銅綠假單胞菌SU8發(fā)酵液與乙蒜素混配對草莓灰霉病的防效
2017-05-11 17:46:27楚文琢彭雙強(qiáng)廖曉蘭馬文月
江蘇農(nóng)業(yè)科學(xué) 2017年6期
關(guān)鍵詞:防治
楚文琢+彭雙強(qiáng)++廖曉蘭+馬文月


摘要:用拮抗細(xì)菌銅綠假單胞菌SU8的發(fā)酵液和乙蒜素乳油進(jìn)行混配以期達(dá)到有效防治草莓灰霉病的目的,分別從SU8發(fā)酵液與乙蒜素乳油混配的室內(nèi)毒力、孢子萌發(fā)抑制率和盆栽防效試驗等3個方面進(jìn)行研究。結(jié)果表明,SU8發(fā)酵液對草莓灰霉病菌的最小抑菌濃度(MIC)為12.50 mg/L,EC50為1 696.4 mg/L,乙蒜素乳油對草霉灰霉病菌的MIC為6.25 mg/L,EC50為143.4 mg/L;當(dāng)兩者以質(zhì)量比1 ∶9混配時,增效系數(shù)為1.04,表現(xiàn)為協(xié)同作用,當(dāng)兩者分別以質(zhì)量比1 ∶4、1 ∶1、4:1、9 ∶1混配時,增效系數(shù)分別達(dá)到了1.53、2.33、5.41、8.41,均表現(xiàn)出明顯的增效作用;在對病菌孢子萌發(fā)抑制方面,在12、24、36 h內(nèi),乙蒜素乳油的抑制率分別為60.9%、58.4%、47.0%,低于兩者質(zhì)量比 4 ∶1 、 9 ∶1 混合組配;在盆載試驗中,乙蒜素乳油的防病效果也比兩者質(zhì)量比4 ∶1、9 ∶1混合組配低。由結(jié)果可知,與SU8發(fā)酵液混配,能極顯著增強(qiáng)乙蒜素對草莓灰霉病的防治效果。
關(guān)鍵詞:SU8發(fā)酵液;乙蒜素乳油;混配;增效作用;草霉灰霉病菌;防治
中圖分類號: S436.68+4文獻(xiàn)標(biāo)志碼: A文章編號:1002-1302(2017)06-0079-04
草莓灰霉病(Botrytis cinerea)是影響我國草莓生產(chǎn)的一種常見病害,其病原菌屬灰葡萄孢菌,為腐生致病菌,可以侵染番茄、茄子、黃瓜、西葫蘆、草莓、葡萄、蘋果、菜豆等多種作物[1-3]。該病菌感染植株后,若不能得到有效控制,一般情況下會致使草莓減產(chǎn)10%~20%,嚴(yán)重時往往導(dǎo)致草莓植株葉片干枯、果實出現(xiàn)斑點或腐爛,甚至整株死亡,減產(chǎn)率高達(dá)70%~80%[4-5],嚴(yán)重影響草莓的產(chǎn)量與質(zhì)量,造成重大經(jīng)濟(jì)損失。目前,農(nóng)業(yè)生產(chǎn)上對灰霉病的防治主要依賴多菌靈、腐霉利等化學(xué)藥劑[6-9]。然而,這些化學(xué)藥劑在取得較好防治效果的同時,由于灰霉病菌具有寄主范圍廣、繁殖速度快、遺傳變異性大和適應(yīng)性強(qiáng)的特點,極易產(chǎn)生抗藥性,并且在化學(xué)藥劑的長期使用過程中,其抗藥性也不斷增強(qiáng)[10-18],這些特性使得化學(xué)藥劑對草莓灰霉病的防治效果下降很快[19-22]。因此,在生產(chǎn)過程中,為了增強(qiáng)對灰霉病的防治效果,往往采用增大劑量或者增加施藥次數(shù)的措施,這種措施可能會導(dǎo)致草莓本身藥劑殘留量超標(biāo),最終危及人畜健康,影響我國草莓生產(chǎn)與出口,非常不利于我國當(dāng)前綠色農(nóng)業(yè)和生態(tài)農(nóng)業(yè)的發(fā)展要求[23]。尤其是我國加入世界貿(mào)易組織(WTO)后,世界對我國農(nóng)副產(chǎn)品出口提出了更高的要求。因此,我國的草莓種植業(yè)迫切需要一些符合我國農(nóng)業(yè)發(fā)展的新型途徑來有效控制灰霉病的發(fā)生與蔓延。
生物防治具有低污染、低殘留、低成本的特點,正逐漸成為灰霉病控制中一條重要有效的途徑[24-25]。近幾十年來,國內(nèi)外專家進(jìn)行了大量研究,篩選出具有抑制灰霉病菌的拮抗細(xì)菌,發(fā)現(xiàn)當(dāng)前常見的灰霉病拮抗菌株主要為木霉、酵母菌、芽孢桿菌、銅綠假單胞菌和放線菌等[26-29]。然而,大量報道也表明,單一的生物防治因菌株具有極大的變異性而導(dǎo)致防治效果不穩(wěn)定。研究也發(fā)現(xiàn),將拮抗細(xì)菌與化學(xué)藥劑混配對延緩病原菌的抗藥性、提高藥劑對病原菌的防治效果有一定的作用。例如,周榮金等將不同的拮抗細(xì)菌混配能有效提高對灰霉病的防效,對灰霉病的防治具有顯著增效作用[30];張紅娟等從核桃上分離得到的2株內(nèi)生菌HT3與HT5分別與速克靈藥劑混配能有效增強(qiáng)對灰霉病菌的抑制作用[31]。但目前利用拮抗細(xì)菌發(fā)酵液和植物源殺菌劑混配來防治草莓灰霉病的報道罕見。筆者所在實驗室從稻鴨共養(yǎng)田中分離出1株對水稻紋枯病菌(Rhizoctoria solani)、稻瘟病菌(Pyricularia oryzae)、煙草赤星病菌(Alternaria alternata)等多種真菌具有較強(qiáng)拮抗效果的銅綠假單胞菌SU8,研究發(fā)現(xiàn)其發(fā)酵液乙酸乙酯提取物也有同樣的抑菌效果[32]。此外,有研究表明,大蒜提取物對草莓灰霉病菌有較好的抑制效果,并且農(nóng)業(yè)生產(chǎn)中以大蒜提取物為原料合成的仿生農(nóng)藥——乙蒜素乳油對包括草莓灰霉病在內(nèi)的多種病害均具有顯著防治效果[33-34]。基于此,本研究擬用乙蒜素乳油和SU8發(fā)酵液混配來開展試驗,以期拓寬對該病的防治途徑,為防治草莓灰霉病提供新思路。
1材料與方法
1.1試驗材料
供試菌株為由湖南農(nóng)業(yè)大學(xué)植物保護(hù)學(xué)院植物病理學(xué)實驗室篩選分離的SU8拮抗細(xì)菌和草莓灰霉病菌。供試藥劑為80%乙蒜素乳油(北京中農(nóng)佳瑞有限公司)。試驗植株為易感灰霉病品種豐香。
供試培養(yǎng)基:(1)PDA培養(yǎng)基,200 g馬鈴薯、15 g葡萄糖、17 g瓊脂,pH值自然 ;(2)馬鈴薯葡萄糖培養(yǎng)液:除不加瓊脂外,其余同PDA培養(yǎng)基;(3)NA培養(yǎng)基:10 g牛肉浸膏、10 g蛋白胨、5 g氯化鈉、17 g瓊脂,pH值為7.0~7.2;(4)NB培養(yǎng)液:除不加瓊脂外,其余同NA培養(yǎng)基。上述培養(yǎng)基均加水定容至1 L,于1.01×106 Pa、121 ℃滅菌20 min,備用。
1.2試驗方法
1.2.1拮抗菌SU8發(fā)酵液的制備將拮抗菌SU8在NA培養(yǎng)基上活化后,用接種環(huán)取1環(huán)于10 mL無菌水中攪拌均勻,做成菌體懸浮液。取NB培養(yǎng)液與10% 上述SU8菌體懸浮液于搖瓶中,在磁力攪拌機(jī)上,28 ℃、220 r/min振蕩連續(xù)培養(yǎng)120 h,得到SU8發(fā)酵液。
取適量發(fā)酵液,用旋轉(zhuǎn)蒸發(fā)儀于100 r/min、60 ℃恒溫條件下濃縮至原來體積的1/10。再將10倍濃縮液在4 ℃、10 000 r/min 條件下離心20 min,取上層液體,得到SU8發(fā)酵液粗濾液。用細(xì)菌過濾器(0.22 μm)逐步過濾除菌后的無菌發(fā)酵液,即為SU8發(fā)酵液(濃度視為 1 g/mL,以下簡稱SU8發(fā)酵液),置于4 ℃,保存?zhèn)溆谩?
1.2.2拮抗效果與拮抗活性的測定(1)SU8菌對草莓灰霉病菌的拮抗效果。試驗采用對峙培養(yǎng)法:在無菌工作臺上,用融化的PDA培養(yǎng)基制作成直徑為7 cm的PDA平板。用SU8菌體懸浮液將滅過菌的濾紙片(直徑為0.5 cm)潤濕,置于PDA平板的一側(cè)。同時,在PDA平板的另一側(cè)對稱性地放置1個直徑為0.5 cm的草莓灰霉病菌菌餅,25 ℃培養(yǎng)箱中連續(xù)培養(yǎng)72 h。觀察草莓灰霉病菌菌落生長情況并測定抑菌帶寬度,每個處理3次重復(fù)。
(2)SU8發(fā)酵液和乙蒜素乳油對草莓灰霉病菌的拮抗活性測定。取草莓灰霉病菌菌餅(直徑為0.5 cm)接種于PDA平板的中央,25 ℃下培養(yǎng)24 h后在新長出的菌絲兩側(cè)對稱打孔(直徑為0.5 cm)。挑出孔內(nèi)基質(zhì)后,在其中的1個孔內(nèi)加入適量的SU8發(fā)酵液(濃度為1 g/mL),在對稱的另1個孔內(nèi)加入等量的無菌水作對照。乙蒜素乳油(無菌水稀釋100倍,濃度視為1 g/mL,下同)作相同的處理。25 ℃培養(yǎng)72 h后,觀察草莓灰霉病菌菌落生長情況并測定抑菌帶寬度,每個處理3次重復(fù)。
1.2.3室內(nèi)毒力測定(1)最小抑菌濃度(MIC)測定。參照黃彰新菌絲生長速率法[35]進(jìn)行MIC測定并稍作修改。其具體操作如下:在無菌工作臺上,用無菌水分別將SU8發(fā)酵液和乙蒜素乳油配制成1 000.0、750.0、500.0、250.0、125.0、62.5 mg/L的6種不同濃度,4 ℃下保存?zhèn)溆谩T?.0 mL熱培養(yǎng)基中,分別加入1.0 mL不同濃度的2種物質(zhì),以加1 mL水為對照,搖勻制成平板;接種同時活化的灰霉病菌菌餅(直徑0.5 cm),使帶菌絲的一面貼在培養(yǎng)基表面,置于25 ℃的培養(yǎng)箱中恒溫培養(yǎng)。待對照菌絲長至培養(yǎng)皿的2/3面積時,用十字相乘法測定菌落直徑,每個處理3次重復(fù)。以不長菌處理藥劑的最低濃度為最小抑菌濃度。
(2)菌絲生長抑制率的測定。在最小抑菌濃度的基礎(chǔ)上,分別取相應(yīng)濃度的SU8發(fā)酵液與乙蒜素乳油以質(zhì)量比 1 ∶9、1 ∶4、1 ∶1、4 ∶1、9 ∶1進(jìn)行混配,每個混合組配配制5種不同的梯度濃度,置于4 ℃保存?zhèn)溆谩⒄站z生長速率法計算藥劑的菌絲生長抑制率,每個處理3次重復(fù)。通過公式計算藥劑對菌絲生長的抑制率,并采用Wadley的增效比率法[36]計算2種物質(zhì)的毒力回歸方程和混合組配的增效系數(shù),相應(yīng)公式:
相對抑制率= 對照菌落直徑-處理菌落直徑1對照菌落直徑-菌餅直徑×100%;
混劑的理論EC(th)50=a+b1(a/A的EC50+b/B的EC50);
增效系數(shù)(SR) = 混劑的EC(th)501混劑的EC50。
式中:菌落生長直徑為測量直徑減去0.5 cm的菌餅直徑,cm;A為SU8發(fā)酵液;B為80%乙蒜素乳油;a、b分別為SU8發(fā)酵液、80%乙蒜素乳油在混合組配物總質(zhì)量中的比例,%。
根據(jù)增效系數(shù)(SR)進(jìn)行聯(lián)合作用綜合評價。當(dāng)0.5 1.2.4孢子萌發(fā)抑制活性的測定采用孢子萌發(fā)法[37]測定孢子萌發(fā)抑制活性。在無菌條件下,分別配制濃度為 500 mg/L 乙蒜素乳油、濃度為2 000 mg/L SU8發(fā)酵液,再取適量SU8發(fā)酵液和乙蒜素乳油按質(zhì)量比4 ∶1、9 ∶1進(jìn)行混配,得到混合組配,置于4 ℃保存?zhèn)溆谩⒉≡囵B(yǎng)8 d,待其產(chǎn)孢后,加無菌水 5 mL,在培養(yǎng)基表面用接種針輕輕摩擦,使病原菌孢子懸浮于水中,將培養(yǎng)基塊和菌絲體用紗布過濾,制成2萬個/mL的孢子懸浮液。分別取各藥劑與孢子懸浮液等體積充分混合,以無菌水作空白對照滴加在潔凈的凹玻片上。在25 ℃恒溫條件下培養(yǎng),分別培養(yǎng)12、24、36 h后,在40倍物鏡下鏡檢孢子萌發(fā)情況(以孢子芽管的長度超過孢子直徑的50%視為已萌發(fā)孢子),檢查各個處理孢子萌發(fā)情況,并計算萌發(fā)率和抑制率,每個處理重復(fù)3次,相應(yīng)公式: 孢子萌發(fā)率=孢子萌發(fā)數(shù)/總孢子數(shù)×100%; 孢子萌發(fā)抑制率=(CK孢子萌發(fā)數(shù)-藥劑處理孢子萌發(fā)數(shù))/對照孢子萌發(fā)數(shù)×100%。 1.2.5盆栽防效試驗試驗于2015年5月中旬—7月上旬草莓育苗期間,從草莓種植區(qū)大棚內(nèi)移取適量的泥土,經(jīng)無菌處理后,盛裝在口徑為40 cm、高為25 cm的花盆中至盆高的2/3。選取生長狀況較一致的1年生豐香草莓3葉期幼苗數(shù)株均勻移植于花盆中,2盆之間的間距為10 cm,其他同常規(guī)管理。待其成活后,將草莓灰霉病菌發(fā)酵液制成2 000萬CFU/mL,每株2 mL均勻噴施于草莓葉面。在人工氣候箱(溫度25 ℃、相應(yīng)濕度90%)中培養(yǎng)3~4 d,待草莓植株完全發(fā)病后調(diào)查病情指數(shù)。分別噴施“1.2.4”節(jié)所配制的各藥劑,以無菌水作空白對照(CK)。每處理20株,連續(xù)施藥2次,第1次施藥與第2次施藥間隔7 d。噴藥后7 d分別觀察記錄草莓植株發(fā)病情況。 參照農(nóng)業(yè)部農(nóng)藥檢定所編寫的《農(nóng)藥田間藥效試驗準(zhǔn)則》對病害進(jìn)行分級,并計算病情指數(shù)和防治效果。病情分級標(biāo)準(zhǔn):0級,無病斑;1級,病斑面積占整個葉面積5%及以下;3級,病斑面積占整個葉面積6%~10%;5級,病斑面積占整個葉面積11%~20%;7級,病斑面積占整個葉面積21%~50%;9級,病斑面積占整個葉面積50%以上。相應(yīng)公式: 病葉率=調(diào)查病葉數(shù)/調(diào)查總?cè)~數(shù)×100%; 病情指數(shù)=[∑(各級病葉數(shù)×相對級數(shù)值)/(調(diào)查病葉數(shù)×最高級數(shù)值)]×100; 防治效果=(對照區(qū)病情指數(shù)-處理區(qū)病情指數(shù))/對照區(qū)病情指數(shù)×100%。 1.2.6數(shù)據(jù)處理 采用Excel、DPS軟件進(jìn)行數(shù)據(jù)處理,用新復(fù)極差法進(jìn)行差異顯著性分析(α=0.05,α=0.01)。
2結(jié)果與分析
2.1拮抗活性的測定
2.1.1SU8菌對草莓灰霉病菌的拮抗效果對峙培養(yǎng)法測得SU8菌對草莓灰霉病菌的抑菌帶寬為3.26 cm。該結(jié)果表明SU8菌對草莓灰霉病菌具有較強(qiáng)的拮抗效果,與張亞等的研究結(jié)果[32]一致。
2.1.2SU8發(fā)酵液和乙蒜素乳油對草莓灰霉病菌的拮抗效果由表1可知,SU8發(fā)酵液和乙蒜素乳油對草莓灰霉病菌均具有抑制作用。
2.2室內(nèi)毒力測定
利用菌絲生長速率法進(jìn)行SU8發(fā)酵液與乙蒜素乳油混配的室內(nèi)毒力測定。結(jié)果表明,SU8發(fā)酵液與乙蒜素乳油對草莓灰霉病菌的最小抑菌濃度分別為12.50、6.25 mg/L。由表2可知,SU8發(fā)酵液對草莓灰霉病病菌的EC50為1 696.4 mg/L,乙蒜素乳油對草莓灰霉病病菌的EC50為1434 mg/L,2種物質(zhì)以質(zhì)量比為1 ∶9、1 ∶4、1 ∶1、4 ∶1、9 ∶1混合組配的EC50分別為151.4、114.2、113.6、98.9、96.6 mg/L,其增效系數(shù)分別為1.04、1.53、2.33、5.41、8.41。
根據(jù)增效系數(shù)的聯(lián)合評價標(biāo)準(zhǔn)可知,2種物質(zhì)以質(zhì)量比 9 ∶1 混合組配為協(xié)同作用;2種物質(zhì)以質(zhì)量比1 ∶4、1 ∶1、4 ∶1、9 ∶1混合組配為增效作用,且以質(zhì)量比為 9 ∶1、4 ∶1的混合組配增效作用較為明顯。
2.3孢子萌發(fā)活性抑制測定
表3結(jié)果表明,隨著時間的增加,病菌孢子萌發(fā)率逐漸提高,但不同藥劑對病菌孢子萌發(fā)的影響不同。在12、24、36 h內(nèi),病菌孢子在單一的SU8發(fā)酵液中萌發(fā)率最高,分別為605%、82.1%、88.5%,均高于其他藥劑處理,而以SU8發(fā)酵液與乙蒜素乳油按質(zhì)量比9 ∶1混合組配最低,其萌發(fā)率分別為8.5%、13.6%、21.8%。比較它們的孢子萌發(fā)抑制率可知,在不同的時間段內(nèi)以單一的SU8發(fā)酵液處理對孢子萌發(fā)的抑制率最低,但當(dāng)SU8發(fā)酵液與乙蒜素乳油以質(zhì)量比 4 ∶1、9 ∶1混配后,2種混合組配對孢子萌發(fā)的抑制率均明顯高于前2者,其中又以質(zhì)量比9 ∶1的混合組配最高(表3)。
2.4盆栽防效試驗
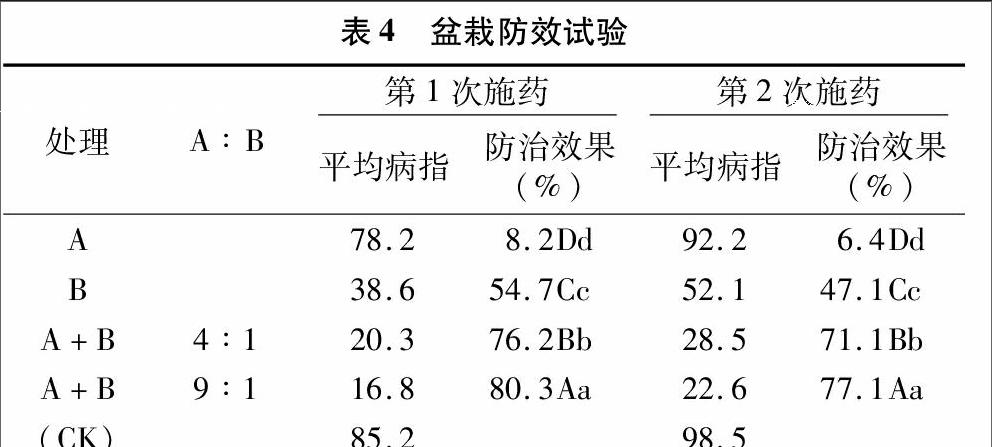
由表4可知,2次施藥,單一乙蒜素乳油防病效果分別為54.7%、47.1%,單一SU8發(fā)酵液防病效果分別為8.2%、64%,但均低于同濃度乙蒜素乳油和SU8發(fā)酵液2者質(zhì)量比4 ∶1、9 ∶1混合組配的防病效果,且差異極顯著。
3結(jié)論與討論
3.1結(jié)論
本研究再一次明確了拮抗細(xì)菌SU8的發(fā)酵液對草莓灰霉病菌具有較強(qiáng)的抑制效果,且混配的各項試驗結(jié)果均表明,乙蒜素乳油與SU8發(fā)酵液以質(zhì)量比4 ∶1、9 ∶1混配對草莓灰霉病的防治效果比其單一藥劑要好,且以2者質(zhì)量比9 ∶1混配效果最好。這一結(jié)果明確了與SU8發(fā)酵液混配,能顯著增強(qiáng)乙蒜素乳油對草莓灰霉病的防治效果,并有力論證了銅綠假單胞菌株SU8成為生物農(nóng)藥的可能性,明確了拮抗菌在農(nóng)業(yè)生產(chǎn)病害防治中的重要地位,也表明混配是防治草莓灰霉病的有效途徑,為今后防治草莓灰霉病提供了新思路,值得更廣范圍地研究與推廣。尤其是本研究利用2種對環(huán)境無污染的生防物質(zhì)混配,在取得較好防治效果的同時,又明確了2種物質(zhì)的具體混配比例,為今后劑型的研發(fā)與推廣提供了試驗數(shù)據(jù)。
3.2討論
生物防治具有低毒、低殘留、易降解的特點,并且與環(huán)境相容,正逐漸成為生產(chǎn)無公害農(nóng)產(chǎn)品時防治病害的首選[38]。因此,生物農(nóng)藥的研發(fā)倍受關(guān)注,開發(fā)新型生物農(nóng)藥防治草莓灰霉病已成為當(dāng)前農(nóng)藥研究與開發(fā)領(lǐng)域的熱點之一。拮抗細(xì)菌銅綠假單胞菌SU8發(fā)酵液和乙蒜素乳油混配防治草莓灰霉病屬于生物防治的范疇,原材料既安全且易得,符合現(xiàn)代農(nóng)業(yè)環(huán)保、健康、持續(xù)發(fā)展的時代要求,值得研究和開發(fā)。
大量研究表明,多種植物的活性提取物或微生物菌株的代謝產(chǎn)物可以達(dá)到抗灰霉病菌的目的,但大多著重于活性物對灰霉病菌的毒力測定,而對這些活性物質(zhì)的具體成分確定研究較少。今后應(yīng)加強(qiáng)活性成分的分離鑒定,探討活性成分的分子結(jié)構(gòu)與構(gòu)效關(guān)系的研究,以期探索出能合成植物源殺菌劑的先導(dǎo)化合物,并研發(fā)科學(xué)合理的生物劑型,最終應(yīng)用于農(nóng)業(yè)生產(chǎn)中。本研究明確了SU8發(fā)酵液對草莓灰霉病菌的生長有較強(qiáng)的抑制效果,尤其與乙蒜素乳油混配更能提高其抑菌效果。彭雙強(qiáng)等也先后報道了SU8菌株對水稻紋枯病菌、草莓灰霉病菌等多種菌株具有較強(qiáng)的拮抗效果,并且分別采用乙酸乙酯、二氯甲烷和石油醚等溶劑提取SU8的抑菌活性物質(zhì),經(jīng)檢測確定了SU8抑菌類物質(zhì)為吩嗪類物質(zhì)[39-41]。吩嗪類物質(zhì)是一種廣泛存在于假單胞菌代謝產(chǎn)物中的抑制真菌的抗生素,與眾多報道的假單胞生防菌的抑菌活性物質(zhì)基本相同,故菌株SU8具有作為生防菌的潛力。
在微生物環(huán)境中,菌株的拮抗現(xiàn)象屢見不鮮。然而拮抗菌的代謝產(chǎn)物未必對同種微生物有抑制效果。研究發(fā)現(xiàn)銅綠假單胞菌SU8發(fā)酵液濾液對草莓灰霉病菌具有較強(qiáng)的拮抗效果。本研究利用乙蒜素乳油、SU8發(fā)酵液及兩者不同質(zhì)量比的混合組配防治草莓灰霉病。室內(nèi)毒力試驗結(jié)果表明,混合組配中以質(zhì)量比為4 ∶1、9 ∶1的增效效果最為明顯,選取2種混合組配開展孢子萌發(fā)抑制試驗,并進(jìn)行盆栽防治試驗。試驗結(jié)果均表明,乙蒜素乳油與SU8發(fā)酵液混配對草莓灰霉病的防治效果比單一藥劑好。這一結(jié)果表明,混配是一條有效防治草莓灰霉病的途徑,也明確了乙蒜素乳油與SU8發(fā)酵液2種生防物質(zhì)的混配比例,但其增效機(jī)制、作用方式與劑型開發(fā)還有待進(jìn)一步研究。
參考文獻(xiàn):
[1]李科孝,謝宏偉. 大棚韭菜灰霉病的發(fā)生規(guī)律與防治[J]. 植物保護(hù),2001,27(2):46.
[2]張建人,陸宏. 南方草莓灰霉病的發(fā)生與綜合防治[J]. 植物保護(hù),1991,17(4):6-7.
[3]Sadfi-zouaoui N,Hannachi L,Andurand D,et al. Biological control of Botrytis cinerea on stem wounds with moderately haophilic bacteria[J]. World J of Microbiol Biotechnol,2008,24(12):2871-2877.
[4]王春艷. 草莓灰霉病發(fā)生危害及防治研究初報[J]. 植物保護(hù),1997,23(3):32-33.
[5]陳治芳,王文橋,韓秀英,等. 灰霉病化學(xué)防治及抗藥性研究進(jìn)展[J]. 河北農(nóng)業(yè)科學(xué),2010,14(8):19-23.
[6]童蘊(yùn)慧,紀(jì)兆林,徐敬友,等. 灰霉病生物防治研究進(jìn)展[J]. 中國生物防治學(xué)報,2003,19(3):131-135.
[7]劉波,葉鐘音. 速克靈抗性灰霉病菌菌株性質(zhì)的研究[J]. 植物保護(hù)學(xué)報,1992,19(4):297-302.
[8]周明國,葉鐘音,杭建勝,等. 對多菌靈具有抗性的草莓灰霉病菌菌株形成與分布研究[J]. 南京農(nóng)業(yè)大學(xué)學(xué)報,1990,13(3):57-60.
[9]韓巨才,閆秀琴,劉慧平,等. 灰霉病原菌對速克靈的抗性監(jiān)測[J]. 山西農(nóng)業(yè)大學(xué)學(xué)報(自然科學(xué)版),2003,23(4):299-302.
[10]李寶聚,朱國仁,關(guān)天舒,等. 節(jié)能日光溫室中番茄灰霉病發(fā)生規(guī)律的研究[J]. 植物保護(hù),2003,29(2):26-29.
[11]Hou J,Gao Y N,F(xiàn)eng J,et al. Sensitivity of Botrytis cinerea to propamidine:in vitro determination of baseline sensitivity and the risk of resistance[J]. European Journal of Plant Pathology,2010,128(2):261-267.
[12]Elad Y. Reduced sensitivity of Botrytis cinerea to two sterol biosynthesis-inhibiting fungicides:fenetrazole and fenethanil[J]. Plant Pathology,1992,41(1):47-54.
[13]Albert M R,Ostheimer K G,Liewehr D J,et al. History of medicine[J]. Annals of Internal Medicine,2003,137(12):993-1000.
[14]Garrison F H,Blocker T M. An introduction to the history of medicine[J]. Plastic & Reconstructive Surgery,1976,57(4):20-21.
[15]Bollen G J,Scholten G. Acquired resistance to benomyl and some other systemic fungicides in a strain of Botrytis cinerea in cyclamen[J]. Netherlands Journal of Plant Pathology,1971,77(3):83-90.
[16]周明國,葉鐘音. 植物病原菌對苯并咪唑類及相關(guān)殺菌劑的抗藥性[J]. 植物保護(hù),1987,13(2):21-33.
[17]紀(jì)明山,祁之秋,王英姿,等. 番茄灰霉病菌對嘧霉胺的抗藥性[J]. 植物保護(hù)學(xué)報,2003,30(4):396-400.
[18]George A,Tomas V,Olga K,et al.Multiple resistance of Botrytis cinerea from kiwifruit to SDHIS,QoIs and fungicides of other chemical groups[J]. Pest Management Science,2010,66(9):967-973.
[19]劉波,葉鐘音. 速克靈抗性灰霉病菌菌株性質(zhì)的研究[J]. 植物保護(hù)學(xué)報,1992,19(4):297-302.
[20]賈曉華. 番茄灰霉病菌和油菜菌核病菌對嘧霉胺的敏感性基線及番茄灰霉病菌抗藥性研究[D]. 南京:南京農(nóng)業(yè)大學(xué),2004.
[21]張紅印,馬龍傳,姜松,等. 臭氧結(jié)合拮抗酵母對草莓采后灰霉病的控制[J]. 農(nóng)業(yè)工程學(xué)報,2009,25(5):258-263.
[22]江琴琴,周俞超,陳小龍,等. 產(chǎn)抗灰霉病菌物質(zhì)的微生物篩選和鑒定[J]. 農(nóng)藥,2010,49(4):257-259.
[23]張志恒,李紅葉,吳珉,等. 百菌清、腈菌唑和吡唑醚菌酯在草莓中的殘留及其風(fēng)險評估[J]. 農(nóng)藥學(xué)學(xué)報,2009,11(4):449-455.
[24]岳東霞,張要武. 番茄根際促生菌——假單胞菌的生防作用[J]. 華北農(nóng)學(xué)報,2009,24(5):210-213.
[25]劉寧. 番茄灰霉病菌生防細(xì)菌BAB-1的鑒定及發(fā)酵工藝的優(yōu)化[D]. 保定:河北農(nóng)業(yè)大學(xué),2009.
[26]胡朋,申琳,范蓓,等. 番茄灰霉病拮抗細(xì)菌Bacillus-1的篩選和鑒定[J]. 食品科學(xué),2008,29(6):276-279.
[27]韓斯琴,徐梅,白震,等. D2-4放線菌抗真菌病害活性成分研究[J]. 微生物學(xué)雜志,2004,24(1):8-10.
[28]谷祖敏,蘇州,劉宏偉,等. 番茄灰霉病菌拮抗放線菌的分離和篩選[J]. 遼寧農(nóng)業(yè)科學(xué),2004,39(5):1-2.
[29]徐大勇,李峰. 番茄灰霉病拮抗內(nèi)生細(xì)菌的篩選、鑒定及其活性[J]. 中國生物防治學(xué)報,2012,31(4):298-302.
[30]周榮金,袁高慶. 煙草灰霉病復(fù)合生防細(xì)菌的篩選[J]. 中國煙草學(xué)報,2015,20(6):107-112.
[31]張紅娟,盧海波,趙麗娟,等. 生防菌HT3和HT5代謝產(chǎn)物對灰葡萄孢菌的抑菌作用[J]. 山西農(nóng)業(yè)科學(xué),2013,41(12):1372-1375.
[32]張亞,蘇品,劉雙清,等. 拮抗假單胞菌 SU8 對幾種植物病原真菌的抑制作用[J]. 農(nóng)藥,2013,52(12):917-920.
[33]耿建峰,黑田克利,田中一久. 洋蔥油和大蒜提取物對灰霉菌的作用效果[J]. 中國蔬菜,2008(5):20-22.
[34]尹曉東,何智勇,魏松紅,等. 大蒜提取液對番茄兩種真菌病害的抑制作用[J]. 沈陽農(nóng)業(yè)大學(xué)學(xué)報,2008,39(1):89-91.
[35]黃彰新. 植物化學(xué)保護(hù)實驗指導(dǎo)[M]. 北京:農(nóng)業(yè)出版社,1993.
[36]Wadley F M. Experimental statistics in entomology[M]. Craduate School Press,U.S. Dept of Agriculture,1967:387.
[37]陳年春. 農(nóng)藥生物測定技術(shù)[M]. 北京:中國農(nóng)業(yè)大學(xué)出版社,1990:135-165.
[38]敖禮林,況小平. 植物源殺菌劑簡介[J]. 農(nóng)業(yè)知識:致富與農(nóng)資,2013(8):51-53.
[39]彭雙強(qiáng),張亞,廖曉蘭,等. 拮抗細(xì)菌發(fā)酵提取物與井岡霉素混配對水稻紋枯病的毒力研究[J]. 湖南農(nóng)業(yè)科學(xué),2015(9):20-23.
[40]張亞,蘇品,劉雙清,等. 一株假單胞菌SU8抑菌物質(zhì)的研究初報[J]. 中國植保導(dǎo)刊,2014,34(6):13-18.
[41]蘇品. 稻鴨種養(yǎng)生態(tài)系統(tǒng)抑制水稻紋枯病的發(fā)生流行規(guī)律及拮抗菌SU8生防潛力研究[D]. 長沙:湖南農(nóng)業(yè)大學(xué),2012.楊棟,李俊領(lǐng),金曉婷,等. 幾種殺蟲劑對韭菜遲眼蕈蚊幼蟲的室內(nèi)毒力篩選及藥劑混配研究[J]. 江蘇農(nóng)業(yè)科學(xué),2017,45(6):83-85.
doi:10.15889/j.issn.1002-1302.2017.06.020
猜你喜歡
中國科技博覽(2016年22期)2016-11-01 15:37:02
中國科技博覽(2016年22期)2016-11-01 15:36:18
中國科技博覽(2016年22期)2016-11-01 15:09:03
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 21:17:37
中國科技博覽(2016年19期)2016-10-19 14:36:07
中國科技博覽(2016年19期)2016-10-19 13:22:33
中國科技博覽(2016年19期)2016-10-19 13:05:18
中國科技博覽(2016年19期)2016-10-19 11:56:15
中國科技博覽(2016年18期)2016-10-19 11:35:47
中國科技博覽(2016年18期)2016-10-19 11:32:09
