基于文獻計量的我國檔案領域大數據研究現狀分析
2016-11-22 01:14:21曹培培
山東檔案 2016年5期
文?曹培培
基于文獻計量的我國檔案領域大數據研究現狀分析
文?曹培培
近年來,大數據研究成為檔案領域的研究熱點。文章以CNKI中國學術期刊
檔案;大數據;高頻關鍵詞;共詞分析;聚類分析
隨著移動互聯網、物聯網和云計算技術時代的到來,人們在日常學習、生活、工作中產生的互聯網數據量正以指數形式增長,呈現“爆炸”狀態,大數據問題在這樣的時代背景下應運而生。那么,究竟什么是大數據呢?麥肯錫將其定義為無法在一定時間內用傳統數據庫軟件工具對其內容進行抓取、管理和處理的數據集合[1]。綜合來看,大數據具有規模大、種類多、生成速度快、價值巨大但密度低的特點。因此,隨著大數據時代的到來,如何將巨大的原始數據進行有效地利用和分析,使之轉變成可以被利用的知識和價值,成為國內外國家政治領域、科研學術界和相關產業界共同關注的熱門話題。在學術界,《Nature》于2008年推出大數據專刊,這應該是“大數據”一詞開始得到業界肯定和接受的開端。隨后,其滲透的領域不斷蔓延,大數據逐步成為國內外學術界眾多學科領域關注的研究熱點。當然,檔案領域也不例外。從2013年起,我國檔案界的學者對大數據的研究關注逐年大幅度遞增。隨著研究的進一步深入,有必要對目前國內檔案領域對大數據的研究現狀進行一下梳理,分析當前的主要研究熱點,為大數據在檔案界實現更高層次的融合提供一些借鑒。
一、數據來源與研究方法
(一)數據來源
(二)研究方法
本文借助Excel數據透視表對我國檔案領域大數據研究文獻的發表時間、著者、來源、關鍵詞進行了相關統計和分析;采用共詞分析法,運用SATI3.2軟件統計了高頻關鍵詞,并構建了高頻關鍵詞共現矩陣和相關矩陣,然后借助Spss19.0軟件對文獻的高頻關鍵詞了進行聚類分析。本文綜合采用文獻計量方法,以定性與定量相結合,統計分析出我國檔案領域大數據研究現狀與熱點。
二、國內檔案領域大數據研究文獻計量分析
(一)文獻發表時間分析
衡量某學科研究領域發展的重要指標就是研究論文數量的變化,統計文獻數量并繪制相應的年度增長曲線,對于評價該研究領域所處階段,預測其發展態勢起著重要的作用。在對我國檔案領域大數據研究文獻進行發表時間分析時,可以通過文獻年度發表數量,總結出我國檔案領域大數據研究的發展趨勢。將Excel表格里的414篇文獻對年度發文數量利用數據透視表進行統計,得出圖1趨勢圖。雖然大數據研究萌芽很久,但其技術優勢得到廣泛認可是在2012 年,2013 年大數據得到進一步普及,成為眾多學科和領域的研究焦點。因此,不難解釋圖中2013以前我國檔案領域對大數據的研究寥寥無幾,而在2013年學界對它有所關注。而且,最近幾年隨著大數據熱的進一步蔓延,檔案領域對它的研究也如火如荼,呈雨后春筍般的研究增長態勢,2014年相比于2013年出現4倍增長,2015年熱度持續,發文數量達到250篇。通過對圖1趨勢圖的分析可得,未來一段時間,大數據仍會是我國檔案領域的研究重點與熱點。
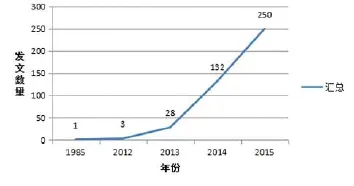
圖1 我國檔案領域大數據文獻數量年份分布
(二)文獻著者分析
通過對文獻著者分析,我們可以發現此研究領域的核心帶頭人物,發現有代表性的研究前沿和學術水平。通過統計,我國共有562位學者進行過檔案領域大數據方面的相關研究,其中發文數量不小于2 篇的有45位,有11位著者發表3篇及以上學術期刊論文,如表1所示(主要展示了發文量在3篇及以上的作者)。根據洛特卡定律的公式f(x) =f(1)/x2(其中f(x)為寫了x篇論文的著者數量,f(1)為寫了1 篇論文的著者數量)可知,寫一篇論文的著者占全部著者總體比例的60%左右[2]。但根據我國檔案領域大數據方面研究文獻的統計數據(表2),只發表過一篇期刊論文的作者數高達92%,此比例遠遠大于洛特卡定律公式推導出來的60%。根據統計結果,我們可以發現,韓海濤、田偉等學者對大數據在檔案領域的滲透興趣顯著,為推動此領域學術水平的發展做出了自己的貢獻。但除此以外,我們更遺憾地是,我國檔案領域對大數據方面的相關研究還遠不成熟。大部分學者僅是借大數據的熱背景,臨時為自己的文章增添色彩,對大數據給檔案帶來的方方面面的影響,只是做到了淺嘗輒止,研究的持續關注性有待進一步提高。當然,我們也需要反思,大數據在檔案界的滲透,只是在迎合時代潮流,還是其發展確實會給檔案帶來全新的思維和技術方式。
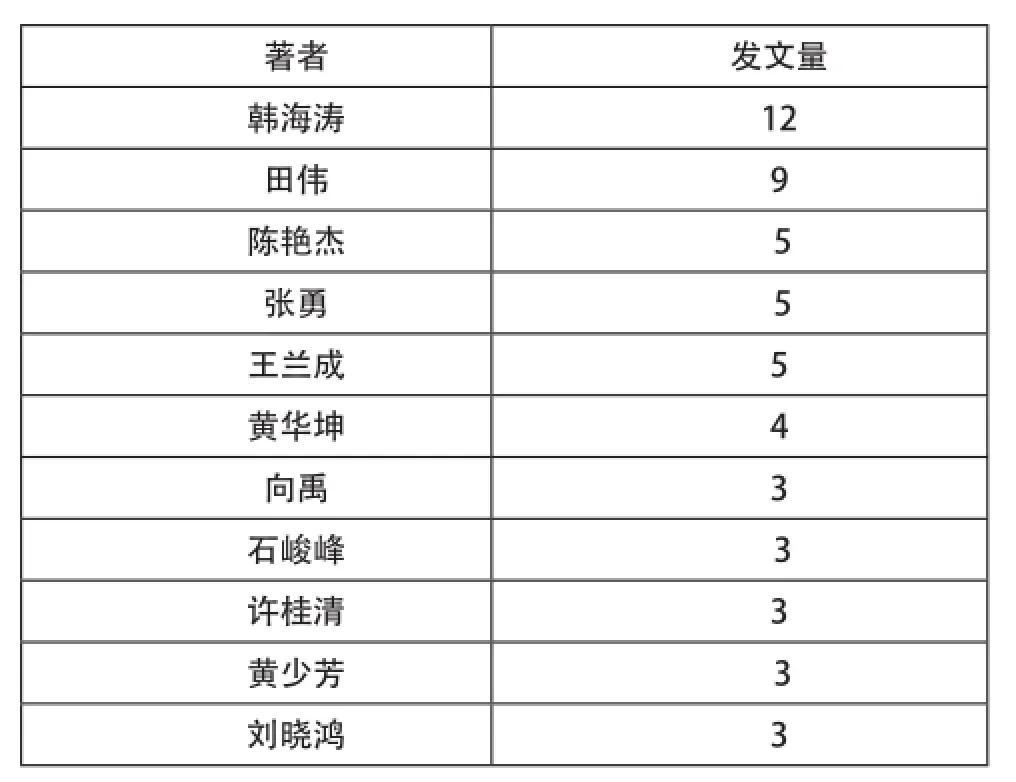
表1 我國檔案領域大數據研究主要著者
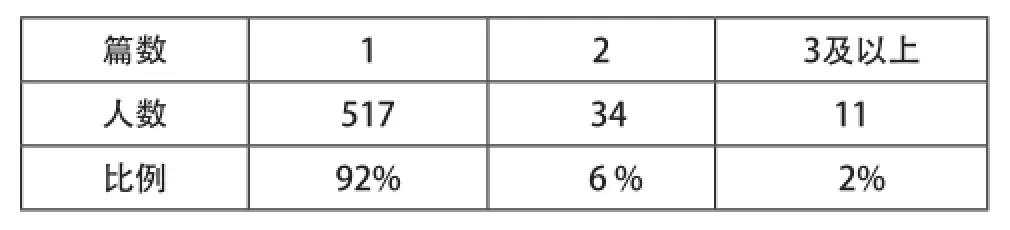
表2 發文篇數人數統計及所占比例
同時,在核心著者方面,根據普萊斯定律,核心作者應該完成所有專業論文總和的一半,寫作m=0.749(n max)0.5篇以上論文的著者為核心著者,其中nmax為最高產著者的發文數[3]。根據表1,目前我國檔案領域大數據研究的最高產著者的發文總量是12,計算得出m為4.49,取近似值5,即我國該領域核心作者最低發文量應為5篇。根據表1的統計數據可知,發文量5篇及以上的作者(即核心作者)僅有5人。這些數據表明,在我國檔案領域,至今仍未形成對大數據相關研究的穩定的核心作者,研究力量相對薄弱且分散。
(三)文獻期刊來源分析
相關研究領域期刊發文數量,代表了此期刊對某研究領域的關注度和研究水平。通過對414篇文獻期刊來源進行統計,共發現141種期刊發表過關于檔案領域大數據方面研究的文章。其中,刊載篇數僅有一篇的期刊有89種,占總期刊數的63%,載文量在10篇及以上的有7種期刊,僅占總期刊種類數量的5%。可見,檔案領域對大數據的關注還不是特別集中。截取載文量在10篇及以上的來源期刊進行分析(如表3)發現,對此研究領域的刊物集中分布在檔案方向,學科交叉性很弱。同時,在7個發文量為10篇以上的期刊中,有4個核心期刊,其載文量不相上下,基本都在15篇左右。但與載文量最多的期刊的相比,數量上的差距有2倍之多。
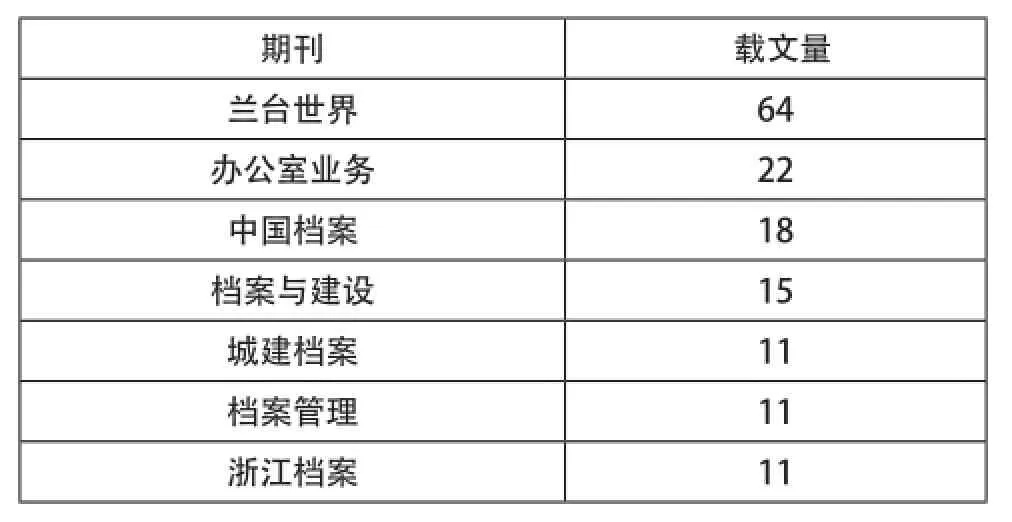
表3 我國檔案領域大數據研究來源期刊
(四)關鍵詞分析
通常一篇論文的關鍵詞可以反映出其學科主題和關注點,而對此研究領域的眾多相關文獻進行關鍵詞分析,可以發現此領域的研究熱點。利用Excel對414篇文獻的關鍵詞進行統計,共得出1221個。頻次為1的關鍵詞共有970個,占全部關鍵詞的79%;頻次為2的關鍵詞共有124個,占10%;頻次在10個及10個以上的關鍵詞有20個,占2%。由于此研究統計中頻次較低的關鍵詞數量較多,為了減少低頻關鍵詞對研究熱點分析結果的干擾,僅選擇高頻關鍵詞進行分析。截取前20位高頻關鍵詞,如表4所示,除去大數據和檔案不能表明研究熱點的兩個高頻關鍵詞,可以看到,目前在檔案領域對大數據的研究主要集中在檔案管理、檔案數字化、數字檔案館、信息技術、檔案利用等方面。
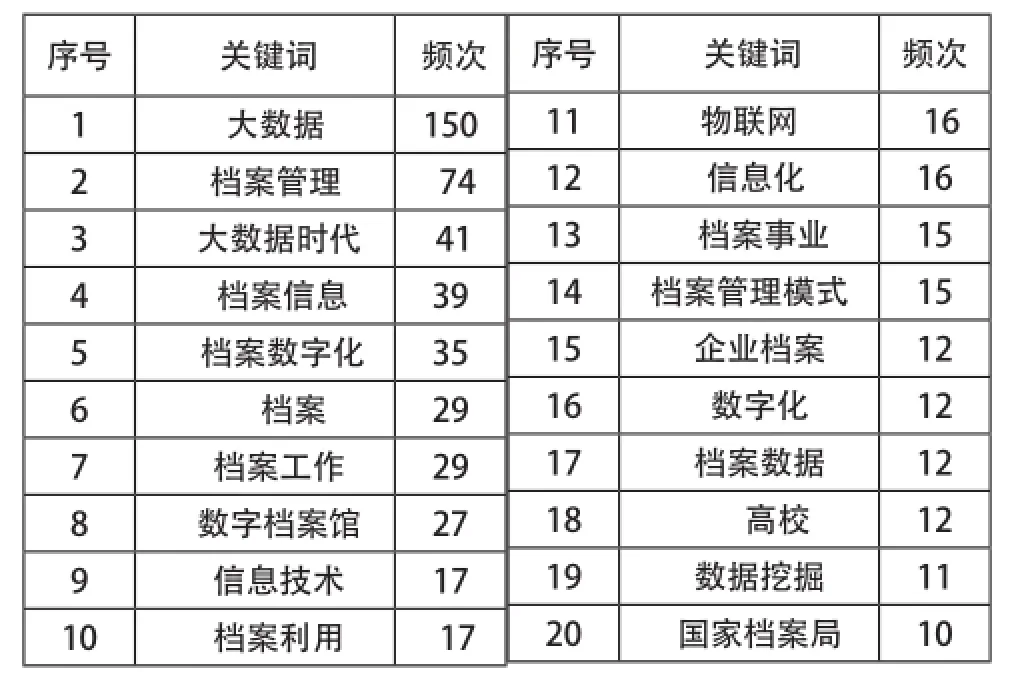
表4 高頻關鍵詞(前20)
雖然高頻關鍵詞可以很好地反映目前檔案領域對大數據的關注熱點,但還不能反映各個關鍵詞在文獻中共現的次數,為此需要對高頻關鍵詞進行共詞分析。根據共詞分析的原理,利用SATI3.2構建高頻關鍵詞共現矩陣,兩兩統計它們在同一篇論文中出現的次數。圖2為截取的檔案領域大數據研究方面的高頻關鍵詞共現矩陣的部分。關鍵詞及其自身的共現頻次為主對角線的數值,而2個不同關鍵詞間的共現頻次則體現在非主對角線上,也是研究的核心對象。兩個關鍵詞共現的頻率越高,說明它們之間的關系越密切。反之,則表明二者關系疏遠。從圖2可以看出,除去必須定義的“大數據”和“檔案”,大數據與檔案管理、檔案信息、檔案數字化、檔案工作、數字檔案館、信息技術、檔案利用等關系密切,由此可以得出,目前檔案領域對大數據的研究熱點主要集中在上述幾個方面。
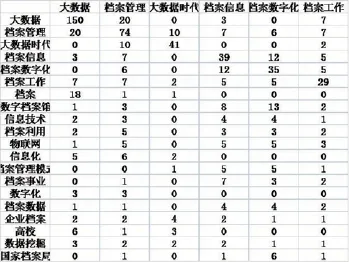
圖2 高頻關鍵詞共現矩陣(部分)
隨后,為了進一步分析高頻關鍵詞之間的親疏遠近關系,需要利用Spss19.0對高頻關鍵詞的相關矩陣進行聚類分析。聚類分析是將一批樣本(或變量)數據根據其諸多特征,按照在性質上的親疏程度在沒有先驗知識的情況下進行自動分類,產生多個分類結果,它可以描述出學科領域的研究主題結構[4]。但是聚類分析是建立在相關矩陣的基礎上,因此,需要再次使用SATI3.2構建高頻關鍵詞的相關矩陣,然后,將得到的相關矩陣導入Spss19.0,在分類中選擇系統聚類,使用Ward法進行聚類分析,最終得到如圖3所示的聚類樹狀圖。縱軸文字和數字代表了表4中的高頻關鍵詞及其位次,橫軸的數字代表了兩個關鍵詞間的相似距離。對聚類樹狀圖進行分析發現,檔案數字化、數字檔案館與國家檔案館關系密切,檔案利用、物聯網、信息技術相關性強,檔案信息、檔案事業、檔案數據組團成為研究特點,大數據、檔案和高校彼此相互聯系,企業檔案、信息挖掘緊緊追隨大數據時代,檔案管理、信息化和檔案工作形成聯系主體,信息管理模式和數字化合為聚類。
領域關于大數據的探討主要集中在期刊載體上,所以,本文以CNKI的中國學術期刊網絡出版總庫為數據源。以“主題”為檢索項,“檔案”+“大數據”為檢索詞,進行“精確”檢索。期刊范圍選取“全部期刊”,以提高檢全率。由于難以確認檔案領域大數據研究的正式起源時間,因此檢索時段沒有設置起始時間。同時2016年的文章不完整,暫時不予分析,確定檢索終止日期為2015年12月31日,共檢出489篇相關文獻。基于數據庫檢索的局限性及學科特點,進一步對數據進行去重、篩選等數據清洗工作,去除會議通知、重復和弱相關文獻,最終保留414篇研究成果。
總庫收錄的檔案領域大數據文獻為研究對象,分別按照文章的年代、著者、來源進行統計分析,并以共詞分析為基礎,利用Spss19.0對文獻的高頻關鍵詞進行聚類分析。由此,總結出我國檔案領域大數據研究的現狀與熱點,以期對國內檔案領域大數據的研究提供有益的參考和借鑒。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
