基于文本蘊含的選擇類問題解答技術研究
2016-10-13 04:28:14王寶鑫鄭德權王曉雪趙姍姍趙鐵軍
北京大學學報(自然科學版) 2016年1期
王寶鑫 鄭德權 王曉雪 趙姍姍 趙鐵軍
?
基于文本蘊含的選擇類問題解答技術研究
王寶鑫 鄭德權?王曉雪 趙姍姍 趙鐵軍
哈爾濱工業大學計算機科學與技術學院, 哈爾濱 150001; ?通信作者, E-mail: dqzheng@mtlab.hit.edu.cn
利用選擇類問題具有明確候選項的特點, 簡化問題分類過程, 并針對長文本語義蘊含短文本語義的語言現象, 提出一種根據文本蘊含強度大小對候選答案進行排序的方法。在沒有大規模問答對的情況下, 采用維基百科中文語料庫, 以全國各省市高考地理選擇題作為實驗數據, 通過句子相似度和文本蘊含兩種方法來解答地理選擇題。實驗表明, 基于文本蘊含方法的準確率為36.93%, 比基于詞嵌入的句子相似度方法提高2.44%, 比基于向量空間模型的句子相似度方法提高7.66%, 驗證了該文本蘊含強度計算方法的有效性。
文本蘊含; 選擇題; 詞嵌入; 句子相似度
問答系統通常分為三類: 基于知識庫的問答系統、基于大規模文本的問答系統和基于問答對的問答系統[1]。隨著互聯網的快速發展以及電子文本的增多, 社區問答系統(community question answering, CQA)和基于大規模文本的問答系統的相關研究不斷增多, 但是針對選擇題這類對人們日常生活和學習影響較大的問答系統的研究相對較少。
本文對具有明確候選項的選擇題問答系統進行研究, 利用大規模維基百科中文語料作為數據源, 提出一種根據文本蘊含強度大小對候選答案進行排序的方法, 利用選擇題選項的規范性來確定問題分類, 降低了問題分析過程的復雜度。最后將本文的方法與傳統的句子相似度計算方法進行比較。
1 相關工作
1.1 文本蘊含相關工作
文本蘊含[2]是一個連貫文本與一個假設文本之間的一種關系, 如果假設文本的語義可以通過文本推斷出來, 則認為文本蘊含文本。文本蘊含由Dagan等[2]在2004年提出, 其相關的任務一般包含識別、產生和抽取, 其中關于文本蘊含識別(recognize textual entailment, RTE)的相關研究相對較多, RTE在問答系統、信息抽取、機器翻譯評測等很多應用中起關鍵作用[3]。RTE常采用的方法有單獨基于詞匯、句法、淺層語義的無監督方法和基于分類器的有監督學習方法等[4]。有監督方法往往需要較多訓練數據, 并且對于訓練數據的領域依賴性較強, 因此本文采用基于詞匯的無監督方法。以往對文本蘊含識別的研究多集中在兩個句子之間, 評測的任務也僅僅是評估句子是否蘊含句子。本文文本蘊含識別則是集中在長文本與短語之間、長文本與句子之間。實際上, 兩個文本之間是否存在蘊含關系很難分清界限, 所以現有的文本蘊含識別系統多是根據某一確定標準來判斷兩個句子是否存在蘊含關系。由于本文研究的是已有明確候選答案的選擇題類問答系統, 需要比較文本對文本1的蘊含關系是否大于文本對文本2的蘊含關系, 而不是簡單地判斷兩個文本之間是否存在蘊含關系。因此, 為衡量蘊含關系的大小, 本文提出文本蘊含強度的概念。
1.2 問答系統相關工作
問答系統一般包含3個主要組成部分: 問題分析、信息檢索和答案抽取。依據處理數據的格式, 問答系統可以劃分為三類: 基于知識庫的問答系統、基于自由文本的問答系統和基于問題答案對的問答系統。早期的問答系統大部分是基于知識庫的問答系統, 但是由于知識庫構建需要消耗大量的資源, 產生的問答系統局限性也比較大, 所以該類問答系統多用來解決限定領域的問題。隨著互聯網的興起, 網絡上的文本數量激增, 隨之興起的是基于自由文本的問答系統, 即從已經存在的非結構化文本中抽取答案。自2005年末以來, 隨著CQA數據的大量出現, 問題答案對數量的增多[5], 基于問答對的問答系統逐漸成為研究熱點。
本文采用全國各省市高考地理選擇題作為實驗數據, 進行關于選擇題問答系統的研究。由于知識庫的匱乏, 構建知識庫需要消耗大量人力和時間, 且關于高考題的問答對的數目相對較少, 重復問題出現的可能性低, 因此本文采用依賴于自由文本的問答系統。本文的選擇題問答系統可以看做問答對類和自由文本類問答系統的結合: 一方面, 它與CQA一樣擁有天然的候選答案可供選擇; 另一方面, 該系統通過自由文本對選擇題進行解答。傳統的基于自由文本的問答系統由于沒有天然可靠的候選答案, 所以問題研究的重點多集中在對問題精細分類、從文本中檢索相關信息以及從文本中抽取簡潔的答案等方面。本文中涉及的選擇題問答, 由于候選選項已經確定, 所以重點研究如何對候選項進行評分排序。本文采用計算文本蘊含(textual entailment, TE)強度的方法來解決選擇題型問答。
2 算法與理論推導
2.1 問題定義
定義1 文本蘊含強度。
對于一個連貫文本與一個假設文本, 如果可以根據推斷出, 則說明與之間存在一個有向的文本蘊含關系。過去對于文本蘊含的研究多集中于兩個文本與是否含有蘊含關系, 然而在很多實際任務中, 不僅需要定性地判斷兩個文本之間是否存在蘊含關系, 而且在不蘊含的情況下, 可能還需要判斷是否部分蘊含, 以及部分蘊含多少[6]。例1給出一個部分蘊含的示例。
例1: 李娜出生于1982年, 是中國著名網球運動員。
: 李娜是中國女子網球運動員。
在例1中可以看到, 從句中可以推斷出句的部分信息, 然而并不能推斷出句的全部信息, 其中“女子”這一信息無法從句中推斷出來。
針對此現象, 本文提出文本蘊含強度的概念, 文本對的文本蘊含強度指與之間信息的交集占全部信息的比重, 即連貫文本對假設文本的蘊含關系的大小。
定義2 長文本蘊含。
過去針對文本蘊含的研究, 多是判斷兩個句子之間的蘊含關系。然而實際問題中, 可能會出現需要判斷長文本(多個句子)對一個句子的文本蘊含關系, 即長文本蘊含。例2給出一個長文本對單句的語義蘊含示例。
例2: 李娜, 1982年2月26日出生在湖北省武漢市, 中國女子網球運動員。2008年北京奧運會女子單打第四名。
: 網球運動員李娜在2008年北京奧運會獲得女子單打第四名。
顯然從文本可以推斷出文本, 因此文本蘊含文本。然而文本包含兩個句子, 每個句子分別包含一部分文本的信息, 過去RTE的很多研究方法對于該類問題并不適用。
RTE常常采用有監督的機器學習算法, 將其作為一個分類任務進行解決, 但是在文本是多個句子的情況下, 很多特征對該類問題并不適用, 并且需要人工標注較多的訓練數據(長文本蘊含的標注往往需要消耗更多的時間和人力)。Glickman等[7]采用基于詞對齊的產生式模型, 計算文本蘊含關系, 但是他們只考慮了詞之間的共現關系而忽視了詞語語義、詞語位置等信息。Jijkoun等[8]利用詞語相似度的方法來識別兩個句子的語義蘊含關系, 但其語義相似度是基于WordNet計算的, 有一定局限性, 并且也沒有考慮詞語位置的關系。本文改進了文獻[7-8]的算法, 提出一個啟發式算法對文本蘊含強度進行求解。
2.2 文本蘊含強度計算方法
文本對文本的蘊含強度大小TES(Textual Entailment Strength)滿足式(1):
其中,表示連貫文本的詞數,表示假設文本的詞數,表示文本中的詞對文本中的詞語義蘊含的大小,表示詞語對應蘊含強度占總蘊含強度的權重。本文用與之間的相似度來近似估計對的語義蘊含大小。
可以這樣理解式(1): 對于文本中的每個詞, 找到在文本中與它相似度最高的詞, 計算與之間的相似度, 最后再對所有詞語相似度加權平均, 求得文本蘊含強度。其中與的關系相當于一種詞對齊關系, 如圖1所示。
的計算過程如下: 定義()表示文本出現的概率,()表示詞語所在文本出現的概率,(|)表示在詞語出現的情況下, 文本出現的概率。直觀上,(|)越大,在公式中所占的比重越大。
由貝葉斯公式(式(2))可知, 當(|H)=1,()為定值時,(|)與成正比。恰好是IDF(inverse document frequency), 常用來表示一個詞語對文本的區分度。本文使用式(3)所示的歸一化IDF作為權重。
傳統詞義相似度計算多是通過WordNet和HowNet等知識庫計算的, 因此詞義相似度的計算效果往往會受限于知識庫的大小。近幾年, 基于神經網絡的Word Embedding因其在詞語語義表示方面的良好性能受到廣泛關注[9–11]。Word Embedding將語料庫中的每個詞表示為一個低維實數向量, 可以很好地表示兩個詞語語義之間的距離。Glickman等[7]的方法需要計算任意兩個詞語在一句話的共現次數, 往往需要較大的空間開銷。Word Embedding也利用了詞共現的信息, 并且能更好地表達一個詞語的語義。因此, 本文中的相似度是采用Word Embedding計算余弦相似度得到的, 余弦相似度的計算如下:
將式(1)~(4)的過程進行總結,得到算法1。
算法1 基于詞語相似度的文本蘊含強度計算。
初始化:
總相似度totalSim=0
總權重totalWeight=0
1 for= 1, ...,do
3 totalSim+=IDF(v) maxSim
4 totalWeight+=IDF(v)
5 end for
6 文本蘊含強度TES=totalSim/totalWeight
7 Return TES
2.3 算法改進
算法1雖然可以在一定程度上表達文本蘊含關系, 但是沒有考慮詞語位置信息。當文本過長時, 如果文本中相鄰的兩個詞在文本中所對應的詞之間的距離很大, 那么與的詞語之間的語義蘊含強度相應降低, 如例3所示。
例3: 新月與滿月時, 太陽、地球、月球呈一直線, 潮差最大, 稱作大潮; 上下弦月時, 三者呈直角, 潮差最小, 稱為小潮。
1: 地球處在太陽與月球之間, 出現大潮。
2: 地球處在太陽與月球之間, 出現小潮。
對于例3, 顯然文本對1的文本蘊含強度應該大于對2的蘊含強度。事實上, 從文本可以推斷出1, 而無法推斷出2。因此, 我們提出對應的改進算法, 相應的蘊含強度計算如下:
其中,和分別表示假設文本和連貫文本的詞數,表示詞語在文本中所在的位置下標,表示詞語在文本中對應詞所在的位置下標, 即是文本中的兩個詞之間的距離。
文本中相鄰的兩個詞所對應的文本中的兩個詞距離越遠, 其語義蘊含強度越低, 且這種降低趨勢隨距離增大先緩慢降低, 到一定距離后再加速降低, 最后再緩慢降低, 高斯函數(式(6))正好滿足這種下降趨勢。
我們用動態規劃求解獲得最終TES的值, 具體描述如算法2所示。
算法2 改進的文本蘊含強度計算
輸出: 文本蘊含強度TES
1 初始化:
2 遞推:
3 終止:
3 選擇類問題解答及分析
鑒于高考地理題具有易獲取、少干擾、形式規范以及可靠性高的特點, 本文采用各地高考近十年的地理選擇題, 去除其中含有圖片的題目以及計算類題目, 剩余287道選擇題作為最終的實驗數據。
本文方法分為預處理、問題分析、信息檢索與答案抽取4個模塊, 如圖2所示。
3.1 預處理
預處理階段, 對維基百科文本語料進行分詞, 并用分詞后的維基百科中文文本語料和Mikolov 等[10–11]提出的word2vec工具實現Word Embedding的訓練。使用目前國際上句法分析效果比較好的ZPar[12]工具, 對選擇題選項進行句法分析。
3.2 問題分析
3.2.1 關鍵詞抽取
本文通過傳統的TF-IDF方法來提取關鍵詞, 即根據計算選擇題題干部分的TF-IDF的數值大小進行排序, 去除停用詞后, 依據TF-IDF值的大小依次選取關鍵詞, 本文實驗中選取的關鍵詞數目為3。例4是一道高考地理選擇題的實例。例5是針對例4的一個抽取關鍵詞的例子。從例5可以看出, 基于TF-IDF抽取關鍵詞的方法雖然簡單, 但是在地理選擇題題干中的表現很好。
例4 春季, 歐洲阿爾卑斯山區, 背風坡常常出現冰雪迅速融化或雪崩。其主要原因是
A. 反氣旋控制下沉增溫
B. 暖鋒過境釋放熱量
C. 西風帶南移釋放熱量
D. 局地氣流下沉增溫
例5 題干:“春季, 歐洲阿爾卑斯山區, 背風坡常常出現冰雪迅速融化或雪崩。其主要原因是”。抽取關鍵詞:背風坡、阿爾卑斯、雪崩。
3.2.2 問題分類
傳統問答系統的問題分類通常比較精細, 一方面為了確定答案的類型, 同時也為了對不同類別的問題采用不同的方法來解答。本文采用的高考題具有規范性, 候選答案的形式規范且符合問題要求。根據該特點, 依據選擇題的選項對問題分為兩大類:一類是候選答案為名詞短語的選擇題; 另一類是候選答案為句子的選擇題。本文對選項的分析判斷采用句法分析, 4個選項中含有名詞短語(NP)的選項有兩個及兩個以上則為名詞短語類型, 否則即為句子類型(IP)。
例6是一道地理選擇題, 其中的4個選項都是NP, 因此該選擇題將會被劃分為名詞短語類型。
例6 人類已知月球上的能源有
A. (NP (NN 生物能) (PU 、) (NN 風能))
B. (NP (NN 核能) (PU 、) (NN 潮汐能))
C. (NP (NN 潮汐能) (PU 、) (NN 太陽能))
D. (NP (NN 太陽能) (PU 、) (NN 核能))
3.2.3 問句正誤傾向分析
選擇題經常會要求判斷“不正確”、“錯誤”或“不合理”。對于這類問題, 我們將其識別出來, 為后面的答案抽取過程提供幫助。該部分主要通過人工配置詞典的方法, 對選擇題題干進行識別, 例如, 在題目的問句中出現“不正確”一詞, 則將該問題作為錯誤傾向類的問題。
3.3 信息檢索
對中文維基百科的詞條建立索引, 根據問題分析階段抽取出來的關鍵詞, 在維基百科語料中檢索相應的詞條, 將與其對應的百科文本提取出來。
3.4 答案抽取
該階段分別采用句子相似度和文本蘊含兩種方法來實現答案抽取。最后根據問題分析中的正誤傾向性判斷來選擇答案。如果是正向問題, 則選擇分值最高的選項, 否則, 選擇分值最低的選項。
3.4.1 句子相似度
在中文維基百科文本中檢索關鍵詞對應的百科文本, 將選項與百科文本中的所有句子一一進行相似度計算, 選取最高的相似度作為該選項最終的分數。相似度計算分別采用基于TF-IDF的向量空間模型和基于Word Embedding的句子相似度計算。
基于VSM的句子相似度: 將兩個句子表示為兩個向量, 向量的每一維權值對應每個詞的TF-IDF值, 再對兩個向量計算余弦相似度, 作為兩個句子最終的相似度。
基于Word Embedding的句子相似度: 如式(7)和(8)所示, 將句子中每個詞的Word Embedding向量相加取平均值作為句子的向量, 再對兩個句子的向量計算余弦相似度, 作為兩個句子最終的相似度。
3.4.2 文本蘊含
將關鍵詞對應的維基百科文本整體作為文本, 句子選項作為文本, 對短語類的問題采用算法1, 對句子類的問題采用算法2, 計算對的文本蘊含強度。
4 實驗結果與分析
由于本文問答系統中候選項已經確定, 正確答案一定會出現在候選項中, 且每道題都有固定的4個候選項, 所以本文對問答系統的評測標準采用準確率。算法2中高斯函數的參數設置如下:,。
根據句子相似度和文本蘊含得到的最終問答系統準確率如表1所示。從表1可見, 基于Word Embedding的相似度計算方法好于基于VSM的方法。可見基于Word Embedding的方法比VSM的方法能更好地表達句子的語義。從表1還可以看出, 算法1對名詞短語類的問題效果比較好, 而算法2對于句子類的問題效果較好。綜合兩種方法后, 本文提出的方法最終的準確率可達36.93%。
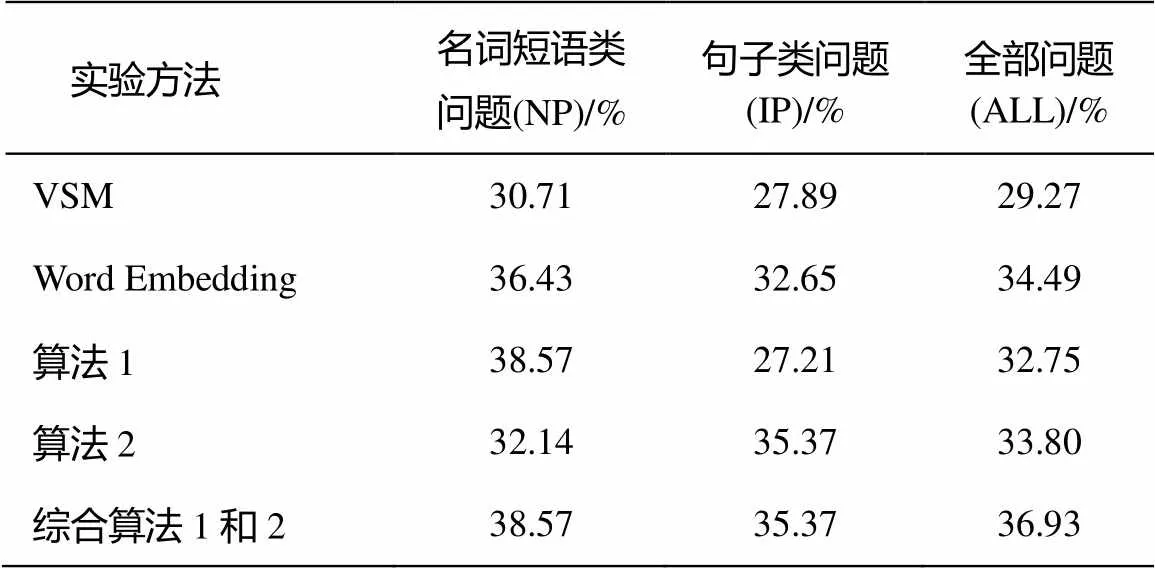
表1 實驗結果
為了驗證本文方法的有效性, 在選取關鍵詞對應的百科全部文本作為連貫文本之外, 還將百科文本中不同數目的連續句子作為進行實驗, 選取其中最大的文本蘊含強度作為最終選項的分值。
圖3是對應的實驗結果, 可以看出, 算法1對應名詞短語類問題的解答準確率隨著句子數目的增大而呈上升趨勢, 但是算法1卻無法對候選項為句子的問題進行有效解答。隨著句子數目增大, 算法1對句子類問題逐漸失效。原因可能有以下兩點: 1)算法1無法很好地分析含有完整句法結構的句子所對應的文本蘊含情況; 2)詞短語部分的選擇題更傾向于概念類題目, 相對簡單, 而候選答案為句子的選擇題分析則較為復雜, 需要更深層的語義分析, 因此無法直接從百科抽取答案。
例7是在算法2中正確而在算法1中錯誤的一個例子(算法2的答案為D, 算法1的答案為A), 其對應的候選項都為句子。例7在一定程度上反映了算法2對候選項為句子的問題的解答效果比算法1好。
例7 在森林中一旦遭遇火災, 下列做法正確的是
A. 使用沾濕的毛巾遮住口鼻, 順風逃離
B. 如果火勢突然減弱, 則可以放心休息
C. 選擇低洼地或坑洞躲避
D. 伺機逆風突破林火包圍
算法2在名詞短語類問題上的表現不如算法1, 原因可能是名詞短語類選項大多由多個實體名詞混合在一起組成, 在百科文本中出現的位置相對分散, 限制其位置會導致最終的準確率較低。算法2對于候選項為句子的問題解答效果顯然比算法1好很多, 并且其準確率隨著句子數目增多而增大, 這也說明算法2對于計算長文本對句子的文本蘊含強度的效果明顯。
5 結論
本文針對選擇類問題解答方法進行了研究, 提出了一種新的計算文本蘊含強度的方法。在沒有大規模訓練數據的情況下, 僅用維基百科中文語料庫, 通過Word Embedding計算文本蘊含強度來解決地理選擇類問題, 最終基于文本蘊含方法的準確率為36.93%, 比基于VSM的句子相似度方法的準確率高7.66%, 比基于Word Embedding的句子相似度方法高2.44%。實驗驗證了本文提出的文本蘊含計算方法對長文本蘊含短文本的情況效果明顯, 并且文本蘊含也是解答選擇類問題的有效的方法。
由于本文關于文本蘊含強度的計算方法是分別針對長文本對短語和長文本對句子兩種類型的文本蘊含情況進行的, 所以該方法在句子對句子類型的文本蘊含強度的計算效果仍有待提升。此外, 對于推理類地理選擇題, 本文的方法在很多情況下并不適用, 需要后期構建大型的知識庫以及邏輯推理框架來解決。
[1]毛先領, 李曉明. 問答系統研究綜述. 計算機科學與探索, 2012, 6(3): 193-207
[2]Dagan I, Glickman O. Probabilistic textual entail-ment: generic applied modeling of language varia-bility // Proc of the Pascal Workshop on Learning Methods for Text Understanding & Mining. Grenoble, 2004: 26–29
[3]Androutsopoulos I, Malakasiotis P. A survey of paraphrasing and textual entailment methods. Journal of Artificial Intelligence Research, 2009, 38(4): 135–187
[4]袁毓林, 王明華. 文本蘊涵的推理模型與識別模型. 中文信息學報, 2010, 24(2): 3–13
[5]張中峰, 李秋丹. 社區問答系統研究綜述. 計算機科學, 2010, 37(11): 19–23
[6]Levy O, Zesch T, Dagan I, et al. Recognizing partial textual entailment // Proceedings of the 51st Annual Meeting of the Association for Computational Lingui-stics. Sofia, 2013: 451–455
[7]Glickman O, Dagan I M. A lexical alignment model for probabilistic textual entailment // Machine Lear-ning Callenges: Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Tectual Entailment. Berlin: Springer, 2006: 287–298
[8]Jijkoun V, de Rijke M. Recognizing textual entailment using lexical similarity // Proc of the First PASCAL Challenges Workshop on RTE. Southampton, 2005: 73–76
[9]Collobert R, Weston J. A unified architecture for natural language processing: deep neural networks with multitask learning // Proceedings of the 25th International Conference on Machine Learning. Helsinki, 2008: 160–167
[10]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space // Proceedings of the Workshop at ICLR. Scottsdale, 2013: 1–12
[11]Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality // Proceedings of Neural Information Processing Systems. Lake Tahoe, 2013: 3111–3119
[12]Zhang Y, Clark S. Syntactic processing using the generalized perceptron and beam search. Compu-tational Linguistics, 2011, 37(1): 105–151
Multiple-Choice Question Answering Based on Textual Entailment
WANG Baoxin, ZHENG Dequan?, WANG Xiaoxue, ZHAO Shanshan, ZHAO Tiejun
School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001; ? Corresponding author, E-mail: dqzheng@mtlab.hit.edu.cn
This paper proposes a method to compute textual entailment strength, taking multiple-choice questions which have clear candidate answers as research objects, aiming at the phenomenon of long text entailing short text. Two methods are used to answer the college entrance examination geography multiple-choice questions based on the Wikipedia Chinese Corpus in the absence of large-scale questions and answers. One is based on the sentence similarity and the other is based on the textual entailment proposed above. The accuracy rate of the proposed method is 36.93%, increasing by 2.44% than the way based on the word embedding sentence similarity, increasing 7.66% than the way based on the Vector Space Model sentence similarity, which confirm the effectiveness of the method based on the textual entailment.
textual entailment; multiple-choice question; word embedding; sentence similarity
10.13209/j.0479-8023.2016.017
TP391
2015-06-19;
2015-08-17; 網絡出版日期: 2015-09-29
國家自然科學基金(61173073)和863計劃(2015AA015405)資助
