在線醫(yī)療文本中的實(shí)體識別研究
2016-10-13 04:28:20蘇婭劉杰黃亞樓
北京大學(xué)學(xué)報(自然科學(xué)版) 2016年1期
蘇婭 劉杰 黃亞樓
?
在線醫(yī)療文本中的實(shí)體識別研究
蘇婭 劉杰?黃亞樓
南開大學(xué)計算機(jī)與控制工程學(xué)院(軟件學(xué)院), 天津 300071; ? 通信作者, E-mail: nkjieliu@gmail.com
針對在線醫(yī)療文本, 設(shè)計考慮醫(yī)療領(lǐng)域特性的識別特征, 并在自建數(shù)據(jù)集上進(jìn)行實(shí)體識別實(shí)驗(yàn)。針對常見的5類疾病: 胃炎、肺癌、哮喘、高血壓和糖尿病, 采用近年來較先進(jìn)的機(jī)器學(xué)習(xí)模型條件隨機(jī)場, 進(jìn)行訓(xùn)練和測試, 抽取目標(biāo)實(shí)體包括疾病、癥狀、藥品、治療方法和檢查5類。通過采用逐一添加特征的實(shí)驗(yàn)方式, 驗(yàn)證所提特征的有效性, 取得總體上81.26%的準(zhǔn)確率和60.18%的召回率, 隨后對識別特征給出進(jìn)一步分析。
實(shí)體識別; 數(shù)據(jù)挖掘; 條件隨機(jī)場; 醫(yī)療信息
隨著生活水平的提高, 人們對于健康問題日益關(guān)注。互聯(lián)網(wǎng)行業(yè)的迅猛發(fā)展催生一大批在線醫(yī)療社區(qū)和醫(yī)療信息網(wǎng)站, 為患者提供了多元化的醫(yī)療信息獲取渠道[1]。這些網(wǎng)站主要以健康知識、疾病信息、醫(yī)療新聞等為主要內(nèi)容, 同時也提供用戶在線疾病問答功能。國內(nèi)比較知名的有新浪健康、尋醫(yī)問藥、好大夫在線、39問醫(yī)生等。據(jù)調(diào)查, 單是尋醫(yī)問藥網(wǎng)就包含2004年11月24日至今十余年的疾病問答數(shù)據(jù), 每天還會涌現(xiàn)數(shù)萬條新提問。日積月累, 這些疾病問答信息將匯成一股非常可觀的大數(shù)據(jù)。這樣的數(shù)據(jù)有著廣泛的參與人群, 其中包含大量真實(shí)的個人案例, 潛藏著豐富的醫(yī)療價值。然而, 它們在文本中大多處于一種非結(jié)構(gòu)化的狀態(tài)。為了實(shí)現(xiàn)信息的充分利用, 抽取和挖掘出其中有用的醫(yī)療知識, 進(jìn)行命名實(shí)體識別通常是第一步。
目前, 在醫(yī)療領(lǐng)域, 針對電子病歷、各種醫(yī)療報告、醫(yī)學(xué)文獻(xiàn)等的實(shí)體識別工作已有不少, 但針對醫(yī)療問答網(wǎng)站中的疾病問答信息尚未見相關(guān)研究。本文針對這樣的問答信息, 首次進(jìn)行實(shí)體識別和挖掘工作。本文抽取的實(shí)體類別包括疾病、癥狀、藥品、治療方法和檢查5類。在特征選取方面, 除使用一般的實(shí)體識別文本特征(例如符號特征、詞性特征、英文數(shù)字特征等)外, 還添加了醫(yī)療領(lǐng)域特有的一些特征(包括詞的后綴特征、身體部位指示詞特征)來輔助完成識別和抽取工作, 最終在自建數(shù)據(jù)集上達(dá)到81.26%的準(zhǔn)確率和60.18%的召回率。
1 相關(guān)工作
命名實(shí)體識別是自然語言處理領(lǐng)域一個重要的研究方向, 1995年舉行的第六屆消息理解會議(MUC-6)[2]正式提出命名實(shí)體識別任務(wù)。它作為文本挖掘中的第一步, 主要任務(wù)是識別文本中代表其知識主體的詞語。MUC將命名實(shí)體定義為兩類: 專有名詞和數(shù)量詞。在不斷的研究中, 命名實(shí)體的含義和范圍也在持續(xù)地豐富和擴(kuò)展。MUC之后, 出現(xiàn)自動內(nèi)容抽取會議(Automatic Content Extraction, ACE)[3], 它由美國國家標(biāo)準(zhǔn)技術(shù)研究院(NIST)組織創(chuàng)辦, 從1999年至今已經(jīng)舉辦多次關(guān)于信息內(nèi)容自動抽取的評測任務(wù), ACE數(shù)據(jù)集已經(jīng)成為測試新的信息抽取算法的公認(rèn)標(biāo)準(zhǔn)。
在生物醫(yī)學(xué)領(lǐng)域, 識別對象集中在以下幾類: 電子醫(yī)療記錄、醫(yī)學(xué)文獻(xiàn)和在線醫(yī)療社區(qū)。目前比較集中的研究是針對醫(yī)學(xué)文獻(xiàn)中的基因、蛋白質(zhì)、藥物名、組織名等進(jìn)行的生物命名實(shí)體識別工作[4]。隨著醫(yī)療系統(tǒng)的信息化, 出現(xiàn)大量針對電子病歷進(jìn)行的識別工作, 目前識別值一般在0.82左右[5]。
命名實(shí)體的識別方法包括3種: 基于詞典的方法、基于啟發(fā)式規(guī)則的方法和基于機(jī)器學(xué)習(xí)的方法。基于詞典的方法通過字符串匹配實(shí)現(xiàn)實(shí)體識別, 但對詞典有很強(qiáng)的依賴性。在國外, 英文醫(yī)療實(shí)體識別日趨成熟, 可供參考的資料也比較詳實(shí), 最著名的詞典包括國際疾病分類ICD-10 (Interna-tional Classification of Diseases-10)[6]、醫(yī)學(xué)一體化語言UMLS(Unified Medical Language System)[7]和醫(yī)學(xué)主題詞表MeSH(Medical Subject Headings)[8]。在中文方面, 國內(nèi)研究還較少, 可使用的資源也相對匱乏。在基于啟發(fā)式規(guī)則的方法方面, Kraus等[9]針對大學(xué)醫(yī)療系統(tǒng)的臨床記錄, 通過構(gòu)建正則表達(dá)式, 對其中提及的藥品、劑量、服用方法等信息進(jìn)行識別。目前比較流行的是基于機(jī)器學(xué)習(xí)的方法。
命名實(shí)體識別可以看成一個分類問題, 采用類似支持向量機(jī)、貝葉斯模型等分類方法, 同時, 也可以看成一個序列標(biāo)注問題, 采用隱馬爾可夫、最大熵馬爾可夫、條件隨機(jī)場等機(jī)器學(xué)習(xí)方法[10]。Sondhi等[11]針對醫(yī)療論壇HealthBoards上的疾病話題信息, 利用SVM和CRF方法進(jìn)行淺層的信息抽取。在中文方面, 葉楓等[12]自建詞典, 采用條件隨機(jī)場對電子病歷中的疾病、臨床癥狀、手術(shù)操作3類比較常見的命名實(shí)體進(jìn)行識別, 達(dá)到90%以上的值。王世昆等[13]對明清古醫(yī)案中的癥狀和病機(jī)進(jìn)行識別, 采用CRF和SVM分別進(jìn)行訓(xùn)練和測試, 是在中文方面的較為大膽的嘗試。
2 模型和特征選取
在前面提到的眾多方法中, 條件隨機(jī)場是一種較優(yōu)秀的識別方法, 它不僅去除了HMM中的獨(dú)立性假設(shè), 而且通過全局的歸一化解決了標(biāo)記偏置的問題, 在命名實(shí)體識別、詞性標(biāo)注等問題上都取得不錯的效果。如果采用CRF建立疾病問答中的實(shí)體識別模型, 將更易于融合新的特征, 使用有重疊性非獨(dú)立的特征。利用其強(qiáng)大的推理能力, 有可能識別出訓(xùn)練語料中未出現(xiàn)的情況。因此, 本文選擇CRF模型進(jìn)行醫(yī)療文本中命名實(shí)體的識別。
2.1 條件隨機(jī)場模型
條件隨機(jī)場(Conditional Random Fields, CRF)是一種無向圖模型, 1958年由Luhn[14]提出。它提供了一種概率框架, 計算在給定一個觀察數(shù)據(jù)序列= (1,2, …,x)的條件下, 該序列所對應(yīng)標(biāo)簽序列= (1,2, …,y)整體出現(xiàn)的概率[15], 即
其中= (1,2, …,)代表模型參數(shù),(,) 是任意定義的以為參數(shù)關(guān)于觀察序列和標(biāo)簽序列的特征函數(shù),(;)是歸一化因子。
用CRF模型進(jìn)行命名實(shí)體識別, 可以視為一個序列標(biāo)注問題。將要識別的每個句子作為一個觀察序列, 句子中的每個詞作為一個符號, 為每一個符號賦予一個類別標(biāo)簽。CRF模型最簡單的一個結(jié)構(gòu)就是鏈?zhǔn)浇Y(jié)構(gòu)[16], 如圖1所示。
進(jìn)行模型訓(xùn)練時, 給定一個訓(xùn)練數(shù)據(jù)集= {(1,1), (2,2), …, (X,Y)}, 其對應(yīng)的經(jīng)驗(yàn)分布為, 一般可以通過最大化對數(shù)似然值, 得出模型參數(shù)估計:
為了避免過擬合, 可以運(yùn)用一些調(diào)整的方法, 通常在參數(shù)上加上高斯先驗(yàn), 目標(biāo)函數(shù)()就變?yōu)?/p>
其中是高斯先驗(yàn)的方差。得到參數(shù)之后, 可以進(jìn)一步推斷給定目標(biāo)序列最可能的標(biāo)簽序列:
目前已有一些成熟的算法可以用來推斷這一值, 比如Viterbi算法[17]。
2.2 特征選取
對于CRF模型, 特征的選取很關(guān)鍵。通過對疾病問答文本的分析, 本文選擇以下特征進(jìn)行識別。
1)符號特征。中文之間沒有類似英文空格的天然分隔符, 因此在進(jìn)行實(shí)體識別時, 需要首先進(jìn)行分詞操作, 將分詞之后的每一個詞語作為符號特征。為提高分詞準(zhǔn)確率, 引入自定義詞典。通過從多個輸入法(包括搜狗、百度、QQ)和醫(yī)療網(wǎng)站(尋醫(yī)問藥、好大夫在線等)中分別獲取, 去重合并之后綜合成疾病、癥狀、藥物、檢查、治療方法和身體部位詞語6類輔助詞典。
2)詞性特征。在病人描述中經(jīng)常會出現(xiàn)“患”、“服用”、“吃”等動詞, 這些詞后會出現(xiàn)疾病名或者藥品名, 這就為實(shí)體的邊界的識別提供了線索。在本文中, 該特征即為采用Ansj分詞后的詞性。本文采用開源代碼庫Github上的Ansj[18]系統(tǒng)的分詞詞性作為這一維特征。
3)形態(tài)特征。形態(tài)特征指當(dāng)前詞的構(gòu)成情況, 包括兩個特征: 英文字母特征和數(shù)字特征。英文字母特征用于標(biāo)記詞當(dāng)中是否包含有英文字母, 因?yàn)閷τ跈z查來說, 經(jīng)常會出現(xiàn)“ct”、“MRI”之類的英文, 而在疾病名、藥物等類別中卻不常出現(xiàn)。同樣, 數(shù)字特征用于標(biāo)記該詞是否由數(shù)字構(gòu)成。
4)后綴特征。在英文命名實(shí)體識別中, 經(jīng)常采用詞的后綴特征進(jìn)行識別, 并且被證明是有效的。本文研究工作雖然是針對中文開展的命名實(shí)體識別, 但經(jīng)觀察發(fā)現(xiàn), 文本中的各類醫(yī)療實(shí)體也有一定的規(guī)律性, 比如病名通常以“病”、“癥”這類詞結(jié)尾, 而藥品則以“顆粒”、“丸”、“劑”等詞語結(jié)尾, 治療方法則常以“術(shù)”結(jié)尾。因此, 本文也加入后綴特征, 即選取詞語的最后一個字作為特征。
5)身體部位指示詞特征。該特征用于標(biāo)記當(dāng)前詞是否為身體部位相關(guān)的詞語, 因?yàn)檫@樣的詞語在癥狀描述中經(jīng)常出現(xiàn)。
6)上下文特征。在詞語組成的序列中, 上下文之間存在相關(guān)性, 該特征即為CRF模型中的邊的特征。當(dāng)選用不同的窗口長度時, 將對各種特征進(jìn)行組合, 形成新的特征。
3 在線醫(yī)療文本中的實(shí)體識別
針對在線醫(yī)療文本信息, 我們主要考慮表1中顯示的5類命名實(shí)體。實(shí)體識別流程如圖2所示, 主要包括預(yù)處理、特征計算、CRF模型訓(xùn)練、實(shí)體識別和識別結(jié)果抽取。首先對獲取的在線醫(yī)療文本進(jìn)行預(yù)處理, 包括特殊符號的過濾、人工標(biāo)注、分詞、大小寫轉(zhuǎn)化等操作; 然后, 利用程序從處理好的文本中自動計算并抽取特征, 將所有數(shù)據(jù)劃分為訓(xùn)練集和測試集兩部分。將訓(xùn)練集放到模型中進(jìn)行訓(xùn)練, 隨后再利用訓(xùn)練得到的參數(shù)測試模型識別效果。

表1 命名實(shí)體類別
3.1 數(shù)據(jù)預(yù)處理
為了對在線醫(yī)療文本進(jìn)行實(shí)驗(yàn), 本文采集好大夫在線的5類疾病的全部問答信息, 涉及疾病包括胃炎、肺癌、哮喘、高血壓和糖尿病。每一篇文本包含一個提問及相應(yīng)回答, 其中已經(jīng)過濾掉沒有回答的提問信息。
針對問答文本, 首先進(jìn)行一些相關(guān)的預(yù)處理(如對特殊字符、英文大小寫、標(biāo)點(diǎn)符號等的處理)。隨后進(jìn)行人工數(shù)據(jù)標(biāo)注。采取的標(biāo)注方式為BIO模型[19], 可以將分塊轉(zhuǎn)化為序列標(biāo)記確定問題, 格式為B-X, I-X或者O, 其中B, I, O分別代表Begin, Internal, Other, 即類別的開始、中間或其他, X代表標(biāo)注的類別。
識別實(shí)驗(yàn)采用開源工具CRF++: Yet Another CRF toolkit[20], 其輸入有一定的格式要求。標(biāo)注時首先進(jìn)行人工標(biāo)注, 為力求準(zhǔn)確, 對不熟悉的語匯都進(jìn)行查閱和了解。隨后將標(biāo)注數(shù)據(jù)轉(zhuǎn)換成所需格式, 如表2所示。本文采用Ansj分詞系統(tǒng), 對于自定義詞典中的詞都有自定義的類別標(biāo)簽。表中“輔舒酮”為自定義藥品詞典中的詞, 因此詞性有別于其他詞語。最終對每類疾病分別標(biāo)注了200篇問答信息, 共1000篇作為訓(xùn)練和測試數(shù)據(jù), 共包含4812個不同的實(shí)體名詞。
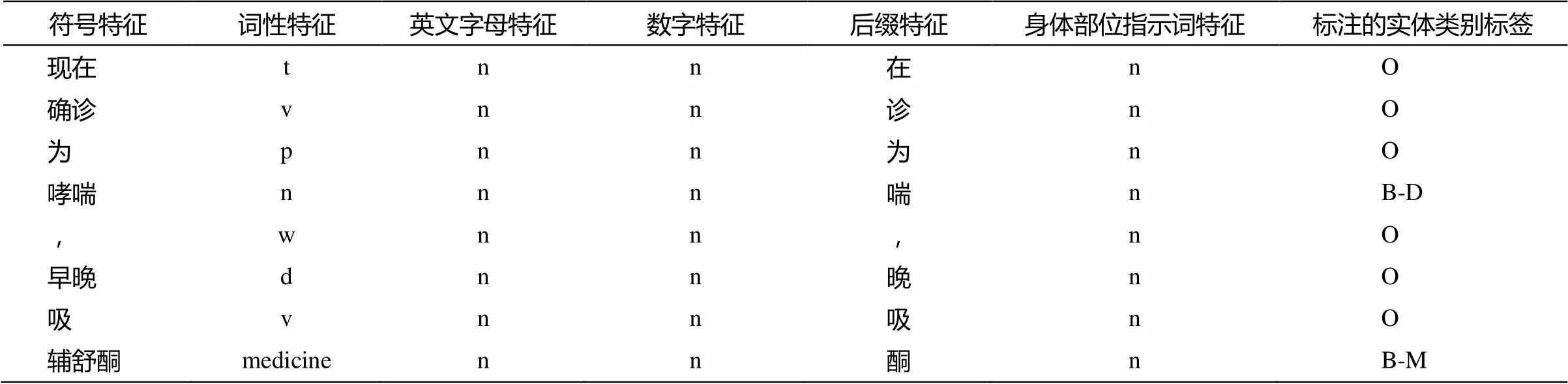
表2 數(shù)據(jù)標(biāo)注示例
CRF++采用用戶模板進(jìn)行特征計算。在選擇窗口大小時, 首先在500條問答數(shù)據(jù)上, 采用同樣的模板, 設(shè)置不同窗口大小進(jìn)行測試。窗口大小為3時的效果優(yōu)于窗口大小為1和2, 此后再增加窗口大小, 效果提升不大, 因此本文最終將窗口大小設(shè)定為3。針對每一列輸入特征(0~5)設(shè)置模板, 包括兩類形式:
T1 = num: %x[index,], (7)
T2 = num: %x[index,]/%x[index+1,], (8)
其中, num為模板的編號, index為窗口大小范圍內(nèi)的索引(0~2), T2由特征前后位置情況組合而成。
3.2 實(shí)驗(yàn)
本文進(jìn)行兩組實(shí)驗(yàn): 第1組字典實(shí)驗(yàn)驗(yàn)證自定義詞典的有效性: 第2組為不同特征實(shí)驗(yàn), 通過逐一添加特征的方式, 觀察實(shí)驗(yàn)效果的變化。實(shí)驗(yàn)結(jié)果的評測標(biāo)準(zhǔn)由精確度(precision)、召回率(recall)、準(zhǔn)確率(accuracy)和F1值(F1-measure) 構(gòu)成, 這也是數(shù)據(jù)挖掘中經(jīng)常用到的評測指標(biāo)[21]。對結(jié)果的評估采用conlleval.pl評測程序[22]。最后針對實(shí)驗(yàn)的詞性特征和后綴特征進(jìn)行分析。
3.2.1 字典實(shí)驗(yàn)
前面提到, 為提高分詞準(zhǔn)確率, 自建6類醫(yī)療詞匯詞典。然而, 由于是從多個輸入法或者醫(yī)療網(wǎng)站獲取的詞匯, 所構(gòu)筑的6類詞典之間難免會有重疊, 同時其中也充斥著一些不相關(guān)的詞匯, 由于數(shù)量巨大, 如疾病和藥品均有上萬個詞匯(未能一一過濾), 因此存在噪聲。為驗(yàn)證其對實(shí)驗(yàn)的影響及添加詞典的識別效果, 首先進(jìn)行字典實(shí)驗(yàn)。
實(shí)驗(yàn)在一個較小的數(shù)據(jù)集上開展, 選取5類疾病各100條問答數(shù)據(jù), 采用符號特征和詞性特征進(jìn)行實(shí)驗(yàn)。包括3組不同的設(shè)置, 第1組分詞時不使用自定義詞典, 第2組和第3組添加同樣的自定義詞典, 但第2組只將自定義詞典中的詞都標(biāo)注為同一個詞性類別“userDifine”, 第3組則根據(jù)詞語的詞典來源標(biāo)注不同的詞性。自定義詞典的詞數(shù)統(tǒng)計信息如表3所示。用B(basic)表示第1組, B+D為第2組, D代表Dictionary, B+Ds為第3組, Ds代表多個詞典, 不同設(shè)置的標(biāo)注示例如表4所示。
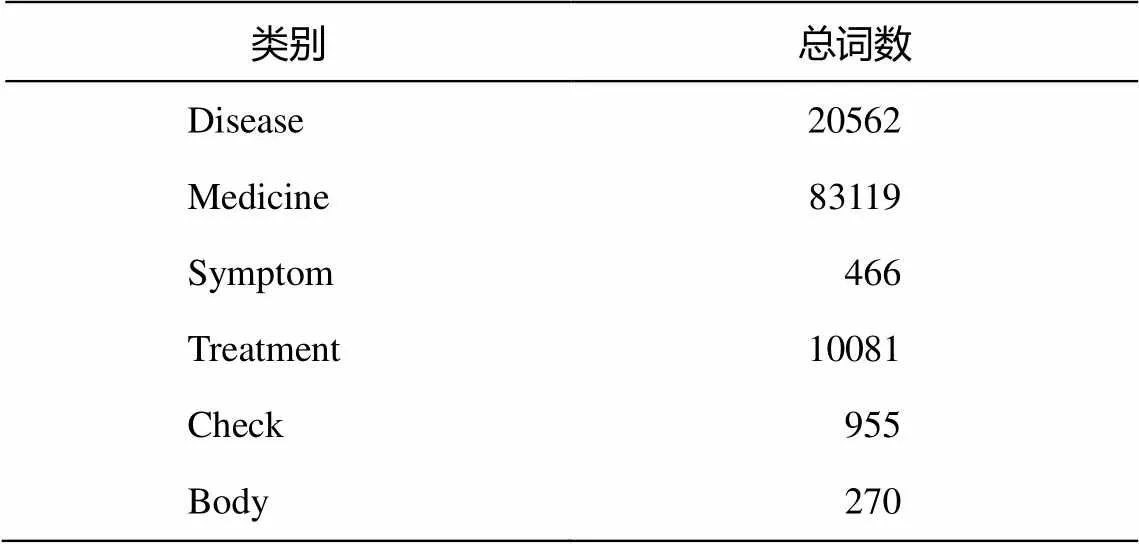
表3 自定義詞典情況
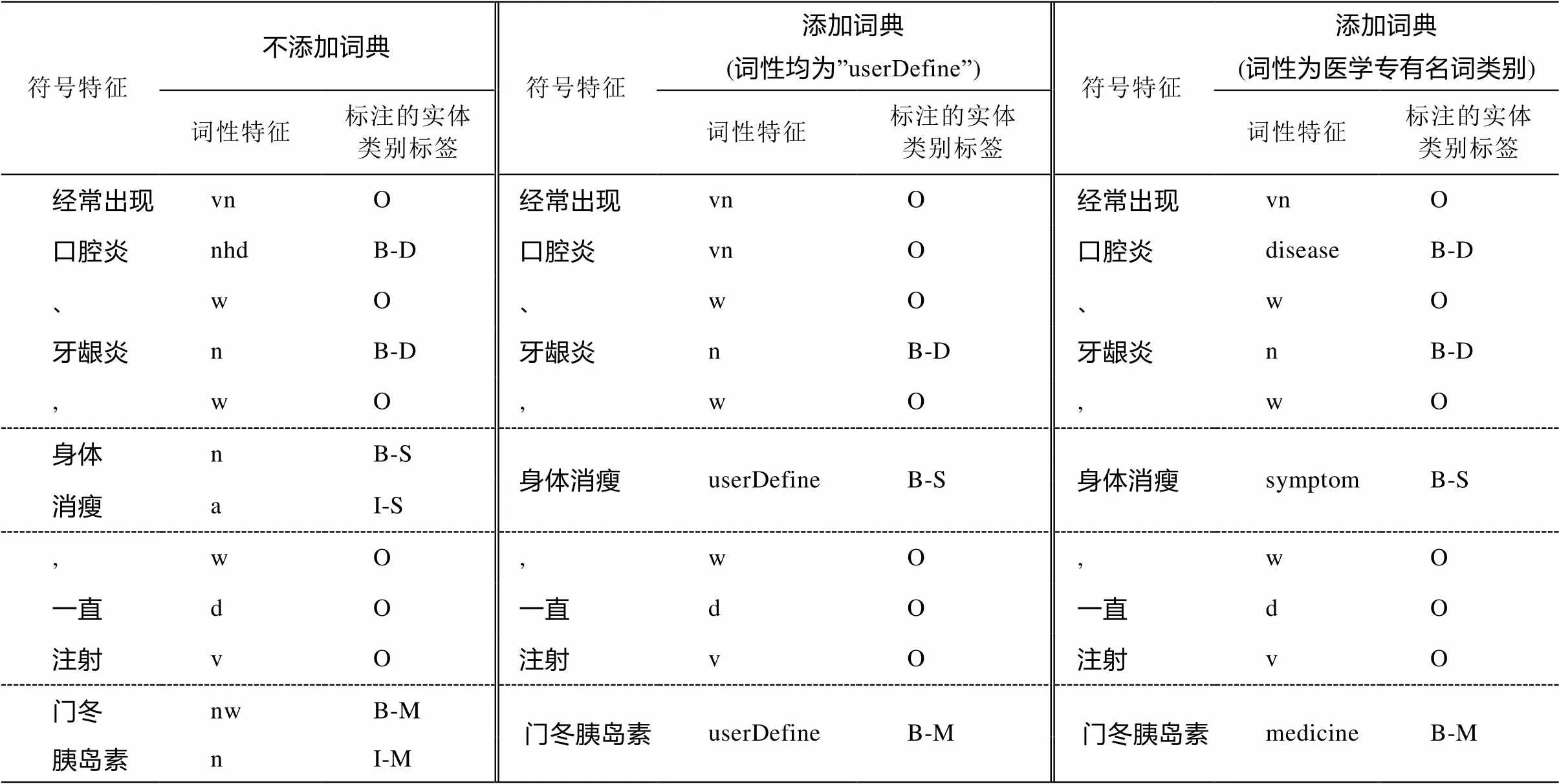
表4 不同詞典設(shè)置的標(biāo)注示例
從實(shí)驗(yàn)結(jié)果表5可以看出, 添加了自定義詞典的識別效果要好于沒有添加的情況, 將詞典分為多個不同類別的效果又好于只設(shè)定為一個詞典的情況。這是因?yàn)閷⒃~典設(shè)置為多個比設(shè)置為一個粒度更細(xì), 因此提供的信息也更為豐富。這組實(shí)驗(yàn)也說明雖然詞典存在噪聲, 但總體上, 影響不大, 添加多個詞典有助于識別效果的提升, 因此, 在下面的實(shí)驗(yàn)中, 分詞時都采用多個字典的方式。
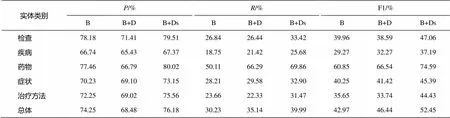
表5 字典實(shí)驗(yàn)結(jié)果
3.2.2 不同特征實(shí)驗(yàn)
為了驗(yàn)證本文提出的各種特征在問答實(shí)體識別中的效果, 采用逐一添加特征的方式對1000條標(biāo)注數(shù)據(jù)進(jìn)行實(shí)驗(yàn), 即每次在符號特征的基礎(chǔ)上增加一種特征。首先添加一些常用的實(shí)驗(yàn)特征(如詞性, 英文、數(shù)字特征等), 再添加本文提出的后綴和身體部位指示詞特征。為了保證實(shí)驗(yàn)結(jié)果的準(zhǔn)確, 均采用5折交叉驗(yàn)證。圖3為實(shí)驗(yàn)結(jié)果總體的變化情況, “word”、“pos”、“al”、“num”、“suffix”和“body”分別代表符號特征、詞性特征、英文字母特征、數(shù)字特征、后綴特征和身體部位指示詞特征。
表6~9為實(shí)驗(yàn)結(jié)果的詳細(xì)情況。可以看到, 隨著各類特征的逐一添加, 識別精確度略有下降, 主要體現(xiàn)在添加詞性特征時; 在后面加入后綴和身體部位指示詞特征后, 精確度又有所回升。總體說來, 精確度變化不大。另一方面, 實(shí)驗(yàn)的召回率在各類實(shí)體上都有大幅度提升, 尤其是在藥物這一類別最終得到41.63%的提升, 比原來37.83%的召回率提升了一倍多。F1值在各類實(shí)體上也都有不同程度的提升, 總體上, 從只用符號特征到所有特征都用, 共提升23.63%。
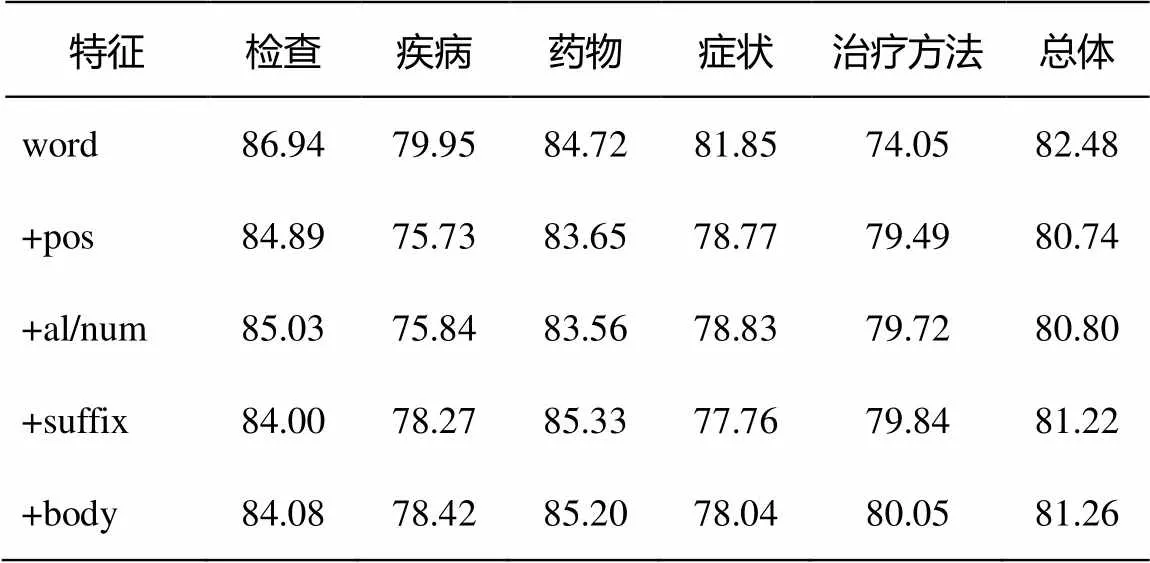
表6 不同特征實(shí)驗(yàn)的precision

表7 不同特征實(shí)驗(yàn)的recall
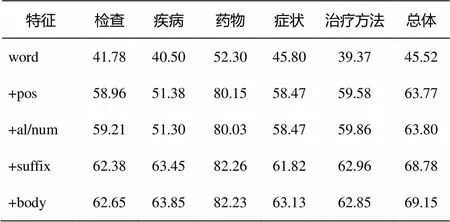
表8 不同特征實(shí)驗(yàn)的F1

表9 不同特征實(shí)驗(yàn)總體的accuracy
實(shí)驗(yàn)結(jié)果表明, 在識別的5類實(shí)體中, 藥物的識別效果最好, 特別是在召回率和F1兩個指標(biāo)上遠(yuǎn)遠(yuǎn)超過其他類別的實(shí)體。在精確度上, 藥物最優(yōu), 其次是檢查和治療方法, 最低為疾病和癥狀, 在召回率上正好相反。這可能是因?yàn)樗幟话惚容^固定, 而且在用戶輸入信息時格式也比較規(guī)整。對于疾病和癥狀通常有多樣化的描述方式, 因此識別精度不如其他類別。
識別結(jié)果大致包含以下幾種錯誤類型: 1)識別邊界不準(zhǔn)確, 例如“胸部CT檢查”只識別出了“CT檢查”, 遺漏了相關(guān)的指示部位, “中央型肺癌”遺漏了修飾語“中央型”等情況; 2)未識別出較長實(shí)體, 像“痰中帶血絲”、“嗓子老發(fā)癢”這樣的癥狀; 3)誤分類, 例如“腔積液”(疾病)被誤分類為藥物。導(dǎo)致錯誤的原因可能與數(shù)據(jù)集規(guī)模有關(guān), 下一步可以擴(kuò)充數(shù)據(jù)集, 豐富特征, 尋找真正能抓住其本質(zhì)的特征進(jìn)行實(shí)驗(yàn)。
3.3 特征分析
對不同特征進(jìn)行的實(shí)驗(yàn)表明, 詞性特征和后綴特征對于識別效果有很大的提升, 所以本文進(jìn)行以下兩組分析。
3.3.1 各類實(shí)體詞性構(gòu)成模式分析
這里的詞性構(gòu)成綜合考慮了當(dāng)前實(shí)體的前一個詞的詞性、當(dāng)前詞的詞性和后一個詞的詞性, 如表10所示。針對被標(biāo)注為藥物的詞語“易瑞沙”, 分析其詞性構(gòu)成, 前一個是動詞“服用”, 詞性為“v”, 后一個為標(biāo)點(diǎn)符號“。”,詞性為“w”, 當(dāng)前詞詞性為藥物專有名詞“medicine”, 因此這個藥名的詞性構(gòu)成為“v+medicine+w”。為了對比不同實(shí)體類別在詞性構(gòu)成上的情況, 我們繪制不同實(shí)體的排名前30種詞性構(gòu)成模式的頻次圖(圖4)。可以看出, 藥物類的曲線非常陡峭, 說明藥物這類實(shí)體的詞性的構(gòu)成在實(shí)驗(yàn)文本中是有規(guī)律性的, 大部分具有固定的模式, 因此詞性特征才能如此好地提升藥物的識別效果。其他幾類, 雖然詞性也有一些模式, 但不如藥物明顯, 實(shí)驗(yàn)結(jié)果也有一定程度的提升。

表10 詞性分析句子示例
藥物類詞性構(gòu)成的前10種模式如表11所示。可以看出, 藥物基本上都通過分詞被準(zhǔn)確標(biāo)注為藥物專有名詞, 前后出現(xiàn)最多的詞性是標(biāo)點(diǎn)、動詞、連詞和數(shù)詞。這也準(zhǔn)確地反映了文本的潛在結(jié)構(gòu): 用戶常將多種藥物進(jìn)行羅列, 因此前后出現(xiàn)標(biāo)點(diǎn)(如頓號、逗號)和連詞(如“阿法替尼/和/azd9291/效果/怎么樣”); 藥物名前, 通常有許多提示性的動詞(如“服用/口服/使用/注射/吃/開了”); 藥物名后, 會緊接著給出服用劑量(如“維生素c/一天/2/-/3片”)。
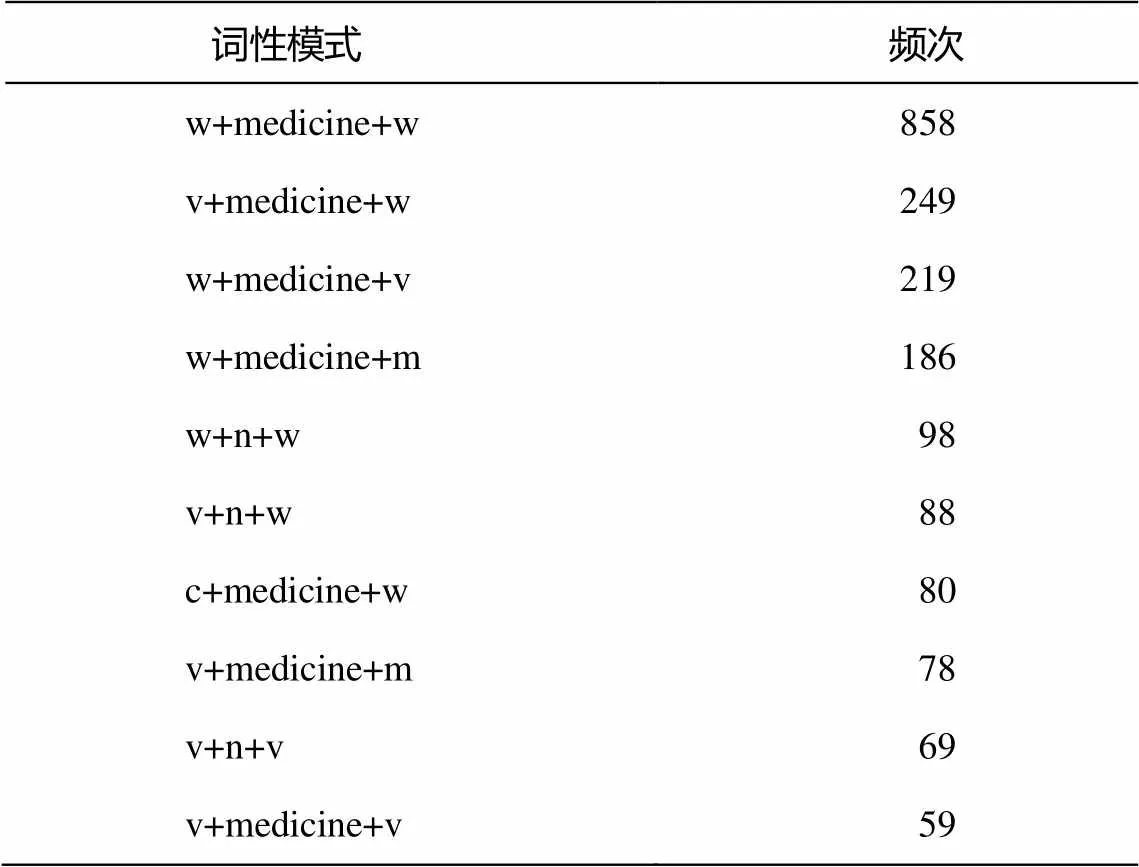
表11 藥物類詞性構(gòu)成前10種模式
說明: w為標(biāo)點(diǎn)符號, medicine為藥物專有名詞, v為動詞, m為數(shù)詞, n為名詞, c為連詞。
3.3.2 各類實(shí)體后綴分析
后綴特征對于疾病類提升較大。統(tǒng)計1000條實(shí)驗(yàn)數(shù)據(jù)中疾病名后綴的分布情況, 如圖5所示。在疾病名中, 出現(xiàn)最多的前7個字分別是炎、病、癌、喘、壓、冒、癥, 以它們結(jié)尾的疾病名共占所有出現(xiàn)的疾病的64%, 其他166個字只占36%, 說明了后綴特征對疾病名稱識別有效的原因。
圖6給出對其他幾類實(shí)體后綴的分析情況, 可以看到, 不同實(shí)體類別的后綴具有不同程度的規(guī)律,因此后綴特征才能有效地提升實(shí)驗(yàn)效果。
4 總結(jié)與展望
本文針對在線醫(yī)療問答信息, 設(shè)計了考慮醫(yī)療領(lǐng)域特性的識別特征, 并采用機(jī)器學(xué)習(xí)模型CRF, 在好大夫問答數(shù)據(jù)上針對5類醫(yī)療實(shí)體(疾病、癥狀、藥品、治療方法和檢查)進(jìn)行實(shí)體識別工作。全部設(shè)計特征包括符號特征、詞性特征、形態(tài)特征、后綴特征、身體部位指示詞特征和上下文特征。首先進(jìn)行了一組字典實(shí)驗(yàn), 表明自定義詞典對識別效果的有效提升, 然后采用逐一添加特征的方式, 觀察實(shí)驗(yàn)結(jié)果的變化情況。結(jié)果表明, 隨著所提特征的逐一添加, 識別精確度有所浮動, 而召回率普遍呈上升趨勢, 總體的F1值也不斷上升, 當(dāng)采用所提全部特征時, 達(dá)到總體81.26%的精確度和60.18%的召回率。我們還分析了后綴特征和各類實(shí)體的詞性構(gòu)成模式, 說明了該特征的有效性。
實(shí)驗(yàn)結(jié)果表明, 本文方法可以有效地識別出問答文本中大部分的醫(yī)療實(shí)體。但是還需繼續(xù)提高識別準(zhǔn)確率, 獲得更精準(zhǔn)的挖掘結(jié)果。未來的工作中, 我們將進(jìn)一步豐富實(shí)體識別的特征, 特別是針對在線的醫(yī)療問答文本, 進(jìn)一步區(qū)分問與答兩種文本的區(qū)別和聯(lián)系, 設(shè)計相應(yīng)特征并引入實(shí)驗(yàn)。我們還會考慮前面有否定意義詞匯的實(shí)體, 處理實(shí)體嵌套的情況。
[1]黃丹. 網(wǎng)絡(luò)醫(yī)療對醫(yī)療服務(wù)理念的挑戰(zhàn). 中藥研究與信息, 2006, 7(9): 31–32
[2]Grishman R, Sundheim B. Message Understanding Conference-6: a brief history // COLING. Copen-hagen, 1996, 96: 466–471
[3]Doddington G R, Mitchell A, Przybocki M A, et al. The automatic content extraction (ACE) program-tasks, data, and evaluation // LREC. Lisbon, 2004: 837–840
[4]胡雙, 陸濤, 胡建華. 文本挖掘技術(shù)在藥物研究中的應(yīng)用. 醫(yī)學(xué)信息學(xué)雜志, 2013(8): 49–53
[5]楊錦鋒, 于秋濱, 關(guān)毅, 等. 電子病歷命名實(shí)體識別和實(shí)體關(guān)系抽取研究綜述. 自動化學(xué)報, 2014, 40 (8): 1537–1562
[6]DiSantostefano J. International classification of diseases 10th revision (ICD-10). The Journal for Nurse Practitioners, 2009, 5(1): 56–57
[7]Lindberg D A, Humphreys B L, McCray A T. The unified medical language system. Methods of Infor-mation in Medicine, 1993, 32(4): 281–291
[8]McDonald C J, Overhage J M, Tierney W M, et al. The regenstrief medical record system: a quarter century experience. International Journal of Medical Informatics, 1999, 54(3): 225–253
[9]Kraus S, Blake C, West S L. Information extraction from medical notes // Medinfo 2007. Brisbane, 2007: 1–2
[10]鄭強(qiáng), 劉齊軍, 王正華, 等. 生物醫(yī)學(xué)命名實(shí)體識別的研究與進(jìn)展. 計算機(jī)應(yīng)用研究, 2010, 27(3): 811–816
[11]Sondhi P, Gupta M, Zhai C X, et al. Shallow information extraction from medical forum data // Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics. Beijing, 2010: 1158–1166
[12]葉楓, 陳鶯鶯, 周根貴, 等. 電子病歷中命名實(shí)體的智能識別. 中國生物醫(yī)學(xué)工程學(xué)報, 2011, 30(2): 256–262
[13]王世昆, 李紹滋, 陳彤生. 基于條件隨機(jī)場的中醫(yī)命名實(shí)體識別. 廈門大學(xué)學(xué)報: 自然科學(xué)版, 2009, 48(3): 359–364
[14]Luhn H P. The automatic creation of literature abstracts. IBM Journal of Research and Development, 1958, 2(2): 159–165
[15]Lafferty J, McCallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data // ICML’01 Proceedings of the Eighteenth International Conference on Machine Learning. San Francisco, 2001: 282–289
[16]Sutton C, McCallum A. An introduction to conditional random fields. Machine Learning, 2011, 4(4): 267–373
[17]University of Leeds UK. Hidden Markov Models [EB/OL]. (2010)[2014–11–01]. http://www.comp.lee ds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html
[18]孫建. Ansj_seg [EB/OL]. (2012–09–07) [2014–12–01]. https://github.com/NLPchina/ansj_seg
[19]Ramshaw L A, Marcus M P. Text chunking using transformation-based learning // Text Speech & Lan-guage Technology. Boston, 1995: 82–94
[20]Kudo T. CRF++: Yet another CRF toolkit [EB/OL]. (2005) [2015–03–01].http://CRFpp.sourceforge.net
[21]Powers D M. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. Journal of Mach Learn Technol, 2011, 2(1): 37–63
[22]Tjong K S E F, Buchholz S. Introduction to the CoNLL-2000 shared task: chunking // Proceedings of the 2nd Workshop on Learning Language in Logic and the 4th Conference on Computational Natural Language Learning-Volume 7. Lisbon, 2000: 127–132
Entity Recognition Research in Online Medical Texts
SU Ya, LIU Jie?, HUANG Yalou
College of Computer and Control Engineering (Software Institute), Nankai University, Tianjin 300071; ? Corresponding author, E-mail: nkjieliu@gmail.com
The authors design recognition features with the consideration of medical field characteristic for the online medical text, and the experiment of the entity recognition is carried out on the self-built data set. Concerned about five common diseases: gastritis, lung cancer, asthma, hypertension and diabetes. In the experiment, an advanced machine learning model Conditional Random Field is used for training and testing. The target entities include five kinds: disease, symptoms, drugs, treatment methods and check. The effectiveness of the proposed features is verified by using the experimental method, and the accuracy of the total 81.26% is obtained and the recall rate is 60.18%. Subsequently, the further analysis is given for the recognition features.
named entity recognition; data mining; conditional random field; medical information
10.13209/j.0479-8023.2016.020
TP391
2015-06-06;
2015-08-16; 網(wǎng)絡(luò)出版日期: 2015-09-30
天津市科技支撐項(xiàng)目(13ZCZDGX01098)、天津市自然科學(xué)基金(14JCQNJC00600)和中國民航信息技術(shù)科研基地開放課題(CAAC-ITRB-201303)資助
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
