基于集成核可預測元分析的非線性故障檢測
2016-11-22 09:09:49宋新建楊煜普
化工自動化及儀表 2016年9期
宋新建 鐘 純 李 楠 楊煜普
(上海交通大學電子信息與電氣工程學院,上海 200240)
基于集成核可預測元分析的非線性故障檢測
宋新建 鐘 純 李 楠 楊煜普
(上海交通大學電子信息與電氣工程學院,上海 200240)
以核可預測元分析(KForeCA)為例,將它與集成學習方法相結合,提出了一種基于集成核可預測元分析(EKForeCA)的非線性故障檢測方法。給出EKForeCA的故障檢測原理。TE仿真實驗結果表明:基于EKForeCA的故障檢測方法可有效提高故障檢測靈敏度和魯棒性。
非線性故障檢測 核可預測元分析 集成學習方法 統計量
近年來,現代工業過程逐漸趨向于規模化和復雜化,因此工業過程的安全性和可靠性越來越受到人們的關注。隨著測量技術的不斷發展,工業過程中的大量過程變量被保存下來,為此基于數據驅動的故障檢測技術在工業過程中得到了廣泛應用[1~3]。
作為一種傳統的多元統計故障檢測方法,主元分析法(PCA)假設數據服從高斯分布,并且數據變量之間線性相關。然而實際的工業過程數據是有限的,常表現出一定的非高斯性,且不同的工業過程數據具有不同的非線性特征,因此PCA方法在實際應用中存在一定的缺陷[4~6]。核可預測元分析(KForeCA)方法作為一種新興的數據特征提取方法,考慮了數據之間的時序相關性,能夠提取具有動態時序特性和可預測性的數據特征,同時又引入了非線性核函數,能夠將低維空間中的數據通過非線性映射投影到高維空間,因此可以很好地處理非線性的過程數據[7,8]。其中,核函數的選擇非常關鍵,這直接影響了該方法提取非線性信息的能力,進而影響故障檢測的效果[9,10]。對于核函數的選擇,一般的方法是根據經驗選擇一個核函數并確定核函數的參數,這具有一定的盲目性,很難在故障信息未知的情況下獲取合適的核參數,而且即便是對于同一個核函數,不同的故障可能在不同的核參數下具有不同的檢測性能[11]。針對該問題,筆者將集成學習方法與KForeCA相結合,提出一種基于集成核可預測元分析(EKForeCA)的非線性故障檢測方法,以提高故障檢測率,增強過程檢測魯棒性。
1 KForeCA
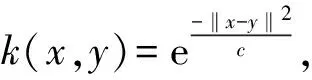
將低維非線性空間的數據映射到線性高維空間后,對高維空間中的數據進行標準化處理。則特征空間F的協方差矩陣ΣF為:
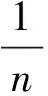
Ki,j=k(xi,xj)=〈Φ(xi),Φ(xj)〉
計算出核矩陣后,對Φ(xi)進行去中心化處理,得到:
(1)
由式(1)可以得出,去中心化后的核矩陣為:
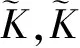
H=[α1,α2,…,αp]
Λ=diag(λ1,λ2,…,λp),λ1≥λ2≥…≥λp
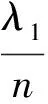
其中,U是經過非線性核映射和白化處理得到的數據,滿足E(UUT)=1,U∈Rp。
獲得U后,利用ForeCA方法對U進行處理,提取可預測元。ForeCA的基本原理是找到一個線性變換矩陣WT∈Rp×m,使得S=WTU,其中S為得分矩陣,W為負荷矩陣,其列向量為負載向量,且兩兩正交。W的求取可以轉換為求解最優化問題,即:
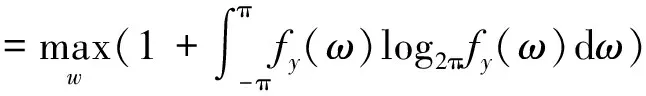
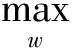
s.t.wTΣUw=1
其中,SU(ω)表示多變量平穩過程的譜密度,ΨU(k)表示自協方差函數,ΣU表示協方差矩陣。

構建KForeCA的過程統計量L2和SPE:
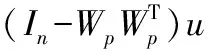
(2)
其中,L2是通過可預測主元模的變化來反映系統趨勢變化的統計量;SPE統計量是觀測數據到可預測模型空間的距離,反映測量值與可預測模型之間的偏離程度。
2 基于EKForeCA的故障檢測
針對KForeCA方法在核函數和核參數選擇方面存在的不足,筆者將KForeCA與集成學習方法[13,14]相結合,提出一種基于EKForeCA的故障檢測方法。EKForeCA方法選取一系列的高斯核函數進行集成學習,得到多個KForeCA訓練子模型,然后利用貝葉斯推理將子模型的檢測結果轉換成故障概率,通過加權策略突出故障信息,提高故障檢測性能。
EKForeCA方法選用的一系列具有不同帶寬參數的高斯核函數為:
其中,核函數序號ci=2i-1rmσ2,i=1,…,ns。
然后利用這些核函數分別構造不同的KForeCA子模型,根據式(2)為每一個KForeCA子模型分別構建L2(i)和SPE(i)統計量:
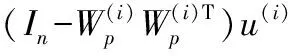
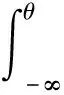
利用貝葉斯推理把每個子模型中已導出的傳統檢測統計量的數值轉換為故障概率,分別為:
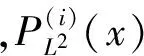
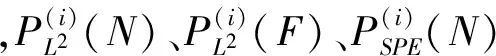
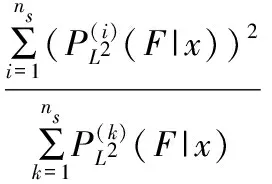
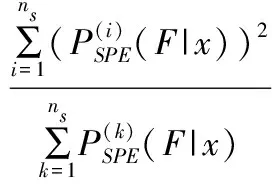
統計量EL2和ESPE的控制限同樣可以通過選取合適的置信水平并利用核密度估計方法獲得。當兩個統計量均未超出各自的控制限時,判定檢測過程處于正常狀態;當任一統計量超出控制限時,則判定為出現故障,觸發故障警報。
3 Tennessee Eastman過程仿真與結果分析
Tennessee Eastman(TE)模型是一個基于實際化工反應過程的基準模型[16],其過程變量之間具有很強的耦合、非線性及時變等特點,被廣泛用于評估過程檢測技術。TE過程有41個測量變量(包括22個連續變量和19個成分變量)和12個操作變量。TE仿真模型共預設了21個故障,具體見表1。
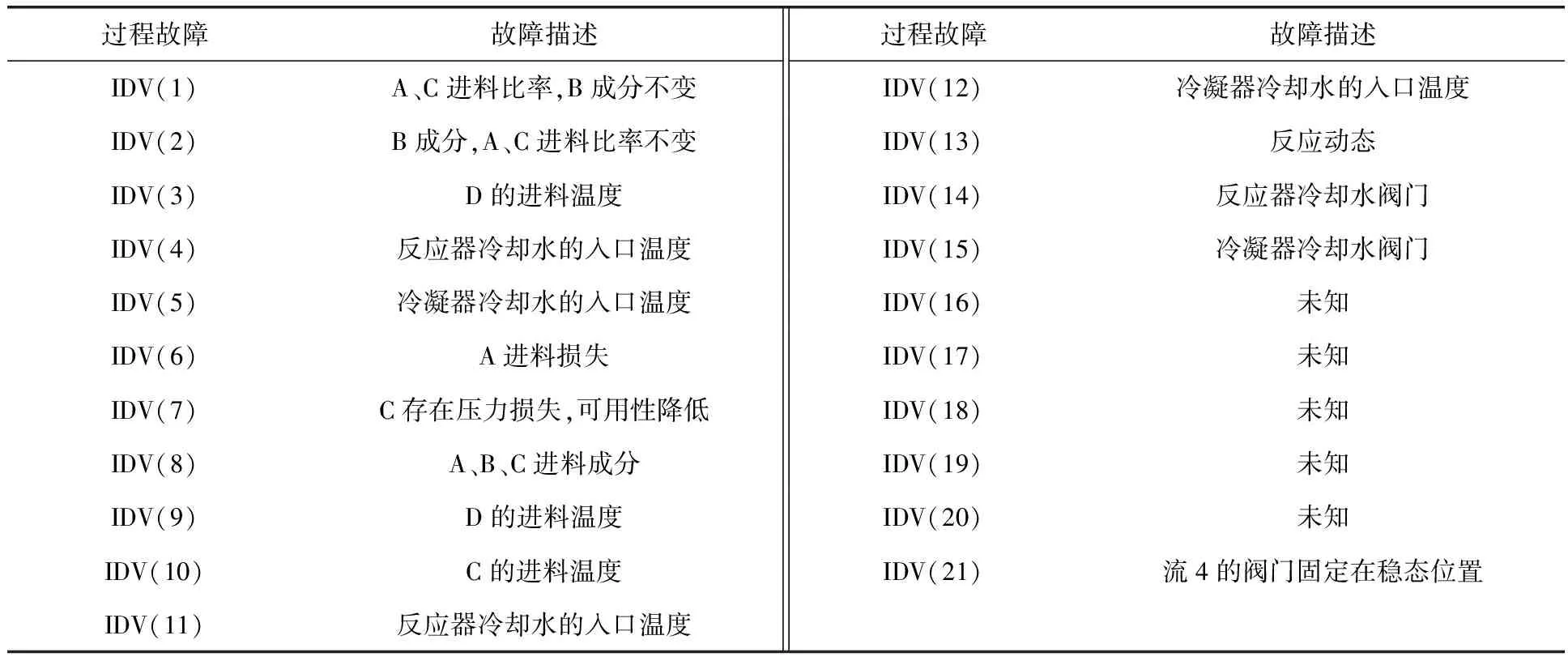
表1 TE仿真模型的過程故障
筆者選取TE仿真模型中的22個連續變量和11個操作變量作為被檢測的變量,選取500個運行在正常狀態下的數據作為訓練數據集,每一個故障測試分別選用960個樣本構造測試數據集,且每一個過程故障都是在第161個采樣時刻被引入。
高斯核函數的帶寬參數通常根據經驗公式選擇,即c=2i·5m,i=1,2,…,10。TE模型仿真實驗分別測試了i=4、i=8時的KForeCA模型與EKForeCA模型對于TE過程21個故障的檢測率,結果見表2。其中,L2和EL2分別反映單個KForeCA模型與EKForeCA模型的系統變化趨勢,SPE和ESPE分別表示觀測數據到可預測模型空間KForeCA與EKForeCA的距離。
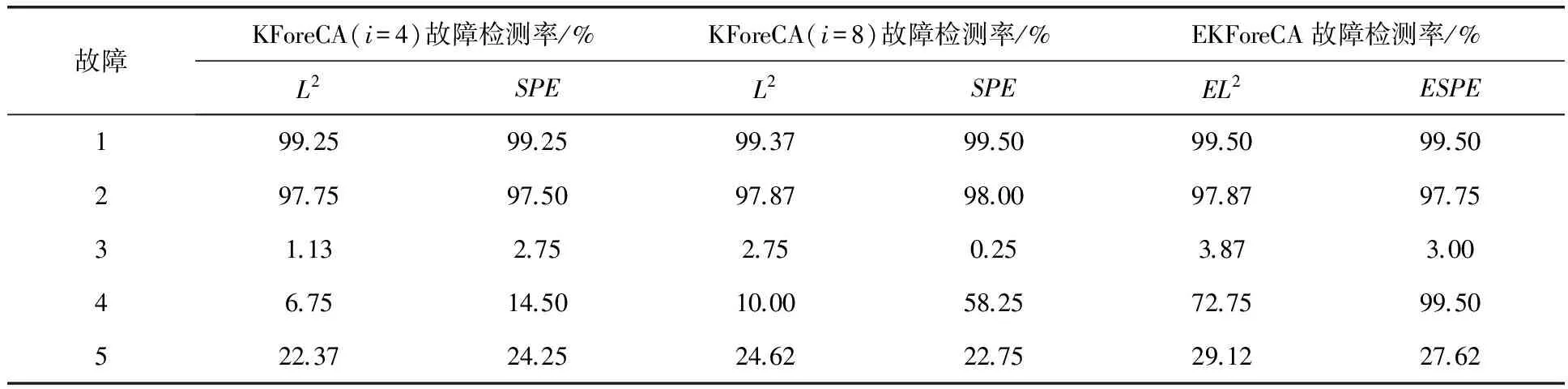
表2 KForeCA、EKForeCA模型對21個故障的檢測結果
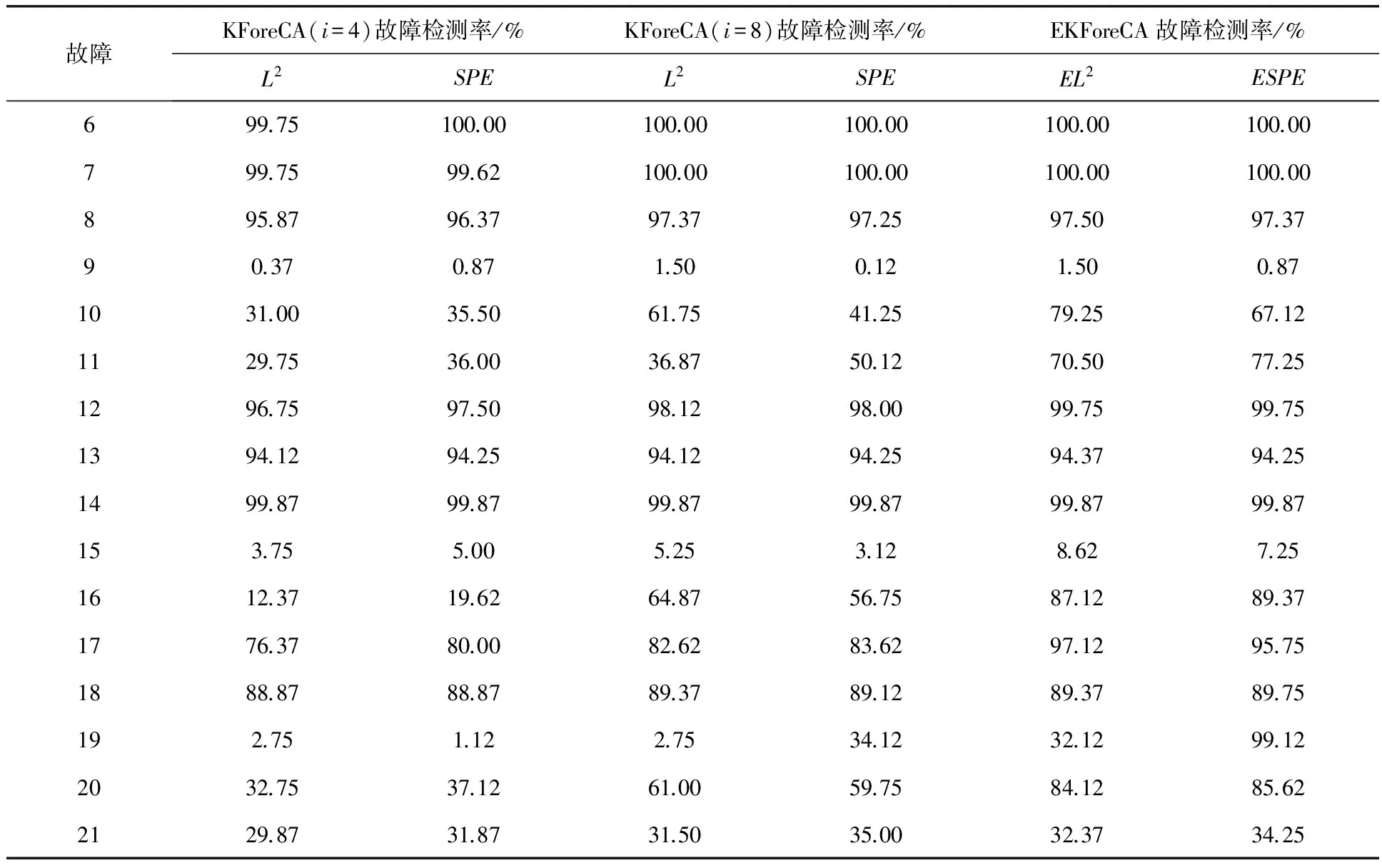
(續表2)
分析表2中的數據可以發現,通過對核函數的集成學習,對于大部分過程故障,EKForeCA基本都能檢測出故障的發生與傳播,尤其對于故障4、10、11、16、20,其故障檢測率得到了顯著提升。下面結合故障4和故障16的仿真實驗結果進行具體分析。
KForeCA和EKForeCA對故障4的檢測結果如圖1所示。可以看出,無論是EL2統計量還是ESPE統計量,相比于單個核函數的KForeCA子模型,EKForeCA的檢測效果均得到了極大提升。幾乎在整個檢測周期內,ESPE統計量都能以非常高的靈敏度將故障檢測出來。
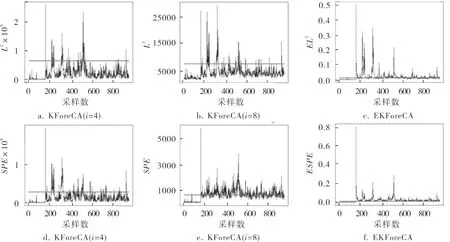
圖1 KForeCA和EKForeCA對故障4的檢測結果
由表1可知,故障16是一種未知故障,對未知故障的檢測效果可以體現出集成核學習方法在故障檢測領域中的推廣應用能力。KForeCA和EKForeCA對故障16的檢測結果如圖2所示,可以看出,L2、SPE統計量在采樣區間內的檢測效果都不是很理想,不同核參數下的檢測效果也有很大差異,而基于集成核學習方法的EL2和ESPE統計量基本都能夠檢測出區間內的絕大部分故障,其檢測靈敏度明顯優于基于單個核函數的L2和SPE統計量。
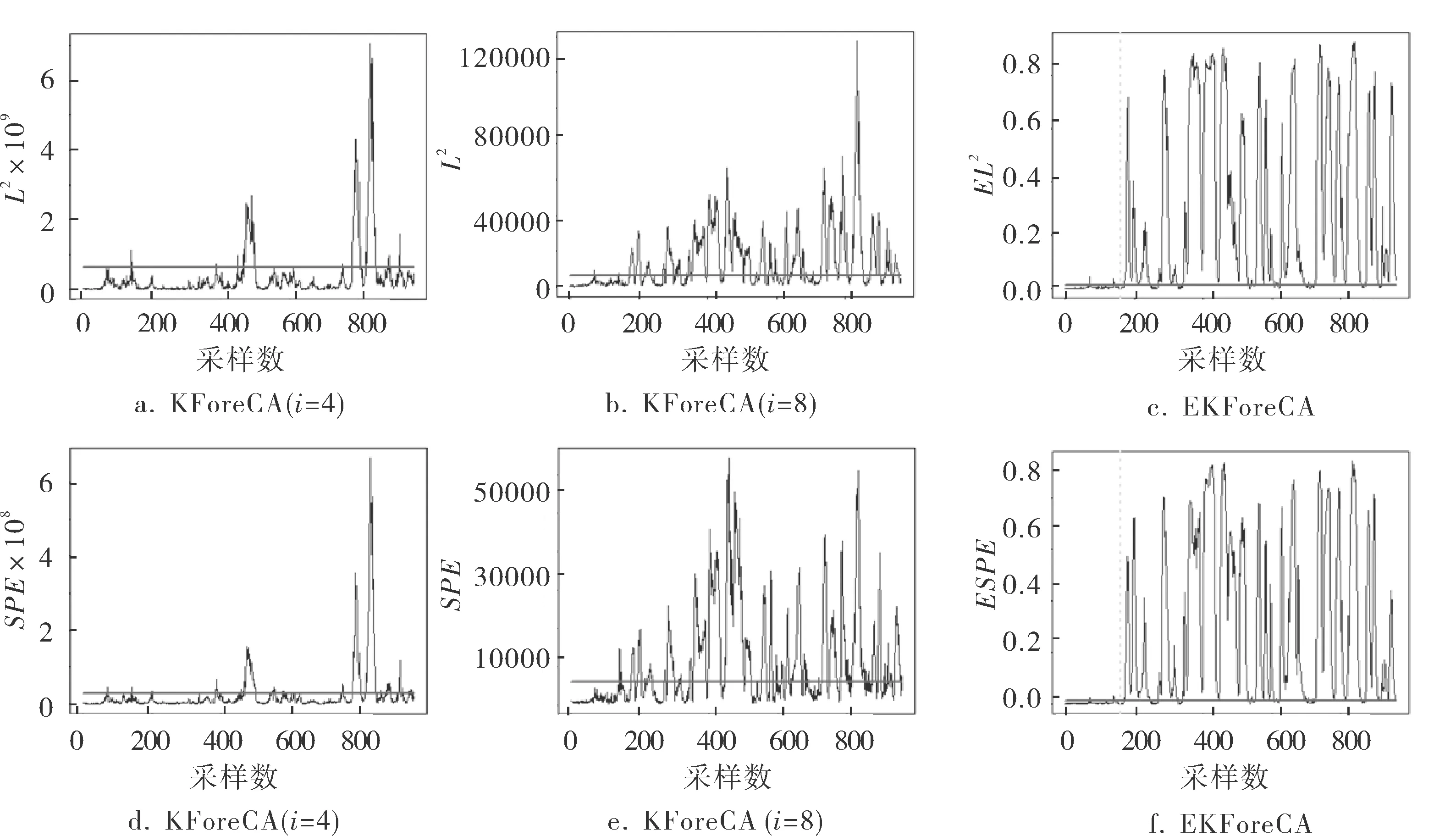
圖2 KForeCA和EKForeCA對故障16的檢測結果
4 結束語
筆者針對核學習方法中核函數參數選擇存在的問題,利用集成學習的思想,以KForeCA為例,將它與集成學習方法相結合,對一系列的核函數進行集成學習,訓練得到若干不同的KForeCA子模型,利用貝葉斯推理將各個子模型的檢測結果轉換成故障概率,并通過加權策略突出故障信息,進而提高過程檢測性能。通過對核函數的集成學習,避免了盲目選擇單個核函數對檢測性能的不利影響,提高了過程檢測魯棒性。TE仿真模型的實驗結果表明,與基于單個核函數的KForeCA模型的故障檢測方法相比,基于集成核學習的EKForeCA故障檢測模型顯著提高了過程檢測性能。因此,基于集成核學習方法的故障檢測方法在非線性過程檢測領域具備一定的研究潛力與應用價值。
[1] 李晗,蕭德云.基于數據驅動的故障診斷方法綜述[J].控制與決策,2011,26(1):1~9.
[2] 周東華,胡艷艷.動態系統的故障診斷技術[J].自動化學報,2009,35(6):748~758.
[3] 赫偉英,裴峻峰.往復機械故障診斷技術進展綜述[J].化工機械,2010,37(5):671~674.
[4] Jiang Q,Yan X,Huang B.Performance-Driven Distributed PCA Process Monitoring Based on Fault-Relevant Variable Selection and Bayesian Inference[J].IEEE Transactions on Industrial Electronics,2016,63(1):377~386.
[5] Ge Z,Song Z,Gao F.Review of Recent Research on Data-Based Process Monitoring[J].Industrial & Engineering Chemistry Research,2013,52(10):3543~3562.
[6] 王迎,王新明,趙小強.基于小波去噪與KPCA的TE過程故障檢測研究[J].化工機械,2011,38(1):49~53.
[7] Goerg G.Forecastable Component Analysis[C].The 30th International Conference on Machine Learning.Atlanta:ICML, 2013:64~72.
[8] 林圣才,楊煜普,屈衛東.一種基于可預測元分析的故障診斷方法[J].化工自動化及儀表,2015,42(3):272~276.
[9] Lee J M,Yoo C K,Sang W C,et al.Nonlinear Process Monitoring Using Kernel Principal Component Analysis[J].Chemical Engineering Science,2004,59(1):223~234.
[10] Cho J H,Lee J M,Sang W C,et al.Fault Identification for Process Monitoring Using Kernel Principal Component Analysis[J].Chemical Engineering Science,2005,60(1):279~288.
[11] Li N,Yang Y.Ensemble Kernel Principal Component Analysis for Improved Nonlinear Process Monitoring[J]. Industrial & Engineering Chemistry Research,2015,54(1):318~329.
[12] Sang W C,Lee C,Lee J M,et al.Fault Detection and Identification of Nonlinear Processes Based on Kernel PCA[J]. Chemometrics & Intelligent Laboratory Systems,2005,75(1):55~67.
[13] Banfield R E,Hall L O,Bowyer K W,et al.A Comparison of Decision Tree Ensemble Creation Techniques[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2007,29(1):173~180.
[14] Polikar R.Ensemble Based Systems in Decision Making[J].IEEE Circuit Systems Magazine,2006,6(3):21~45.
[15] Chen Q,Kruger U,Meronk M,et al.Synthesis ofT2,andQ,Statistics for Process Monitoring[J].Control Engineering Practice,2004,12(6):745~755.
[16] Downs J J,Vogel E F.A Plant-Wide Industrial Process Control Problem[J].Computers & Chemical Engineering,1993, 17(3):245~255.
NonlinearFaultDetectionBasedonEnsembleKernelForecastableComponentAnalysis
SONG Xin-jian, ZHONG Chun, LI Nan, YANG Yu-pu
(CollegeofElectronicInformationandElectricalEngineering,ShanghaiJiaotongUniversity,Shanghai200240,China)
Taking KForeCA(Ensemble Kernel Forecastable Component Analysis)as an example, having it combined with ensemble learning and KForeCA based to put forward the nonlinear fault detection method was implemented, including the presentation of EKForeCA fault detection principle. The TE simulation results show that, that the EKForeCA-based nonlinear fault detection method can improve the sensitivity of fault detection effectively and the robustness.
nonlinear fault detection, KForeCA, ensemble learning method, statistics
TH165+.3
A
1000-3932(2016)09-0917-06
2016-02-25(修改稿)
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年6期)2015-04-17 03:31:50
