基于數(shù)字標牌廣告數(shù)據(jù)的興趣點推薦算法研究
2016-08-05 08:04:50解貴龍于重重
計算機應(yīng)用與軟件 2016年7期
關(guān)鍵詞:區(qū)域
解貴龍 張 珣 于重重 趙 霞
(北京工商大學計算機與信息工程學院 北京 100048)
?
基于數(shù)字標牌廣告數(shù)據(jù)的興趣點推薦算法研究
解貴龍張珣*于重重趙霞
(北京工商大學計算機與信息工程學院北京 100048)
摘要為了解決數(shù)字標牌廣告投放的推薦問題,研究基于位置數(shù)據(jù)的推薦算法。在已有的基于矩陣分解思想的興趣點推薦算法基礎(chǔ)上,提出結(jié)合矩陣分解思想和商業(yè)地理信息數(shù)據(jù)的興趣點推薦模型,并在基于位置的數(shù)字標牌廣告數(shù)據(jù)上進行實驗。實驗結(jié)果表明,通過為矩陣分解附加商業(yè)地理信息的方法,解決了位置訪問數(shù)據(jù)稀疏性的問題,并為數(shù)據(jù)類型單一,推薦依據(jù)不足的問題提供了有效的數(shù)據(jù)參考及實現(xiàn)方法。為數(shù)字標牌廣告投放提供了重要的參考依據(jù)。
關(guān)鍵詞興趣點推薦數(shù)字標牌位置推薦矩陣分解
0引言
數(shù)字標牌是一種全新的媒體概念, 指的是在大型商場、超市、酒店大堂、飯店、影院及其他人流匯聚的公共場所,通過大數(shù)字標牌終端顯示設(shè)備,發(fā)布商業(yè)、財經(jīng)和娛樂信息的多媒體專業(yè)視聽系統(tǒng)[1]。然而,傳統(tǒng)的數(shù)字標牌的選址,廣告的投放均由人工完成,時效性低、缺乏參考依據(jù)、已經(jīng)不能滿足廣大廣告主和媒體商的利益需求[2]。因此,構(gòu)建廣告精準投放推薦模型,為廣告主用戶提供廣告牌的推薦,實現(xiàn)廣告商和媒體商的利益最大化,成為值得研究的課題。本文所研究的興趣點推薦即可為廣告投放方提供有關(guān)數(shù)字標牌的地理屬性和商業(yè)屬性的分析結(jié)果,從而達到廣告在時間、空間、個性化上精準投放的目的。
本文所要研究的興趣點推薦是推薦領(lǐng)域比較新的研究點,其中一個重要特性就是位置數(shù)據(jù),訪問或簽到,它可以看成推薦系統(tǒng)中常見的隱式評分數(shù)據(jù)。隱式評分是相對于顯示評分而言的,它不需要用戶額外行動,而是根據(jù)用戶行為判斷對待推薦物品的喜好或厭惡程度。而對這種隱式數(shù)據(jù)的處理主要是量化這種喜好或厭惡程度的操作。2010年Ye Mao等人利用用戶社交好友的協(xié)同評分和通過距離衡量好友之間的相似性進行興趣點推薦[3],但此方法忽略了隱式數(shù)據(jù)的處理。2012年Cheng Chen等人基于用戶簽到頻率,利用矩陣分解思想進行興趣點推薦[4],很好地處理了隱式數(shù)據(jù),但是并沒有考慮到地理特征等其他因素的影響。同時還有些工作利用這些位置信息通過對空間聚集效應(yīng)建模來幫助位置推薦[5,6],但是這些方法是獨立于協(xié)同過濾的。2014年Lian De-Fu等人在此基礎(chǔ)上提出了基于地理建模內(nèi)嵌的加權(quán)矩陣分解方法進行興趣點推薦[7],擴展了地理特征因素,并為可能添加的其他因素提供了一種方法。
本文研究的興趣點推薦,主要針對廣告-興趣點矩陣稀疏性處理及數(shù)字標牌位置數(shù)據(jù)的特性分析處理這兩個問題展開。針對于以上兩個問題,本文基于Lian De-fu等人提出的GeoMF算法[7],結(jié)合數(shù)字標牌數(shù)據(jù)特點,提出一種考慮位置的社會經(jīng)濟數(shù)據(jù)作為推薦指標的推薦算法,該算法較有效地解決了上述問題。
1基于位置廣告數(shù)據(jù)的興趣點推薦算法
1.1基本矩陣分解推薦算法
運用矩陣分解做推薦面臨最大的挑戰(zhàn)是數(shù)據(jù)的稀疏性。對于缺失的評分,可以轉(zhuǎn)化為基于機器學習的回歸問題,也就是連續(xù)值的預測,矩陣分解如下:
(1)
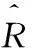
(2)


(3)
其中β是正則參數(shù)。最后的目標,就是每一個非缺失值元素的損失函數(shù)的總和最小。
為了快速有效地得到損失函數(shù)的最小值,需要對損失函數(shù)的更新采用優(yōu)化算法。下面式(4)為基于梯度下降的優(yōu)化算法,式(5)是P、Q矩陣里面每個元素的更新方式:
(4)
(5)
其中,θ、β均為優(yōu)化參數(shù)。
對于類似播放頻次這種隱式數(shù)據(jù),加權(quán)矩陣分解會在大部分的隱式數(shù)據(jù)上工作得很好,因為它把所有的未投放位置都作為負樣本,并給它們賦了一個更小的權(quán)重[8,9]。在加權(quán)矩陣分解中,對損失函數(shù)的每一項進行了加權(quán)修改:
(6)
其中wij為權(quán)重矩陣W第i行j列的元素,wij元素的值如下:
(7)
其中α(cij)為R矩陣每個元素的值,這表明權(quán)重是依賴于訪問頻率的。這樣的設(shè)置可以體現(xiàn)訪問頻率是用戶偏好的置信值的特性。
1.2基于數(shù)字標牌廣告投放的興趣點推薦模型
本文所采用的興趣點推薦算法原理主要如圖1興趣點推薦算法原理所示,每個數(shù)字標牌實體即為一個興趣點。首先構(gòu)造出廣告在興趣點上的播放頻次矩陣,然后通過矩陣分解算法將該矩陣分成兩個隱式特征和對應(yīng)興趣點和廣告組成的隱式空間,再通過附加上廣告播放范圍矩陣和興趣點影響力矩陣,最后合并兩個矩陣,形成最后的推薦結(jié)果矩陣。這樣則可為播放頻次數(shù)據(jù)引入可能影響推薦效果的其他數(shù)據(jù),從而提高推薦結(jié)果的可信度。

圖1 興趣點推薦算法原理
圖1中,播放頻次矩陣R的每一個元素rij(其中1≤i≤M,1≤j≤N)為廣告類型xi對應(yīng)在數(shù)興趣點yj上的對于播放時間加權(quán)的播放頻次,i的最大值數(shù)為廣告類型數(shù)M,j的最大值為興趣點的個數(shù)N。由此矩陣直接進行矩陣分解得到的兩個隱式特征矩陣(分別為M行K列和K行N列)組成的隱式空間。根據(jù)矩陣分解及內(nèi)積的性質(zhì),可以為這兩個隱式特征矩陣附加上包含其他信息的矩陣。當附加廣告播放范圍矩陣X(M行L列)和興趣點影響力矩陣Y(L行N列)時,可以有效表達廣告類型對不同興趣點的偏好,所以本文選取此兩矩陣作為附加信息,根據(jù)這兩個矩陣的信息,為興趣點推薦提供更多的可信度。
廣告類型分布范圍矩陣是由一系列區(qū)域以及廣告類型在這些區(qū)域上出現(xiàn)的可能性共同組成的。而興趣點的影響范圍矩陣是由興趣點能影響到的區(qū)域以及興趣點對它們的影響力值所組成的。對于興趣點的影響范圍,當假設(shè)區(qū)域是通過把目標地域劃分成L個的均勻網(wǎng)格得到的,表示為L={g1,g2,…,gi}(其中1≤i≤l)。因此定義如下:
定義1廣告分布區(qū)域,一類廣告的分布區(qū)域是指有一系列的廣告可能會出現(xiàn)的網(wǎng)格區(qū)域gi(1≤i≤l),在上面可能出現(xiàn)的非負的可能性x()i對所組成的。
本文可以把廣告的分布區(qū)域表示成一個非負向量x={x1,x2,…,xi}(1≤i≤l)。其中每一個元素xl表示了此廣告在網(wǎng)格區(qū)域gl出現(xiàn)的可能性。
定義2興趣點的影響范圍,即一個興趣點的影響范圍是由一系列的興趣點能影響到的網(wǎng)格區(qū)域gl和在網(wǎng)格區(qū)域上的非負影響力yl對所組成的。
影響力的分布對于每個具體位置是連續(xù)并與周圍位置有相互影響的,如圖2影響力分布示例。
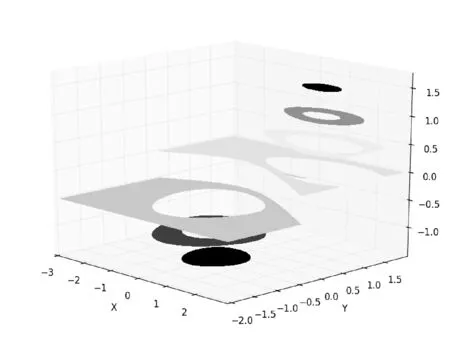
圖2 影響力分布示例
X軸和Y軸分別表示地塊的經(jīng)度和維度的相對坐標,其中X軸坐標坐標由-3到2,Y軸坐標由-2到2,Z軸表示影響力的值。從圖中可以看出某一具體位置的影響力。實際數(shù)字標牌影響力是沒有負值的。此處為方便顯示影響力的變化趨勢引入負值。
同樣,興趣點影響范圍區(qū)域也可以被轉(zhuǎn)化成一個非負向量y={y1,y2,…,yi}(1≤i≤l)。當假設(shè)興趣點的影響力是固定的且是以這個興趣點為中心正態(tài)分布的。那么興趣點i在網(wǎng)格區(qū)域gl的影響力如下:
(8)
其中K(·)為標準正態(tài)分布而σ則是標準差。d(l,i)表示興趣點i與gl網(wǎng)格區(qū)域的距離。然而實際情況興趣點的影響力往往是不同的,興趣點的影響力受諸多因素影響,而其中一個可能影響最大的因素是社會經(jīng)濟因素,如人口、收入等因素。為此,本文希望通過對一些社會經(jīng)濟因素的分析,將興趣點的影響力函數(shù)進行修正為:
(9)
其中ti為修正系數(shù),直接決定于興趣點所屬網(wǎng)格區(qū)域gi的社會經(jīng)濟因素。為此,本文構(gòu)建該修正系數(shù)矩陣:
(10)
其中ki,j表示第j個社會經(jīng)濟因素在i興趣點所在地塊區(qū)域上的取值,wj表示第j個社會經(jīng)濟因素的權(quán)重。各個權(quán)重的調(diào)整可根據(jù)不同網(wǎng)格區(qū)域所播放的廣告時長總和比例及各個社會經(jīng)濟因素的比值進行調(diào)整。假設(shè)每個社會經(jīng)濟因素之間互不影響,將有廣告播放記錄的網(wǎng)格區(qū)域挑選出來,選取其中一個區(qū)域作為基準區(qū)域,以此區(qū)域各社會經(jīng)濟因素比例為基準設(shè)置初始權(quán)重。然后任意選取一個剩余區(qū)域,按廣告播放時長比例與對應(yīng)社會經(jīng)濟因素比例的比值逐步調(diào)整權(quán)重,進一步以更新后的權(quán)重為基準繼續(xù)進行權(quán)重修正,直到所有有播放記錄的區(qū)域迭代完即止。這樣選取區(qū)域的好處在于每個區(qū)域所做的比較基本相同,因為目前還沒法證明某個區(qū)域具有權(quán)重調(diào)整的代表性。第j個權(quán)重更新表達式為:
(11)
其中sn+1和sn分別表示后一次選擇的區(qū)域的廣告播放時長總和和前一次所選區(qū)域廣告播放時長總和。
這樣設(shè)置影響力向量的優(yōu)點是x和y之間的點積對應(yīng)了對廣告類型投放位置的核密度估計。具體來說,廣告類型u在興趣點i上的估計密度等于:
(12)
其中Pu是廣告類型u的投放興趣點集合。如果這些興趣點Pu被映射到相應(yīng)的網(wǎng)格區(qū)域Lu?L,那么這個估計就變成:
(13)
其中nl為廣告類型u對gl的投放頻率。
本文利用x和y來擴展在矩陣分解中得到的廣告類型隱向量和興趣點隱向量。因此估計偏好矩陣,如下表示:
R=PQT+XYT
(14)
其中,所有廣告類型的分布范圍向量按行堆積得到廣告類型分布范圍矩陣X并且把所有興趣點的影響范圍向量按行堆積得到興趣點影響區(qū)域矩陣Y。進行這種顯式擴展來增加位置和商業(yè)信息的原因在于還沒有證據(jù)說明隱式空間己經(jīng)包含了位置和商業(yè)相關(guān)信息,這里可以看到很容易通過類似的方法添加其他類型的屬性信息,比如興趣點類別等。在這種情況下,廣告類型對興趣點的偏好就建模成擴展空間內(nèi)的點積,因此包含了來自于隱空間的興趣信息也包含了對興趣點的位置偏好。如果廣告類型對興趣點的位置偏好是非零的,那么廣告類型的分布區(qū)域是與興趣點的影響范圍相交的,從而,這些興趣點是可以從廣告類型的分布區(qū)域范圍可達的。
最后需要對廣告可達范圍矩陣和興趣點影響力矩陣進行調(diào)整:
(15)
其中,addsij為調(diào)整后的矩陣元素。k為調(diào)整系數(shù),初始設(shè)為1,即視頻次矩陣和附加信息矩陣對推薦結(jié)果影響作用相同。addij為調(diào)整前的矩陣i行j列元素。H1為頻次矩陣中的最大值,L1為頻次矩陣中的最小值。H2為附加矩陣中的最大值,L2為附加矩陣中的最小值。
2數(shù)據(jù)處理
本文廣告播放數(shù)據(jù)及數(shù)字標牌關(guān)數(shù)據(jù)為合作企業(yè)提供,經(jīng)濟相關(guān)數(shù)據(jù)來源為第三次經(jīng)濟普查數(shù)據(jù)。其中播放記錄為北京地區(qū)的1311塊數(shù)字標牌在2013年1月至2014年12月間所產(chǎn)生的全部播放記錄,約6GB大小數(shù)據(jù)量。并包括期間全部播放廣告的基礎(chǔ)數(shù)據(jù),和數(shù)字標牌的基礎(chǔ)數(shù)據(jù)。
2.1基礎(chǔ)數(shù)據(jù)處理
2.1.1剔除冗余數(shù)據(jù)
播放記錄中有無效播放記錄或空播放記錄,對之后的數(shù)據(jù)處理屬于冗余信息,需要進行剔除。
2.1.2數(shù)據(jù)存儲
需要將基礎(chǔ)的數(shù)據(jù)存入數(shù)據(jù)庫以備查詢調(diào)用。包括基礎(chǔ)的行業(yè)標簽庫,數(shù)字標牌(興趣點)庫,廣告素材庫,地塊信息庫。本文采用redis內(nèi)存數(shù)據(jù)庫進行存儲。
2.1.3數(shù)據(jù)結(jié)果統(tǒng)計
對播放記錄進行初步的統(tǒng)計并將統(tǒng)計結(jié)果存入對應(yīng)數(shù)據(jù)庫中。對統(tǒng)計數(shù)據(jù)入庫。并形成廣告類型和興趣點的播放頻次矩陣并存儲成文件保存到本地。同時形成興趣點和地塊的影響力矩陣,此矩陣為根據(jù)經(jīng)濟因素調(diào)整后的矩陣,并存儲成文件保存到本地。
2.2經(jīng)濟特征數(shù)據(jù)處理
本文所指的特征數(shù)據(jù)為那些可以反映某一地區(qū)完整經(jīng)濟情況并與地理位置有緊密聯(lián)系的經(jīng)濟類型數(shù)據(jù)。對于這種經(jīng)濟特征數(shù)據(jù)的處理,首先需要去掉或合并關(guān)聯(lián)度過大的經(jīng)濟數(shù)據(jù)。然后通過各地塊的經(jīng)濟數(shù)據(jù)變化與播放時長記錄變化的關(guān)聯(lián)性分析,找出對播放時長影響進行特征提取。本文經(jīng)過分析選取常住人口、商業(yè)從業(yè)人口和平均地價作為后續(xù)推薦結(jié)果的參考依據(jù)。
2.3地塊數(shù)據(jù)處理
2.3.1地理數(shù)據(jù)分塊
為方便統(tǒng)計地理位置上的經(jīng)濟數(shù)據(jù),并與興趣點產(chǎn)生關(guān)聯(lián)。需要對地理位置進行分塊,本文將興趣點分布的范圍分成500米×500米的小地塊。地塊有其中心點經(jīng)緯度坐標。
2.3.2相關(guān)數(shù)據(jù)關(guān)聯(lián)
在將地理數(shù)據(jù)分塊好后,需要將各類經(jīng)濟數(shù)據(jù)關(guān)聯(lián)到地塊上,并根據(jù)地塊坐標及所占范圍將各數(shù)字標牌(興趣點)與地塊進行關(guān)聯(lián)。將各數(shù)字標牌播放廣告的有效時長總和統(tǒng)計結(jié)果關(guān)聯(lián)到地塊上。
3實驗
3.1開發(fā)環(huán)境
本文采用python2.7作為開發(fā)語言。為快速響應(yīng)查詢信息,數(shù)據(jù)庫選為Redis2.6。采用NumPy1.8.1進行數(shù)據(jù)處理。同時調(diào)用用于協(xié)同過濾的矩陣分解基礎(chǔ)推薦算法LIBMF1.2庫[10]進行基本矩陣分解。本文采用Matplotlib1.4.3進行數(shù)據(jù)的統(tǒng)計分析展示,采用ArcMap10.1對推薦結(jié)果關(guān)聯(lián)到地理位置上的分析展示。
3.2推薦結(jié)果分析
最終推薦結(jié)果為廣告播放頻次矩陣分解的結(jié)果與數(shù)字標牌影響力矩陣和廣告播放范圍矩陣合并的結(jié)果。最終會為每個廣告類型生成推薦數(shù)字標牌的列表。根據(jù)列表中值的大小決定為該廣告類型推薦的數(shù)字標牌,也就是選取TopN結(jié)果推薦。
為了測試推薦結(jié)果的準確性,本文選用準確率(Precision)參數(shù)進行評定,其定義為pu=nu/Nu,其中pu為廣告類型u的準確率,Nu為廣告類型u選取N個推薦結(jié)果,nu表示這些推薦結(jié)果中為u實際播放過的個數(shù)。
為每種廣告類型的前10個推薦結(jié)果進行Precision評定。圖3為在廣告類型中隨機抽取的10種廣告類型的Precision結(jié)果。

圖3 隨機抽取推薦結(jié)果Precision值
可以從圖中看出推薦結(jié)果的Precision評定基本在10%左右,初步確定推薦結(jié)果具有一定的可信度。
圖4展示了所有廣告類型在北京范圍內(nèi)產(chǎn)生的前10個推薦結(jié)果中的Precision值的統(tǒng)計結(jié)果。

圖4 廣告類型Precision值統(tǒng)計
圖4中的百分數(shù),如10%~14%表示的是廣告類型的Precision值在10%~14%之間,其所占的餅狀圖面積與整個餅狀圖的比值代表了Precision值在10%~14%之間的所有廣告類型數(shù)占總的廣告類型數(shù)的比值。從圖中可以看出有超過75%的廣告類型的Precision值集中在8%~14%概率上,這表明推薦結(jié)果在整體數(shù)據(jù)的推薦效果上是比較集中的。并且推薦結(jié)果在保持一定的可信度的同時,還擁有著不錯的興趣偏移預測,即因為時間、地點等因素改變所引起的播放興趣轉(zhuǎn)變。
對于某一類廣告投放推薦結(jié)果,我們希望它能根據(jù)相似或相同類型廣告的歷史播放記錄和商業(yè)地理信息數(shù)據(jù),選出那些包含著投放用戶已有投放經(jīng)驗,如在學校附近投放培訓、教育類的廣告,的數(shù)字標牌(推薦結(jié)果)。并且能根據(jù)商業(yè)地理信息數(shù)據(jù)為其篩選排序。以下為某一類廣告推薦結(jié)果的具體分析。
商業(yè)地理信息數(shù)據(jù)就是將商業(yè)特征和現(xiàn)象的數(shù)值表征聯(lián)系到它所在的地理信息上[11]。本文利用商業(yè)地理信息數(shù)據(jù)完成推薦結(jié)果在位置上的展示,展示選取技能培訓、教育輔助及其他教育行業(yè),行業(yè)代碼為P829的廣告的所有推薦結(jié)果展示在北京市范圍內(nèi)的分布情況。如圖5為北京地區(qū)推薦結(jié)果分布。

圖5 P829北京地區(qū)推薦結(jié)果分布
途中顏色越深的點表示此位置的數(shù)字標牌的推薦值越高,顏色越淺的點表示推薦的值越低。可以看出大部分的高推薦度的數(shù)字標牌都集中在三環(huán)內(nèi)。
為了更準確地看出推薦數(shù)字標牌分布的趨勢,本文用相同的數(shù)據(jù)繪制了如圖6北京地區(qū)推薦結(jié)果熱度的推薦值的熱點圖。

圖6 P829北京地區(qū)推薦結(jié)果熱度
圖6中顏色越深的區(qū)域表示推薦的值越高,顏色越淺的區(qū)域表示推薦值越低。由圖6中可以看出,對于技能培訓類的廣告,這里會推薦三環(huán)內(nèi)偏北值的數(shù)字標牌進行投放,這些推薦結(jié)
果里包含著如“在學校附近投放培訓教育類廣告”等的投放經(jīng)驗,同時推薦值的排序也借助了商業(yè)地理信息的指導,那些人流密集,商業(yè)發(fā)達的地區(qū)的推薦值會更高,與推薦決策吻合。
4結(jié)語
本文通過基本的矩陣分解算法,利用它對其他數(shù)據(jù)的很好的擴展性能選取了部分商業(yè)地理信息融合在推薦算法中,從而在解決了數(shù)據(jù)稀疏性問題的同時為推薦結(jié)果提供了更多的推薦依據(jù),提高了推薦結(jié)果的可信度。同時為數(shù)字標牌這種有著明顯地理特征的興趣點提供了一種可能的推薦模型。從推薦結(jié)果上看,本文在保證一定可信度的同時,為可能的興趣偏移提供了一定的預測性能。
參考文獻
[1] 叢秋波.數(shù)字標牌:新媒體,新趨勢,新市場[J].電子設(shè)計技術(shù),2009(6):76.
[2] 王敏,寇亞龍,趙霞.數(shù)字標牌廣告即時排期優(yōu)化算法研究[J].電腦知識與技術(shù),2014(26):210-213.
[3] Ye M,Yin P,Lee W C,et al.Exploiting geographical influence for collaborative point-of-interest recommendation[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval.ACM,2011:325-334.
[4] Cheng C,Yang H,King I,et al.Fused matrix factorization with geographical and social influence in location-based social networks[C]//Twenty-Sixth AAAI Conference on Artificial Intelligence,2012.
[5] Liu B,Fu Y,Yao Z,et al.Learning geographical preferences for point-of-interest recommendation[C]//Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2013:1043-1051.
[6] Zhang J D,Chow C Y.iGSLR:personalized geo-social location recommendation:a kernel density estimation approach[C]//Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems.ACM,2013:334-343.
[7] Lian D,Zhao C,Xie X,et al.GeoMF:joint geographical modeling and matrix factorization for point-of-interest recommendation[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2014:831-840.
[8] Hu Y,Koren Y,Volinsky C.Collaborative filtering for implicit feedback datasets[C]//Data Mining,2008.ICDM’08.Eighth IEEE International Conference on.IEEE,2008:263-272.
[9] Pan R,Zhou Y,Cao B,et al.One-class collaborative filtering[C]//Data Mining,2008.ICDM’08.Eighth IEEE International Conference on.IEEE,2008:502-511.
[10] Zhuang Y,Chin W S,Juan Y C,et al.A fast parallel SGD for matrix factorization in shared memory systems[C]//Proceedings of the 7th ACM conference on Recommender systems.ACM,2013:249-256.
[11] Zhang X,Zhang X,Zhong E,et al.Multi-Scale Centrality Measures of Street Network in Beijing,China[J].Sensor Letters,2014,12(3-5):651-658.
收稿日期:2015-07-02。國家自然科學青年基金項目(612020 60);教育部人文社會科學研究青年基金項目(15YJCZp24);北京市自然科學基金重點項目B類(KZ201410011014);北京市教育委員會2015年度科技計劃面上項目(KM201510011009);北京市自然科學基金青年項目(9164025)。解貴龍,碩士生,主研領(lǐng)域:機器學習,數(shù)據(jù)挖掘。張珣,講師。于重重,教授。趙霞,副教授。
中圖分類號TP301.6
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.07.056
RESEARCH ON POI RECOMMENDATION ALGORITHM BASED ON DIGITAL SIGNAGE ADVERTISEMENT DATA
Xie GuilongZhang Xun*Yu ChongchongZhao Xia
(CollegeofComputerandInformationEngineering,BeijingTechnologyandBusinessUniversity,Beijing100048,China)
AbstractTo solve the problem of digital signage advertising recommendation, we studied the location data-based recommendation algorithm. On the basis of existing point of interest (POI) recommendation algorithm, which is based on matrix factorisation idea, we proposed a POI recommendation model which combines the matrix factorisation idea and commercial GIS data, and conducted experiments on location-based digital signage advertising data. Experimental results showed that, by the method appending commercial GIS data to matrix factorisation, the problem of location access data sparseness has been solved, and this provides an effective reference and implementation approach for the problems of single data type and insufficient recommendation basis. Our study provides an important reference basis for the digital signage advertising.
KeywordsPoints of interest recommendationDigital signageLocation recommendationMatrix factorisation
猜你喜歡
發(fā)明與創(chuàng)新·小學生(2021年3期)2021-03-25 11:48:49
科學(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農(nóng)墾科技(2016年2期)2016-08-21 13:50:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
新疆財經(jīng)大學學報(2015年3期)2015-12-10 03:49:15
