基于CiteSpace的醫學大數據國際發展研究現狀分析
2017-03-22 03:59:58,
中華醫學圖書情報雜志 2017年7期
,
互聯網、物聯網、移動互聯網等相關技術的發展與應用,使全球范圍內的數據容量正以前所未有的速度增長。2011年5月,EMC公司在美國拉斯維加斯舉辦以“云計算相遇大數據”為主題的第11屆EMC世界年度大會,大會正式提出了“大數據”(Big Data)的概念[1]。
大數據科學作為“第四范式”開始出現,將數據丟進巨大的計算機機群中,只要有相互關系的數據,統計分析算法可以發現過去的科學方法發現不了的新模式、新知識甚至新規律[2]。在醫學領域,隨著現代檢測、存儲技術、傳感技術、醫院信息系統和電子病歷的發展,采集到的數據的復雜度和數據容量都在不斷增大[3-4]。
醫學大數據具備了典型5V特點,即數據量大(Volume)、數據種類多(Variety)、產生快、處理快(Velocity)、真實性 (Veracity) 和密度低(Value)。對這些數據進行挖掘分析可以提升醫院和健康服務機構的診療和服務水平,促進健康產業發展。
醫學大數據現有研究集中在工程應用部分,體現在數據采集、存儲和醫患互動方面。在理論研究方面,大多數工作現僅停留在評述醫學大數據如何大或是如何有用,從計量學角度并結合CiteSpace軟件對當前醫學大數據領域進行分析的文章較少。本文通過對醫學大數據領域相關文獻進行可視化展示,分析醫學大數據的研究熱點、前沿、關鍵文獻等,梳理其演化路徑,可以預測該領域的研究趨勢,給該領域的研究者一個全面、直觀的參考。
1 數據來源與方法
1.1 數據來源
數據取自Web of Science(WOS)。檢索式為:主題:("medicine& big data") OR主題:("medical & big data"),數據庫選擇SCI-EXPANDED,文獻類型不限定,共檢索到1 570篇相關文獻,去重后得到1 520篇文獻。為了解近10年醫學大數據的研究熱點、前沿,本文限定文獻年限為2008-2017年,檢索時間為2017年4月30日,雖然2017年的數據并不完整,但已有的部分文獻對于最新研究主題的獲取具有重要作用。各種類型的文獻對本文研究國際醫學大數據現狀具有重要作用,故本文對文獻類型不作限定。
1.2 研究方法
CiteSpace軟件是一款用于計量和分析科學文獻數據的信息可視化軟件,具有多元、分時、動態的特點,它利用分時動態的可視化圖譜展示科學知識的宏觀結構以及發展脈絡,直觀地展示某一領域的信息全部內容,識別并顯示某一領域科學發展的新趨勢和新動態,展現研究熱點及前沿方向[5]。CiteSpace根據“年輪”大小和顏色的區別展示分析內容,一個“年輪”代表一個節點。“年輪”環內的顏色代表關鍵詞的出現時間;年輪的厚度與關鍵詞出現的頻次成正比;節點間的連線代表節點與節點間的共現關系;連線越粗,則表明節點間關系越緊密[6]。
將1 520篇文獻導入CiteSpace,繪制所需的可視化圖。參數設置如下:時區選擇為 2007-2017年,時間跨度選擇 1年,閾值選擇為g-index,節點類型選擇“關鍵詞(Keyword)”“文獻共引(Cited Reference)”。
共詞分析是計量學中常用的內容分析方法之一,基于兩個(多個)關鍵詞同時出現這一原理。共詞分析法能將研究主題內容相近的資源聚合到一起,因此,通過對關鍵詞共現強弱的考察,可以有效揭示它們所代表主題內容在學科研究中熱度的高低。關鍵詞共現分析法是對當前發表文獻的直接統計,所尋找的是當前論文所集中關注的主題,反映的是在趨勢形成之后的焦點、熱點[7]。
2 結果
2.1 研究文獻的時間分布
對1 520篇檢索結果進行統計分析,結果顯示,2012年伊始,國際醫學大數據的研究成果數量迅速攀升,2016年發文更是2012年的6.42倍。2012年聯合國發布《大數據促進發展:挑戰與機遇》白皮書,此后,美、英、加、澳、日、韓、中等眾多國家相繼發布一系列大數據技術研究和發展計劃,大力推進大數據研究和應用,這可能是造成2012年以后相關研究成果攀升的重要原因。
1 520篇文獻共來自91個國家1 835個機構的5 901位作者,這些文獻分布于以計算機學科為主的107個學科當中,發表于679種期刊或會議論文集中。美國排在首位,發文量為522篇(占總發文量的34.34%);中國(占14.8%)、德國(7.89%)和英國(7.76%)依次緊隨其后。
經統計分析發現,發文量前10的機構美國占了9所,這9所機構中,排在前4位的依次分別是哈佛大學、斯坦福大學、華盛頓大學、加州大學,各機構發文量均超過18篇,這4所大學成為美國醫學大數據研究的主力機構。中國科學院以17篇的發文量位列第五,是中國醫學大數據研究的主力機構之一。
2.2 醫學大數據領域研究熱點
應用CiteSpace進行可視化研究,其中節點146個,連線1 406條,得到國際醫學大數據領域關鍵詞共現圖(圖1)。結合圖1對出現頻次在20次以上的關鍵詞進行分析,可以得出醫學大數據領域主要的5個研究熱點。
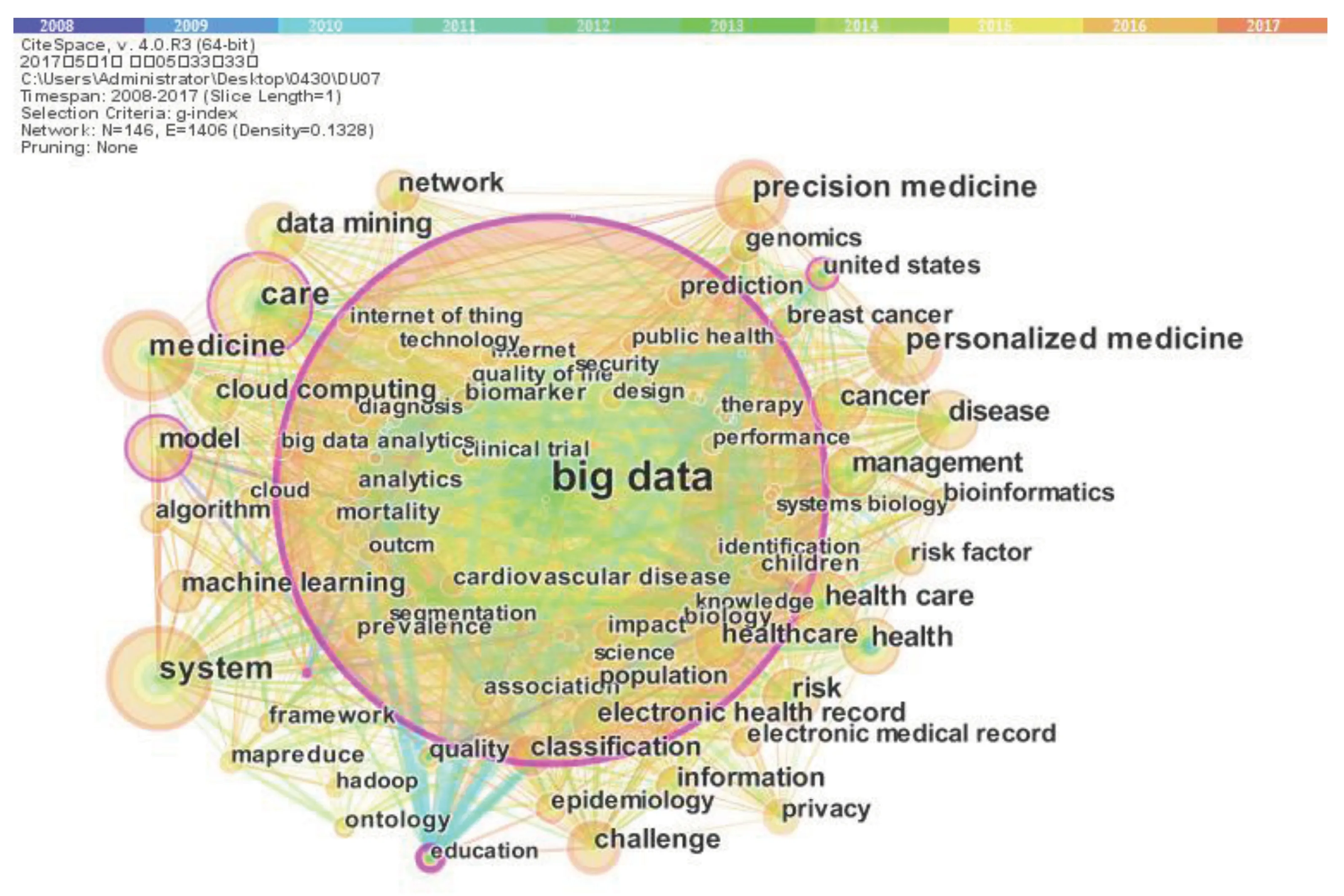
圖1 國際醫學大數據領域的共現關鍵詞
2.2.1 醫學大數據技術研究
醫學大數據的發展離不開大數據技術的支持,大量結構化和非結構化的醫學大數據需要相關大數據技術來處理分析,當前醫學大數據領域在探討醫學大數據系統、大數據挖掘、模型、云計算、機器學習、算法與框架等大數據技術上較多,如圖2所示的重要共現關系包括big data-system、big data-data mining、big data-model、big data-cloud computing、big data-network、big data-classification、big data-machine learning、big data-algorithm、big data-framework、big data-prediction、big data-analytics。在此方向,O'Driscoll等概述了云計算和大數據技術,并探討如何使用這些專業知識來處理生物學的大數據集,以Apache Hadoop為例討論分布式和并行化的大數據技術處理和分析PB級數據集,以及Hadoop在生物信息學當前使用的概述[8],具有60次的高被引頻次。
2.2.2 精準醫療
個體化醫療的說法由來已久,自2015年奧巴馬提出“精準醫學”計劃[9],更是把個體化醫療推向一個世界關注的地位。自從在本世紀之交人類基因組計劃完成以來,基因組序列數據出現前所未有的擴大,為精準醫療的實現奠定了基礎。此外,基礎研究的進步包括分子生物學、基因組學和生物信息學的進步,以及社交媒體和移動設備的應用均推動著精準治療的發展。對疾病的研究中,腫瘤精準治療最為突出,其中又以乳腺癌的研究最多。如圖1所示的重要共現關系包括big data-personalized medicine、big data-precision medicine、big data-disease、big data-cancer、big data-breast cancer、big data-genomics、big data-bioinformatics、big data-analytics。
2.2.3 醫學健康大數據管理
電子健康記錄的普及,存儲了大量病歷、診斷、篩查、檢測等臨床數據,為醫學健康大數據管理奠定了基礎,對其整合再利用對于身體狀況監測,疾病預防和健康趨勢分析都具有積極的意義。如圖2所示的重要共現關系包括big data-care、big data-health care、big data-health、big data-management、big data-electronic health record、big data-healthcare、big data-electronic medical record。對于electronic health record、electronic medical record的探討,Bates[10]等探討《衛生保健中使用大數據分析技術識別和管理高風險和高成本的患者以降低美國保健成本》一文,具有74次的高被引頻次。此外,Skripcak[11]等重點討論了放療和腫瘤學領域國際研究數據交換戰略發展的一個思想概念框架。
2.2.4 醫學大數據的隱私問題
醫學大數據與其他行業大數據的區別之一是醫學大數據的隱私性:在對醫療數據的數據挖掘中,不可避免地會涉及到患者的隱私信息,這些隱私信息的泄露會對患者的生活造成不良的影響。此外,HIPAA(健康保險攜帶和責任法案)未涵蓋的大量醫學數據由患者自己產生,包括信用卡數據、互聯網檢索數據、電子郵件數據、社交媒體數據和移動健康等數據,這些數據由第三方數據經紀人和互聯網公司控制,公司將這些數據與消費者的日常活動、交易、運動和人口結構等個人信息相結合,再將結合的數據用于個人健康狀況的預測分析,但同時也會出售給廣告商等[12],造成了隱私安全隱患。因此,對醫學大數據隱私的探討也成為醫學大數據領域研究的熱點之一,如圖2所示的重要共現關系包括big data-privacy、big data-riskfactor。
2.2.5 醫學大數據發展的挑戰
醫學大數據處于初級階段,在發展過程中還面臨著不同程度的挑戰,如數據的異質性、不同格式類型和不完備的EHR和基因組數據庫、如何生成具有成本效益的高通量數據、數據存儲和處理、數據整合與解讀、隱私、基礎設施、監管環境、混合教育和多學科團隊、個人和全球經濟的關系等[13-15]。如圖1所示的重要共現關系包括big data-challenge、big data-risk。此方向上,Costa Fabricio[16]的“Big data in biomedicine”一文被引次數最高(為753次),探討了在轉化醫學、生物醫學領域應用大數據面臨的挑戰,以及個性化醫療將組學和臨床健康數據相結合的重大突破。
2.3 醫學大數據領域研究前沿
利用CiteSpace提供的詞頻探測技術在關鍵詞共現網絡知識圖譜的基礎上進行突現值(Burst term)分析,通過考察詞頻的時間分布,將其中頻次變化率高的詞(Burst term)從大量的主題詞中探測出來,依靠詞頻的變動趨勢反映領域前沿和發展趨勢。本文共探測得出24個高Burst值(表1)。
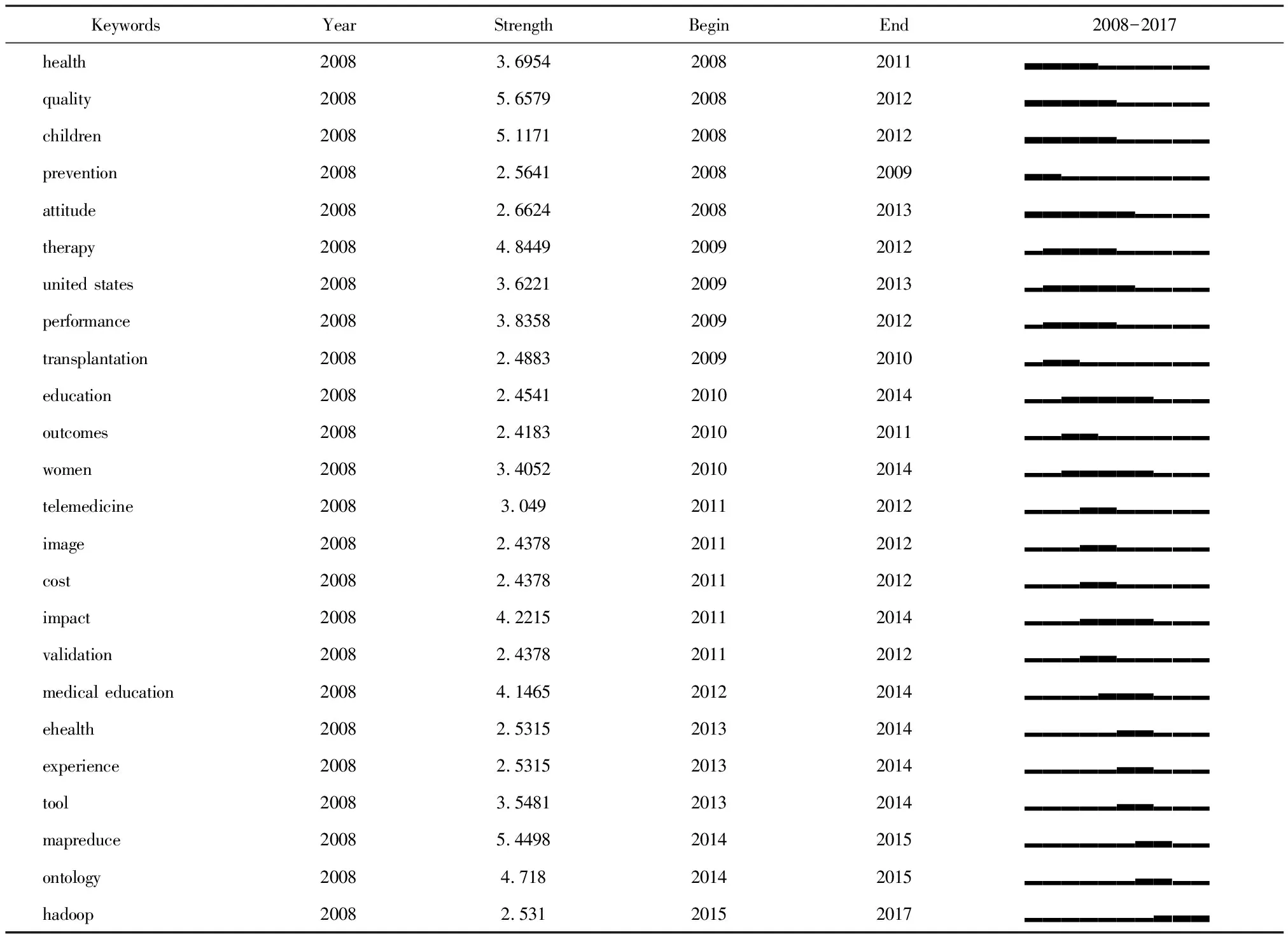
表1 高頻Burst關鍵詞
由表1可知,2008-2012年間,國際上對quality、children探討突增,Burst值較高,均在5以上。medical education、telemedicine、education、health、image等詞在2009-2014年間探討較多。
近兩年間,對mapreduce、ontology、hadoop等討論突增,mapreduce更是具有高達5.5的Burst值,說明對醫學大數據處理技術及本體的研究是當前醫學大數據領域的研究前沿與趨勢。其中,Hadoop是一個平臺,MapReduce是一個并行處理框架,基于其的大數據處理方法是目前醫學大數據的主流。對mapreduce、hadoop的探討中,Schatz[17]介紹《基于MapReduce的CloudBurst并行算法用于分析人體基因組數據的良好性能》一文,被引次數最高(為60次)。對 ontology的研究中,Gai[18]提出在大數據中使用本體的模式來生成警報機制以幫助醫生進行醫學診斷一文,被引次數最高,為16次。
2.4 奠基性文獻分析
節點類型選擇Cited Reference,運行軟件后共得到節點141個,連線651條,進行調整后得到文獻共被引時區知識圖譜(圖2),該圖譜側重于從時間維度上表示知識演進,可以清晰地展示出文獻的更新和互相影響情況,它將結點定位在一個二維坐標系中,根據結點首次被引用的時間,結點被放在不同的時區中。對知識演進進行直觀展示[7]。
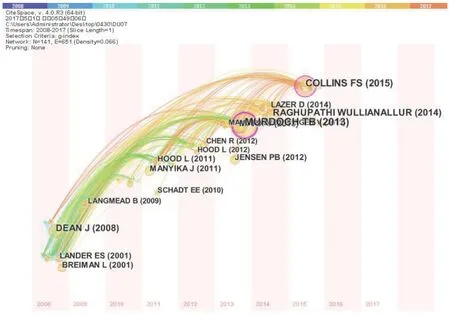
圖2 文獻共被引時區知識圖譜
一篇文獻如果記錄了所在研究領域某個重要的、基礎的研究成果,對后續研究起到非常重要的奠基作用,該領域其他研究學者對該文獻的認可程度高,那么被引用頻次就高,可被認為是該領域的奠基性文獻[19]。根據CiteSpace的被引網絡圖,可以得出被引最高的9篇文獻,視為醫學大數據領域的奠基文獻。從圖3可以看出,這些奠基性文獻依然影響著當今醫學大數據的研究。具體內容如下。
2001年Surhone等[20]等探討了Random forests(隨機森林樹)預測模型。2008年1月,Google 公司Dean等[21]以谷歌大數據處理為例介紹了MapReduce編程模型在處理各種大數據任務的可用性及數據處理模式,即程序員通過指定 Map 函數和Reduce 函數,底層系統會自動實現大規模集群的并行計算,并自動處理機器故障和調度機間的通信,有效地利用網絡和磁盤資源。
2013年,Murdoch等[22]利用經濟框架來強調大數據提供的機會和實施過程中的障礙,探討了醫學領域應用大數據的必然性,對收集到的醫患數據進行分析可以提高醫療保健服務的質量和效率。
對電子病歷(EHRs)的挖掘有可能建立新的患者分層原則和揭示未知疾病的相關性,將EHR數據與遺傳數據整合也將更好地了解基因型-表型關系。2012年,Jensen等[23]探討使用EHRs數據推動醫學研究和臨床治療的潛力,以及在此之前必須克服的挑戰。
2011年,Hood等[24]表明分析醫學將從傳統的反應性醫學向主動性醫學邁進,即走向集預測性、個性化、預防性和參與性于一體的P4醫學。Collins(2015)等[9]指出奧巴馬宣布的“精準醫學計劃”短期目標是為癌癥找到更多更好的治療手段,長期目標則是為實現多種疾病的個性化治療提供有價值的信息。精準醫學并不是一個新的概念,它是在個體化醫療的基礎上,伴隨大量生物數據庫(例如人類基因組序列)、特征化患者的方法(如蛋白質組學、代謝組學、基因組學、多種檢測技術甚至移動健康技術)以及大數據分析工具的涌現而發展起來的。
2009年,Google谷歌流感趨勢(GFT)對用戶搜索數據進行挖掘,比美國疾病控制與預防中心(CDC)提前1-2周預測到了甲型H1N1流感爆發。此事件震驚了醫學界和計算機領域的科學家,Google的研究報告發表在Nature雜志上。2013年1月,美國流感發生率達到峰值,而GFT的估計值比實際數據高兩倍,再次引起了媒體的關注。2014年,Lazer[25]等就這一事件進行了分析,探討了導致GFT失誤的兩個因素:大數據的浮夸和算法演化,提供了大數據發展路上的經驗和教訓。GFT作為醫學大數據的重要實例之一,表明醫學大數據正處在初級階段,現階段困難與挑戰并存,而未來的潛力無比巨大。
3 結論
本文對WoS數據進行醫學大數據研究領域的可視化分析結果表明,醫學大數據仍屬于初級階段,相關文獻較少,但并不是純概念性的理論研究,而是和醫療衛生服務緊密結合進行的實踐探索。
醫學大數據研究從2012年開始迅速攀升,到目前已引起越來越多的學者的關注,90余個國家的1 800多個機構的近6 000位作者從事相關領域研究。從發表論文數量和被引頻次來看,美國在醫學大數據研究上占領先地位,其相關機構較多,中國發文量排名第二,但在發文數量上離美國還有較大差距,中國科學院是我國醫學大數據研究主力機構。
醫學大數據技術、精準醫療、醫學健康大數據管理、醫學大數據的隱私及挑戰是當前的研究熱點。醫學本體、mapreduce、hadoop等是當前醫學大數據領域研究前沿與發展趨勢。
