基于改進K均值的Context量化模型
2016-05-06 03:17:42彭淑燕劉思聰
中國新通信 2016年6期
彭淑燕 劉思聰
摘要:為了提高圖形編碼系統壓縮性能,可以通過使用Context模型來得到當前所要編碼符號的概率。但是事實證明由于高階Context模型很難在統計中有效收斂于信號的真實分布,結果使得編碼效果降低,這就是所謂的“模型代價”問題。為了解決這一問題,一種有效的方法就是對高階Context模型進行量化。由于Context量化問題與一般矢量量化問題相似,可以在設定合適的失真度量準則的條件下,使用聚類算法來實現Context量化。目前,K均值是使用比較廣泛的一種聚類算法,但K均值算法必須具有確定的類數和選定的初始聚類中心。但在實際中,K均值往往難以準確界定,從而導致了聚類效果不佳。基于此,為了找到最佳的聚類數,本文提出采用聚類有效性函數來改進K均值聚類算法。
【關鍵詞】 Context模型 Context量化 聚類有效性 最佳聚類數目Kopt K均值
Context quantization model based on improved K mean
Abstract: In order to improve the compression performance of the image coding system,the context model can be used to get the probability of the current coded symbol. However, it is proved that high-level context model is difficult to achieve the true distribution of the signal, as a result the effect of coding is reduced, which is the so-called “model cost” problem. Context quantization is an efficient method to deal with this problem. As the context quantification is similar to the general vector quantization problem, context quantization can be achieved by the clustering algorithm under the condition that a suitable distortion measure is defined. Currently, K-means is widely used as a clustering algorithm, but K-means algorithm is determined by the premise that the number of classes and the initial cluster centers are given. However, in fact, K-means is often difficult to be defined precisely, resulting in poor clustering effects. To obtain the best number of clustersin this paper, using cluster validity to improve K-means clustering.
一、引言
熵編碼在圖形編碼中占有非常重要的地位,它通過利用信源符號的統計特性[2,4,5]來獲得圖像的壓縮編碼。近十幾年來隨著算術編碼技術以及高速計算機的廣泛運用,使得復雜的高階熵編碼實現成為可能。近幾年來,圖像編碼研究者的注意力逐漸集中在了高階熵編碼上。但是高階熵編碼的實現卻面臨著一個很嚴重的問題—模型代價問題。
為了解決模型代價[1]問題,一種有效的方法是對Context模型進行量化。通過Context量化可以使經過訓練后得到的Context模型的條件分布經過聚類后更易于統計、更好的收斂于信源的真實概率分布,而且在最小相對熵的準則下,使得量化后增加的熵在最優情況下最小并且可得到最小碼長。
本文采用改進K均值的Context量化方法。其中選擇K均值算法作為Context量化的聚類算法。K均值聚類算法是目前最常使用的聚類算法之一。該算法對大型數據集的處理效率較高,可以達到較好的聚類效果。但K均值的聚類數目開始是確定的,而在實際處理中最佳聚類數目往往很難確定,而這導致了K均值的聚類效果不佳。
本文提出了一些檢驗聚類有效性的函數指標,主要有Davies-Bouldin(DB)指標、Dunn指標、Between-WithinProportion(BWP)指標[6]等。使用這些有效性指標可以得到最佳的聚類數目Kopt 。這使得Context量化能夠得到更短的熵編碼碼長。
二、基于聚類有效性函數的K均值Context量化器設計
2.1 Context模型量化原理
設有一隨機變量C,在給定條件變量E的前提下對C編碼所需的最小比特率為條件熵H(C|E)。其中當E被量化為M=Q(E),條件熵H(C|E)變為H(C|M),
則可得到:
由上式可知Context量化在增加熵的同時也減低了模型代價。
Context量化器的設計就是要找到一種最小的I(C;E|M)。為此可以定義相對熵公式如下: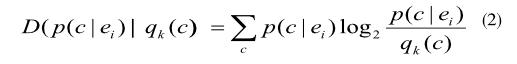
而qk(c)=p(c|mk)可視作相應的p(c|ei)的量化值,其中ei∈mk。這里選擇p(ei)D(p(c|ei)‖qk(c))作為量化的失真度標準。這里的相對熵是非對稱的,它并不是兩個失真度標準概率之間的真實距離。
定義Context量化的量化失真如下:
此時Context量化的最優目標就變為:找到最佳的量化級數K,使對所有的ei∈E都找到一個最優的劃分,然后為所有的K個劃分分別計算最優量化值p(ei)D(p(c|ei)‖qk(c)),
在給定的量化級數K的條件,并且使量化失真最小。只有使量化值對于每一個劃分都有以下形式: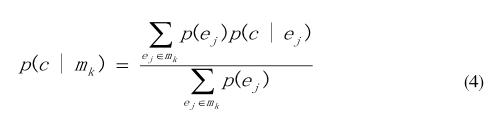
2.2聚類有效性指標函數
2.2.1聚類算法的指標
由上文可以,盡管K均值聚類是一種常用的聚類方法,但是卻有諸多條件的限制,為了突破這些條件的限制,學界提出了多種聚類有效性函數[3]。常見的聚類有效性函數有以下幾種:
(1)Dunn指標
該指標定義如下:
d(ci,cj)表示類ci和類cj樣本之間的相異性, diam(ck)表示同類中樣本的相似性。
當該指標越大時表示聚類效果越好,但聚類數對指標并沒有明顯的指示性。
(2) Daivies-Bouldin(DB)指標
該指標定義如下:
k 和j表示類標,xi(j)表示第j類的第i個樣本,xp(k)表示第k類的第p個樣本,nk表示第k類中的樣本數目。
其中:xq(j)表示第j類中的第q個樣本,nj表示第j類樣本數。
2.3基于聚類有效性函數的K均值Context量化器算法
算法步驟如下:
步驟1:用圖像來訓練條件概率分布p=(c|ej),i=1…N。由此得到對p=(c|ej)和p=(ej)的準確估計;
步驟2:從kmin循環至kmax;
(1)構造一個初始化的Context模型量化器,Qcn=Qc1=p(c|mk),k=1…K這里K是量化劃分的數量。設n=1;
(2)為每一個集合中的p(c|ej)設定Context模型量化器Qcn=p(c|mk),k=1…K,對所有的集合mk,k=1…K,計算p(ej)D(p(c|ej)‖p(c|mk)),并找到其最小值。當l≠c,將je從所屬集合ml移到另一集合mc,直到所有ml,l=1…K均被處理;
(3)對所有的集合[1,2]mk,用公式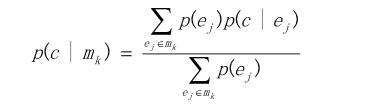
計算量化值p(c|mk)從而獲得新的Context量化器Qcn+1;
(4)計算失真度D。如果它與上一步的迭代相比只是改變很小的數值,就停止,否則就將n+1賦值給n,然后轉至(2);
(5)利用公式(1)、(2)、(3)分別計算Dunn、DB、BWP的指標值。在這里將公式中的歐式距離全部改為散度值;
步驟3:輸出最佳聚類數、有效性指標值和聚類結果。
步驟4:從kmin循環至kmax計算基于K均值聚類的Context量化的算術編碼長度,找到最小碼長的聚類數;
步驟5:比較上述幾種聚類有效性得到的最佳聚類數計算出的算術碼長與步驟4的到的最小碼長和聚類數進行比較;
三、實驗結果與分析
本文選擇了3幅512階灰度的圖形,將其均勻量化為8階灰度圖形來作為測試的信源數據。選擇以下的Context模型: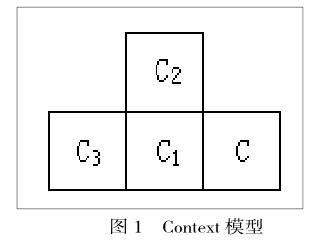
該模型共有83=512個條件分布,實驗中聚類數K搜索范圍為[2,25]。得到了基于K均值算法的DB、Dunn、BWP有效性指標值,結果如下表1。
由DB、Dunn、BWP指標確定的最佳聚類數目曲線其中由DB指標確定的最佳聚類數為9,由Dunn指標確定的最佳聚類數為16,由BWP指標確定的最佳聚類數為10。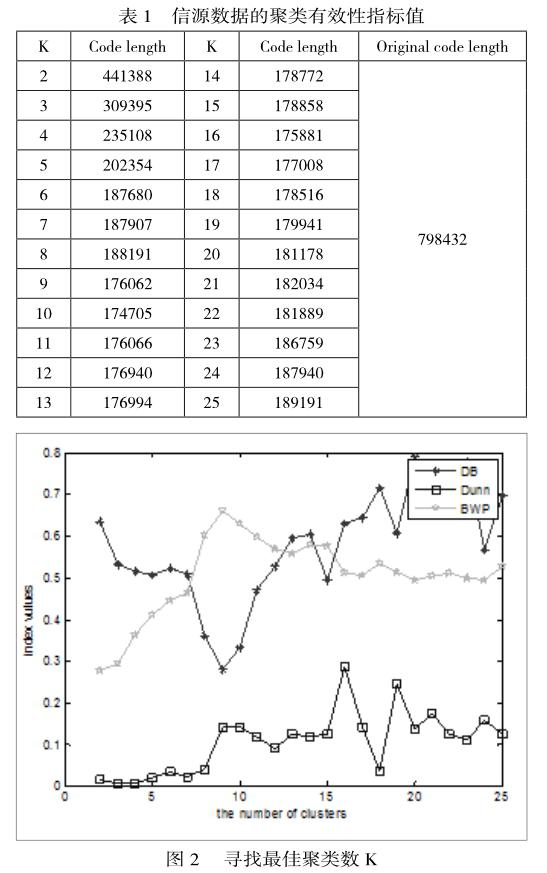
在聚類數目為2~25的條件下,由K均值算法計算得到的Context模型的算術編碼長度,如表2所示。
由表2可知,在聚類數目為10時,得到了最小的算術編碼,其長度為174705。
通過對由幾種有效性評價指標計算出的信源數據的最佳聚類數目與遍歷K均值找到的最佳聚類數目比較,從表3中可以看出,BWP指標找到最佳聚類數為10,與遍歷K均值找到的最小碼長所對應的聚類數相一致。即基于K均值的BWP聚類指標評價能夠設計最優的Context量化器。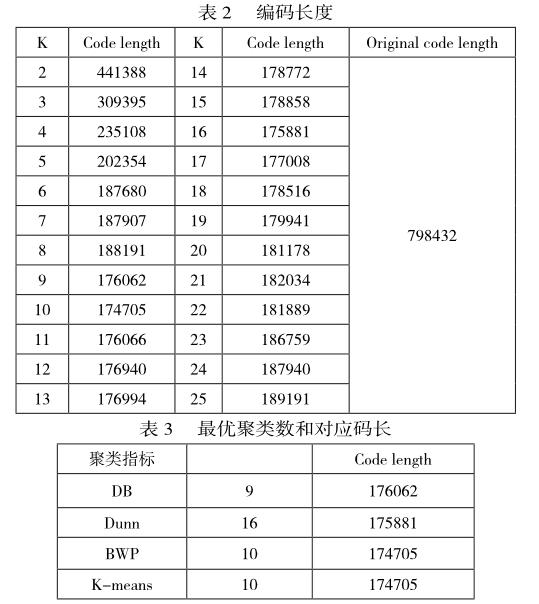
四、結論
熵編碼是利用信源符號之間的相關性來進行圖像的,但是由于高階熵編碼的復雜計算,因而Context模型被廣泛應用熵編碼中,存在一個嚴重的問題就是模型代價問題。解決模型代價的最好方法就是利用模型量化,許多實驗已經證明Context模型量化的類似一般的矢量量化。目前最常用的矢量量化方法就K均值聚類算法,但是K均值聚類算法存在聚類數需先確定的缺點。這樣得到的聚類效果不是最佳,就量化器的設計不是最優。為了得到最佳聚類數,本文提出了一種基于聚類有效性指標的K均值聚類算法。通過比較上述幾種聚類指標找到最佳的聚類數,設計了
一種最優的Context量化器。
參 考 文 獻
[1] 陳建華.于Context量化的Context模型[J].云南大學學報,2002,24(5):345-349.
[2] 楊亞彪.基于貝葉斯估計的Context量化器設計方法[J].昆明學報,2013,35(2):79-82.
[3] 孫秀娟.基于新聚類有效性函數的改進K-mean算法[J]計算機應用,2008,28(12):3244-3247.
[4] M. J. Weinberger, J.J. Rissanen, R. B. Arps.Applications of universal context modeling to lossless compression of gray-scale images[J]. IEEE Transactions on Image Processing,1996,5(4) :575-586.
[5] D.Marpe, H. Schwarz, T. Wiegand,.Context-base dadaptive binary arithmetic coding in the H.264/AVC video compression standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2003,13(7) 620-636.
[6] LF Lago-Fernández,F Corbacho. Normality-based validation for crisp clustering[J]. Pattern Recognition 2010, 43(3):782-795.
[7] S. Forchhammer, X. Wu, Context quantization by minimum adaptive code length, in: Proceedings of IEEE International Symposium on Information Theory,Nice, France, June2007,246-250.
