基于抽象語法樹的數據泥團自動檢測研究
2017-03-01 04:32:05劉宏韜胡志剛
計算機應用與軟件 2017年1期
劉宏韜 劉 偉,2 胡志剛
1(中南大學軟件學院 湖南 長沙 410075)2(湖南中醫藥大學管理與信息工程學院 湖南 長沙 410208)
基于抽象語法樹的數據泥團自動檢測研究
劉宏韜1劉 偉1,2胡志剛1
1(中南大學軟件學院 湖南 長沙 410075)2(湖南中醫藥大學管理與信息工程學院 湖南 長沙 410208)
數據泥團是一種常見的代碼味道,它將帶來重復代碼和維護難度增加等問題。針對大部分已有的代碼味道自動檢測工具無法檢測數據泥團,且檢測類型不全面等問題,提出一種基于抽象語法樹的數據泥團自動檢測方法。該方法在已有檢測工具的基礎上,增加了新的數據泥團類型,并加入了剔除冗余數據泥團和提取子數據泥團等步驟。通過對4個開源項目進行數據泥團實驗,結果表明方法具有較高的精確率,與Stench Blossom、inFusion等工具的數據泥團自動檢測功能相比,能夠檢測出一些其他工具無法檢測的數據泥團。同時,該方法具有較好的性能,執行時間與系統規模成正比。
代碼味道 數據泥團 抽象語法樹 源代碼解析 重構
0 引 言
代碼味道是指源代碼中存在的一些不良實現方案。軟件工程大師Martin Fowler和Kent Beck在文獻[1]中初次使用“代碼味道”一詞來描述這些不良實現方案,文獻中定義了22種常見的代碼味道,包括數據泥團、重復代碼、霰彈式修改等。此后,一些新的代碼味道[2]被學者和研究人員陸續提出。檢測、去除代碼味道對于提高代碼質量具有非常重要的意義[3],去除代碼味道能夠改善代碼的可維護性,因此應當對程序代碼中的代碼味道進行檢測和合理重構,在不改變程序外部行為的前提下改善代碼的質量。
開發人員往往在對代碼味道進行重構之前,人工審查代碼、檢測代碼味道,這樣的方式效率低下,且正確率不高。近年來,自動檢測代碼味道已成為軟件工程領域的一個研究熱點。Liu等人[4-5]對泛化重構機會檢測進行了研究,并基于概念關系、實現相似性等開發了一款重構時機檢測工具。Maneerat等人[6]提出了從軟件設計模型的角度檢測代碼味道,將7種機器學習的算法運用于數項代碼味道數據集,并根據27個度量指標檢測7種代碼味道,并對各種機器學習算法在代碼優化方面的性能進行了評估。此外,針對檢測代碼味道這一問題也誕生了一些自動化工具。PMD[7]可以檢查源代碼中存在的過大類、重復代碼等代碼味道,它允許用戶自定義檢測這些代碼味道的閾值;CheckStyle[8]能夠探測代碼大小是否違規、類的設計是否良好,也能找出過長函數、過長參數列等代碼味道。
本文將以源代碼中數據泥團代碼味道為研究對象,提出了一種精確率及性能俱佳的數據泥團自動檢測算法,有助于軟件開發人員快速精準地發現項目中存在的數據泥團代碼味道,為進一步的數據泥團重構提供有力支持。
1 數據泥團和抽象語法樹
1.1 數據泥團
數據泥團[1]是22種常見代碼味道之一,它指代那些經常捆綁出現的數據,如多個類中出現了相同的數個屬性,或多個方法中出現了相同的數個參數。對于類屬性數據泥團,應當使用提煉類,將數據提煉到一個獨立對象;對于方法參數數據泥團,應當使用引入參數對象。數據泥團的存在將增加系統的耦合度,自動檢測并重構數據泥團,對數據實施集中式管理,可以提高代碼的可維護性和可復用性,進而增強系統內聚性,降低耦合度,并提高代碼的可讀性、可擴展性等。Fontana等人[9]對現有的代碼味道自動檢測工作進行研究,發現對于數據泥團這一代碼味道,目前僅有inFusion[10]和Stench Blossom[11]兩款工具能作出自動檢測。
1.2 抽象語法樹
數據泥團的檢測工作基于對抽象語法樹AST(Abstract Syntax Tree)的分析,將指定項目源代碼轉換成抽象語法樹之后,再收集數據泥團檢測的相關信息。抽象語法樹是一種常用的程序代碼的中間表示形式。
本文使用Java語言為例,Eclipse JDT提供了Eclipse AST[12]用于將Java源代碼解析為抽象語法樹,并能對其進行節點的創建、修改。Eclipse AST中ASTNode類作為所有Java語法結構節點的父類,它的子類如TypeDeclaration(類聲明)、MethodDeclaration(方法聲明)等都對相應的語法結構進行了明確地描述,并提供了大量的方法用于訪問該節點的屬性,如類名、方法參數列表等。此外,還提供了一個ASTVisitor類用于定義AST的抽象訪問者,在該類中聲明了一組訪問各類AST節點的方法,用于對各種類型的節點實施相應的操作。
2 數據泥團自動檢測算法
考慮到檢測數據泥團后的重構流程,本文所檢測的單個數據泥團將包含兩部分:
(1) 數據集 (Datum) 單個數據泥團所包含的數據。
(2) 位置集 (Location) 該數據泥團出現的位置。
本文主要針對數據類型、名稱(部分包括初始值)完全相同的情況,數據泥團中的數據將以如表1格式的字符串進行存儲。
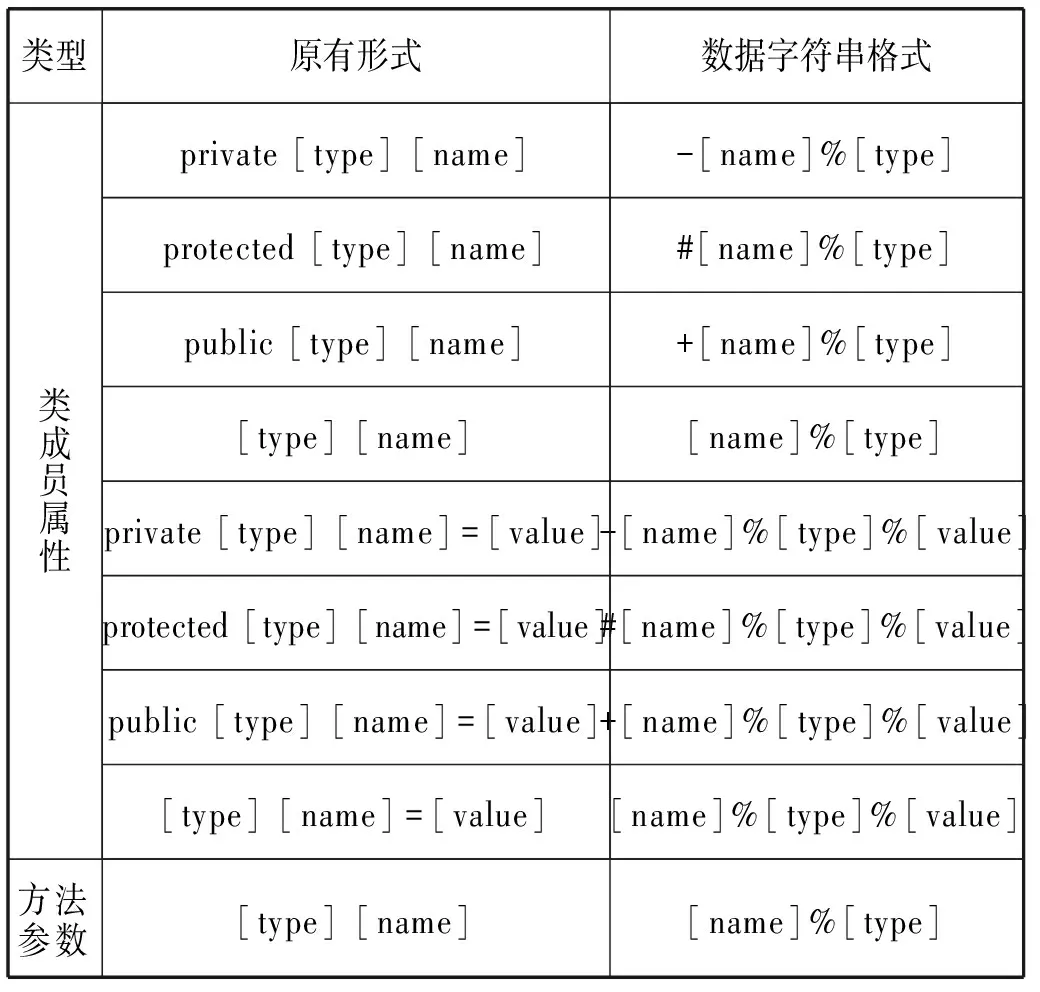
表1 數據字符串格式
數據集來自對類屬性和方法參數的收集、計算和篩選,其中篩選主要依據以下兩項度量指標:
(1) 重復度 (Repeat) 數據泥團出現的次數。
(2) 規模 (Size) 數據泥團的大小。
考慮到使用者檢測數據泥團需求的不同,數據泥團的重復度下限(minRepeat)和規模下限(minSize)兩項閾值將作為參數傳入,若一候選數據泥團重復度和規模均不小于重復度下限和規模下限(即Repeat≥minRepeat & Size≥minSize),則將其判定為一個數據泥團,使用者可以根據需求自定義重復度和規模閾值以查找所需的數據泥團。
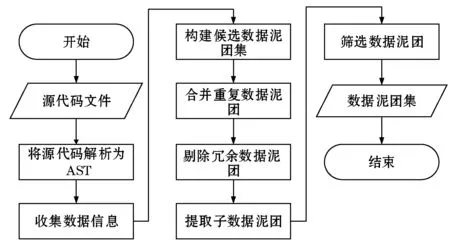
圖1 數據泥團自動檢測流程圖
數據泥團自動檢測流程如圖1所示,其中步驟解釋如下:
(1) 將源代碼解析為AST。
(2) 收集數據信息 遍歷AST中每一個類節點(TypeDeclaration)、匿名類節點(AnonymousClassDeclaration)和方法節點(MethodDeclaration),對符合規模下限的類屬性和方法參數進行整理,得到數據信息列表。數據信息包含數據集和位置兩部分,數據集即所對應的類屬性或方法參數以表1中的字符串格式存儲的字符串集合,位置即所對應的類或方法所在的位置。
(3) 構建候選數據泥團集 對數據信息列表中的每兩個數據信息p和q進行集合運算,將符合規模下限的結果存儲為數據泥團A,得到候選數據泥團集。其中A.datum = p.datum ∩ q.datum。之后需對候選數據泥團集按照數據集的規模,從大到小排序,以確保規模較大的數據泥團優先被檢測。
(4) 合并重復數據泥團 對于候選數據泥團集中的每兩個候選數據泥團A和B,如果A和B兩者數據集相同,則將B的位置集合并到A的位置集中,并從候選數據泥團集中刪除B。
(5) 剔除冗余數據泥團 假設候選數據泥團集中存在{a, b}和{b, c},它們都存在于方法func(a, b, c),若將{a, b}確定為數據泥團并封裝為數據類A,則原參數列表將被修改為func(A, c),參數列表中將不再存在數據泥團{b, c},因此需要從候選數據泥團中刪除{b, c}。
(6) 提取子數據泥團 假設重復度閾值為2,func(a, b, c)中存在的數據泥團{a, b}被封裝成數據類A,原參數列表將被修改為func(A, c),若{A, c}仍為滿足閾值要求的數據泥團并被封裝為類B,則需將{a, b}作為{A, c}的子數據泥團,即在重構時B繼承A,且原參數列表修改為func(B)。
(7) 篩選數據泥團 根據輸入的規模下限和重復度下限對候選數據泥團集進行篩選,以得到最終數據泥團檢測結果。
數據泥團自動檢測算法偽代碼如表2所示。

表2 自動檢測算法偽代碼
該算法根據所處理內容的不同,可劃分為兩個部分進行時間復雜度的分析。第一部分為數據信息的收集,該部分主要將代碼源文件轉換到抽象語法樹并進行遍歷進而收集數據信息,因此不難得知數據信息收集過程的時間復雜度為O(n),n為源代碼文件的數量,即理論上運行時間隨著源代碼文件數量的增加而線性增加。第二部分為數據泥團的檢測,該部分主要針對第一部分中所收集的數據信息進行集合運算等一系列的處理,根據算法分析可知時間復雜度基本為O(n2),n為第一部分中所收集的數據信息的數量,即理論上運行時間與數據信息數的平方成正比。
3 實驗結果分析
本文算法已嵌入到前期研究工作所開發的一款Eclipse插件SCORT[13]中。為了測試數據泥團的自動檢測效果,本文選取了同樣具有數據泥團自動檢測功能的工具inFusion和Stench Blossom與SCORT進行比較,三款工具檢測效果如表3所示。
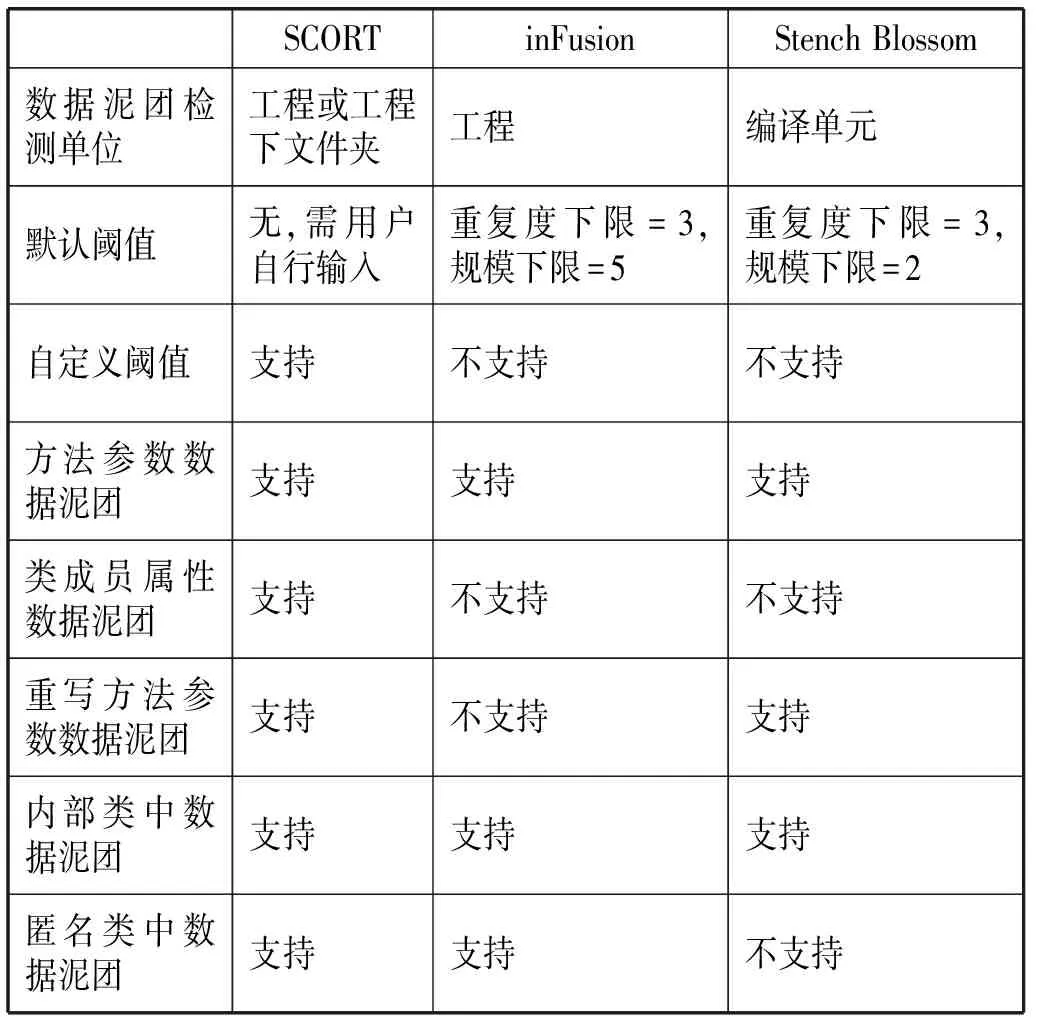
表3 數據泥團自動檢測工具對比
由檢測效果可知:Stench Blossom[14]作為Eclipse插件,其檢測結果實時呈現在編輯器中,效率較慢,且只能針對當前編譯單元(即當前打開的文件)進行檢測,檢測效果一般;inFusion作為一款定期升級的商業軟件,檢測效果較好,且能針對整個工程進行檢測,與SCORT檢測效果相近,SCORT所檢測的數據泥團類型更為全面。為了驗證本文所述數據泥團的自動檢測算法的執行效率和正確性,本文選取四個開源項目進行實驗,并為了與檢測效果相近的inFusion工具對比,因此使用與inFusion相同的閾值(即minRepeat=3、minSize=5)。本文選取了四個開源Java 項目,這四個項目規模和類型不一,基本信息如表4所示。
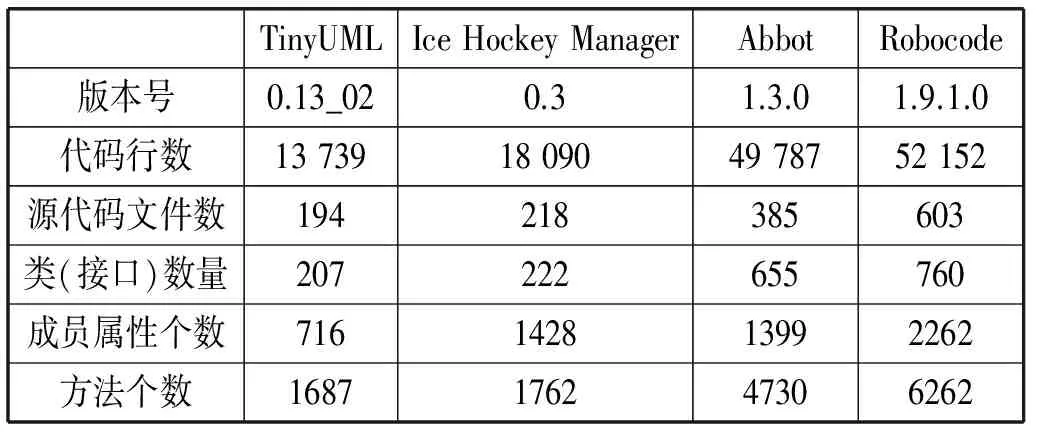
表4 待測項目基本信息
3.1 數據泥團檢測算法執行效率實驗
實驗首先使用SCORT工具對四個項目進行數據泥團的檢測,并對算法執行時間進行分析。對于每一個項目,數據泥團自動檢測算法均執行5次,然后分別計算算法兩個部分的平均時間。數據泥團檢測實驗在一臺安裝Windows 7操作系統的PC機上進行,其配置為:雙核2.00 GHz,2 GB DDR2 RAM。數據泥團自動檢測算法包括數據信息的收集和數據泥團的檢測兩個部分,表4中四個待測項目的數據信息收集平均時間如表5所示。
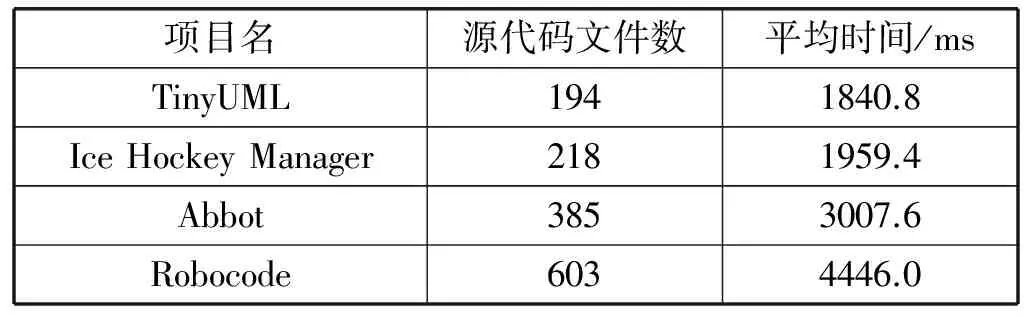
表5 數據信息收集平均時間
由表5可知,隨著系統規模的增大(源文件數量的增加),數據信息收集的平均執行時間也逐步增加,以源代碼文件數為X軸,數據信息收集程序的執行時間為Y軸,可得圖2所示源文件數-數據信息收集執行時間圖。
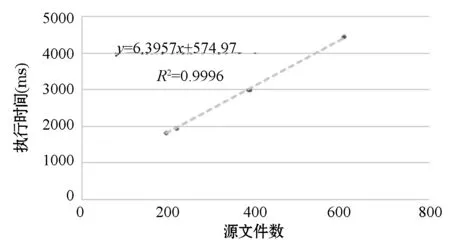
圖2 源文件數-數據信息收集執行時間圖
圖2中虛線為對實驗結果進行擬合的線性趨勢線,擬合方程為y=6.3957x+574.97,R2=0.9996。在數據信息收集部分,主要是將項目中的所有源文件轉換為抽象語法樹,并在抽象語法樹中根據條件收集數據信息,因此該部分執行時間與源文件數量關系密切。因此從圖2中可以看到,執行時間與系統規模(源文件數量)成正比,隨系統規模的增大執行時間增加,整體呈現線性關系,算法具有良好的性能。
考慮到數據泥團的檢測部分算法執行速度較快,因此該部分實驗將時間精確到納秒進行統計,并在表4中四個項目的基礎上追加六個開源項目,總共十個開源項目的數據泥團檢測部分執行時間如表6所示。
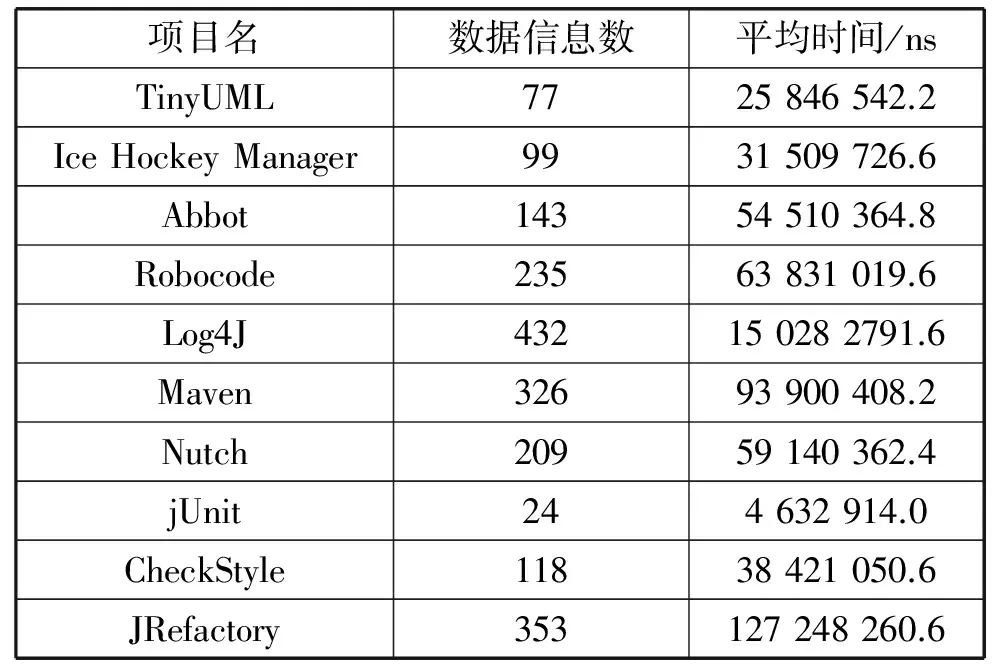
表6 數據泥團檢測平均時間
由表6可知,隨著算法第一部分所收集的數據信息的數量增加,數據泥團檢測的平均執行時間也逐步增加,以數據信息數為X軸,數據泥團檢測程序的執行時間為Y軸,可得圖3所示數據信息數-數據泥團檢測執行時間圖。
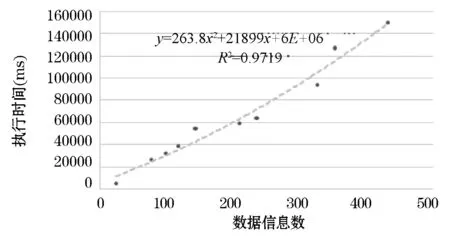
圖3 數據信息數-數據泥團檢測執行時間圖
圖3中虛線為對實驗結果進行擬合的線性趨勢線,擬合方程為y=263.87x2+218990x+6E+06,R2=0.9719。在數據泥團檢測部分,主要是對前段算法所收集的數據信息進行集合運算,因此執行時間與該項目所收集的數據信息關系密切。從圖3中的趨勢線可以看到,執行時間與數據信息數的平方成正比。總體看來,本文中的數據泥團自動檢測算法執行效率與系統規模成正比,執行時間隨著系統規模的增加而增加,算法具有較好的執行效率。
3.2 數據泥團檢測算法性能實驗
為了更好地評價數據泥團檢測結果,本文使用精確率(Precision)和召回率(Recall)來分析算法的性能,并結合人工審查判斷檢測結果是否正確,精確率和召回率分別表示為:
Precision=TP/(TP+FP)
(1)
Recall=TP/(TP+FN)
(2)
其中,真陽性TP(True Positive)表示工具檢測到的正確數據泥團數量;假陽性FP(False Positive)表示工具檢測到的錯誤數據泥團數量,即人工審查后發現檢測出的數據泥團是錯誤的;假陰性FN(False Negative)表示工具沒有檢測到,但人工審查后發現應當作為數據泥團檢測的數量。通過對檢測出的數據泥團進行逐個審查可以得到TP和FP值。
而對于FN值,由于人工查找正確的數據泥團難度較大,因此,實驗將既有成熟的代碼檢測工具inFusion檢測結果視為人工查找到的正確的數據泥團。SCORT和inFusion對表4中四個項目的數據泥團檢測結果如表7所示。

表7 SCORT與inFusion的數據泥團檢測結果
根據表7得到TP、FP和FN值,并計算出相應的精確率和召回率,結果如表8所示。
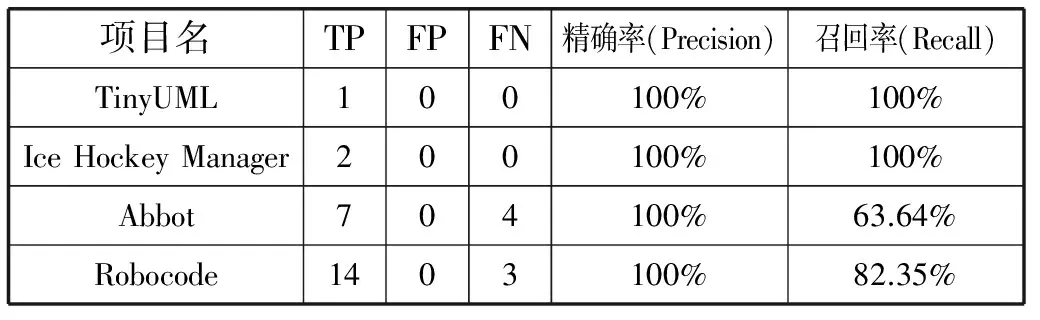
表8 數據泥團自動檢測精確率與召回率
對于SCORT和inFusion兩款工具檢測結果的差異,以及召回率進行分析。表7中,兩款工具對于項目TinyUML的檢測結果相同;在項目Ice Hockey Manager的檢測結果中,SCORT檢測到了2個類屬性數據泥團,而inFusion由于沒有該項功能,因此沒有檢測結果;項目Abbot的檢測結果中,SCORT檢測到7個數據泥團,剔除了4個inFusion結果中存在的冗余數據泥團,另外檢測出3個來自于重寫方法的數據泥團,這些方法所在的類存在于同一繼承樹;項目Robocode的檢測結果中,SCORT檢測到13個數據泥團,剔除了3個inFusion結果中存在的冗余數據泥團,另外檢測出1個來自于重寫方法的數據泥團,以及1個類屬性數據泥團。
經分析發現,檢測結果存在差異的主要原因為SCORT與inFusion工具所使用的算法的目的和對“數據泥團”概念的認識不一。inFusion工具目的在于度量和評估軟件的質量,且它所檢測的數據泥團僅為方法參數;SCORT目的在于檢測重構時機,便于日后的重構工作,因此將冗余數據泥團情況進行處理,并且SCORT所檢測的數據泥團包括了方法參數和類成員屬性。對于來自同一繼承樹的類成員屬性,以及來自重寫方法的參數,本文都認為是需重構的數據泥團。SCORT相較于inFusion所檢測的數據泥團類型更為全面,更符合數據泥團的定義。
4 結 語
代碼味道的自動探測與優化對于提高軟件質量具有重要意義,但針對“數據泥團”這一代碼味道的檢測算法和工具較少。本文研究了一套基于抽象語法樹的數據泥團自動檢測算法,該算法在以往研究成果的基礎上增加了檢測類成員屬性所組成的數據泥團,并提出剔除冗余數據泥團、提取子數據泥團,為日后的自動重構工作做好鋪墊。
通過對4個開源項目進行數據泥團檢測實驗,結果表明,該方法精確率非常高,能夠正確檢測出源代碼中所有的數據泥團,實驗項目的數據泥團檢測精確率可達100%,并消除了所有的假陽性實例,與已有方法相比,其結果更全面;算法執行效率較高,執行時間與系統規模成正比,適用于各種規模的系統。
本文算法將類成員屬性與方法參數分開處理,且以字符串形式完全匹配而進行數據泥團的檢測,但在實際軟件開發過程中有著同時存在于屬性和參數的數據泥團,或變量名并不完全相同的數據泥團,在后續工作中,將逐步改進上述問題。此外,還將實現對數據泥團的自動重構,例如將其自動封裝為數據類。
[1] Fowler M. Refactoring: improving the design of existing code[M]. Massachusetts: Addison-Wesley, 1999.
[2] Kerievsky J. Refactoring to patterns[M]. Massachusetts: Addison-Wesley, 2004.
[3] Emden E V, Moonen L. Java quality assurance by detecting code smells[C]//Proceedings of the Ninth Working Conference on Reverse Engineering (WCRE' 02), 2002: 97-106.
[4] Liu H, Ma Z, Shao W, et al. Schedule of bad smell detection and resolution: a new way to save effort[J]. IEEE Transactions on Software Engineering, 2012, 38(1): 220-235.
[5] Liu H, Niu Z, Ma Z, et al. Identification of generalization refactoring opportunities[J]. Automated Software Engineering, 2013, 20(1): 81-110.
[6] Maneerat N, Muenchaisri P. Bad-smell prediction from software design model using machine learning techniques[C]//Computer Science and Software Engineering (JCSSE), 2011 Eighth International Joint Conference on. IEEE, 2011: 331-336.
[7] Dangel A, Pelisse R. PMD[CP/OL]. (2013-05-01) [2013-05-04]. http://sourceforge.net/projects/pmd/.
[8] Burn O. CheckStyle[CP/OL]. (2012-10-12) [2013-05-04]. http://sourceforge.net/projects/checkstyle/.
[9] Fontana F A, Braione P, Zanoni M. Automatic detection of bad smells in code: An experimental assessment[J]. Journal of Object Technology, 2012, 11(2): 1-38.
[10] Intooitus SRL. inFusion[CP/OL]. (2012-10-31) [2013-05-04]. http://www.intooitus.com/products/infusion.
[11] Murphy-Hill E. Stench Blossom[CP/OL]. http://people.engr.ncsu.edu/ermurph3/tools.html.
[12] Thomas K, Eye M G, Olivier T. Eclipse corner article: abstract syntax tree[EB/OL]. (2006-11-20) [2013-05-04]. http:// www.eclipse.org/articles/article.php?file=Article-JavaCodeManipulation_AST/index.html.
[13] 劉偉, 劉宏韜, 胡志剛. 代碼缺陷與代碼味道的自動探測與優化研究[J]. 計算機應用研究, 2014, 31(1): 170-176.
[14] Murphy-Hill E, Black A P. An interactive ambient visualization for code smells[C]//Proceedings of the 5th International Symposium on Software Visualization. ACM, 2010: 5-14.
RESEARCH OF AUTOMATIC DETECTION FOR DATA CLUMPS BASED ON ABSTRACT SYNTAX TREE
Liu Hongtao1Liu Wei1,2Hu Zhigang11(SchoolofSoftware,CentralSouthUniversity,Changsha410075,Hunan,China)
2(SchoolofManagementandInformationEngineering,HunanUniversityofChineseMedicine,Changsha410208,Hunan,China)
Data Clumps is a common code smell, it will lead to issues such as duplicated code and increased difficulty in maintenance. As most existing code smell automatic detection tools fail to detect data clumps, and the detection type is not complete, a data clumps automatic detection based on abstract syntax tree is proposed. On the basis of existing detection tools, adding new types of data clumps to the algorithm, with some new steps as redundant data elimination and sub-data clumps extraction. Experiments are executed on 4 open source projects. Results show that the approach has high accuracy, and it is able to detect data clumps which other tools failed to detect, such as Stench Blossom, inFusion, etc. In addition, this approach has good efficiency and the execution time is directly proportionate to the size of system.
Code smell Data clumps Abstract syntax tree Source code parsing Refactoring
2015-12-03。國家自然科學基金項目(61272148)。劉宏韜,碩士生,主研領域:軟件工程。劉偉,高工。胡志剛,教授。
TP311.5
A
10.3969/j.issn.1000-386x.2017.01.003
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
