基于詞間關聯度度量的維吾爾文本自動切分方法
2016-10-12 08:29:58吐爾地托合提維尼拉木沙江艾斯卡爾艾木都拉
北京大學學報(自然科學版) 2016年1期
吐爾地·托合提 維尼拉·木沙江 艾斯卡爾·艾木都拉
?
基于詞間關聯度度量的維吾爾文本自動切分方法
吐爾地·托合提?維尼拉·木沙江 艾斯卡爾·艾木都拉
新疆大學信息科學與工程學院, 烏魯木齊830046; ?E-mail: turdy@xju.edu.cn
提出一種基于詞間關聯度度量的維吾爾文本自動切分方法。該方法從大規模生語料庫中自動獲取維吾爾文單詞Bi-gram及上下文語境信息, 在充分考慮維吾爾文單詞間結合規則的前提下, 將相鄰單詞間的互信息、-測試差及雙詞鄰接對熵的線性融合作為組合統計量(dmd), 度量文本中相鄰單詞之間的關聯程度。以dmd度量的弱關聯的詞間位置作為切分點進行自動切分, 得到語義及結構完整的詞串, 而不僅僅是以空格隔開的單詞。在大規模文本語料上進行的測試表明, 該方法的切分準確率達到88.21%。
語義串; 互信息;-測試差; 鄰接對熵; 單詞結合規則
文本切分是自然語言處理中的第一步, 也是關鍵的一步。采取何種方法及切分難易程度, 在不同語言環境下有所不同, 但最終目的是一樣的, 即從文本中獲取能表達具體、完整語義的語言單元的集合。這些語言單元在很多情況下是突破詞語概念界限的語義串[1–2], 是文本中上下文任意多個連續字符(字或詞)的穩定組合, 是結構穩定不可分割且語義完整的語言單元(如固定搭配、習語、對偶詞等具有詞匯意義和語法意義的模式串[3–4]、詞組或短語[5]、復合詞或領域術語[6]以及命名實體等)。
在文本中, 句子可以表達完整、連貫、易于理解的語義, 而語義串蘊含句子的關鍵信息。因此, 用語義串表示文本, 可以有效地刻畫文本主題[7], 構造泛化能力更強、更緊湊的文本模型[8-9], 從而可以提高相關算法性能及文本處理效率。因此, 如何識別語義串邊界并完整獲取, 已成為文本挖掘領域中的關鍵問題[10–11]。
中文信息處理領域中, 分詞是研究歷史最悠久的問題, 經過多年的研究, 中文分詞已出現多種較成熟的技術和實用分詞工具。但是, “文本海嘯”的到來, 對中文自動分詞研究提出一系列新的課題, 尤其是新詞邊界的正確識別及分詞系統對開放環境的適應性及健壯性的需求日益突出。
作為文本中上下文任意多個連續字符(字或詞)的穩定組合, 語義串是語義及結構完整的語言單元, 其內部結合緊密, 不可分割。因此, 以相鄰漢字之間的結合程度作為切分依據, 或將它作為補充手段來消除歧義, 在中文分詞和新詞識別方法中已起到很好的作用。孫茂松等[12]從大規模生語料中獲取漢字二元信息, 用互信息及-測試差的線性疊加值來衡量相鄰漢字之間的結合能力, 并設計了一種無詞表及無指導學習的自動分詞算法。王思力等[13]用雙字耦合度和-測試差的線性疊加值來消除分詞中的交叉歧義, 但他們是從熟語料中獲取二元模型。費洪曉等[14]分別用-gram、互信息及-測試3種統計量來判斷雙字構成詞的可能性。王芳等[15]用互信息定量估計相鄰兩個基本詞間的結合可信度, 提出一種基于可信度的中文完整詞自動識別方法。何賽克等[16]將字串鄰接變化數(accessor variety)引入基于條件隨機場的中文分詞系統, 提高了分詞系統性能。基于詞典的分詞方法mmseg中, 蔣建洪等[17]用互信息來度量并過濾非鄰接詞, 使分詞系統性能得到提高。
基于上述研究, 本文提出一種基于詞間關聯度度量的維吾爾文本自動切分方法。所提方法接近于孫茂松等[12]和王思力等[13]的研究, 但又有區別。首先, 他們都是用兩種基本統計量的線性融合作為組合統計量, 度量相鄰漢字之間的結合緊密度, 目的是提高現有中文分詞系統的精度。本文引入鄰接對熵(dual adjacent entropy), 并將-測試差(difference of-test)、互信息(mutual information)及鄰接對熵的線性融合作為一個組合統計量dmd, 用以度量相鄰維吾爾文單詞之間的結合緊密程度。本文目的是從已分好詞的單詞序列(以空格隔開的詞序列)中識別出最終的切分邊界, 從而獲取文本中結構及語義完整的語言單元。除此之外, 本文還將維吾爾文不同詞性之間的結合規律作為一種規則, 融入詞間位置判斷中, 以便提高語義串識別精度。
1 維吾爾文分詞及存在的問題
維吾爾文是突厥語族中的一個成員, 又屬于阿爾泰語系, 是一種拼音文字, 具有黏著語特性。從表面上看, 維吾爾文詞在文本中以空格與上下文隔開, 因此, 一直認為維吾爾文中不需要分詞。在各種文本處理中也都以空格作為自然分隔符進行分詞(簡稱空格分詞), 以詞為特征表征文本。
例1 去北京的火車從哪個車站出發?
例1由6個詞組成, 經過詞干復原處理后再進行空格分詞, 對應的中文也經ICTCLAS分詞(省略了功能詞), 得到的詞序列(維吾爾文書寫順序為從右到左)如圖1所示。
從分詞結果上看, 空格分詞對以上句子是有效的, 切分出來的詞都能作為基本的語義單元運用。但對于以下幾個新聞標題, 這種分詞結果幾乎是錯誤的。
例2 科學家研制出禽流感病毒。
例3 首批全國政協委員抵達北京。
例4 奧巴馬連任面臨就業問題挑戰。
例2~4采用空格分詞的結果見圖1。
根據一個詞語的最小語義完整性, 例2應該被分為5個詞語(帶下劃虛線的串), 但是空格分詞把句子分成8個詞。然而, 二詞串②, ④和⑤都是常用實詞, 是兩個單詞的穩定組合, 不可分割。例3中的二詞串①, ③, ⑥和例4中二詞串③, ④, ⑥也都是結構穩定、語義完整的常用實詞, 不能以空格分開提取。
維吾爾文中能表達一個最基本的、具體而完整語義的語言單元, 在很多情況下不僅僅是一個以空格隔開的單詞, 而是它與上下文若干個詞的穩定組合。維吾爾文中能表達一個完整語義或者說在實際語料中能充當一個實詞的串, 可分為以下兩類。
定義1 單詞語義串是一個維吾爾文單詞, 即一個無空格字母串, 語義完整且獨立運用, 可用空格分詞切分得到。比如, 例1中以空格分割的都是單詞語義串。
定義2 多詞語義串是若干個維吾爾文單詞的穩定組合, 并且滿足如下條件: 1)語義完整, 在真實語料中充當一個實詞, 不能以空格分開; 2)結構穩定, 在大規模語料中具有較高的流通度, 是獨立運用的語言單元。
隨著維吾爾文文本挖掘相關領域研究工作的不斷深入及更廣范圍的開展, 空格分詞方法開始暴露出其潛在的缺陷和局限性, 主要表現如下。
1)在維吾爾文Web搜索中, 由于空格分詞沒有考慮切分單元的語義完整性和結構完整性, 因此獲取的單詞難以在文本標引中發揮關鍵詞的作用[18]。另外, 空格分詞還會導致組合歧義及交叉歧義的產生, 并出現低查準率[19–20]。
2)中、英文文本聚類和分類中, 常用詞特征來表征文本, 聚類和分類效果也比較滿意。同樣以詞特征表征文本并用性能最好的學習算法, 維吾爾文文本聚類和分類效果卻遠不及中文和英文[21]。這是因為, 文本中表示關鍵信息的語義串被空格分詞拆分為與其語義完全不符的若干個字母串, 因此不僅不能提取更具有表征能力的文本特征, 反而提高了特征空間的維度, 甚至導致大量冗余、不相關(噪音)甚至類間交叉特征的出現。冗余特征的存在會降低學習算法的效率, 不相關特征(噪音特征)的存在會損害學習算法的性能[22], 類間交叉特征的存在會極大地降低聚類和分類準確率[23]。
除搜索、聚類和分類外, 空格分詞在機器翻譯、主題詞提取、維吾爾人名(名在前姓在后, 以空格隔開)、地名、機構名等命名實體識別以及新詞識別等文本處理過程中也會成為一個瓶頸。
2 詞間關聯度度量
本文的主要思路是, 從第一個單詞開始掃描待處理文本中的詞序列, 并用一個統計量去觀察相鄰單詞間的結合程度。如果>(為閾值), 則保留它們之間“連”的狀態, 否則插入一個分隔符(維吾爾文單詞之間以空格隔開, 因此本文以字符“|”作為分隔符)將它們分開, 這時它們之間是“斷”的狀態。例如, 一個有個單詞的文本的詞序列為123...W–1W...W–1W, 則基于統計量的詞間連、斷判斷如圖2所示。最后以分隔符“|”進行切分, 就得到文本中的所有語義串。其中, 統計量是從大規模生語料中學習計算得出。
本文所用語料都來自網絡和正式出版物, 包括從互聯網收集的人工分類文本(共20類)、新疆日報2008年3和4月份全部內容、出版物8本(有關文學、社會、法制、經濟等)。在實驗和算法驗證中, 我們將大語料分為3個語料庫, 每個語料庫都包含以上大語料中一定比例的內容。1)生語料庫 URC (Uyghur Raw Corpus), 共含維吾爾文單詞及標點9443290個, 未經標注; 2)開發集USC1(Uyghur Segmented Corpus), 共含維吾爾文單詞及標點15708個, 經人工標注; 3)測試集USC2, 共含維吾爾文單詞及標點154411個, 經人工標注(以上語料均由新疆大學智能信息處理重點實驗室提供)。實驗中, 除對文本語料進行詞干提取處理外, 無任何特殊處理和人工干預, 算法所需要的所有統計信息直接從生語料中獲得。
在實驗和算法驗證中, 我們用單詞間的“連”和“斷”的判斷準確率來調整閾值和其他參數, 直到算法給出最好的性能。準確率的定義為
其中,W–1和W是文本中相鄰的詞對, PosCount連(W–1,W)表示正確判斷為“連”的詞間位置數, PosCount斷(W–1,W)表示正確判斷為“斷”的詞間位置數, PosCount(W–1,W)表示被處理文本中所有的詞間位置數。
2.1 基本統計量: 互信息(mi)
在一個維吾爾文文本以空格隔開的有序詞序列中,和是相鄰的詞對, 則根據互信息原理, 單詞和之間的互信息可定義為
其中,(,)為詞對和在大規模語料庫中出現的概率,()為單詞出現的概率,()為單詞出現的概率。假定它們在語料庫中出詞頻分別為count(), count()和count(,),是語料庫中的詞頻總數, 則有
互信息mi(,)反映相鄰詞對和間的關聯程度。mi(,)越大, 表明和之間的關聯程度越緊密, 如果mi(,)大于給定的一個閾值mi, 則可以認為和之間是不可分割的。
我們以生語料庫URC訓練維吾爾文單詞Bi-gram模型, 并以USC1為對象考察互信息關于單詞間連、斷的分布情況。互信息變化范圍在–6.75~ 21.01之間, 當閾值mi取4.0時(根據URC統計得到的mi均值為3.63),值最高可達75.26%。例如, 對于例5中各位置的判別基本上是正確的(如圖3(a), “|”為分隔符)。
例5 這種軟件可以監測硬盤狀態。
從式(2)可以看出, 互信息反應的是相鄰詞對和之間的靜態結合能力, 而不考慮它們的上下文, 因此僅僅參考互信息這個基本統計量, 也會出現錯誤的連、斷判斷。比如, 對于例6和7的詞間位置判斷準確率較低(圖3(b)和(c))。
例6 首批全國政協委員抵達北京。
例7 奧巴馬連任面臨就業挑戰。
2.2 基本統計量:-測試差(dts)
Church等[24]首次引入-測試來度量一個英文單詞與其上下文單詞和的結合緊密程度。根據定義, 維吾爾文單詞序列的-測試值計算公式如下:
其中(|)和(|)分別為相鄰詞對()和()的Bi-gram概率,2((|))和2((A|x))分別是二者的方差。由式(4)可以看出, 如果t, y()>0, 則與后繼結合的強度大于與前趨結合的強度, 此時應與斷而與連; 如果t, y()<0, 則與前趨結合的強度大于與后繼結合的強度, 此時應與斷而與連; 如果t, y()=0, 則與其前趨和后繼的結合強度相等,無法判斷與和的連斷關系。
-測試是基于字的統計量, 而不是基于字間位置。為了能夠在中文分詞中直接計算相鄰字間連斷概率, 孫茂松等[12]提出-測試差的概念。根據定義, 對于維吾爾文單詞序列, 相鄰單詞和之間的-測試差值計算公式如下:
當dts(,)>dts(dts為閾值)時, 相鄰詞對與之間的位置更傾向于判斷為連, 否則判斷為斷。我們仍以USC1為對象, 考察-測試差關于單詞間連、斷的分布情況。-測試差變化范圍在–264.14~ 108.41之間, 當閾值dts取0.0時,值可達最高為78.14%。與mi相比, 切分準確率較高, 但對于例5~7, 各位置的判斷與mi有所不同(圖4)。
2.3 基本統計量: 鄰接對熵(dae)
語義串作為頻繁使用的語言單元, 在真實文本中具有一定的流通度, 能夠應用于多種不同的上下文環境。因此, 我們可以根據相鄰兩個單詞上下文語言環境的復雜程度來衡量詞對的結構穩定性。
對于維吾爾文有序單詞序列(和是任何一個維吾爾文單詞), 詞對和在文本中每次出現的左鄰接元素和右鄰接元素構成一個鄰接對<,>, 那么和的所有鄰接對組成鄰接對集dae={<x,y>}。為集合中所有鄰接對個數,為集合鄰接對種類數(不重復鄰接對個數),n為每個鄰接對<x,y>的頻次, 則和的鄰接對集合的信息熵(鄰接對熵)的計算公式如下:
由式(6)可知, dae(,)取值越大, 詞對和的語言環境變化越靈活多樣, 其內部結合越緊密; dae(,)取值越小,和的獨立性越弱, 很可能是一種偶然性組合。因此, 當dae(,)>dae(dae為閾值)時,和的單詞間位置更傾向于判斷為“連”, 反之判斷為“斷”。
例如, 三詞語義串()在語料庫中共出現5次, 其語言環境分別為,,,,, 那么相鄰詞對和的鄰接對集合dae={<,>, <,>, <,, <,>, <,>}, 此時=5,=5, 因此和的鄰接對熵為
我們仍以USC1為對象, 考察鄰接對熵關于單詞間“連”、“斷”的分布情況。dae變化范圍在0.06~ 1.37之間, 當閾值dae取0.60時,值可達最高為73.23%。
與mi和dts相比, dae的分詞準確率稍低, 但它對新詞詞間位置的連、斷判斷更準確。例如, 對于一個新出現的語義串, 因為和是兩個獨立語言單位, 在真實文本中會頻繁使用, 他們結合構成的特定新詞的詞頻遠遠小于和的詞頻, 會出現count()和count()極大而count()極小的情況。在這種情況下, mi和dts幾乎都會做出錯誤的判斷, 但dae中詞頻不是決定性因素, 而是更多地考慮兩個詞上下文語言環境的變化多樣性, 因此能夠做出正確的判斷。
例如, 新詞“??? ?????”(禽流感)在生語料庫URC中共出現17次, 單詞“???”(禽)出現2378次, 單詞“?????”(流感)出現4927次。因此, (??? ,?????)的互信息值為3.78, dts取值不均勻(–3.17~–0.48), 如果以mi或dts來判斷詞間位置的連斷, 是要斷開的。但鄰接對熵取值為0.96, 用dae判別詞間位置是連接的。例如, 對于例8中“??? ?????”的詞間位置判斷, mi和dts都是錯誤的, 只有dae的判斷是正確的(圖5)。
例8 科學家研制出禽流感病毒。
不論互信息、-測試差或鄰接對商, 都是將詞在語言環境中某一方面的信息特征作為計算依據, 因此必然存在一定的局限性。中文分詞中已有成功的案例, 將基本統計量加以組合從而各取所長。我們分別用互信息、-測試差和鄰接對熵對USC1進行實驗, 發現將它們結合互補有較大的可行性。
2.4 組合統計量: dmd
我們單獨用基本統計量對USC1進行詞間位置判斷, 其中-測試差的值最高(78.14%), 其次為互信息(75.26%), 最后是鄰接對熵(73.23%)。因此, 我們以dts為主, 將3個基本統計量進行線性疊加, 融合成一個組合統計量dmd, 并完全根據dmd來判斷詞間位置。由于以上基本統計量取值范圍相差較大,-測試差變化范圍為–264.14~108.41, 互信息變化范圍為–6.75~21.01, 鄰接對熵變化范圍為0.0~3.97, 因此, 線性迭加前先進行歸一化處理, 如式(7)~(9)所示。
其中dts,mi和dae分別是dts, mi和dae的均值, 實驗值依次為–6.51, 3.63和0.52。dts,mi和dae分別是dts, mi和dae的均方差, 實驗值依次為24.29, 3.54和0.31。通過下式將它們疊加:
其中,和的值經實驗測定, 發現當=0.35,= 0.30時的分詞效果最好。dmd在USC1上的變化范圍為–11.5~6.9, 當閾值dmd取為0時,值最高(84.31%), 比單獨使用-測試差、互信息或鄰接對熵分別提高6.17%, 9.05%和11.08%。
2.5 基于規則的詞間關聯度度量
以組合統計量dmd判斷詞間位置的準確率達到84.31%, 但是與理想的準確率還存在一定的距離。我們從維吾爾文本身的語言特性中尋找有助于詞間位置判斷的信息, 發現以下特性。
特性1 維吾爾文中的助詞(????、?????等)、連詞(?????、????等)、副詞(???、 ?????等)、量詞(????、 ?????等)、代詞(???、???等)以及感嘆詞(???、???等)等功能詞, 在文本中始終不與其他單詞結合成為語義串。本文將這些詞稱為“獨立詞”(in-dependent word, IW)。
特性2 維吾爾文單詞間的結合主要是在名詞(N)、形容詞(ADJ)和動詞(V)之間發生, 并構成語義串。當形容詞與名詞或與動詞結合時, 形容詞總是作為前驅, 而不會出現在后繼位置。因此, N+ADJ或V+ADJ關系的相鄰單詞不可能結合構成一個語義串。
根據特性1和特性2, 我們歸納出用于詞間關聯識別的單詞結合規則(word association rule, WAR), 并定義如下。
定義3 單詞結合規則(WAR): 對于文本中的相鄰詞對“”, 如{IW}或{IW}或{ADJ}, 則判斷與不能結合成為關聯模式, 要斷開。
因此, 我們建立兩個輔助詞表: 獨立詞表和形容詞表, 并用單詞結合規則判斷詞間位置。這樣, 既減少了詞間位置的dmd計算量, 又明顯提高了準確率。
3 基于詞間關聯度度量的切分算法
確定組合統計量dmd和單詞結合規則后, 基于詞間位置判斷的維吾爾文語義串識別及切分整體流程如圖6所示。
對于訓練語料, 將所有的標點符號都替換為分隔符“|”, 并進行詞干提取處理, 然后計算語料庫中所有詞對的dmd值, 構建雙詞結合度(dmd)詞典。對于待處理文本, 進行同樣的預處理(標點符號的替換以及詞干提取), 然后依次提取詞間位置(詞對), 按以下步驟判斷詞間的相鄰性。
1)對于當前詞對“”, 如{IW}或{IW}或{ADJ}, 則判斷與斷開, 并插入分隔符“|”來消除與間的相鄰性, 否則轉步驟2。
2)從雙詞結合度詞典中讀取詞對“”的dmd值, 如dmd(,)>dmd, 則判斷與連接并保留相鄰性, 否則插入分隔符“|”, 消除與間的相鄰性, 轉步驟3。
3)如“”是最后一個詞對, 則轉步驟4, 否則提取下一個詞對并轉步驟1。
4)結束當前文本詞間位置的判斷。
對當前文本中所有詞間位置判斷結束后, 以分隔符“|”進行切分, 得到文本中所有語義串。算法流程如圖7所示。
4 實驗與分析
我們基于生語料庫URC得到維吾爾文單詞(詞干)統計模型, 并構建雙詞結合度詞典, 以USC1為對象, 用不同統計量判斷詞間位置的準確率并調整閾值, 確定式(10)中的和來檢驗組合統計量dmd的有效性以及驗證語義串提取算法在開放環境下的健壯性。因此, 我們分別在開發集和測試集上進行詞間位置判斷實驗, 分析dts, mi和dae組合前和組合后詞間位置正確判斷情況。
以分界符“|”替換為所有標點符號后, 開發集USC1和測試集USC2共含的維吾爾文單詞及需要判斷的詞間位置如表1所示。
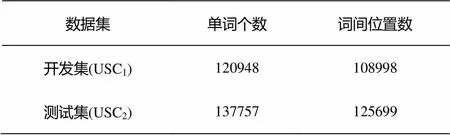
表1 USC1和USC2中單詞及詞間位置數
使用不同策略情況下的開發集和測試集實驗結果如表2和3所示。
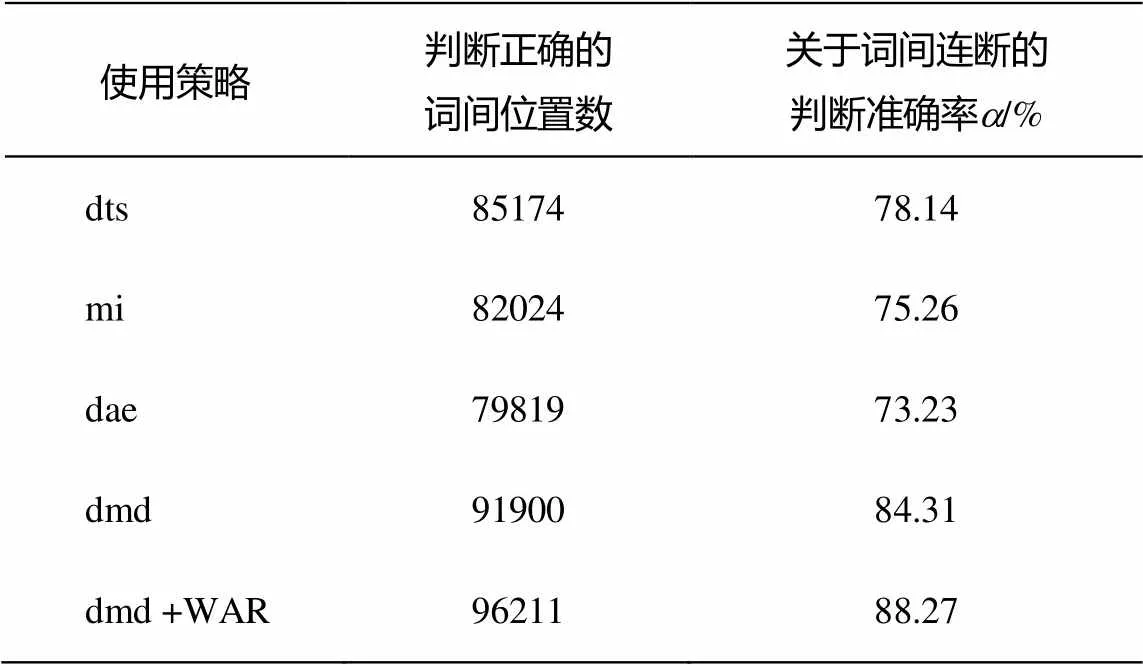
表2 開發集切分結果
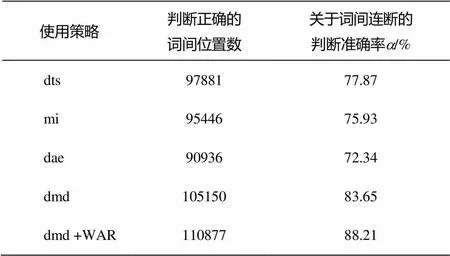
表3 測試集切分結果
從測試結果看出, 算法在測試集中的性能沒有下降, 表明本文提出的組合統計量dmd及各類參數的確定是有效的, 尤其是引入語言特性的單詞結合規則后, 詞間位置判斷準確率有明顯提高。
我們發現, 詞干切分工具的局限性、維吾爾文中難以避免的拼寫錯誤、詞間位置的不規范性以及名詞術語的不規范縮寫等因素在一定程度上影響詞間位置判斷準確率。關于詞干切分算法的局限性, 除算法本身的缺陷外, 拼寫錯誤也是一個主要的因素, 現有的方法和工具還不能對批量文本進行全自動檢錯和糾錯。對于詞間位置和名詞術語書寫規范化, 還沒有相關的研究報道。不管是算法上的缺陷, 還是原始文本的不規范性, 都會影響詞間判斷準確率。因此, 對語料庫進行訓練或對待處理文本進行處理前, 應盡量排除以上負面因素的影響, 在較規范的文本語料上可以獲得更高的切分準確率。這也是我們將來工作的研究重點。
5 結語
以空格作為自然分隔符的維吾爾文傳統分詞方法, 會把多詞結構的語義串拆分成與其本義完全不符的若干個片段, 表現出非常明顯的不足和局限性, 在維吾爾文文本挖掘領域研究中已成為一大瓶頸。本文提出一種基于詞間關聯度度量的維吾爾文本自動切分方法, 利用單詞關聯規則和統計結合的方法度量相鄰單詞之間的關聯緊密程度, 從而識別出語義串的邊界, 達到以語義及結構完整的詞串為單位進行文本切分的目的, 實現了相應的自動切分算法。在大規模測試語料上進行的切分實驗表明, 該算法表現出較高的準確率和健壯性。本文提出的方法還能應用到哈薩克文、柯爾克孜文等其他語言文本自動切分中。
[1]賀敏. 面向互聯網的中文有意義串挖掘[D]. 北京: 中國科學院研究生院, 2007: 1–8
[2]吳慶耀. 無監督的中文語義詞抽取技術研究[D]. 深圳: 哈爾濱工業大學深圳研究生院, 2009: 5–10
[3]Chien L F. PAT-Tree-Based keyword extraction for Chinese information retrieval // Proceedings of the 20th annual international ACM SIGIR Conference on Research and Development in Information Retrieval.Philadelphia, PA, 1997: 50–58
[4]Candito M, Constant M. Strategies for contiguous multiword expression analysis and dependency parsing // 52nd Annual Meeting of the Association for Computational Linguistics (ACL 2014). Baltimore, MD, 2014: 743–753
[5]Luo R L, Zhang H X, Wu M H. Ambiguity analysis model of word segmentation based on word group. Journal of Applied Sciences, 2013, 13(16): 3153–3160
[6]Masaki M, Masao U. Compound word segmentation using dictionary definitions-extracting and examining of word constituent information. ICIC Express Letters, Part B: Applications, 2012, 3(3): 667–672
[7]Liu X L. Automatic summarization method based on compound word recognition. Journal of Computa-tional Information Systems, 2015, 11(6): 2257–2268
[8]Zheng H T, Kang B Y, Kim H G. Exploiting noun phrases and semantic relationships for text document clustering. Information Sciences, 2009, 179(13): 2249–2262
[9]Sreya D, Narasimha M M. Using discriminative phrases for text categorization // 20th International Conference on Neural Information Processing.Daegu, 2013: 273–280
[10]Rais N H, Abdullah M T, Kadir R A. Multiword phrases indexing for malay-English cross-language information retrieval. Information Technology Journal, 2011, 10(8): 1554–1562
[11]Zhang Y F, Long F, Bin L. Identifying opinion sentences and opinion holders in internet public opinion // Proceedings of the 2012 International Conference on Industrial Control and Electronics Engineering.Xi’an, 2012: 1668–1671
[12]孫茂松, 肖明, 鄒嘉彥. 基于無指導學習策略的無詞表條件下的漢語自動分詞. 計算機學報, 2004, 27( 6): 736–742
[13]王思力, 王斌. 基于雙字耦合度的中文分詞交叉歧義處理方法. 中文信息學報, 2007, 21(5): 14–17
[14]費洪曉, 康松林, 朱小娟, 等. 基于詞頻統計的中文分詞的研究. 計算機工程與應用, 2005, 30(7): 67–69
[15]王芳, 萬常選. 基于可信度的中文完整詞自動識別. 中文信息學報, 2009, 23(3): 17–23
[16]何賽克, 王小捷, 董遠, 等. 歸一化的鄰接變化數方法在中文分詞中的應用. 中文信息學報, 2010, 24(1): 15–19
[17]蔣建洪, 趙嵩正, 羅玫. 詞典與統計方法結合的中文分詞模型研究及應用. 計算機工程與設計, 2012, 33(1): 387–391
[18]Tohti T, Musajan W, Hamdulla A. Efficient term extraction and indexingapproach in small-scale web search of Uyghur Language. Journal of Multimedia, 2013, 8(5): 481–488
[19]Liu J Y, Liu Y. Resolution to combinational ambiguity of Chinese word segmentation // 2009 International Conference on E-learning, E-Business, Enterprise Information Systems, and E-Government.Hong Kong: IEEE, 2009: 141–145
[20]Qiu L K, Hu H L, Wu Y F. Corpus-based method for differentiating genuine and spurious combinational ambiguity. ICIC Express Letters, 2013, 7(4): 1437–1441
[21]阿力木江·艾沙, 吐爾根·依布拉音, 艾山·吾買爾, 等. 基于機器學習的維吾爾文文本分類研究. 計算機工程與應用, 2012, 48(5): 110–112
[22]徐峻嶺, 周毓明, 陳林, 等. 基于互信息的無監督特征選擇. 計算機研究與發展, 2012, 49(2): 372–382
[23]孟春艷. 用于文本分類和文本聚類的特征抽取方法的研究. 微計算機信息, 2009, 25(3): 149–150
[24]Church K W, Gale W, Hanks P, et al. Using statistics in lexical analysis // Zernik U. Lexical acquisition: exploiting on-line resources to build a lexicon. Hillsdale NJ: Lawrence Erlbaum Associates, 1991: 115–164
Uyghur Text Automatic Segmentation Method Based on Inter-Word Association Degree Measuring
Turdi Tohti?, Winira Musajan, Askar Hamdulla
School of Information Science and Engineering, Xinjiang University, Urumqi 830046; ? E-mail: turdy@xju.edu.cn
This paper puts forward a new idea and related algorithms for Uyghur segmentation. The word based Bi-gram and contextual information are derived from large scale raw corpus automatically, and according to the Uyghur word association rules, the liner combinations of mutual information, difference of-test and dual adjacent entropy are taken as a new measurement to estimate the association strength between two adjacent Uyghur words. The weakly associated inter-word position is taken as a segmentation point and the perfect word strings both on its semantics and structural integrity, not just the words separated by spaces, is obtained. The experimental result on large-scale corpus shows that the proposed algorithm achieves 88.21% segmentation accuracy.
semantic string; mutual information; difference of-test; dual adjacent entropy; word association rules
10.13209/j.0479-8023.2016.023
TP391
2015-06-07;
2015-08-18; 網絡出版日期: 2015-09-30
國家自然科學基金(61262062, 61163033, 61262063, 61562083)和新疆維吾爾自治區高校科研計劃重點項目(XJEDU2012I11)資助
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
