有效結果,而不同機構的數據格式和內容往往不一致,個人信息通常也不能夠被全面獲取,同時也難以確定隱私保護的方案。這導致擁有數據的機構難以進行數據分享以及進一步的數據分析。更高程度的信息化有助于這一問題的解決。
3)分析方案的選擇和實現。數據之間有千絲萬縷的聯系,但只有通過合適的分析、統計才能夠揭示這些聯系。采用SIR模型,能夠描述一個小區域內某種流行病感染人數的比例。通過結合疾病傳播模型,流行病在更大范圍的發作情況就能夠得到預測[28];利用全球的手術數據,也可以預測哪些地方對何種外科手術有需求,以便制定政策和措施,以滿足外科手術治療需求[29]。其他學科中數據分析方法的引入和借鑒,是解決不同類型公共衛生大數據分析問題的一個重要途徑。隨著超算和云計算技術的應用,許多占用資源多,耗機時多的方案也能夠不斷被應用于公共衛生領域。
11 前景分析
公共衛生是居民健康的重要基礎和保障。采集到的各種數據資源,連同其他相關數據,形成公共衛生大數據,發揮好這些數據的應用,將產生巨大的社會效益。目前科技的進步正在以全所未有的速度進展,新技術和方法的應用,會不斷形成新的成果,覆蓋多種公共衛生相關疾病的預警、傳播源和傳播途徑的識別。隨著人工智能,機器學習等技術的進步,加上對健康方面知識的積累,以及人們對健康的重視,在提高人們健康水平方面,公共衛生領域大數據的應用將越來越廣泛。
在進行公共衛生大數據應用時,需開發科學合理的模型、進行挖據,通過提出假設發現新問題,并利用數據進行推理,獲取隱藏在數據中的規律,為最終決策提供支持。但在進行此類研究時候,要充分認識到原始數據的異構性、多樣性,數據中干擾因素的存在,以及實現最終應用的復雜性和挑戰性。
開展公共衛生大數據的解讀分析,需要既懂公共衛生又懂數據分析的“雙能”人才。中國人口眾多、地域廣闊、待解決的問題多樣、復雜,急需進行問題的提煉和解決,培養人才隊伍相當關鍵。
可以看到,實現最終目標,還需要多方的努力,包括軟硬件,政策環境等的制定。通過協調解決各個方面的問題,公共衛生大數據分析能夠發揮更大作用,提升人群健康水平。
12 結 語
公共衛生大數據具有廣闊的發展空間,也是解決特定人群健康問題的重要手段之一。采取如下措施,能夠促進該方向全面發展。
1)需要形成能夠包容多種數據的信息管理平臺,提供方便的數據采集和交互。
2)將高性能計算發展成易于廣泛使用的形式,形成計算資源的方便使用。
3)數據分析方法作為核心技術,需要能準確提取異構數據中的關鍵特征。
4)需要培養復合型人才,形成多學科知識的融合。
5)合理、適時的法律法規、政策、標準的制定將對該領域發展有重要影響。以大數據為立足點,多方面的協同將能立體推進公共衛生的健康發展。
References)
[1]賀婷, 劉星, 李瑩, 等.大數據分析在慢病管理中應用研究進展[J]. 中國公共衛生, 2016, 32(7): 981-984. DOI:10.11847/zgggws2016-32-07-28.
HE Ting,LIU Xing,LI Ying,et al. Application of medical big data in non-communicable chronic diseases management[J]. Chinese Journal of Public Health, 2016, 32(7): 981-984.DOI:10.11847/zgggws2016-32-07-28.
[2]KLONOFF D C. Precision medicine for managing diabetes[J]. Journal of Diabetes Science and Technology, 2015, 9(1):3-7. DOI:10.1177/1932296814563643.
[3]史倩楠, 馬家奇. 公共衛生大數據分析方法與應用方向[J]. 中國數字醫學, 2016, 11(2): 10-12. DOI:10.3969/j.issn.1673-7571.2016.02.003.
SHI Qiannan, MA Jiaqi. Big data analytics and application in public health[J].China Digital Medicine, 2016, 11(2):10-12. DOI:10.3969/j.issn.1673-7571.2016.02.003.
[4]GALPERIN M Y, FERNNDEZ-SUREZ X M, RIGDEN D J. The 24th annual Nucleic Acids Research database issue: a look back and upcoming changes[J]. Nucleic Acids Research, 2017, 45(D1): D1-D11. DOI:10.1093/nar/gkw1188.
[5]FABREGAT A, SIDIROPOULOS K, VITERI G, et al. Reactome pathway analysis: a high-performance in-memory approach[J]. BMC Bioinformatics, 2017, 18: 142. DOI:10.1186/s12859-017-1559-2.
[6]DUMANCAS G G, ADRIANTO I, BELLO G, et al.Current developments in machine learning techniques in biological data mining[J]. Bioinformatics and Biology Insights, 2017, 11:1177932216687545. DOI: 10.1177/1177932216687545.
[7]MONTAZERI M, MONTAZERI M, MONTAZERI M, et al.Machine learning models in breast cancer survival prediction[J]. Technol Health Care, 2016, 24(1):31-42. DOI:10.3233/THC-151071.
[8]BENSON A R, GLEICH D F, LESKOVEC J. Higher-order organization of complex networks[J]. Science, 2016, 353(6295):163-166. DOI:10.1126/science.aad9029.
[9]GOGOSHIN G, BOERWINKLE E, RODIN A S. New algorithm and software (bnomics) for inferring and visualizing bayesian networks from heterogeneous big biological and genetic data[J]. Journal of Computational Biology, 2017, 24(4):340-356. DOI:10.1089/cmb.2016.0100.
[10]范婷, 婁巖. 2010-2016年大數據與健康相關SCI論文的聚類分析[J].中國數字醫學, 2017, 12(1): 3-5. DOI:10.3969/j.issn.1673-7571.2017.1.001.
FAN Ting, LOU Yan. Cluster analysis on topics of big data and health from 2010 to 2016[J].China Digital Medicine, 2017,12(1):3-5.DOI:10.3969/j.issn.1673-7571.2017.1.001.
[11]TENG Yue, BI Dehua, XIE Guigang, et al. Dynamic forecasting of zika epidemics using google trends[J]. PLoS One, 2017, 12(1):e0165085.DOI:10.1371/journal.pone.0165085.
[12]任向楠, 丁鋼強, 彭茂祥, 等. 大數據與營養健康研究[J]. 營養學報, 2017, 39(1):5-9. DOI:10.3969/j.issn.0512-7955.2017.01.002.
REN Xiangnan,DING Gangqiang,PENG Maoxiang,et al. Big data in the field of nutrition and health[J]. Acta Nutrimenta Sinica, 2017, 39(1): 5-9. DOI: 10.3969/j.issn.0512-7955.2017.01.002.
[13]FUNG I C H, TSE Z, FU K W. Converting big data into public health[J]. Science, 2015, 347(6222):620. DOI:10.1126/science.347.6222.620-b.
[14]ZHANG Y C, KAGEN A C. Machine learning interface for medical image analysis[J]. Journal of Digital Imaging, 2017, 30(5): 615-621. DOI:10.1007/s10278-016-9910-0.
[15]PAGE A, OATES S P T, MOHSENIN T. An ultra low power feature extraction and classification system for wearable seizure detection[C]//Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Milan, Italy: IEEE, 2015: 7111-7114. DOI:10.1109/EMBC.2015.7320031.
[16]FERNANDEZ E B, VILLARREAL J, LONARDI S, et al. FHAST: FPGA-based acceleration of bowtie in hardware[J]. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2015, 12(5): 973-981. DOI:10.1109/TCBB.2015.2405333.
[17]王藝, 任淑霞.醫療大數據可視化研究綜述[J]. 計算機科學與探索, 2017, 11(5): 681-699. DOI: 10.3778/j.issn.1673-9418.1609014.
WANG Yi, REN Shuxia. Survey on visualization of medical big data[J]. Journal of Frontiers of Computer Science and Technology, 2017,11(5): 681-699. DOI: 10.3778/j.issn.1673-9418.1609014.
[18]AFGAN E, BAKER D, Van Den BEEK M, et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2016 update[J]. Nucleic Acids Research, 2016, 44(W1): W3-W10. DOI:10.1093/nar/gkw343.
[19]COLLABORATORS T. Smoking prevalence and attributable disease burden in 195 countries and territories, 1990-2015: a systematic analysis from the Global Burden of Disease Study 2015[J]. Lancet, 2017, 389(10082): 1885-1906. DOI:10.1016/S0140-6736(17)30819-X.
[20]LI Yanping, WANG Dong, LEY S H, et al. Potential impact of time trend of life-style factors on cardiovascular disease burden in China[J]. Journal of the American College of Cardiology, 2016, 68(8):818-833. DOI:10.1016/j.jacc.2016.06.011.
[21]LAM T T, WANG Jia, SHEN Yongyi, et al. The genesis and source of the H7N9 influenza viruses causing human infections in China[J]. Nature, 2013, 502(7470): 241-244. DOI:10.1038/nature12515.
[22]杜鵬程, 于偉文, 陳禹保, 等. 利用系統進化樹對H7N9大數據預測傳播模型的評估[J]. 中國生物工程雜志, 2014,34(11): 18-23. DOI: 10.13523/j.cb.20141103.
DU Pengcheng, YU Weiwen, CHEN Yubao, et al. Evaluation of the H7N9 transmission model predicted by big data by phylogenetic tree[J]. China Biotechnology, 2014, 34(11):18-23. DOI:10.13523 /j.cb.20141103.
[23]郭雄. 大骨節病病因與發病機制的研究進展及其展望[J]. 西安交通大學學報(醫學版), 2008, 29(5):481-488.
GUO Xiong. Progression and prospect of etiology and pathogenesis of Kashin-Beck disease[J]. Journal of Xi’an Jiaotong University(Medical Sciences), 2008. 29(5):481-488.
[24]WANG Shuang, GUO Xiong, WU Xiaoming, et al. Genome-wide gene expression analysis suggests an important role of suppressed immunity in pathogenesis of Kashin-Beck disease[J]. PLoS One, 2012, 7(1):e28439. DOI:10.1371/journal.pone.0028439.
[25]姜友貴.基于GC-MS尋常型銀屑病患者的代謝組學分析[D]. 西安:西安交通大學, 2017.
JIANG Yougui. Metabonomics analysis of patients with psoriasis vulgaris based on GC-MS[D]. Xi’an:Xi’an Jiaotong University, 2017.
[26]尚穎. 青海省60歲以上藏族阿爾茨海默病患病率及影響因素研究[D]. 廣州: 南方醫科大學, 2015.
SHANG Ying. The risk factors of Alzheimer’s disease among Tibetan aged 60 years and older in Qinghai Province[D]. Guangzhou: Southern Medical University, 2015.
[27]DU Huaidong, LI Liming, BENNETT D, et al. Fresh fruit consumption and major cardiovascular disease in China[J]. New England Journal of Medicine, 2016, 374(14): 1332-1343. DOI:10.1056/NEJMoa1501451.
[28]PAEZ CHAVEZ J, GOTZ T, SIEGMUND S, et al. An SIR-Dengue transmission model with seasonal effects and impulsive control[J]. Mathematical Biosciences, 2017, 289: 29-39. DOI:10.1016/j.mbs.2017.04.005.
[29]ROSE J, WEISER T G, HIDER P, et al. Estimated need for surgery worldwide based on prevalence of diseases: a modelling strategy for the WHO Global Health Estimate[J]. Lancet Glob Health, 2015, 3(S2): S13-S20. DOI:10.1016/S2214-109X(15)70087-2.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
首都公共衛生(2019年5期)2019-02-12 17:32:32
電子制作(2018年18期)2018-11-14 01:48:24
首都公共衛生(2017年1期)2017-11-29 01:21:36
山東工業技術(2016年15期)2016-12-01 05:31:22
中國衛生(2015年3期)2015-11-19 02:53:36
中國衛生(2014年3期)2014-11-12 13:18:10
中國衛生(2014年11期)2014-11-12 13:11:26
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
江蘇年鑒(2014年0期)2014-03-11 17:10:06
