基于排列熵的城市化區域地下水系統復雜性測度
2017-03-21 02:02:41張永嘉
節水灌溉 2017年6期
張永嘉,劉 東,2,3,4
(1.東北農業大學水利與土木工程學院,哈爾濱 150030;2.農業部農業水資源提高利用重點實驗室,哈爾濱 150030;3.黑龍江省糧食產能提升協同創新中心,哈爾濱 150030;4.黑龍江省普通高校節水農業重點實驗室,哈爾濱 150030)
0 引 言
城市地下水水文系統復雜性作為一個較新的研究方向被人們廣為關注,它直接影響著區域農業生產、旱澇災害等相關的生產活動。在全球氣候變化的今天,地下水水文系統復雜性日益顯著,研究地下水水文系統的復雜性可為水資源系統的預測以及后期對水資源的優化配置奠定基礎,通過預測對區域的水資源進行分配,更有效、合理、可持續的利用水資源。
在研究復雜性科學中熵理論最為常用,近似熵[1]、多尺度熵[2]、風險熵[3]、小波熵[4]、信息熵[5]、樣本熵(Sample Entropy)[6]、最大熵原理[7]等都是熵理論算法。其中排列熵(PE)計算簡便、抗噪聲能力強[8]。近些年國內外研究以及取得的研究成果主要有:顏云華和吳志丹結合多元經驗模態分解和PE進行高速列車故障工況檢測[9];從華等運用基于PE的連續隱馬爾可夫模型診斷4種狀態齒輪故障[10];Hamed Azami等運用改進后的PE算法分析多時間尺度下腦電圖中眨眼時顱內猝發反應的變化[11];Sesham Srinu等人運用振幅感知PE來增強、合成信號,并對腦神經數據進行處理[12]。PE雖然在相應領域中都取得一定成果,但在水文水資源領域運用較少。
本文采用PE對哈爾濱逐日地下水埋深序列復雜性進行測度,在結果準確的基礎上,選取更可靠、直觀的熵理論方法分析區域地下水水文系統的復雜性,并探究當地下墊面條件與地下水水文系統復雜性的相關關系,揭示影響城市區域地下水水文系統的關鍵因素。
1 研究區域與方法
1.1 研究區域
哈爾濱是黑龍江省省會,地處東經125°42′~130°10′、北緯44°04′~46°40′是中國東北北部的政治、經濟、文化中心。全市總面積約為53 840 km2,轄9個市轄區、7個縣,代管2個縣級市,其中市轄區面積10 198 km2。2014年戶籍總人口994萬人。哈爾濱的氣候屬中溫帶大陸性季風氣候,冬長夏短,全年平均降水量569.1 mm,降水主要集中在6-9月,夏季占全年降水量的60%[13]。在下墊面條件(例如地形、地貌等)的影響下,該地區地下水分布不均,復雜性特征明顯,因此揭示區域地下水埋深序列復雜特征,為區域地下水水資源預測和合理性分配奠定基礎。
1.2 資料來源
從黑龍江省氣象局收集到哈爾濱水文局下屬的10個區域從2008年到2013年的逐日的地下水埋深監測資料(n=2192)。哈爾濱各區域監測地點地下水埋深均表現出周期性變化,但各個區域地下水埋深變化幅度中含有隨機、非線性等復雜性特征,使得各區域地下水埋深變化各不相同,其中市區、五常、依蘭、尚志和延壽有遞減趨勢,而其余區域都呈現遞增趨勢。
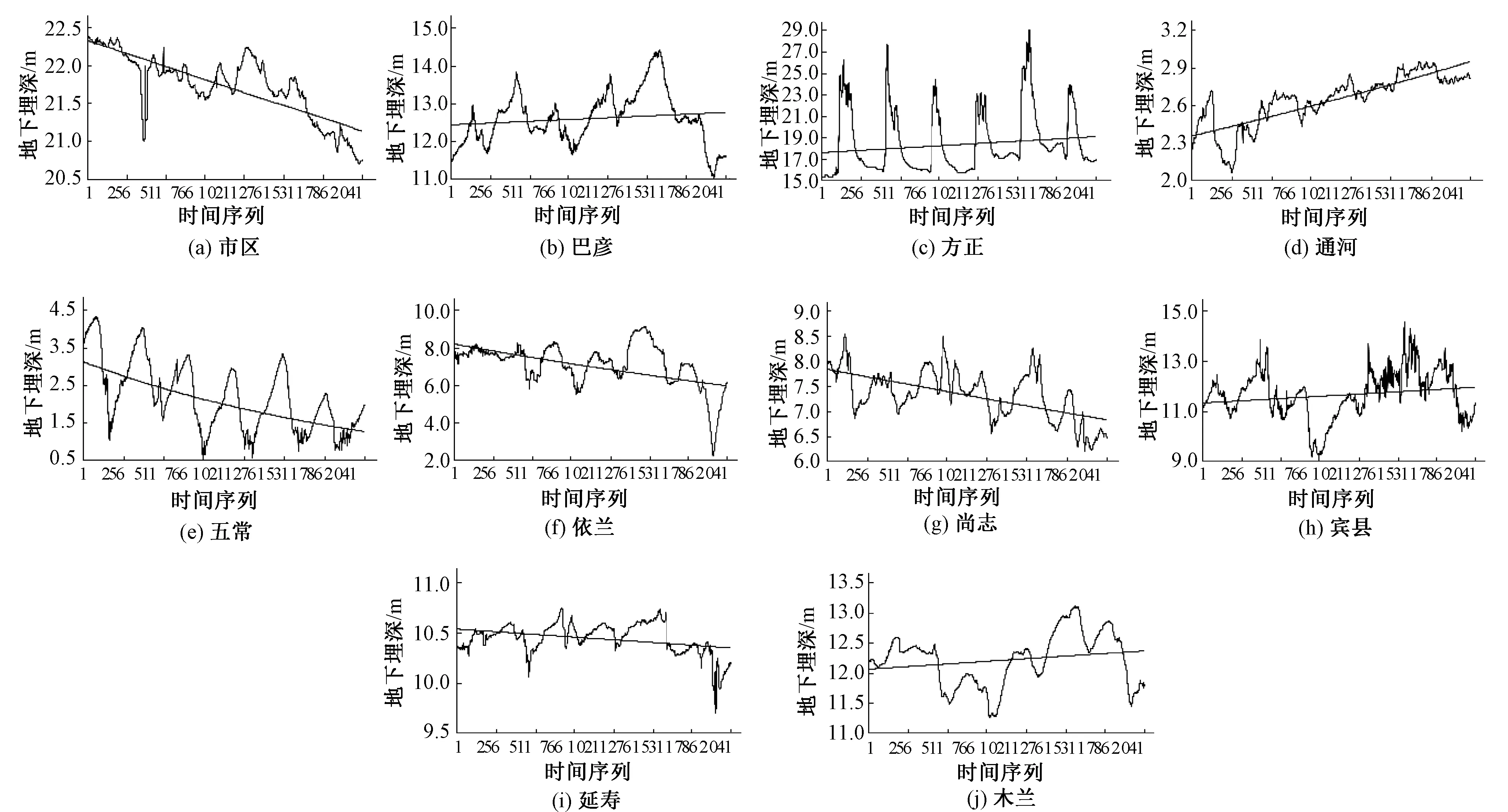
圖1 哈爾濱市各區域逐日地下水埋深序列變化曲線(2008-2013)Fig.1 Variation curves of daily groundwater depth series of each county in Harbin (2008-2013)
1.3 研究方法--排列熵
Christoph Bandt[14]等人提出了一種衡量一維時間序列復雜度的算法PE (Permutation Entropy) ,具有計算簡單、抗噪聲干擾能力強等特點。
PE具體算法如下[18]:
(1)設時間序列Xi,i=1,2,…,n,進行相空間重構,得到矩陣Xk;
(1)
式中:m,τ分別為嵌入位數和延遲時間;K=n-(m-1)τ。
(2) 將Xi重構矩陣中的第j個重構分量[xj,xj+τ,…,xj+(m-1) τ],按照升序重新排列,j1,j2,…,jm,即:
xi+[j(1)-1] τ≤xi+[j(2)-1] τ≤ … ≤xi+[j(m)-1] τ
(2)
(3) 時間序列Xi排列方式共m!種排列,計算每一種符號序列出現的概率為P1,P2,…,Pm,則PE為:
PEp(m)=-∑mj=1pjlnPj
(3)
PEp(m)表示了時間序列Xi的隨機程度,PE值越大,時間序列復雜性越大,PE值越小,時間序列復雜性越小。
2 結果與分析
采用上述方法,其中嵌入位數m取4,延遲時間τ取2,利用Matlab R2010b軟件編程,計算哈爾濱各區域逐日的地下水埋深序列PE值,結果見表1。
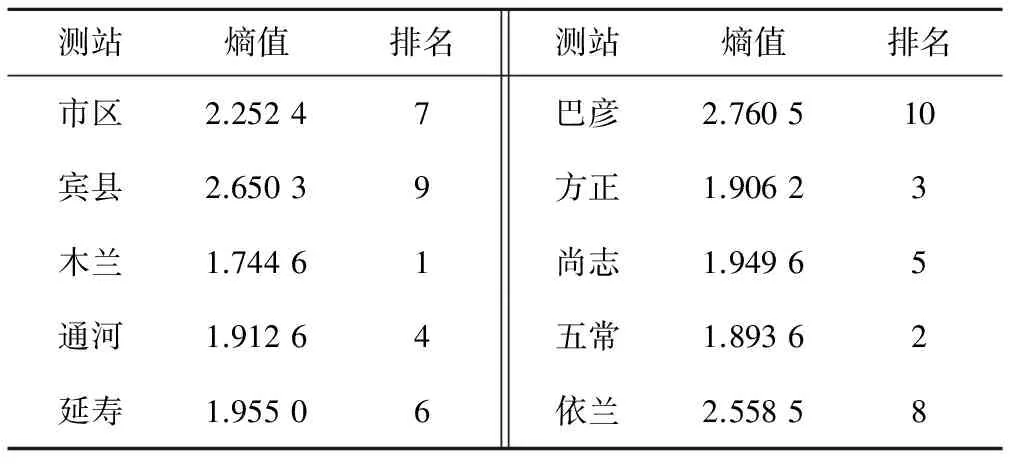
表1 基于PE的哈爾濱市各區域逐日地下水埋深序列熵值及排序Tab.1 The values of entropy of daily groundwater depth series of each county in Harbin based on PE and the orders
若測站地下水埋深序列PE值越大,則復雜性越強,地下水埋深序列的可預測性降低。由表1可知,哈爾濱各測站地下水埋深序列可預測性從高到低為:木蘭>五常>方正>通河>尚志>延壽>市區>依蘭>賓縣>巴彥,并根據PE值將復雜性分為3級,熵值在2.900~2.400之間為Ⅰ級,在2.400~1.900之間為Ⅱ級,在1.900~1.400之間為Ⅲ級,見表2,并繪制其地下水埋深序列復雜性空間分布圖,見圖2。
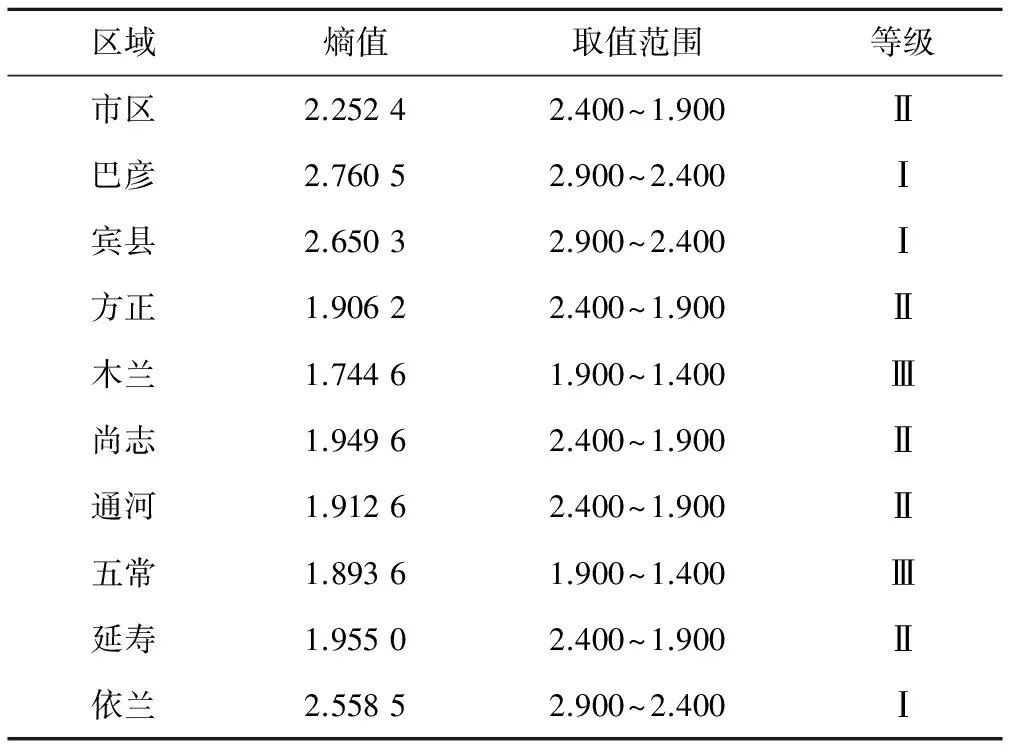
表2 各區域逐日地下水埋深序列復雜性分級Tab.2 Complexity grade of daily groundwaterdepth series in each county
由圖2可知,巴彥、賓縣、依蘭3個區域地下水埋深序列復雜性為Ⅰ級,等級最高,說明這3個區域的地下水資源預測難度大,影響因子較多;市區、方正、尚志、通河、延壽5個區域地下水埋深序列復雜性為Ⅱ級,等級居中,說明這5個區域的地下水資源預測難度一般,影響因子數量一般;木蘭、五常2個區域地下水埋深序列復雜性為Ⅲ級,等級最低,說明這兩個區域的地下水資源預測容易,影響因子較少。
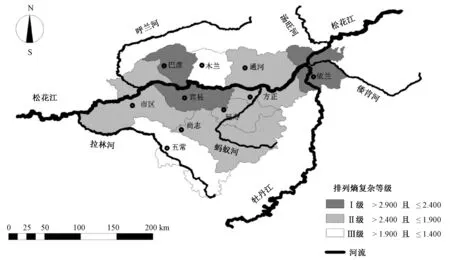
圖2 哈爾濱各區域逐日地下水埋深序列復雜性空間分布Fig.2 Complexity spatial distribution of daily groundwater depth series of each county in Harbin
3 討 論
本文選擇哈爾濱地區兩個下墊面條件(山地面積、水域面積),分析兩個條件與地下水埋深序列復雜性進行相關性分析,探究其對地下水水文系統復雜性的影響。分別計算山地面積比例與水域面積比例,并將其劃分為3級,見表3。其中山地面積比例在60%~80%為Ⅰ級,在35%~60%為Ⅱ級,在0%~35%為Ⅲ級),而水域面積在4.9%~7.0%為Ⅰ級,在2.5%~4.9%為Ⅱ級,在1.0%~2.5%為Ⅲ級。在哈爾濱各區域逐日地下水埋深序列復雜性空間分布底圖上分別繪制山地面積比例和水域面積比例空間分布圖,見圖3和圖4。
由圖3可知,巴彥、依蘭、尚志、延壽和方正的地下水埋深序列復雜性等級與山地面積比例等級一致,說明這5個區域的山地地形對地下水水文系統影響較大;賓縣和五常地下水埋深序列復雜性等級與山地面積比例等級相差2級,說明這2個區域的山地地形對地下水水文系統影響較小;其余區域兩者等級則相差1級,說明這3個區域的山地地形對地下水水文系統影響能力一般。
由圖4可知,巴彥和依蘭的地下水埋深序列復雜性等級與水域面積比例等級一致,說明這兩個區域的水域對地下水水文系統影響較大;賓縣和五常的地下水埋深序列復雜性等級與水域面積比例等級相差2級,說明這兩個區域的水域對地下水水文系統影響較小;其余區域兩者等級則相差1級,說明這6個區域的水域對地下水水文系統影響能力一般。
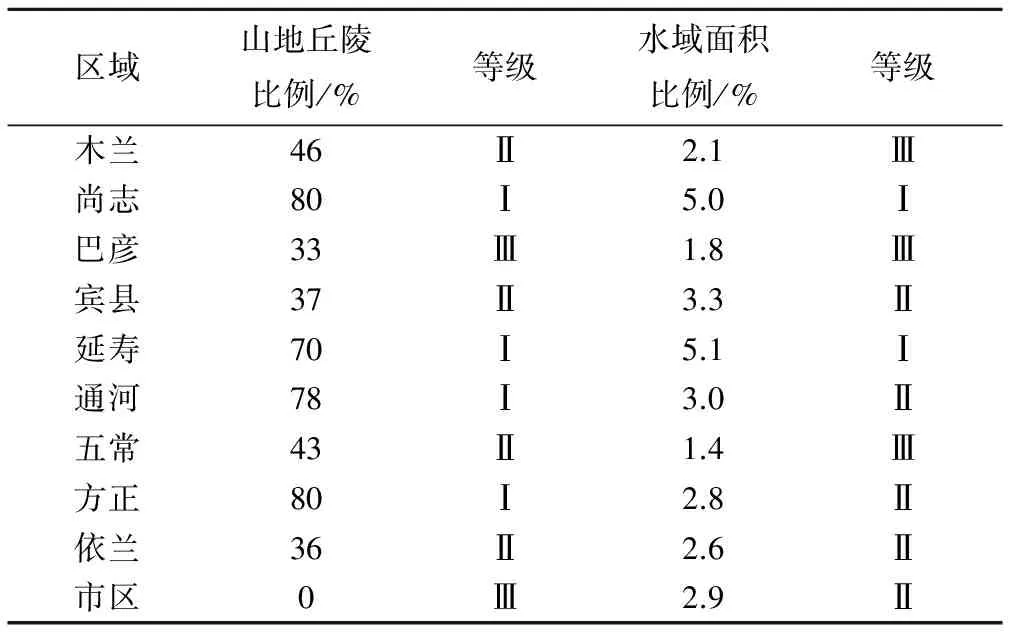
表3 哈爾濱各區域山地和水域面積比例及其分級Tab.3 Average value of proportion of mountain areaand its grade of each county in Harbin

圖3 哈爾濱各區域山地面積比例空間分布Fig.3 Spatial distribution of proportion of mountain area of each county in Harbin
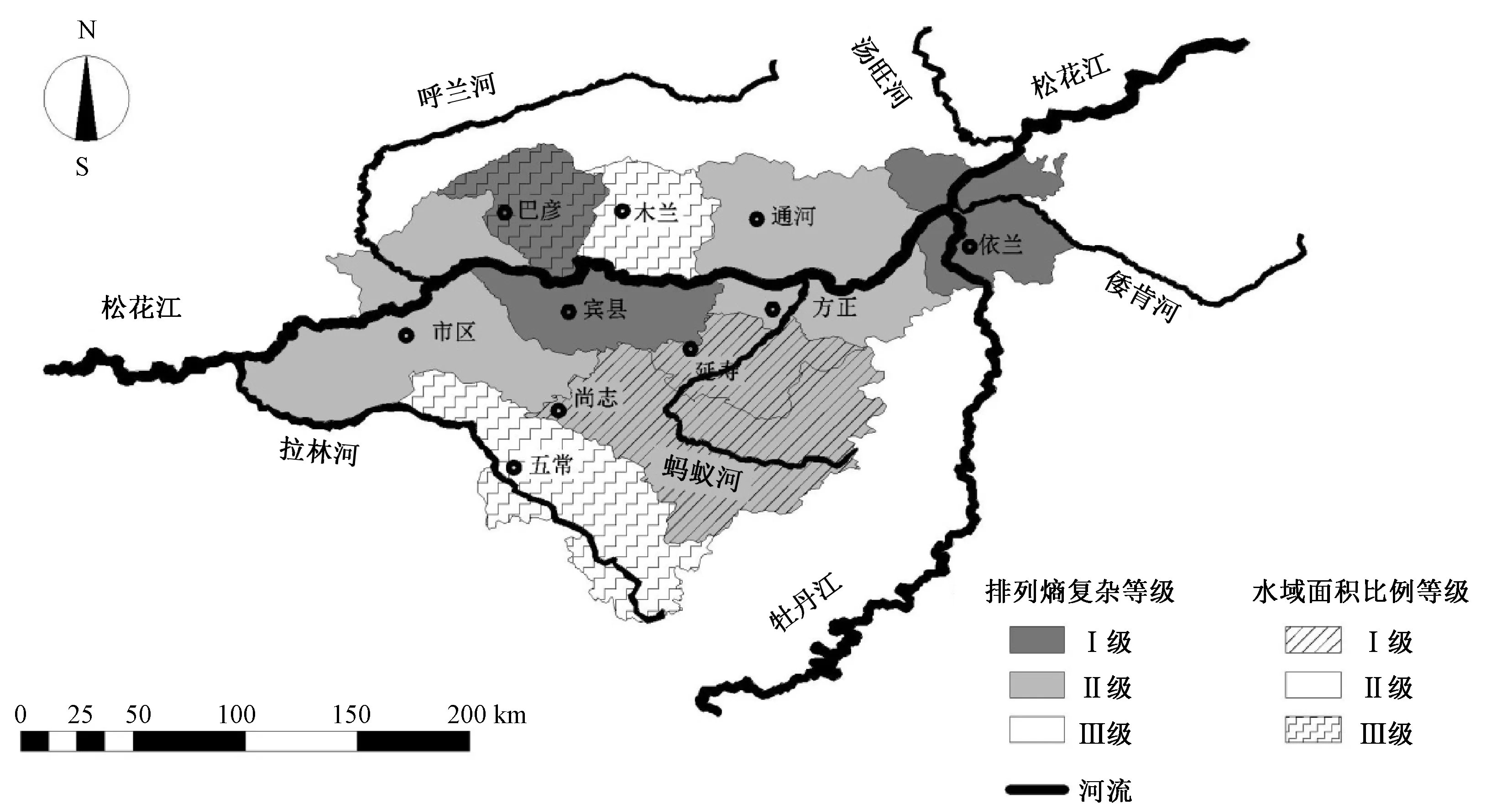
圖4 哈爾濱各區域水域面積比例空間分布Fig.4 Spatial distribution of proportion of water area of each county in Harbin
綜上所述,哈爾濱地區山地地形與水域對地下水埋深序列復雜性有重要影響,但具有差異性,其中山地地形的影響比水域影響較大一些。因此,下墊面條件對地下水水文系統復雜性有著一定影響。
4 結 論
本文運用PE測度哈爾濱地區2008-2013年地下水埋深序列復雜性,并分析下墊面條件對其影響,結論如下:
(1)PE算法具有計算簡便、結果穩定、抗干擾,適用于分析水文水資源復雜性特征。
(2)巴彥、賓縣、依蘭3個區域地下水埋深序列復雜性為Ⅰ級,說明這3個區域的預測難度大;市區、方正、尚志、通河、延壽5個區域地下水埋深序列復雜性為Ⅱ級,說明這5個區域的預測難度一般;木蘭、五常2個區域地下水埋深序列復雜性為Ⅲ級,說明這兩個區域的預測較為簡單。
(3)巴彥和依蘭等5個區域的地下水埋深序列復雜性與山地地形比例等級一致,而巴彥和依蘭2個區域的地下水埋深序列復雜性與水域面積比例等級一致,說明當地下墊面條件對地下水水文系統復雜性有重要影響;而其他區域則表現出地區差異型,推測是因為人類活動對地下水水文系統干擾較大。
(4)參數嵌入位數和延遲時間以及數據長度都直接影響著分析結果,所以結合智能算法優化參數以及數據完整收集并結合人類活動影響,對未來的地下水水文系統復雜性影響有重大意義。
[1] 洪 波,唐慶玉,楊福生,等. 近似熵,互近似熵的性質--快速算法及其在腦電與認知研究中的初步應用[J]. 信號處理,1999,15(2):100-108.
[2] 茍 競,劉俊勇,魏震波,等. 基于多尺度熵的電力能量流復雜性分析[J]. 物理學報,2014,60(20):208402(1-8).
[3] 姜 丹, 錢玉美. 效用風險熵[J]. 中國科學技術大學學報, 1994,24(4) :461-469.
[4] Quian Q R, Rosso O A, Baar E. Wavelet entropy: a measure of order in evoked potentials[J]. Electroencephalography & Clinical Neurophysiology Supplement, 1999,49:299-303.
[5] Ziesche P. Correlation strength and information entropy[J]. International Journal of Quantum Chemistry, 1995,56(4):363-369.
[6] Vasicek O. A Test for Normality Based on Sample Entropy[J]. Journal of the Royal Statistical Society, 1976,38(1):54-59.
[7] Cheng H D, Chen J R. Automatically determine the membership function based on the maximum entropy principle[J]. Information Sciences, 1997,96(3-4):163-182.
[8] 趙小磊, 任明榮, 張亞庭,等. 基于排列熵的心電信號非線性分析[J]. 現代電子技術, 2010,33(19) :90-93.
[9] 顏云華, 吳志丹. 基于MEMD的高速列車轉向架故障的排列熵特征分析[J]. 電子技術應用, 2016,42(5) :124-127.
[10] 叢 華, 崔 超, 劉遠宏,等. 基于排列熵和CHMM的齒輪故障診斷[J]. 失效分析與預防, 2015,(2) :72-77.
[11] Azami H, Escudero J. Improved multiscale permutation entropy for biomedical signal analysis: Interpretation and application to electroencephalogram recordings [J]. Biomedical Signal Processing & Control, 2016,23:28-41.
[12] Srinu S, Mishra A. Cooperative sensing based on permutation entropy with adaptive thresholding technique for cognitive radio networks [J]. IET Science Measurement & Technology, 2016:1-25.
[13] Xiu Jun L I. The Alkili-saline land and agricultural sustainable development of the western songnen plain in China [J]. Scientia Geographica Sinica, 2000,20(1):51-55.
[14] Bandt C, Pompe B. Permutation entropy: a natural complexity measure for time series [J]. Physical Review Letters, 2002,88(17):174 102.
[15] Parra L, Spence C. Cooperative sensing based on permutation entropy with adaptive [J]. IEEE Transactions on Speech & Audio Processing, 2000,8(3):320-327.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
