隨機(jī)森林算法在交通狀態(tài)判別中的應(yīng)用
2017-04-25 04:57:50盛子豪
實(shí)驗(yàn)技術(shù)與管理 2017年4期
關(guān)鍵詞:分類
高 林, 劉 英, 盛子豪
(青島科技大學(xué) 自動(dòng)化與電子工程學(xué)院, 山東 青島 266042)
隨機(jī)森林算法在交通狀態(tài)判別中的應(yīng)用
高 林, 劉 英, 盛子豪
(青島科技大學(xué) 自動(dòng)化與電子工程學(xué)院, 山東 青島 266042)
隨機(jī)森林算法隨機(jī)選擇多個(gè)決策樹(shù)構(gòu)成森林,算法分類結(jié)果由這些決策樹(shù)投票得到,在運(yùn)算量沒(méi)有顯著增加的前提下提高了預(yù)測(cè)精度,是一種目前比較流行的組合分類器算法。隨機(jī)森林算法不僅可以用來(lái)做分類,也可用來(lái)做回歸預(yù)測(cè),是機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺(jué)等領(lǐng)域內(nèi)應(yīng)用極為廣泛的一個(gè)算法。該文將隨機(jī)森林分類算法用于交通狀態(tài)判別,利用實(shí)測(cè)數(shù)據(jù)進(jìn)行模型訓(xùn)練和驗(yàn)證,并用袋外數(shù)據(jù)計(jì)算判別正確率,實(shí)驗(yàn)結(jié)果表明該方法具有可行性,為交通狀態(tài)判別提供了一種新思路。
隨機(jī)森林算法; 交通狀態(tài)判別; 袋外數(shù)據(jù)
隨機(jī)森林(random forest,RF)算法是Leo Breiman提出的一種利用多個(gè)樹(shù)學(xué)習(xí)器進(jìn)行分類預(yù)測(cè)和回歸預(yù)測(cè)的組合算法[1]。該算法具有廣泛的應(yīng)用,在生物信息學(xué)、生態(tài)學(xué)、醫(yī)學(xué)、遺傳學(xué)、遙感地理學(xué)、經(jīng)濟(jì)學(xué)等領(lǐng)域都有學(xué)者做了相關(guān)研究[2]。張華偉等[3]將隨機(jī)森林模型應(yīng)用于文本分類,實(shí)驗(yàn)表明分類性能勝于C4.5,與KNN、SMO和SVM效果相當(dāng)。林成德等[4]將隨機(jī)森林算法用于企業(yè)信用評(píng)估指標(biāo)體系的確定,該方法確定的指標(biāo)體系更有效地體現(xiàn)企業(yè)的信用狀況。周博翔等[5]將改進(jìn)的隨機(jī)森林算法應(yīng)用于基于加速度傳感器的人體姿態(tài)識(shí)別,具有較高的分類預(yù)測(cè)正確率和行為識(shí)別率。
但隨機(jī)森林算法在交通領(lǐng)域的應(yīng)用較少。劉擎超等[6]提出了基于隨機(jī)森林算法的交通事件檢測(cè)模型,進(jìn)一步提高了決策樹(shù)模型的交通事件檢測(cè)性能,且避免了噪聲和過(guò)擬合現(xiàn)象,提高了檢測(cè)率,減少了檢測(cè)時(shí)間,提高了分類正確率。傳統(tǒng)的交通狀態(tài)判別算法多基于聚類算法、神經(jīng)網(wǎng)絡(luò)和支持向量機(jī)[7-9]。黃衍等[10]選取了20個(gè)UCI數(shù)據(jù)集,從泛化能力、噪聲魯棒性和不平衡分類主要方面進(jìn)行分析,發(fā)現(xiàn)在多分類問(wèn)題上,隨機(jī)森林算法的泛化能力顯著優(yōu)于支持向量機(jī),二者對(duì)數(shù)據(jù)類別噪聲的魯棒性無(wú)顯著差異,在不平衡分類問(wèn)題上,隨機(jī)森林算法顯著遜色于支持向量機(jī)。本文用隨機(jī)森林算法進(jìn)行交通狀態(tài)判別,為交通狀態(tài)的識(shí)別開(kāi)辟了一種新途徑。
1 隨機(jī)森林算法簡(jiǎn)介
1.1 隨機(jī)森林算法
隨機(jī)森林算法基于決策樹(shù)[11],決策樹(shù)是數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)領(lǐng)域中一種非常重要的分類器,該算法通過(guò)訓(xùn)練數(shù)據(jù)來(lái)構(gòu)建一棵用于分類的樹(shù),從而對(duì)未知數(shù)據(jù)進(jìn)行高效分類。
構(gòu)建決策樹(shù)是個(gè)遞歸過(guò)程,理想情況下所有的記錄都能被精確分類,但現(xiàn)實(shí)條件往往很難滿足,使得決策樹(shù)在構(gòu)建時(shí)可能很難停止。即使構(gòu)建完成,最終節(jié)點(diǎn)數(shù)往往過(guò)多,導(dǎo)致過(guò)度擬合現(xiàn)象。因此在實(shí)際應(yīng)用中需要設(shè)定停止條件,當(dāng)達(dá)到停止條件時(shí),直接停止決策樹(shù)的構(gòu)建,但這不能完全解決過(guò)度擬合問(wèn)題。實(shí)際中常常需要對(duì)構(gòu)建好的決策樹(shù)進(jìn)行剪枝,但它不能解決根本問(wèn)題。隨機(jī)森林算法的出現(xiàn)能夠較好地處理決策樹(shù)的過(guò)擬合問(wèn)題。
隨機(jī)森林算法是一種有監(jiān)督的集成學(xué)習(xí)算法,其基本思想是首先將大量的分類回歸樹(shù)(classification and regression tree,CART)通過(guò)特定規(guī)則組合成一片森林,然后對(duì)測(cè)試樣本進(jìn)行投票表決,最終分類結(jié)果由森林中的所有決策樹(shù)根據(jù)多數(shù)占優(yōu)的原則投票得出。
給定兩個(gè)隨機(jī)向量X、Y和由一系列分類器{h(x,θ1),h(x,θ2),…,h(x,θk),k=1,2,3,…}(其中參數(shù)集{θk}是獨(dú)立同分布的隨機(jī)向量,x是輸入向量)構(gòu)成的森林。邊緣函數(shù)(margin function)的定義如下:
mg(X,Y)=aνkI(hk(x)=y)
-maxj≠yaνkI(hk(x)=j)
(1)
其中I(·)是示性函數(shù),y為正確的分類向量,j為不正確的分類向量,aνk(·)表示取平均。實(shí)際上,邊緣函數(shù)表示的是在正確分類Y之下X的得票數(shù)超過(guò)其他分類的最大得票數(shù)的程度,邊緣函數(shù)的值與分類器置信度呈正相關(guān)。
在隨機(jī)森林算法中,hk(x)=h(x,θk),當(dāng)樹(shù)的數(shù)目很大時(shí),它遵循大數(shù)定律。邊緣函數(shù)可以表示為:
mr(X,Y)=P(hk(x)=y)
-maxj≠yP(hk(x)=j)
(2)
其中,P(hk(x)=y)為判斷正確的分類的概率,maxj≠yP(hk(x)=j) 為判斷錯(cuò)誤的其他分類的概率的最大值。
泛化誤差PE*由下式得到:
PE*=PX,Y(mg(X,Y)<0)
(3)
其中,下標(biāo)X,Y表明了概率的定義空間。
隨著分類樹(shù)數(shù)目的增加,對(duì)于所有的序列θk,PE*幾乎處處收斂到:
Px,y(Pθ(hk(x)=y)=y-
maxj≠yPθ(hk(x)=j)<0)
(4)
因此隨機(jī)森林算法不會(huì)隨著分類樹(shù)的增加而產(chǎn)生過(guò)擬合,但是會(huì)有一個(gè)有限的泛化誤差。
1.2 袋外數(shù)據(jù)(OOB)估計(jì)
用Bootstrap自助采樣方法(有放回)生成隨機(jī)森林訓(xùn)練集時(shí),初始的數(shù)據(jù)樣本有一部分是不能被抽取的,這些樣本的個(gè)數(shù)是初始數(shù)據(jù)集的(1-1/N)N,其中N為初始訓(xùn)練集中樣本的個(gè)數(shù)[12]。已經(jīng)有人證明,當(dāng)N足夠大時(shí),(1-1/N)N會(huì)收斂于1/e≈0.368,即有將近37%的數(shù)據(jù)樣本不會(huì)被抽取,這些不能從初始數(shù)據(jù)集中被抽取出來(lái)的樣本組成的集合稱為袋外數(shù)據(jù)(outofbag,OOB)。使用OOB數(shù)據(jù)估計(jì)隨機(jī)森林算法的性能,稱為OOB估計(jì)。
在隨機(jī)森林生成的過(guò)程中,每一棵決策樹(shù)生成過(guò)程中都會(huì)產(chǎn)生OOB數(shù)據(jù),因此對(duì)于每棵決策樹(shù)都會(huì)得到一個(gè)OOB估計(jì)。將森林中所有決策樹(shù)的OOB誤差估計(jì)取平均,即可得到隨機(jī)森林算法的泛化誤差估計(jì)。因?yàn)镺OB數(shù)據(jù)是在隨機(jī)森林算法生成過(guò)程中產(chǎn)生的,所以在隨機(jī)森林算法中不需要再進(jìn)行交叉驗(yàn)證或者單獨(dú)地測(cè)試集來(lái)獲取測(cè)試集誤差的無(wú)偏估計(jì),因此只用很少的資源就可以評(píng)估算法的泛化誤差。
本文結(jié)合交通狀態(tài)判別的實(shí)際需求,根據(jù)交通流特性[13],利用隨機(jī)森林算法進(jìn)行交通狀態(tài)判別,僅利用OOB數(shù)據(jù)來(lái)計(jì)算判別結(jié)果的正確率。
2 實(shí)例應(yīng)用
本文所用數(shù)據(jù)取自某市智能交通系統(tǒng)管控平臺(tái)數(shù)據(jù)庫(kù),數(shù)據(jù)庫(kù)中原始數(shù)據(jù)的存儲(chǔ)周期為1min,考慮到實(shí)際應(yīng)用情況,交通狀態(tài)判別所用數(shù)據(jù)周期為5min。每條數(shù)據(jù)都包含速度、流量、占有率以及交通狀態(tài),其中交通狀態(tài)是通過(guò)視頻判斷的結(jié)果。對(duì)數(shù)據(jù)庫(kù)中原始數(shù)據(jù)進(jìn)行加權(quán)平均,因?yàn)闀r(shí)間越近對(duì)交通狀態(tài)的影響越大,所以所賦權(quán)重越大。計(jì)算公式如下:
xl=0.5xl,t+0.2xl,t-1+0.15xl,t-2
+0.1xl,t-3+0.005xl,t-4,l=1,2,3
(5)
其中,t為交通狀態(tài)發(fā)布時(shí)刻,xl,t~xl,t-4為交通狀態(tài)發(fā)布時(shí)刻所對(duì)應(yīng)的5個(gè)時(shí)刻的原始數(shù)據(jù),x1、x2、x3分別代表速度、車流量和時(shí)間占有率在t時(shí)刻的值。加權(quán)平均后交通流數(shù)據(jù)格式見(jiàn)表1。
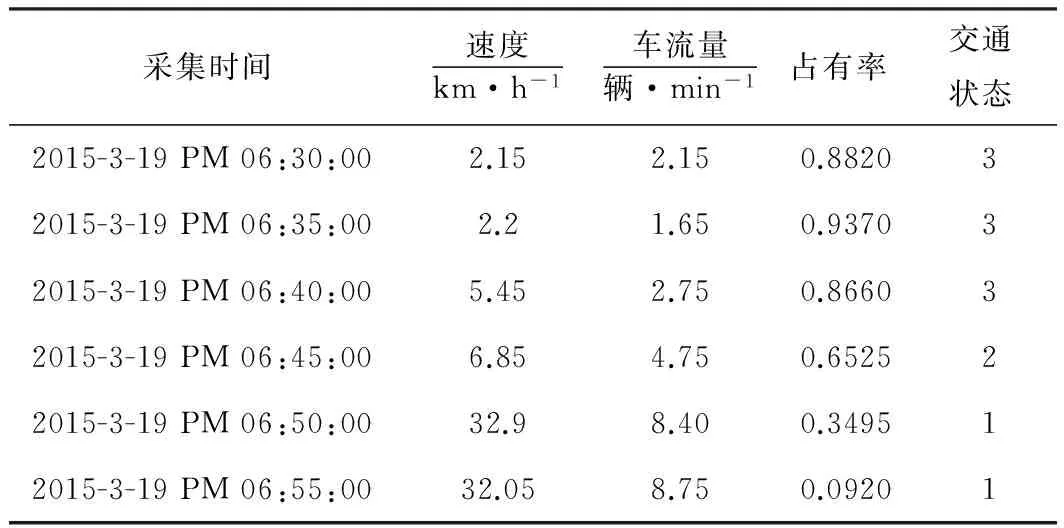
表1 交通流數(shù)據(jù)格式
其中,為記錄及編程方便,用1、2、3分別代表交通的暢通、緩行、擁堵3個(gè)狀態(tài)。一般而言,速度越大,占有率越小,交通狀態(tài)越趨向于暢通。由于進(jìn)行了加權(quán)處理,所以車流量不是整數(shù)而是會(huì)出現(xiàn)小數(shù)。
本文為研究選取不同時(shí)間段數(shù)據(jù)對(duì)交通狀態(tài)判別準(zhǔn)確率的影響,將交通流數(shù)據(jù)分為普通時(shí)間段數(shù)據(jù)(包含晚高峰數(shù)據(jù))與晚高峰數(shù)據(jù)進(jìn)行驗(yàn)證分析,原始數(shù)據(jù)以及交通狀態(tài)分別見(jiàn)圖1和圖2。

圖1 普通時(shí)間段交通狀態(tài)分布圖
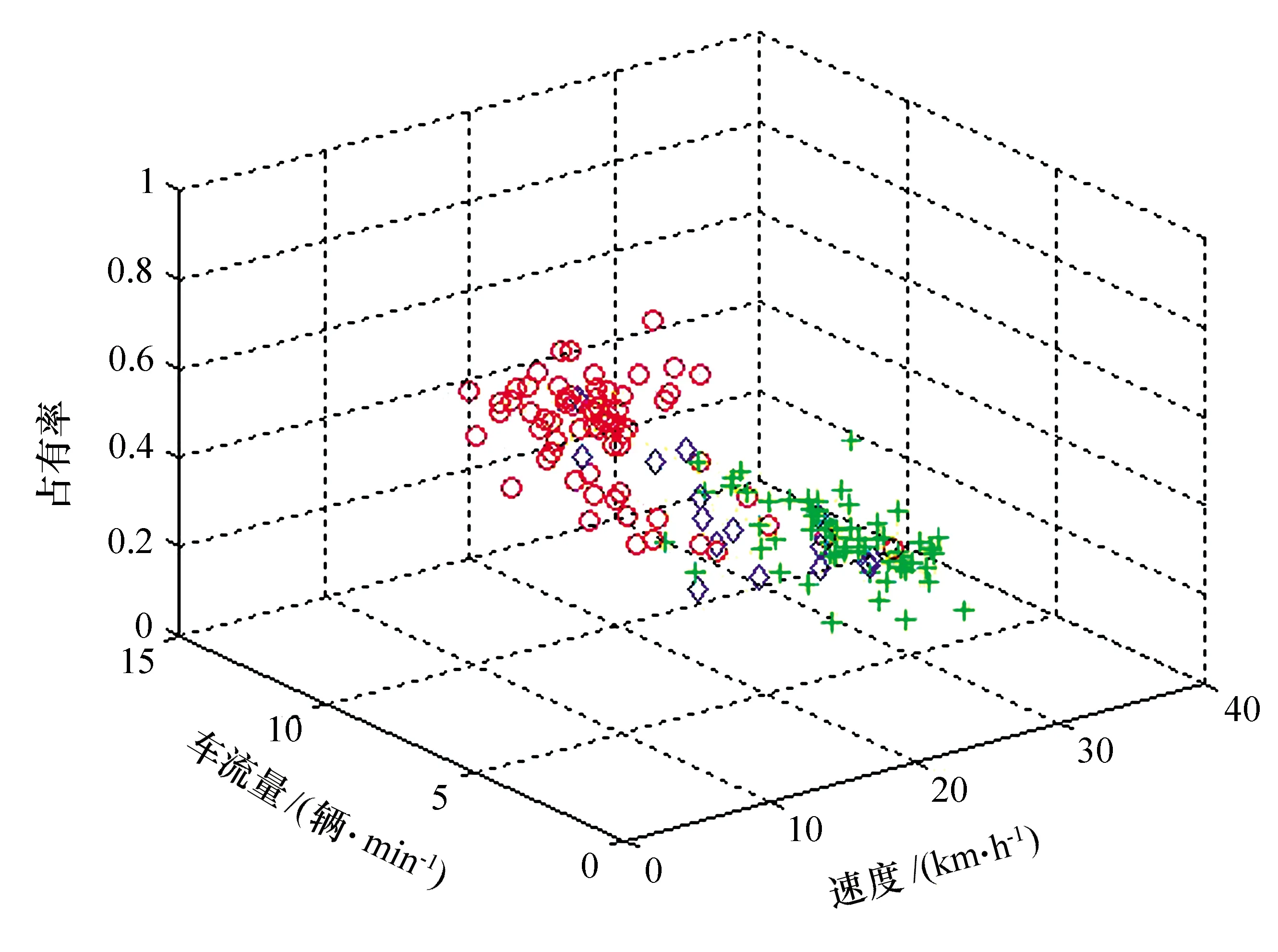
圖2 晚高峰交通狀態(tài)分布圖
圖1共取306個(gè)數(shù)據(jù),圖2取145個(gè)數(shù)據(jù)。圖中不同符號(hào)表示不同的交通流狀態(tài),加號(hào)代表“暢通”狀態(tài),菱形代表“緩行”狀態(tài),圓圈代表“擁堵”狀態(tài)。從圖中可以看出,普通時(shí)間段“暢通”狀態(tài)居多,“緩行”和“擁堵”所占比例很小;而晚高峰數(shù)據(jù)3種狀態(tài)的數(shù)據(jù)比例相差不大。本文將這2個(gè)數(shù)據(jù)集作為原始數(shù)據(jù)集。
隨機(jī)森林算法判別交通狀態(tài)流程見(jiàn)圖3。

圖3 基于隨機(jī)森林算法的交通狀態(tài)判別流程
(1) 原始數(shù)據(jù)集中數(shù)據(jù)個(gè)數(shù)為N,從原始數(shù)據(jù)集中隨機(jī)抽取2/3的數(shù)據(jù)作為訓(xùn)練集,對(duì)訓(xùn)練集進(jìn)行學(xué)習(xí),由此可構(gòu)建N×2/3棵決策樹(shù)分類器模型,剩余的N×1/3未被抽中的數(shù)據(jù)形成OOB數(shù)據(jù),作為測(cè)試集。
(2) 假設(shè)共有M個(gè)特征變量,從M個(gè)特征中隨機(jī)抽取F個(gè)特征,各個(gè)內(nèi)部節(jié)點(diǎn)均是利用這F個(gè)特征變量上最優(yōu)的分裂方式來(lái)分裂,F值在隨機(jī)森林模型生成過(guò)程中固定不變。本文數(shù)據(jù)共有速度、流量、占有率3個(gè)特征變量,因此M=3,F≤3。
(3) 對(duì)測(cè)試集中的每個(gè)數(shù)據(jù),將所有決策樹(shù)分類器模型的判別結(jié)果采用多數(shù)投票法進(jìn)行投票,票數(shù)最多的結(jié)果作為最終交通狀態(tài)判別結(jié)果。
根據(jù)隨機(jī)森林算法,用Matlab進(jìn)行編程實(shí)現(xiàn),利用OOB數(shù)據(jù)計(jì)算交通狀態(tài)判別正確率,結(jié)果如圖4和圖5所示。

圖4 普通時(shí)間段RF算法交通狀態(tài)判別正確率

圖5 晚高峰RF算法交通狀態(tài)判別正確率
圖4所示的普通時(shí)間段的交通狀態(tài)判別正確率平均值為93.16%,圖5所示晚高峰時(shí)的判別正確率平均值為82.38%,說(shuō)明將隨機(jī)森林算法用于交通狀態(tài)判別是可行的。普通時(shí)間段判別正確率明顯高于晚高峰時(shí)的判別正確率,結(jié)合圖1和圖2的交通狀態(tài)分布情況,說(shuō)明對(duì)于交通狀態(tài)判別來(lái)說(shuō),時(shí)間的影響不可忽略。
從圖4和圖5也可以看出,驗(yàn)證次數(shù)取100次,但是每次驗(yàn)證的準(zhǔn)確度都不同,因?yàn)殡S機(jī)森林分類算法執(zhí)行時(shí),每次都會(huì)隨機(jī)選取數(shù)據(jù)樣本構(gòu)成決策樹(shù),數(shù)據(jù)樣本選擇不同,訓(xùn)練學(xué)習(xí)時(shí)產(chǎn)生的模型不同,則學(xué)習(xí)分類效果就會(huì)有所區(qū)別。
3 結(jié)語(yǔ)
將隨機(jī)森林算法用于交通狀態(tài)判別,并且利用OOB數(shù)據(jù)計(jì)算判別正確率。Matlab驗(yàn)證結(jié)果顯示,基于隨機(jī)森林算法的交通狀態(tài)判別正確率可以達(dá)到80%以上,說(shuō)明該算法具有可行性。普通時(shí)間段和晚高峰數(shù)據(jù)的正確率對(duì)比說(shuō)明在進(jìn)行交通狀態(tài)判別時(shí),選取不同時(shí)間段的數(shù)據(jù)對(duì)判別正確率會(huì)有影響,在今后提高交通狀態(tài)判別算法正確率的研究時(shí),可以僅利用晚高峰數(shù)據(jù),這樣更具有實(shí)際意義。
致謝:本文得到了山東省自然科學(xué)基金,青島科技大學(xué)博士啟動(dòng)基金以及“黃彪泰山學(xué)者團(tuán)隊(duì)”資助。
)
[1]BreimanL.Randomforests[J].MachineLearning, 2001,45:5-32.
[2] 方匡南,吳見(jiàn)彬,朱建平,等. 隨機(jī)森林方法研究綜述[J]. 統(tǒng)計(jì)與信息論壇,2011,26(3):32-38.
[3] 張華偉,王明文,甘麗新. 基于隨機(jī)森林的文本分類模型研究[J]. 山東大學(xué)學(xué)報(bào)(理學(xué)版),2006,41(3):5-9.
[4] 林成德,彭國(guó)蘭. 隨機(jī)森林在企業(yè)信用評(píng)估指標(biāo)體系確定中的應(yīng)用[J].廈門大學(xué)學(xué)報(bào)(自然科學(xué)版),2007,46(2):199-203.
[5] 周博翔,李平,李蓮. 改進(jìn)隨機(jī)森林及其在人體姿態(tài)識(shí)別中的應(yīng)用[J].計(jì)算機(jī)工程與應(yīng)用,2015(16):86-92.
[6] Liu Qingchao, Lu Jian, Chen Shuyuan. Design and analysis of traffic incident detection based on random forest[J]. Journal of Southeast University (English Edition), 2014(1):88-95.
[7] 姜桂艷,郭海鋒,吳超騰. 基于感應(yīng)線圈數(shù)據(jù)的城市道路交通狀態(tài)判別方法[J]. 吉林大學(xué)學(xué)報(bào)(工學(xué)版),2008(增刊1):37-42.
[8] 巫威眺,靳文舟,林培群. 基于BP神經(jīng)網(wǎng)絡(luò)的道路交通狀態(tài)判別方法研究[J]. 交通信息與安全,2011,29(4):71-74.
[9] 于榮,王國(guó)祥,鄭繼媛,等. 基于支持向量機(jī)的城市道路交通狀態(tài)模式識(shí)別研究[J].交通運(yùn)輸系統(tǒng)工程與信息,2013,13(1):130-136.
[10] 黃衍,查偉雄. 隨機(jī)森林與支持向量機(jī)分類性能比較[J]. 軟件,2012,33(6):107-110.
[11] 唐華松,姚耀文. 數(shù)據(jù)挖掘中決策樹(shù)算法的探討[J]. 計(jì)算機(jī)應(yīng)用研究,2001,18(8):18-19.
[12] 劉建,吳翊,譚璐. 對(duì)Bootstrap方法的自助抽樣的改進(jìn)[J]. 數(shù)學(xué)理論與應(yīng)用,2006(1):69-72.
[13] 鄭建湖,郭銀歲,葉潤(rùn)真,等. 基于環(huán)形線圈檢測(cè)器信息的交通狀態(tài)模糊識(shí)別方法[J]. 昆明理工大學(xué)學(xué)報(bào)(自然科學(xué)版),2009,34(2):71-75.
《國(guó)際單位制及應(yīng)用》GB 3100—93列出了國(guó)際單位制(SI)的構(gòu)成體系,規(guī)定了可以與國(guó)際單位制并用的單位以及計(jì)量單位的使用規(guī)則。
本標(biāo)準(zhǔn)適用于國(guó)民經(jīng)濟(jì)、科學(xué)技術(shù)、文化教育等一切領(lǐng)域中使用計(jì)量單位的場(chǎng)合。
摘自《國(guó)際單位制及應(yīng)用》GB3100—93
Application of random forest algorithm to traffic state identification
Gao Lin, Liu Ying, Sheng Zihao
(College of Automation and Electronic Engineering, Qingdao University of Science and Technology, Qingdao 266042, China)
The random forest algorithm selects multiple decision trees randomly to constitute a forest, and the algorithm classification results are obtained by voting of these decision trees. The prediction accuracy is improved under the premise of no significant increase in computation, and it is a popular combination classifier algorithm at present. The random forest algorithm can be used for not only classification, but also regression prediction. It is most widely used in the fields of machine learning, computer vision and so on. This paper applies the random forest algorithm to the traffic state identification, and by using the real measured data, the model training and validation are carried out. The discriminant accuracy is calculated with the data out of the bag. The experimental results show that the method is feasible and provides a new idea for traffic state identification.
random forest; traffic state identification; data out of bag
10.16791/j.cnki.sjg.2017.04.012
2016-11-03 修改日期:2016-11-19
山東省自然科學(xué)基金項(xiàng)目(ZR2014FL018); 青島科技大學(xué)博士啟動(dòng)基金項(xiàng)目(010022530)
高林(1976—),男,山東青島,博士,副教授,從事智能交通和數(shù)據(jù)挖掘算法的研究
E-mail:gaolin0619@126.com
劉英(1992—),女,山東濰坊,碩士研究生,研究方向?yàn)閿?shù)據(jù)挖掘和算法.
U491
A
1002-4956(2017)4-0043-04
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫(huà)刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46

- 實(shí)驗(yàn)技術(shù)與管理的其它文章
- 德國(guó)雙元制應(yīng)用技術(shù)大學(xué)對(duì)我國(guó)地方院校轉(zhuǎn)型的啟示
- 加拿大高校工程實(shí)踐能力培養(yǎng)模式及啟示
- 國(guó)家重點(diǎn)實(shí)驗(yàn)室大型儀器設(shè)備平臺(tái)建設(shè)與管理
- 基于WEB的教育技術(shù)專業(yè)實(shí)驗(yàn)室建設(shè)探討
- 關(guān)于特殊教育專業(yè)師范生實(shí)踐教學(xué)基地建設(shè)的思考
- 大學(xué)化學(xué)先修課實(shí)驗(yàn)制作探索與實(shí)踐