云環境下基于Agent協商的宿主機容錯策略
2017-03-01 04:26:10張凱旋顧春華
計算機應用與軟件 2017年1期
張凱旋 顧春華 萬 峰
(華東理工大學信息科學與工程學院 上海 200237)
云環境下基于Agent協商的宿主機容錯策略
張凱旋 顧春華 萬 峰
(華東理工大學信息科學與工程學院 上海 200237)
云計算平臺中大量使用了廉價的設備,使得宿主機出現故障概率大大增加。針對因宿主機故障而導致的虛擬機實例失效問題,提出一種宿主機容錯策略。通過對宿主機集群分組和對宿主機進行Agent建模,在每個小組內利用Agent協商來快速重建虛擬機實例。仿真實驗表明,所提出的策略能夠自動重建失效的虛擬機實例,提出的容錯策略在耗時上小于其他策略。
云環境 宿主機 Agent協商 容錯
0 引 言
隨著互聯網和云計算的不斷發展,云計算平臺作為基礎服務變得越來越流行。現在的云計算平臺,其底層是基于虛擬化技術實現的[1]。云計算平臺最典型的實現是在大量的的物理機構成的集群上運行虛擬機,通過虛擬機向用戶提供服務。在云計算平臺中,稱這種物理機為宿主機,虛擬機為客戶機或者實例。
作為衡量云計算平臺服務質量的重要標準,云計算平臺的高可用性越來越得到重視[2]。云計算平臺的高可用性是指虛擬機實例正常運行的時間占虛擬機實例總時間的百分比。云計算平臺的最大優勢是大量使用了廉價的標準計算機,而這種普通的計算機和專用服務器相比,出現故障的概率則大大增加。當宿主機出現故障,宿主機上運行的虛擬機實例便會失效,從而造成租用該虛擬機實例的用戶服務中斷。當宿主機出現斷電、硬件損壞等故障時,對宿主機上運行的虛擬機進行恢復重建才能恢復云計算平臺的服務。因此,云計算平臺需要有一定的容錯能力,才能保證云計算服務的高可用性。
1 相關研究
云計算平臺的出現的錯誤分布在三個層面:應用層、虛擬機層和宿主機層[3]。其中應用層面,是指應用程序在運行過程中出現的錯誤,例如Web服務器數據庫服務故障。虛擬機層面是指某一些虛擬機出現故障,如虛擬機網絡中斷等。而宿主機層面的錯誤是指宿主機出現硬件故障。在應用層容錯方面,傳統的容錯方案能夠滿足需求,如通過Web服務器集群和反向代理技術實現對Web服務器的容錯。因此,目前在云計算平臺的容錯方面研究的重點在于虛擬機層面的容錯和宿主機層面的容錯,而本文研究的是宿主機層面的容錯策略。
在宿主機層的容錯方面,Wang等提出了一種主備份的容錯調度策略用于對宿主機的錯誤容忍[4]。這種策略使用了主從宿主機結構,當宿主機出現故障,啟用備用的宿主機,這種策略需要設置多個宿主機作為備份宿主機,對宿主機資源浪費比較嚴重。Nogueira等將宿主機故障問題描述為一個拜占庭故障模型[5],提出了一種副本組的策略,使得對于有2m+1個宿主機集群,最多可以容忍m個宿主機出現錯誤。這種策略改進了傳統的拜占庭故障模型,提高了容忍錯誤的數量。但是,由于它的決策在全局中進行迭代,當集群規模比較大的時候,這種策略在效率上會變得很慢。
很多云計算廠商將宿主機的錯誤當作虛擬機錯誤來處理[6-7],其做法是,通過實時監測所有的虛擬機,并對虛擬機進行周期性快照。監控程序一旦檢測到虛擬機出現問題,則從最近的一次快照重新新建一個虛擬機取代失效的虛擬機。這種策略由于要定期做快照,保存快照增大了存儲資源的開銷。
在宿主機容錯方面存在著資源開銷大、效率低的問題。針對這些問題,本文提出了一種基于Agent協商的宿主機容錯策略,在不額外使用宿主機的前提下,能夠快速自動重建因宿主機故障而失效的虛擬機,提高了云計算平臺的容錯性。下文將介紹這種基于多Agent協商的容錯策略。
2 多Agent容錯模型
把宿主機看作Agent,利用Agent的自治性、協商來處理Agent故障[8]。
2.1 系統架構
在云計算平臺中,宿主機的數量成千上萬,因此Agent的數量也成千上萬。如果把整個集群中的Agent視為一個多Agent系統,則對于規模較大的多Agent系統,其用于通信的系統開銷也很大,并且Agent之間的協商時間開銷也很大。為了避免因多Agent系統規模太大造成的策略的收斂速度慢的問題,把集群中宿主機劃分成規模較小的組,每個組內有5到10個宿主機。每個組內的宿主機構成了規模較小的多Agent系統,組內的Agent之間通過交互來互相彼此狀態信息。當某個宿主機出現故障時,即Agent失效時,同一個組內的其他活動的Agent通過協作來處理失效Agent上正在運行的任務,即重建失效的虛擬機。由于故障處理策略作用在組內,從而加快了決策的收斂速度。圖1是多Agent系統的分組模型,其中Agent在邏輯上被分到一個個的組內。
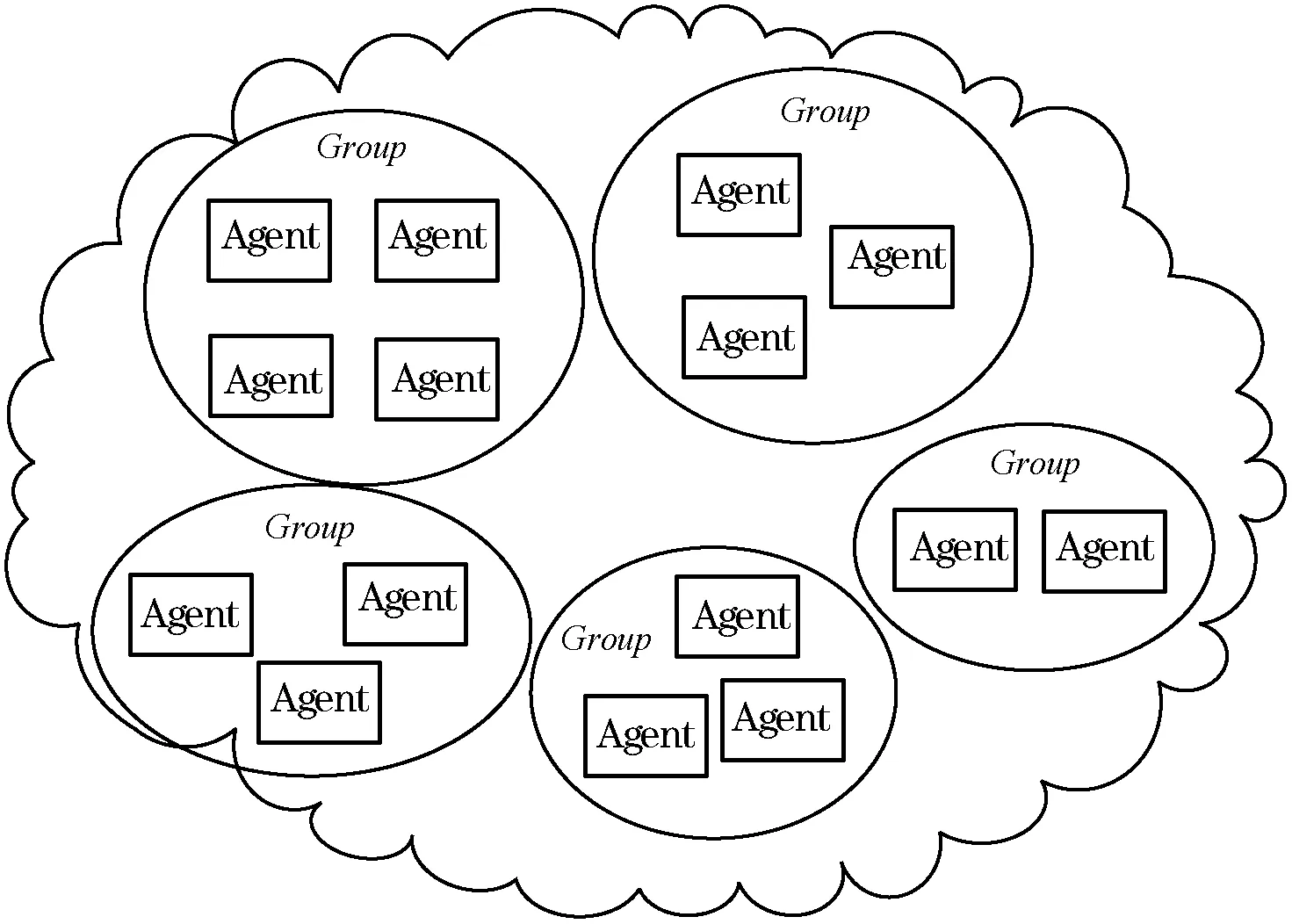
圖1 多Agent的分組模型
同一個組內的Agent構成了一個規模較小的多Agent系統,它們形成了一種聯盟。它們之間通過周期性的信息更新,來獲取組內成員Agent的任務信息和狀態信息。假設某時刻t某個Agent失效,則其他Agent檢測到該Agent失效后,由于失效Agent的狀態信息和任務信息在其他Agent上留有副本,因此,其余Agent通過協商來共同處理失效Agent正在處理的任務。如圖2所示。

圖2 組內Agent通過協商處理任務
2.2 Agent結構
按問題求解能力劃分,Agent分為三種類型[9],即反應型Agent,能響應環境的變化或來自其他Agent的消息;慎思型Agent,能夠針對意圖和信念進行推理,建立行為計劃,并執行這些計劃;社會型Agent,除具有慎思型Agent的能力外,還具有關于其他主體的明確模型[10]。本文的Agent代表了宿主機,則CPU利用率、內存利用率等是Agent本身能夠感知的信息,且這些信息隨著外部環境如負載的變化而變化。Agent除了能感知自身的信息之外,還通過其他Agent交互獲取其它Agent的狀態、任務信息,例如運行的虛擬機實例的個數、類型、虛擬機的配置信息等。慎思型的Agent其會維護一個內部可識別的世界模型,該模型描述了自身可感知的信息和外界環境信息。而當環境發生變化,Agent根據預設的目標作出不同的反應。本文的Agent需要維護自身和其他Agent的狀態,當外部環境改變即發現有Agent失效,就會做出反應。因此,慎思型Agent的結構最適合構造本文的Agent。如圖3所示。

圖3 慎思型Agent的結構
2.3 Agent世界模型
Agent的世界模型(WM,World Model)是Agent內部可識別的狀態,是對外部環境和自身信息經過加工、推理而建立的世界狀態[10]。Agent通過與其他Agent交互來獲取外部環境信息,通過自身的感知來獲取自身信息。虛擬化軟件啟動虛擬機的流程如下:虛擬機化軟件根據用戶指定的虛擬機配額生成一個xml文件,該文件描述了虛擬機的配置情況。接下來,虛擬機化軟件會根據上面生成的xml文件啟動虛擬機。虛擬機化軟件則根據鏡像文件和配置文件在計算節點啟動虛擬機。通過分析虛擬化軟件啟動虛擬機的流程可知,啟動一個虛擬機所必需的輸入條件是基礎鏡像和配置文件。其中基礎鏡像是虛擬機操作系統的鏡像,配置文件指定了虛擬機的核數、內存大小、硬盤大小、網卡設備等信息。用戶在虛擬機的過程中,會產生用戶數據,如用戶存放的文件等。一般地,用戶數據會單獨保存在云硬盤上,而云硬盤由塊服務提供,通過遠程掛載的方式掛載在虛擬機上。
Agent的世界模型由Agent自身周期性的進行更新。世界模型的信息按照信息變化的頻率可以劃分為靜態信息和動態信息。靜態數據是指Agent在初始化后,不經常改變的數據,如CPU核數、內存總大小、鏡像文件、虛擬機配置文件等。動態信息是指在Agent正常活動時,會時刻發生改變的數據,如CPU利用率、內存利用率、組內其他Agent運行的虛擬機信息和緩存的鏡像信息等。靜態信息的更新周期較長,相反的,動態信息的更新周期則要短。Agent的世界模型用一個二元組表示,其中StaticInfo表示靜態信息,DynamicInfo表示動態信息。
WM=
(1)
為了簡化描述,靜態信息用一個三元組表示。其中CPUtotle表示總的CPU核數,MEMORYtotle表示總的內存總大小,Disktotle表示總的硬盤總容量。
StaticInfo=
(2)
動態信息用一個五元組表示,分別表示宿主機的CPU剩余核數、內存剩余大小、硬盤剩余容量、所運行的虛擬機信息、緩存的鏡像信息、Agent所在的分組信息。
DynamicInfo=
(3)
所運行的虛擬機信息是Agent上所有運行的虛擬機的摘要信息,每一個虛擬機的摘要信息為虛擬機的id和鏡像id。虛擬機的id是由虛擬化軟件在啟動虛擬機虛擬機時分配的一個唯一的id,Agent用虛擬機的id作為該虛擬機配置文件的文件名保存到自身的文件系統中。
(4)
(5)
分組信息用一個三元組表示,其中MemberList是Agent所在組的其他Agent的集合。IsMaster表示Agent自身是不是管理Agent。
GroupInfo=
(6)
成員列表MemberList用一個二元組集合表示,其中Agentm表示組內第m個成員,Addressm表示Agentm的通信地址。
MemberList={
(7)
Agent在初始化后,從分組信息中獲知和它同一個組的其他Agent的通信地址,接下來Agent會周期性的更新自己的世界狀態。為了在啟動虛擬機時,節省鏡像從鏡像服務器傳輸到Agent的時間,Agent主動的將從已經緩存的鏡像文件平均的分發到組內其他Agent。因此,針對鏡像文件,Agent采取的更新策略是主動的將自己的鏡像文件平均的推到組內其他Agent上。而鏡像的描述信息以及其他摘要信息的更新采用拉的模式。
3 改進的合同網協商模型
Agent周期性地更新自身世界模型時,如果存在無響應的Agent,則認為該Agent失效了。當檢測到Agent失效時,同一組內的其他活動的Agent就會通過協商來協助失效Agent重建正在運行的虛擬機。Agent協商中經典的協調策略是由RandallDevis等提出的合同網協議,合同網協議是為了解決Agent之間的任務分配而進行的一種合約協商過程[10]。
3.1Agent的協商過程
合同網協議中的Agent有兩種類型[11],一種是管理Agent(MA,MasterAgent),另一種是執行Agent(EA,ExecuteAgent)。MA是協商過程的組織者,EA是執行任務的工作Agent。MA組織協商的過程如下:①MA向所有的EA發布任務;②EA收到任務信息后,根據任務要求和自己的能力,計算自己能夠完成的任務,并提交標書給MA進行競標;③MA選擇一個或多個EA進行作為最終的中標者,并與競標者簽訂問題求解合同;④MA負責監視整個任務的執行,EA將求解的結果提交給MA;⑤MA整合最終的處理結果。
3.2MA的選舉
傳統的合同網模型會指定某個Agent充當一種角色,而實際上每個Agent都有可能失效,如果MA自身失效,則會導致Agent之間因缺少組織者而無法協商。為了避免這個問題,本文的MA由所有Agent選舉產生,并且Agent可以充當多個角色,即Agent可以同時具備兩個角色。初始化時,每一個Agent都是EA,第一個檢測到存在失效的Agent,首先將失效Agent和當時的時間戳記錄下來,然后將帶時間戳的失效消息告知到組內其他Agent,并選舉自己為MA。當收到超過一半的Agent同意后則,把自己標記為Agent。如圖4所示。

圖4 Group內的不同角色的Agent
在這個過程中,為了避免多個Agent競爭MA,規定每個Agent在一次失效中只能投一次票。Agent投票之前,Agent分兩種情況來決定是否選舉自己為MA:① 如果它還沒有檢測到有失效Agent,就收到失效通知信息,說明自己不是第一個發現存在失效Agent。那么它將發送一個探測包給失效Agent,來確認Agent是否真的失效。確認后,則發送確認信息給發布失效通知的Agent,并且同意其成為MA;② 如果它自己也探測到有失效Agent并且自己沒來得及發出通告,則它就不再發出通告,避免多個Agent爭奪MA,接下來它按照①的方式繼續處理。Agent在發出選舉自己為在收到超過半數的投票后,把自己標記為MA,并告知其他Agent自己成為MA。
3.3 任務模型
當MA選舉成功后,由MA生成和發布任務。由前面的分析可知,該任務就是重建失效Agent上所運行的n個虛擬機。根據重建虛擬機所需的必要條件,任務的內容可以用一個待重建的虛擬機列表來表示。由于每個Agent的世界模型中都能保存了組內其他任意一個Agent運行虛擬機的摘要信息。因此,當故障出現時,其他活動Agent都可能具備失效Agent的完整信息。由于每個Agent更新世界狀態并不是同步的,所以并不能保證每個Agent在某一時刻對同一個對象的認知和描述都是一樣的。為了獲得失效Agent在失效的時刻最準確的信息,MA需要向所有活動EA詢問誰的信息是最新的。EA將自己最近一次更新世界狀態的時間戳發送給MA,MA對比所有EA發來的時間戳,就能確定最準確的信息在哪里。MA確定了最準確的信息之后制作任務清單,任務清單用一個二元組表示:
Task=
(8)
其中Agentadd表示失效的Agent的地址,InfoAgentadd描述了要失效的Agent在失效時的最準確的狀態信息所在的Agent地址。
3.4MA組織協商
MA在制作完任務清單后,將清單發送給所有的EA。EA收到MA發來的任務清單后,根據任務清單中的描述,從指定的Agent那里獲得失效Agent失效時的虛擬機信息VMInfo。EA按照約定的存儲方式,根據VMInfo提供的信息可以推算出要恢復的虛擬機所需的鏡像以及配置文件。
EA獲取到虛擬機的信息后,根據自身當前的負載和已經保存的信息來評估自己恢復每一個VM所耗費的時間,并制作標書發送給MA,標書用一個五元組表示,它描述了該Agent能夠對重建每一個VM所耗費的時間:
VMBid=
(9)
其中Agentadd表示該Agent的地址,VMid表示VM的id,Tschedule表示啟動這個虛擬機的調度耗時,TtransImage表示傳輸鏡像耗時,Tlaunch表示加載虛擬機耗時。
MA根據每個EA的提交的標書,求出最優的解。為了提高云計算服務的高可用性,就要盡量縮短恢復故障的時間,即MA求解的目標是使得在最短的時間內完成任務。從單個Agent來看,重建一個虛擬機的耗時包括三個方面:一是調度耗時,二是鏡像傳輸耗時,三是啟動耗時。其中一包含了控制器轉發請求時間和選擇合適的宿主機時間。這部分耗時對于Agent協商這種模型是不需要控制轉發,也不需要去遍歷所有的宿主機節點。針對第二點,Agent協商模型中每個Agent都會緩存其他Agent的信息,這其中包含啟動鏡像的配置文件和鏡像文件,因此傳生成配置文件的時間為0,啟動已經緩存過鏡像的虛擬機鏡像傳輸的耗時為0。針對第三點,通過實踐可知,大多數的虛擬機化技術啟動一個虛擬機的耗時很少且恒定。雖然Agent協商模型會帶來額外的協商時間開銷,但是由于組內的Agent數目有限,且合同網協議處理一個任務是一次協商,而不是多次協商。因此,Agent協商耗時相對于其節約的調度耗時和鏡像傳輸耗時要小得多,因此通過理論分析,Agent協商模型能減小故障恢復的時間。
而另一方面,要重建的虛擬機可能不止一個,MA在分配任務時,讓EA盡可能并行地去處理任務,從而縮短任務處理的時間。在啟動虛擬機時,鏡像傳輸是最耗時的一個環節,因此首先將虛擬機分配給那些不需要傳輸鏡像的Agent。如果任務沒有分配完成,再將剩下的虛擬機平均地分配到每個Agent上,算法保證了每個EA獲取到任務量是相等的,下面給出該算法的偽代碼。
算法1 任務分配算法
輸入數據:標書列表BidList,要重建的虛擬機列表VMList。
結果:任務分配結果Result。
0 int Average= VMList.size() / BidList.size();
//每個Agent平均獲得的任務數目
1 /*首先嘗試將任務分配給不需要傳輸鏡像的Agent*/
1 for ( vmi:VMList ){
2 for ( bidj:BidList ){
3 currentAgent = bidj.agent();
//當前報價的Agent
4 if( bidj.T_transImage = = 0 )
//已經緩存該鏡像
5 if( currentAgent.acceptVm < Average)
//小于平均值
6 Result.add(vmi,currentAgent);
//將vmi分配給currentAgent
7 currentAgent.acceptVm += 1;
8 break;
9 else
//當前Agent已經獲得的任務書達到期望值
10 continue;
//嘗試分配給下一個Agent
11 }
12 }
13 /*一輪分配后,如果還存在未分配的任務,則平均分配給每個Agent*/
14 if( Result.size() < VMList.size() ){
15 List UnallocateVMList;
//沒有分配出去的VM
16 for( bidj:BidList ){
17 currentAgent = bidj.agent();
18 while(currentAgent.acceptVm < Average){
19 vm = UnallocateVMList.take();//分配一個VM
20 Result.add(vm,currentAgent);
21 currentAgent.acceptVm += 1;
22 }
23 }
24 }
該任務分配算法,使得整個任務平均分攤在每個EA上,并且盡可能優先考慮最優分配。最后MA將計算出來的最終中標結果發送個每一個EA,中標結果中包含了整個中標結果。EA收到中標結果后,向MA發送一個確認回復,表示接收任務,即簽訂了合同,并開始執行任務。EA執行任務結束后將執行結果發送給MA。MA確定協商結果后,將去掉自己的MA角色,并告知其他Agent,任務處理結束,系統恢復正常。
4 仿真實驗
FIPA是Agent領域制定Agent之間互操作標準的國際組織[12],本文采用JADE進行仿真實驗室。JADE是一個完全由Java語言實現的Agent開發框架,它通過中間件的方式實現符合FIPA規范的多Agent系統,并支持通過一組圖形工具支持調試和部署[13]。
4.1 實驗設計
以OpenStack云計算架構作為實驗的參考架構,OpenStack是一個由NASA和Rackspace合作并發起的開源云計算管理平臺[14]。OpenStack啟動虛擬機的流程為:控制節點接收請求,啟用調度器,調度器根據各個宿主機的負載和資源使用情況,在所有的宿主機集群中選擇合適的宿主機,并將任務發送給計算節點的計算服務。計算節點首先從鏡像服務器請求鏡像,再調用底層虛擬機化軟件啟動虛擬機。
為了便于仿真實驗,定義一些預設前置條件:① 宿主機是同構的且物理資源是足夠大的;② 網絡傳輸的最大速度為1000 MB/s,且傳輸鏡像時以網絡最大速度傳輸;③ 設定5種規格的鏡像文件;④ 以鏡像的最低配置要求啟動虛擬機;⑤ 假設Agent失效時,Agent之間已經完成了數據的同步。如表1所示。

表1 預設的鏡像文件列表
現有的調度策略都是全局類調度策略,因此設計兩個實驗做對比:全局調度類的策略和本文基于組內Agent協商的策略。兩個實驗啟動虛擬機流程都是模擬OpenStack啟動虛擬機的流程,兩個實驗假設都是一個宿主機出現故障,針對兩個實驗分別構造20組實驗,故障宿主機上運行的虛擬機個數從1到20個。當虛擬機個數小于等于鏡像種類時虛擬機使用不同的鏡像,當虛擬機個數大于鏡像種類時,隨機選擇一個鏡像。本文策略的實驗構造一個Agent Group,當Agent之間完成數據同步后,通過JADE的GUI界面隨機殺死一個Agent,輸出中間的協商過程,并統計協商耗時、重建虛擬機耗時等。
4.2 結果分析
1) Agent協商效率分析
本文使用CNP作為協商的協議,由于本文改進了傳統的CNP協議,增加了管理Agent選舉的過程,使得整個協商過程的耗時會增加。為了減少選舉管理Agent的耗時,本文通過規定每個Agent在一次選舉中只能投一次票、投票前的分析等原則使得選舉在一輪即可得到結果。實驗表明,選舉過程對協商過程的協商效率影響很小,只有在參與協商的Agent數目非常多的時候才會有明顯的影響。實際上,參與協商的Agent處于同一個組內,而每個組的Agent數量又是比較小的。所以,增加了選舉過程的CNP協議在效率上是可以接受的。如圖5所示。

圖5 改進的CNP協商和經典的耗時對比
2) 恢復故障的耗時分析
從實驗結果可以看出,隨著虛擬機個數的增加,兩種策略的耗時都在增加,但在一定的范圍內本文策略的耗時是小于全局調度策略的耗時。如圖6所示。

圖6 重建虛擬機耗時隨著失效Agent運行的虛擬機個數的變化曲線
這是因為Agent已經緩存了數據,在重建虛擬機時候,不需要傳輸鏡像和重新生成虛擬機的配置文件,并且任務分配算法又保證了每個Agent的任務是相同的,因此極大提高了處理任務的并行度。全局調度的算法在失效Agent運行的虛擬機個數達到鏡像種類個數相等的時候,由于OpenStack在短時間內會緩存鏡像,所以會存在一個拐點。在實際的云計算環境中,一個宿主機上運行的虛擬機實例個數是有限個的且數目在幾十個之內。因此,本文的策略在實際的環境中是有效的。
5 結 語
從仿真實驗可以得出,提出的基于Agent協商的容錯策略是可行的。它具備以下的優點:① 不額外增加宿主機,減小了資源浪費;② 容錯機制作用在Agent組內,策略收斂速度較全局調度策略快。
[1] 林利, 石文昌. 構建云計算平臺的開源軟件綜述[J]. 計算機科學, 2012, 39(11):1-7,28.
[2] 陳康, 鄭緯民. 云計算:系統實例與研究現狀[J]. 軟件學報, 2009, 20(5):1337-1348.
[3] Tchana A, Broto L, Hagimont D. Approaches to cloud computing fault tolerance[C]//Computer, Information and Telecommunication Systems (CITS), 2012 International Conference on. IEEE, 2012:1-6.
[4] Wang J, Zhu X, Bao W. Real-Time Fault-Tolerant Scheduling Based on Primary-Backup Approach in Virtualized Clouds[C]// High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC), 2013 IEEE 10th International Conference on. IEEE, 2013:1127-1134.
[5] Nogueira R, Araujo F, Barbosa R. CloudBFT: Elastic Byzantine Fault Tolerance[C]//2014 IEEE 20th Pacific Rim International Symposium on Dependable Computing (PRDC). IEEE Computer Society, 2014:180-189.
[6] Microsoft. Windows azure: Microsoft's cloud services platform[EB/OL]. http://www.microsoft.com/windowsazure/.
[7] Bakshi K. Cisco cloud computing-data center strategy, architecture, and solutions point of view white paper for U.S. public sector[EB/OL]. http://www.cisco.com/web/strategy/docs/gov/CiscoCloudComputing WP.pdf.
[8] 黃楠, 劉斌. 多Agent技術綜述[J]. 微處理機, 2010, 31(2):1-4.
[9] 黃關山, 徐冬梅. Agent的理論與結構模型分析[J]. 微型機與應用, 2004(2):6.
[10] 徐燕妮. 基于合同網協議的多Agent協作技術研究[D]. 青島:山東科技大學, 2006.
[11] 宋海剛, 陳學廣. FIPA合同網協議的一種改進方案[J]. 華中科技大學學報(自然科學版), 2004, 32(7):31-33.
[12] FIPA. Welcome to FIPA[OL]. http://www.fipa.org/.
[13] JADE. Introduction to Jade[EB/OL]. http://jade.tilab.com/documentation/tutorials-guides/introduction-to-jade/.
[14] OpenStack. Document for Mitaka[EB/OL]. http://docs.openstack.org.
FAULT TOLERANCE STRATEGY BASED ON AGENT NEGOTIATION IN A CLOUD ENVIRONMENT
Zhang Kaixuan Gu Chunhua Wan Feng
(CollegeofInformationScienceandEngineering,EastChinaUniversityofScienceandTechnology,Shanghai200237,China)
In the cloud computing platform,a large number of low-cost devices are used,which greatly increases the failure probability of host computers.To deal the problem of virtual machine instance failure caused by host failure,a kind of fault tolerant strategy of host is proposed.The virtual machines are rebuilt in each group using Agent negotiation by clustering,grouping and Agent modeling the host computers.The simulation experiment shows that the proposed method is able to rebuild the disabled virtual machine instances automatically,and take less time than other strategies.
Cloud Host Agent negotiation Fault tolerance
2015-10-12。張凱旋,碩士生,主研領域:云計算方向。顧春華,教授。萬峰,高工。
TP3
A
10.3969/j.issn.1000-386x.2017.01.005
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
汽車維修與保養(2019年7期)2020-01-06 03:30:42
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
中華手工(2017年2期)2017-06-06 23:00:31
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
中外會展(2014年4期)2014-11-27 07:46:46
時代英語·高三(2014年5期)2014-08-26 02:49:51
