數據挖掘在個人信用評估中的研究
2016-12-12 02:40:00陶超李超李杰趙騫
商丘師范學院學報 2016年12期
陶超,李超,李杰,趙騫
(1.安徽財經大學 統計與應用數學學院,安徽 蚌埠 233030;2.安徽財經大學 財政與公共管理學院,安徽 蚌埠 233030)
?
數據挖掘在個人信用評估中的研究
陶超1,李超1,李杰1,趙騫2
(1.安徽財經大學 統計與應用數學學院,安徽 蚌埠 233030;2.安徽財經大學 財政與公共管理學院,安徽 蚌埠 233030)
個人信用評估是現代商業銀行個人信用管理的核心.本文將數據挖掘中的隨機森林算法(Random Forests,RF)運用到現代個人信用評估模型中,實現了逐步優化和評估.實證分析的結果證明,隨機森林模型具有較高的精確性和泛化能力,能夠克服噪聲數據的影響.通過對各特征變量的重要性評分,得到貸款期限和總額等對風險預測的準確率具有顯著作用.
隨機森林;特征變量;個人信用評估;R軟件
0 引 言
金融危機過后,隨著經濟的逐漸復蘇,個人消費貸款不斷升溫,消費貸款已成為了全球各商業銀行一個重要的利潤增長點.個人消費信貸迅速發展的同時也增加了商業銀行的信用風險,個人信用風險指個人在信貸發生后,借款人由于各種原因無法按時還款的風險,此時銀行會面臨利潤的損失.但個人信用評估涉及的指標繁雜,數據往往存在缺失和分布復雜等缺點,給目前個人信用評估中的單分類器模型帶來了很強的噪聲干擾,降低了模型的預測精度和穩健性等.因此本文運用單個分類器的組合算法—隨機森林模型對樣本數據進行仿真,并對特征變量評估.
1 實驗數據準備和指標描述
1.1 數據來源
本文的實驗數據來源于歐洲Stat log數據庫中德國教授Han.Hofmann收集的消費貸款數據:German Credit Dataset[1].貸款者的詳細資料和最終的信用分類指標如表1所示:

表1 用戶歷史數據指標及代碼
該數據集一共有20個指標變量,包括13個分類變量和7個數值變量,共有1000個樣本數據,其中最終未發生違約的客戶為700個(下文用良好表示),發生違約的客戶為300個(下文用不良表示).
1.2 數據歸一化處理
為了提高模型分類的準確性,本文首先對樣本集中的定性指標賦予相應的數值,由于個人信用的各指標變量是以不同尺度測量的.因此需要通過最小—最大規范化法對原始數據中的定性指標進行線性轉換,使之落在區間[0,1]內[2],即:

本文指標中借貸者的年齡、貸款時間、貸款金額三個屬性值都近似服從正態分布,因此可以利用正態分布函數對這些指標的屬性值進行轉換,使其規范在(0,10)區間內,正態分布的概率密度函數為:
將其進行標準化得到標準正態分布函數為:
運用R軟件構建標準正態函數即可得到變換后的新屬性值,組成本文的實驗數據樣本.
1.3 確定訓練樣本和測試樣本
本文將所有樣本分為訓練樣本和測試樣本兩部分,并按0.8∶0.2的比例設置隨機數種子,以有放回抽樣的方式得到訓練樣本的樣本數為822個,測試樣本的樣本數為178個.
2 隨機森林模型
2.1 隨機森林算法
本文采用的隨機森林模型(Random Forest)是一種基于的決策樹(CART)分類器和Bootstrap抽樣的組合算法.由于信用貸款樣本數據集中的指標變量都是獨立同分布的,故采用Gini系數作為決策樹停止生長的指標[3]:
Gini=1-∑(P(i)*P(i))
P(i)為當前節點上樣本中第i類樣本的比例.類別分布越平均,Gini值越大,類分布越不均勻,Gini值就越小.
應用Bootstrap Sampling自助法在訓練樣本中有放回地隨機抽取k個樣本,組成k棵決策樹,因此每個樣本未被抽到的概率為:
p=(1-1/n)n
此時約有37% 的樣本不會出現在訓練樣本中,這些未被抽取的樣本就被稱為袋外數據(Out-Of-Bag,OOB),主要用于計算單棵決策樹的預測誤差;
隨機森林采用簡單多數投票原則作為其組合規則最終的分類結果:
式中I(·)表示示性函數,mg(x,y)函數衡量分類器集將樣本x分到正確類別的平均票數u1與將x分到其他錯誤類別的平均票數u2之間的差.一般來說,mg(x,y)的值越大,隨機森林模型預測效果就越準確.
2.2 隨機森林模型參數的確定
本文的隨機森林模型在R環境中運行,因此需要對模型參數進行調整,使誤差率達到最小.ntree (隨機森林中樹的數目)、mtry (節點處供選擇特征的數目)是眾多參數中對模型影響最大的參數[4].一般來說,ntree的值越大,模型的誤差就越小,在達到某一固定值后誤差不再變化.因此本文先對mtry值進行調整,先設定ntree=1000,接著再對ntree的值進行調整,求得最優解,以減少模型的迭代次數,提高泛化能力.
(1)mtry值的確定
隨機森林的分類模型中參數mtry指決策樹的變量個數,一般默認取樣本數據中變量個數的二分之一次方,由于本文的指標變量共20個,故以客戶信用分類屬性值為因變量迭代20次,并計算每次迭代的平均誤差率,最后得到不同mtry值下的平均誤差趨勢圖1.
從圖1中可以看出,模型平均誤差率隨著mtry的值增大而減少,最終當mtry=12時平均誤差達到最低點,故取mtry=12為最優的單棵決策樹變量個數.
(2)ntree值的確定
參數ntree是指隨機森林模型中決策樹的數目,根據上文的論述,ntree的值越大越好,故先設定ntree的初始值為1000,mtry值為12進行迭代,得到隨機模型的誤差率與ntree值的關系,如圖2所示:
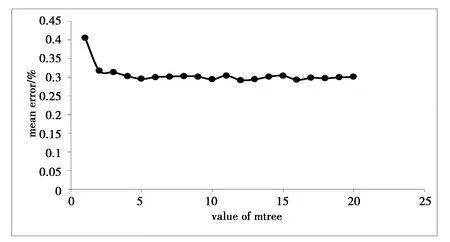
圖1 模型誤差率與mtry值趨勢
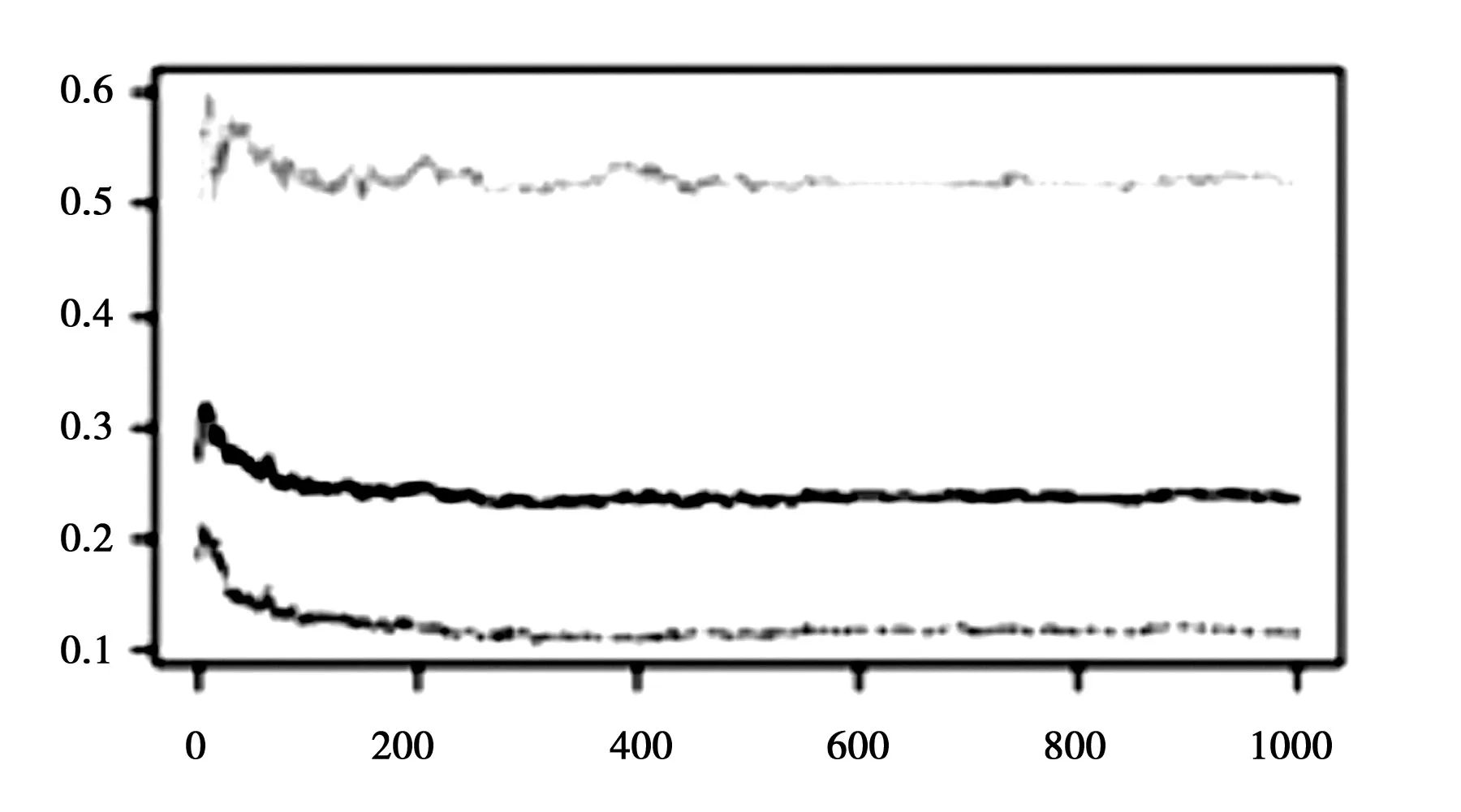
圖2 模型誤差率與ntree值趨勢
圖2顯示當mtry=12時,隨機森林模型的誤差率隨著ntree的增大而減小,當ntree值為400,誤差穩定在10%左右.故ntree=400,mtry=12為該隨機森林模型的最優參數解.
2.3 隨機森林模型的優化
將隨機森林模型的最優解代入模型后運用訓練樣本對模型進行優化.其中錯判率定義為模型將i類樣本錯判給j類的個數占該類樣本總數的比率.得到訓練樣本的錯判矩陣如表1.

表2 訓練樣本下模型錯判矩陣
表1中客戶的貸款分類良好和不良兩種.從表2中可以看出,在訓練樣本中,屬于良好類的樣本有576個,不良類樣本有256個.其中,在良好類的樣本中錯判率為11.28%,不良類樣本的錯判率為52.85%,模型總的分類準確率為76.28%
2.4 隨機森林模型的評估
利用測試樣本對訓練后的隨機森林模型進行評估,并與測試樣本中客戶貸款狀態已分類的結果進行對比,計算模型的預測準確率,如表2所示:

表3 測試樣本下模型錯判矩陣
表2中良好類貸款的錯判率為18.38%,不良類的錯判率為30.95%,得到最終模型的準確率為78.65%.對比測試樣本,模型對不良客戶貸款的分類準確率有了顯著增加.同時隨機森林模型的預測準確率有所增加,表明模型具有較強的泛化能力.
2.5 各指標(特征)變量重要性度量
特征變量重要性測度定義為OOB數據中某個特征變量值發生輕微擾動后的模型分類正確率與擾動前分類正確率的平均減少量.本文采用平均精度下降(Mean Decrease Accuracy)方法給各指標變量的重要性進行評分[5]:
(1)對于每棵決策樹,利用OOB數據進行驗證,將OOB數據的預測誤差記錄下來,每棵樹的誤差為:
err1,err2,err3,…errn
(2)隨機變換OOB數據中的每個特征變量(即人工加入噪聲干擾),從而形成新的袋外數據,再利用袋外數據進行驗證,則每個變量的OOB準確率為:
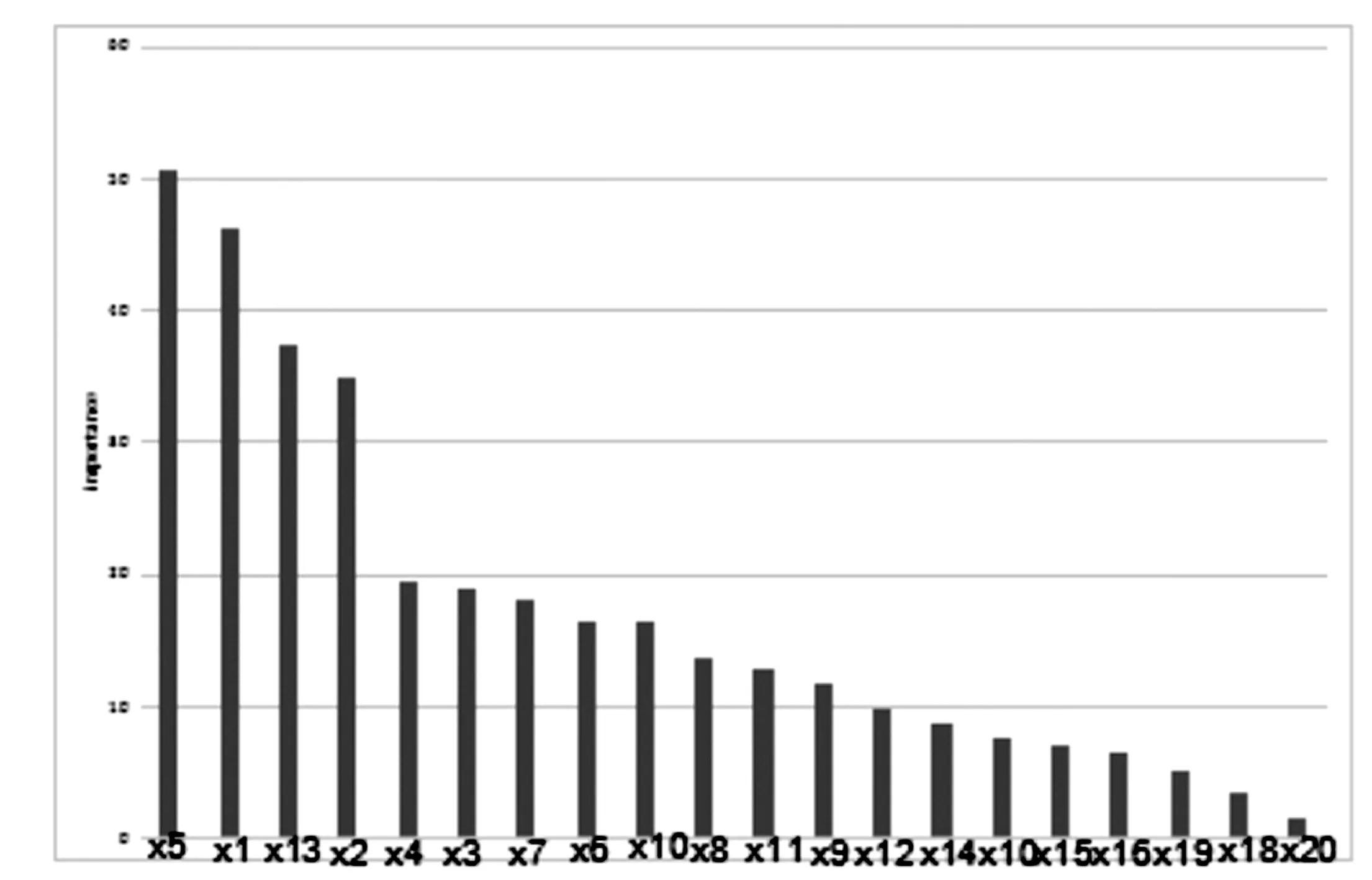
圖3 特征變量重要性評分降序
從圖3中可以看出,借貸者的貸款總額,年齡,目前的賬戶的狀態,貸款期限對客戶貸款的分類精確率有顯著影響.同時借貸者是否有電話注冊,需要撫養的人數和是否為國外工作人員則對分類準確率的影響較小,可以忽略不計.
3 結 論
隨機森林模型是一種基于單棵分類樹的組合算法.該算法對變量的多元共線性不敏感以及對缺失數據比較穩定,可以很好地應用到具有幾千個解釋變量的數據集合中.模型隨機選擇特征對分支進行屬性分裂,使模型不僅具有良好的分類效果,而且能夠對數據中存在的噪聲問題有較好的容忍能力.本文的隨機森林模型對德國個人信貸數據進行的實證研究,得到了較高的預測準確率和泛化性能.同時對特征變量評分得到的結論具有一定的參考價值.
[1]http://archive.ics.uci.edu/ml/machine-leaming_databases/statlog/german/[EB/OL].
[2]張建.商業銀行個人信用評估模型研究[D].廣西大學,2012.
[3]基于Logistic和神經網絡的個人信用評估組合模型研究[D].電子科技大學,2012.
[4]蕭超武,蔡文學,黃曉宇,等.基于隨機森林的個人信用評估模型研究及實證分析[J].2014(06):111-113.
[5]林成德,彭國蘭.隨機森林在企業信用評估指標體系確定中的應用[J].2007(2):200-203.
[責任編輯:王軍]
The research of data mining in personal credit evaluation
TAO Chao1,LI Chao1,LI Jie1,ZHAO Qian2
(1.Institute of Statistics and Applied Mathematics,Anhui University of Finance and Economics,Bengbu 233030,China;2.Institute of Finance and Public Management,Anhui University of Finance and Economics,Bengbu 233030,China)
Personal credit assessment is the core of modern commercial bank personal credit management.In this paper,the Random Forest algorithm in data mining (the Random Forest,RF) apply to the modern personal credit evaluation model,realized step by step optimization and evaluation.Empirical analysis proves that the result of the random forest model has high accuracy and generalization ability,and can overcome the influence of the noise data.Through to the importance of each feature variables score,loan time limit and the total accuracy of risk prediction has a significant effect.
random forests; characteristics of the variable; personal credit assessment; R software
2016-03-11
國家社會科學基金“代際轉移視角下縮小我國收入差距的路徑與仿真模擬研究” (11CTJ006)資助項目
李超(1980-),男,安徽合肥人,安徽財經大學副教授,博士,碩士生導師,主要從事宏觀經濟統計分析、綜合評價方法與應用的研究.
F832.332
A
1672-3600(2016)12-0012-04
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
