云環境下基于分布式計算平臺的交通大數據高效查詢研究
2017-04-06 02:07:57呂家琦
企業文化·下旬刊 2016年12期
呂家琦
摘要:隨著時代的發展與信息技術的廣泛應用。現如今,數據的爆炸式增長已經成為熱點問題。尤其是在交通領域內,研究的深入必然產生海量的數據信息,同時也帶來了數據存儲了數據查詢方面的難題。云平臺的產生和應用為海量數據的存儲和查詢提供了一種新的有效方法。本文以交通大數據為研究對象,主要探討了基于分布式數據庫HBase的大數據查詢策略。本文的研究為交通大數據的高效查詢研究提供了一種新的思路。
關鍵詞:云環境;分布式計算;大數據查詢;HBase
一、綜述
隨著大數據時代的到來,給對應的應用領域帶來了一系列的挑戰。如數據的存儲方式和數據的實時訪問等。大數據的存儲和高效查詢成為了研究熱點。傳統的關系型數據庫難以滿足海量數據的存儲和實時查詢的要求。Hadoop云平臺具有并行性,高可靠性和可擴展性的優勢因而得到研究人員的廣泛關注。HBase作為一種分布式數據庫使海量數據的存儲和高效訪問提供了可能。
二、關鍵技術介紹
(一)Hadoop
在Hadoop平臺上,HDFS作為數據存儲的文件系統,MapReduce負責數據的并行計算。與傳統的關系型數據庫相比,Hadoop具有擴展性更強,數據處理方式更加泛化,處理類型更加廣泛的特點。對于海量數據來說,分布式計算平臺Hadoop是代替傳統的數據倉庫的必然選擇。
(二)HBase
HBase基于分布式平臺的分布式數據庫,與傳統數據庫相比,HBase是基于列存儲,適合于結構化、非結構化數據存儲的數據庫,這一點與大數據具有的特點不謀而合,所以說,HBase適合存儲數據的存儲于處理。HBase將數據按照表、行和列進行存儲。
三、數據遷移與查詢策略的研究
(一)數據遷移
通常,交通行業的相關數據收到業務的影響,目前都存儲與傳統的關系型數據庫,如ORACLE等中。為了對海量的交通數據進行分析研究,就涉及到要將數據從傳統數據庫中導入到分布式數據庫中,也就是所謂的數據遷移。目前可通過相應的工具,如Sqoop或importTsv等完成數據的遷移過程。數據遷移中,首先要在HBase中設計好對應的表結構,因為HBase中,RowKey是表中每條記錄的“主鍵”,能夠實現對某條數據的快速定位,Rowkey的設計非常重要。Colunm Familv代表列族,包含一個或者多個相關列。所以在進行數據遷移前,要完成RowKey和Column Family的設計。
(二)索引的建立
HBase無可置疑擁有其優勢,但其本身只對rowkey支持毫秒級的快速檢索,對于多字段的組合查詢卻無能為力。針對HBase的多條件查詢也有多種方案,基于Sok的HBase多條件查詢原理是將HBase表中涉及條件過濾的字段和rowkey在Sok中建立索引,通過Sok的多條件查詢快速獲得符合過濾條件的rowkey值,拿到這些rowkey之后在HBase中通過指定rowkey進行查詢。
(三)實驗與分析
本集群選擇8臺物理機搭建,硬件配置為4G內存,80G硬盤容量,集群內部通過SSH連通。軟件配置為LinuxCentOS操作系統,Hadoop2.6.0,Hbase2.7.3,hivel.2.1,對應的還有sqoop負責數據遷移,Sok負責索引的建立。實驗數據來自高速公路收費系統中近三個月的綠色通道數據。數據總量約100萬條,500G。
實驗步驟:
1設計HBASE表結構,確定RowKey和ColunmFamily中包含的元組。
2利用Sqoop將數據從ORACLE中遷移到HBASE中。
3利用Sok為所要查詢的數據屬性建立相應索引。
4按照數據量由小到大的順序,分四次進行查詢效率對比實驗。
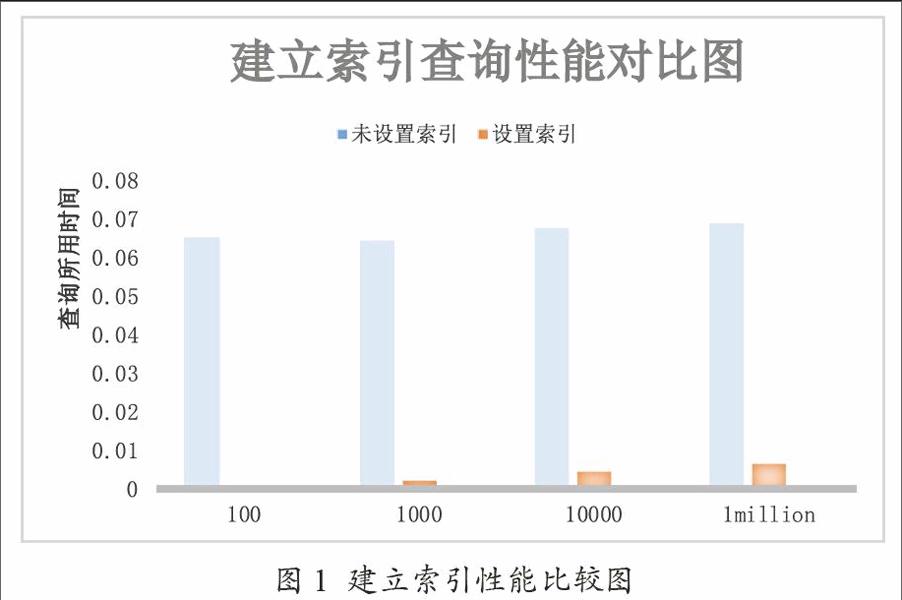
圖1展示了未建立索引和建立索引的數據查詢時間對比。
通過上圖的展示表明,若未對存儲的HBase中的數據設計索引,則進行數據查詢時,查詢的時間與數據量大小無關,耗時在5000秒左右。當利用Sok對存儲在HBase中的數據設計索引后,能夠大幅度的降低數據的查詢時間。當數據量在100萬條時,花費的查詢時間耗時為8分鐘左右。通過對比可以看出,建立索引能夠減少數據查詢時間,提高查詢效率,滿足對交通大數據實時查詢的要求。
四、總結
本文是云平臺Hadoop框架上,基于分布式數據庫Hbase的海量數據的存儲和查詢。主要從數據遷移,索引的建立和通過相關的實驗對比來展示云環境下,分布式數據庫對海量數據存儲和查詢的優勢。本文根據實際研究內容,對高速公路特色車輛進行查詢,通過對實驗展示了建立索引對非主鍵數據的查詢效率的提升。放眼大數據行業,在未來的研究中,針對Hadoop和HBase的優化研究將會繼續進行,這樣才能進一步提高數據的查詢效率,使云技術更好的服務于大數據行業。
