基于隨機森林的P2P網絡借貸成功率預測研究
2016-02-07 09:21:04周玉琴張曉玫羅璇
東北農業大學學報(社會科學版) 2016年6期
關鍵詞:模型
周玉琴 張曉玫 羅璇
(西南財經大學,四川成都 611130)
基于隨機森林的P2P網絡借貸成功率預測研究
周玉琴 張曉玫 羅璇
(西南財經大學,四川成都 611130)
P2P網絡借貸成功率較低是P2P網絡借貸市場快速發展瓶頸。探索借貸成功率提高路徑,構建基于隨機森林的網絡借貸成功率評估模型,根據“人人貸”平臺2015年一季度訂單數據,選取借款人基本特征、歷史信息、貸款特征及認證信息等33個變量,最大限度包含借款訂單信息。研究表明歷史借款成功率、未還清借款量、收入認證等是借貸成功率重要影響因素;預測P2P網絡借貸成功率時,隨機森林方法準確率明顯優于Logistic回歸模型等方法。
隨機森林;smote算法;P2P網絡;歷史借貸成功率
P2P網絡借貸依托于互聯網技術與民間借貸,可快速發布信息并被投資者檢索,促成交易高效匹配,提升市場效率。P2P網絡借貸準入門檻較低[1](投資者僅需出資50元以上即可),參與方式較靈活,借貸雙方具有廣泛性。然而,由于交易通過互聯網渠道完成,借款人可能是傳統金融機構篩選后的“次級客戶”,而借貸平臺無法考查所有借款人情況,且出借人可能不具備良好風險識別與承受力,導致基于信用的網絡借貸平臺借貸成功率偏低,制約網絡借貸市場持續健康發展。如何從大量借款訂單信息中挑選少量預測P2P網絡借貸平臺借貸成功率,進而減少信息搜集成本,一直被監管層、投資者以及學者廣泛關注。研究表明性別、借款人信用等級、年齡以及信用評級等對P2P網絡借貸成功率具有顯著影響[2-3],已有文獻多采用統計模型(多元回歸、Logistic回歸和Tobit回歸等)研究網絡借貸成功率影響因素,但并未給出變量重要程度排序。雖然統計模型具有廣泛適用性,但線性、非線性傳統統計學嚴格假設條件要求預測變量、函數形式間相互獨立,與實際函數關系不符。因此,本文運用機器學習方法中的隨機森林算法研究P2P網絡借貸成功率影響因素。
隨機森林是一種非參數統計方法,預測準確率與噪聲容忍度明顯優于支持向量機、神經網絡、決策樹等機器學習方法[4]。近年來,隨機森林被廣泛運用到客戶流失、信用風險管理、客戶忠誠度研究等領域,學者發現較之Logistic回歸與普通線性回歸,隨機森林預測效果明顯更優[5-6]。因此研究引入非參數隨機森林模型評估與預測P2P網絡借貸成功率,為網絡借貸平臺、借款人及投資者提供參考。本研究與已有研究主要區別:一是運用隨機森林模型評估P2P網絡借貸成功率,并與其他模型比較評估準確率;二是運用隨機森林模型分析各變量重要程度,降低數據維度,為投資者選取標的提供指標參考;三是在借貸成功率影響因素選擇上,選取33個變量,最大限度包含借款訂單信息。
一、網絡借貸成功率評估模型
(一)Logistic回歸模型
選擇通用Logistic回歸模型作為其他方法比較基準,可識別自變量對P2P網絡借貸成功率的影響方向與程度。Logistic模型具體形式見式(1):
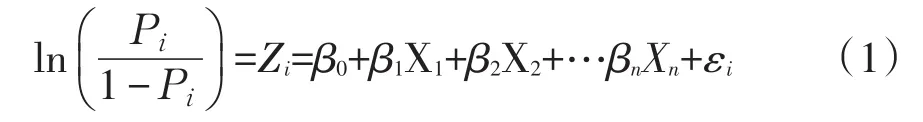
其中Pi為網絡借貸成功率,βi(i=0,1,…,n)為待估計系數,Xi(i=0,1,…,n)為自變量,εi為隨機誤差項。網絡借貸成功率指借款成功率變量為1的概率,自變量包括借款人基本特征、歷史信息、貸款特征、認證信息等33個變量。
(二)隨機森林分類模型
Logistic回歸模型解決因變量不連續回歸問題,但線性或非線性以及變量間獨立傳統統計假設與現實數據不符,為開發一種更精確通用方法解決此問題,數據挖掘與機器學習方法被廣泛應用于預測,取得較好效果。大量理論與實證研究證明隨機森林預測準確率較高,對異常值與噪聲具有容忍度,且不易出現過擬合[4]。隨機森林方法在生物信息學、農學和醫學等領域應用,但尚未運用于P2P網絡借貸成功率影響因素分析。因此,本研究選用此方法評估P2P網絡借貸成功率。
隨機森林方法具有很好自適應功能,結合隨機子空間算法和Bagging算法特點與優勢,以決策樹為基分類器。在訓練集抽樣時采用Bagging算法無放回抽樣法,借鑒隨機子空間方法,在訓練集中僅抽取部分特征訓練,最終由訓練決策樹投票決定分類結果,如圖1所示。即隨機森林分類是組合分類模型,由若干決策樹分類模型{h(X,θi),i= 1,…k}組成,且參數集{θi}是獨立分布隨機變量,在給定自變量X下,各決策樹分類模型均有一票投票權選擇最優分類結果。網絡借貸成功率問題中,因變量為P2P網絡借貸成功率(成功為1,失敗為0),由于因變量是二值變量,估計模型采用隨機森林二分類模型,而非隨機森林回歸模型。
隨機森林分類器算法如下:第一步,從P2P網絡借貸數據中抽取一定比例包含借款訂單信息的樣本集D作為原始訓練集,剩余樣本集作為預測集;第二步,運用Bootstrap重抽樣方法從D中抽取k個子樣本集,其中子樣本集與原始樣本集D樣本容量一致,記為Di(i=1,2,…,k),并生成隨機向量序列θi(i=1,…,k),通過構造不同訓練集增加模型間差異,提高組合分類模型外推預測能力;第三步,從P2P網絡借貸數據中篩選出用于研究網絡借貸成功率的自變量矩陣X,然后對各子集樣本Di(i=1,2,…,k)分別建立網絡借貸決策模型{h(X,θi),i=1,…,k};第四步,構建多分類模型系統,該系統由經過k輪學習得到分類模型序列{h1(X),h2(X),…,hk(X)}組成,且最終分類決策可用公式(2)(說明最終分類由多數投票決策方式確定)表示,其中,Y為目標變量(或稱輸出變量),hi表示單個決策樹分類模型,H(X)為組合分類模型,I(·)表示性函數。
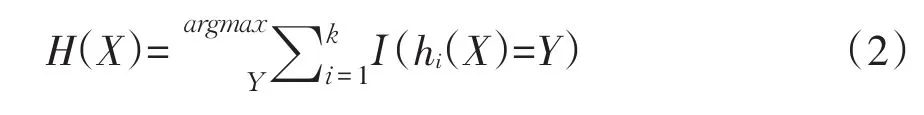
篩選變量是隨機森林重要特征,運用預測精度法與基尼值法評價變量重要性。首先,對生成的隨機森林,用OOB(out-of-bag)數據(在使用Bootstrap方法抽樣時,訓練集中數據不會出現在各Bootstrap樣本中,OOB數據即未被抽中數據)測試性能,得到原始OOB基尼值;其次,在OOB某特征值中人為添加噪聲干擾(即隨機改變特征值),用改變后OOB數據測試隨機森林性能,得到加入噪聲后的OOB基尼值;最后,相應特征重要性度量值為原OOB基尼值與加入噪聲后OOB基尼值之差。加入噪聲后OOB基尼值下降幅度越大,則該特征重要程度越高。
(三)模型評價標準
運用準確度、靈敏度和特異性指標比較各模型結果,準確度度量全部樣本被正確分類比例,靈敏度度量正例樣本被正確分類比例,特異性度量負例樣本被正確分類比例。指標值越大,說明模型效果越好。通過混淆矩陣(見表1)定義三個指標,將值得關注的數據稱為正類(本研究指貸款成功樣本),其他稱為反類。
準確度=100×(TP+TN)/(TP+TN+FP+FN)
靈敏度=100×TP/(TP+FN)
特異性=100×TN/(TN+FP)
二、變量描述與模型構建
(一)變量選擇
根據已有研究,認為借款人基本特征及歷史信息、借款特征、平臺認證信息等與P2P網絡借貸成功率存在相關關系。
借款人基本特征主要包含借款人婚姻狀況、學歷、性別、年齡、行業、公司規模、工作城市、收入范圍、工作階層、房產、房貸、車產、車貸、信用等級等指標。借款人歷史信息指借款人歷史借貸成功率、未還清借款數量、逾期金額、嚴重逾期筆數,借款人持有債權數量、U計劃①U計劃在用戶認可標的范圍內,對符合要求標的自動投標,且回款本金在相應期限內自動復投,期限結束后U計劃會通過“人人貸”債券轉讓平臺轉讓退臺,詳細信息可參考http://www.renrendai.com/financeplan/listPlan.action。數量、薪計劃②薪計劃是針對工薪族理財需求的高效自動投標工具,用戶可在每月固定日期投入固定金額,詳細信息可以參考http://www.renrendai. com/autoinvestplan/listPlan!detailPlan.action。數量等特征。
借款特征指借款金額、期限、用途、利率、保障方式等,借款金額與借貸成功關系研究最多。大量研究表明,借款人借貸行為與其基本特征及貸款特征高度相關。Seth研究指出借款人基本信息與借款金額影響投資者最終投資決策,借款人提高借款金額時,借貸成功率相對下降[7];Pope等分析借貸成功率與借款人年齡關系,研究表明較之35歲以下人群,35~60歲人群貸款成功機率更高[3]。
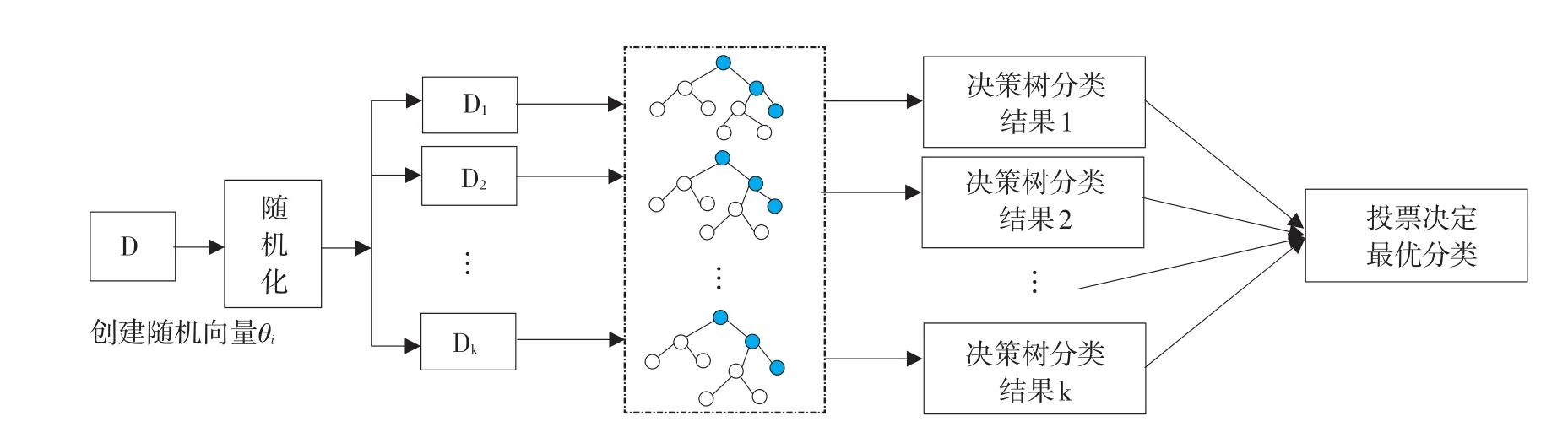
圖1 隨機森林結構示意

表1 混淆矩陣
認證信息包含機構擔保、信用報告、工作認證、實地認證、身份認證、收入認證、房產認證、車產認證、婚姻認證等特征。Puro等研究表明當前拖欠記錄、總負債償還比例及信用得分等是借貸成功率主要影響因素[8];王會娟和廖理[9]研究P2P網絡借貸平臺信用認證機制對借貸行為的影響,發現信用評級越高,借款成功率越高且借款成本越低,進一步分析認證指標與方式對借貸行為的影響,研究表明工作、收入、車產、房產等認證指標對借貸行為影響較大。
(二)變量說明與數據處理
1.數據來源與變量說明。采用2015年一季度“人人貸”網站全部借款訂單作為初始樣本,共收集56 614筆真實交易數據,其中借款失敗樣本46 062份,借款成功樣本10 552份。數據集包含33個變量,包括借款人基本特征、借款人歷史信息、借款特征及認證信息等,見表2。
2.數據預處理。為剔除缺失值對實證分析的影響,必須檢測缺失值,原始樣本中含有缺失值29 261個,其中成功借款1 030個,失敗借款28 231個,剔除缺失值后剩余有效樣本27 353個,其中成功借款9 522個,失敗借款17 831個。從原始數據缺失變量個數(見表3)發現,缺失變量超過3個的借款訂單成功概率極小,說明借貸成功率與借款人信息完整程度成正比。由于實地認證標③實地認證標由“人人貸”與友眾信業金融信息服務(上海)有限公司(以下簡稱“友信”)共同推出,產品在原有審核基礎上,增加友信前端工作人員對借款人情況實地走訪,審核調查以及貸中、貸后服務環節中,加強風險管理控制,達到雙重保障效果。、機構擔保標④“人人貸”為提高資金借貸安全性,引入“中安信業”“證大速貸”作為合作伙伴,為相應借款承擔連帶保證責任,有機構擔保的借款為機構擔保標。本研究討論借貸行為影響因素,主要針對無擔保借款,因此剔除此類觀測值。及信用認證標認證機制不同,因此剔除機構擔保標576個和實地認證標8 222個,剩余有效樣本18 555個。樣本中非信用認證標8 798個,其中成功借款8 796個,失敗借款2個,說明經過實地認證與機構擔保的借款成功率較高。
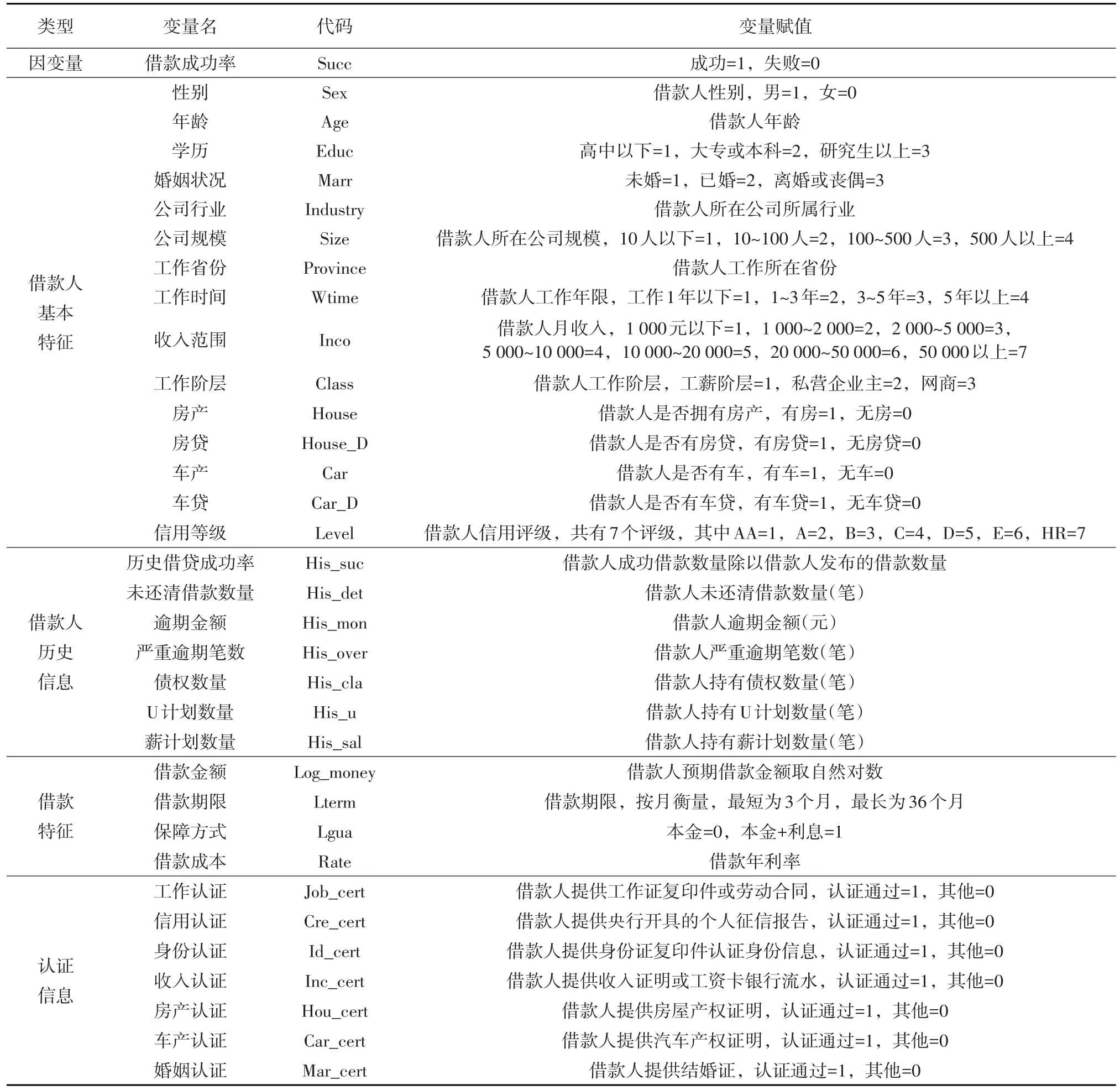
表2 變量說明

表3 樣本中缺失變量個數
剔除缺失值和非信用認證標后,剩余有效樣本中成功借款726個,失敗借款17 829個,數據集過多集中于失敗借款,造成數據嚴重失衡,即樣本非對稱分布問題,使模型無法正確分類預測成功借款類別[10]。因此,本研究采用Smote算法平衡數據,該方法以新生成數據豐富原數據樣本,綜合運用過采樣與欠采樣技術,解決數據分布稀疏性問題[11]。
運用有效樣本集生成訓練集、測試集及預測集。首先,在有效樣本中隨機抽取約20%樣本(3 711個數據)作為預測集,主要檢驗平衡后模型對有效樣本集適應性;其次,用剩余14 844個數據(包含586個成功借款)平衡抽樣,采用Smote算法,將成功與失敗比例約平衡為1∶3[12]。平衡后數據集中包含1 172個成功借款和3 516個失敗借款,最后將2/3平衡后數據作為訓練集(包含782個成功借款,2 344個失敗借款),1/3作為測試集(包含390個成功借款,1 172個失敗借款)。
(三)特征描述
有效樣本數據集中,總體成功率約3.9%。為了解各類借款人成功率情況,將借貸成功情況與已有研究中關注較多變量交叉分析,包括性別、年齡及信用等級(見圖2、3、4)。
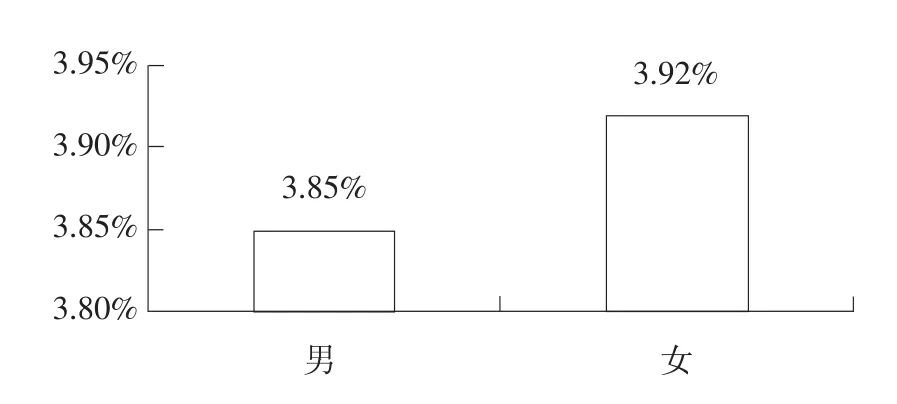
圖2 不同性別借款成功率
從圖2可知,女性借款者成功率略高于男性借款者,但差距不明顯。圖3表明30~40歲借款者成功率最高,而50歲以上借款者成功率最低,說明各年齡層借貸成功率存在差異。圖4顯示HR信用等級借款者(占有效樣本97%)中僅2.49%借款者能夠獲得資金,說明信用等級較低借款者,無法通過傳統銀行體系獲得借款時,也很難通過P2P網絡借貸平臺獲得借款,但其他等級中未出現信用等級越高借入者越易獲得借款情況。
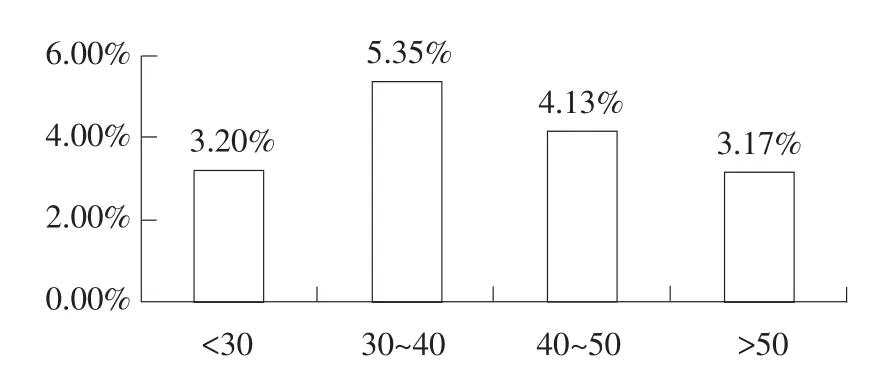
圖3 不同年齡借款成功率
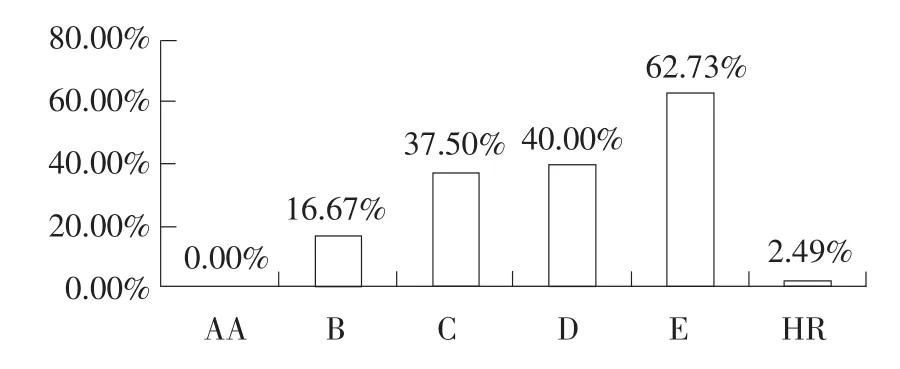
圖4 不同信用等級借款成功率
三、實證分析
(一)確定指標體系
由于原始自變量較多,變量間包含一些共性信息,非所有變量均有助于評估借貸成功率,可能因變量間相關性等降低了模型有效性,因此在確定借貸成功率評估模型前,從原始變量中選取合適變量建立成功率評估指標體系,有助于投資者在投標時審核和重點關注。為選取合適評估指標體系,運用隨機森林方法計算變量重要性(通過在變量加入噪聲前后的預測準確性差異判斷),并篩選出預測模型自變量。
從表4發現借款者歷史信息與認證信息重要性強于貸款特征與借款者基本特征變量,其中“歷史借貸成功率”和“未還清借款數量”是影響貸款成功率極重要變量。在認證信息中,“收入認證”“工作認證”“信用認證”比其他認證信息重要;在借款者基本特征中,“信用等級”重要性強于其他變量;在貸款特征中,“貸款金額”“貸款利率”更重要。
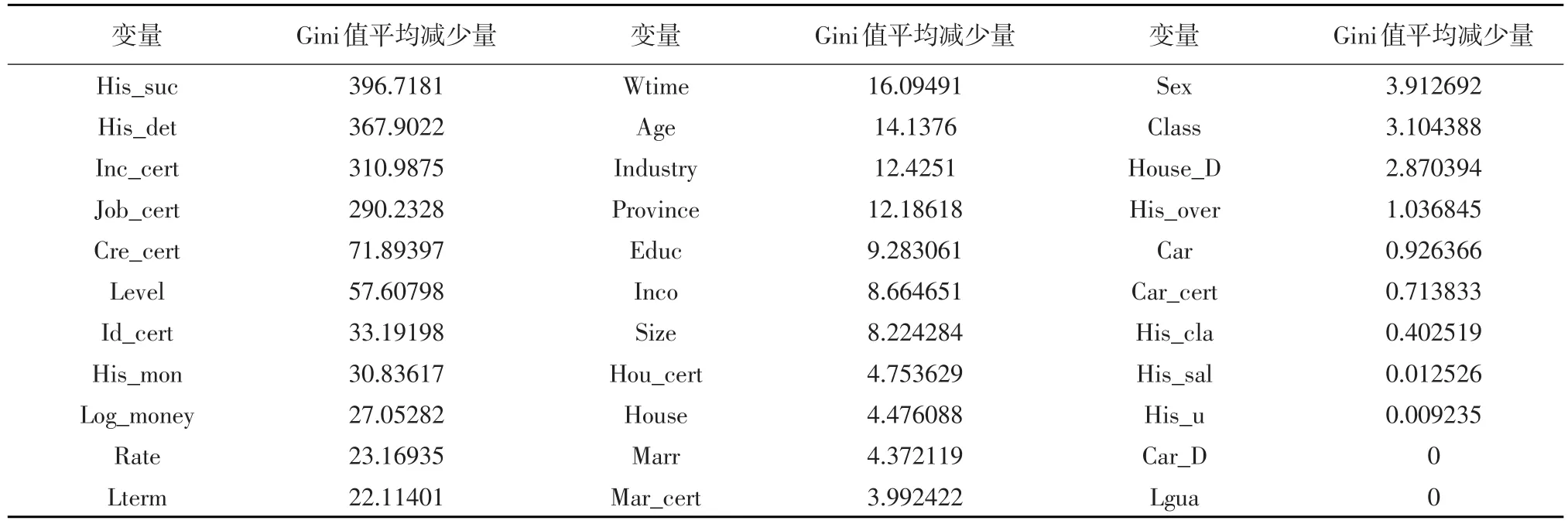
表4 變量重要性
根據變量重要性排序,分別選取前6個變量、前10個變量、前14個變量、前18個變量為輸入變量集,運用隨機森林方法分別計算訓練集、測試集及預測集準確度、靈敏度與特異性,其中隨機森林參數取值為系統默認值,以此確定最優指標體系。
為檢驗平衡后模型對有效樣本集的適應性,重點關注預測集評價指標,由于投資者更關注成功可能性較高借款訂單,因此重點關注準確度與靈敏度指標。結果進一步驗證選取合適指標體系必要性(見表5)。前10個變量模型在訓練集與預測集里靈敏度最高,準確度和特異性也高于前6個變量模型;雖前10個變量模型準確度非最高,但總體精度較高,在預測集中為98.14%。綜合而言,10個變量最合適,且該模型相對14個變量與18個變量所需變量較少,可提高投資者選擇效率,縮短訂單滿標時間。

表5 不同輸入變量評價指標
(二)模型結果與解釋
以前10個變量為輸入變量,建立隨機森林模型,同時建立決策樹、神經網絡、貝葉斯、支持向量機及Logistic模型預測模型并比較。各模型預測結果表明隨機森林模型預測準確度、靈敏度和特異性均較高,支持向量機與貝葉斯在預測靈敏度方面較好,但預測準確度低于神經網絡和Logistic模型。此外,貝葉斯、支持向量機和隨機森林模型對成功借款預測準確率(靈敏度)高于失敗借款預測準確率(靈敏度)(見表6)。隨機森林模型在訓練集、測試集和預測集準確度與特異性均優于其他模型。
(三)穩健性檢驗
為檢驗平衡比例對模型效果影響,采用Smote算法對剩余14 844個數據平衡抽樣,將成功和失敗比例分別平衡為1∶2與1∶4,平衡后數據2/3作為訓練集,其余數據作為測試集,平衡后樣本情況如表7所示。不同比例下模型在預測集中準確度表明,隨機森林模型在預測集準確度均高于其他模型,且比例越高的預測集準確度越高,如圖5所示。
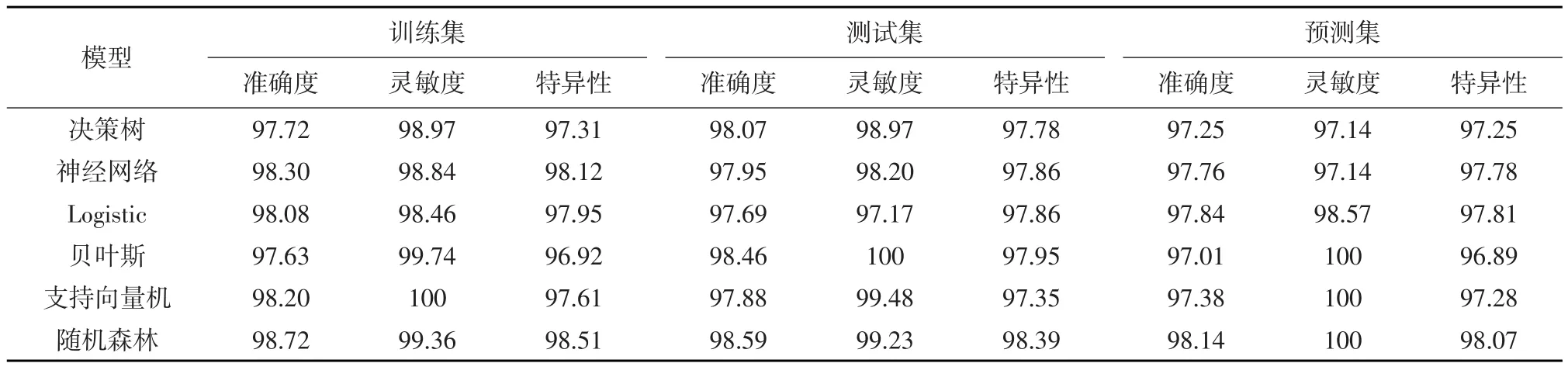
表6 六種模型比較

表7 平衡后樣本統計表
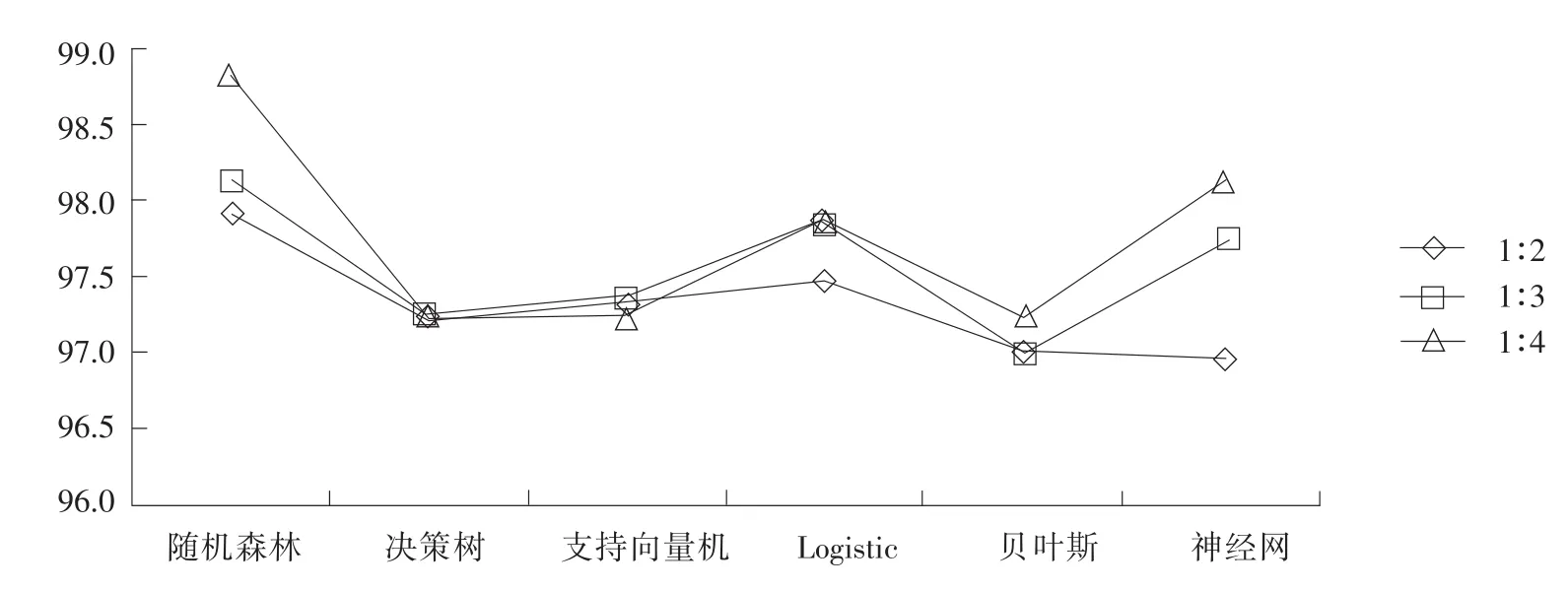
圖5 不同平衡比例預測集準確度
四、結語
本研究根據“人人貸”2015年一季度數據,建立基于非參數隨機森林的借貸成功率評估模型,并與決策樹、支持向量機、貝葉斯、神經網絡和Logistic回歸算法比較,其中隨機森林模型預測集準確度最高,約98%。隨機森林借貸成功率模型評估所有變量重要程度,選取33個變量中前10個重要變量(歷史借貸成功率、未還清借款數量、收入認證、工作認證、信用認證、信用等級、身份認證、預期金額、貸款金額和借款成本)預測借款訂單成功率,可降低信息搜集成本。基于隨機森林借貸成功率評估模型快捷篩選出成功率較高訂單,提高投資者選擇有效性,且模型避免復雜計算過程,適用于網絡借貸平臺海量且不斷增加的訂單。將隨機森林方法應用到我國網絡借貸成功率評估模型上,為進一步實際應用網絡金融提供實證參考,充實網絡借貸行為理論研究。由于隨機森林模型未給出變量對借貸成功率的影響方向,后續研究中可深入分析。
[1]帥青紅.P2P網絡借貸監管的博弈分析[J].四川大學學報(哲學社會科學版),2014(4).
[2]Lin M,Prabhala N R,Viswanathan S.Judging Borrowers by the Company They Keep:Social Networks and Adverse Selection in Online Peer-to-Peer Lending[J].Management Science,2012(1).
[3]Pope D G,Sydnor J R.What’s in a Picture?Evidence of Discrimination from Prosper.com[J].Journal of Human Resources,2011(1).
[4]Breiman L.Random Forests[J].Machine Learning,2001(1).
[5]Lariviere B,Den Poel D V.Predicting Customer Retention and Profitability by Using Random Forests and Regression ForestsTechniques[J].Export Systems with Application,2005(29).
[6]方匡南,吳見彬.個人住房貸款違約預測與利率政策模擬[J].統計研究,2013(10).
[7]Seth Freedman,Ginger Z J.Do Social Networks Solve Information Problems for Peer-to-Peer Lending?Evidence from Prosper.com [EB/OL].(2016-04-20).https://ideas.repec.org/p/net/wpaper/0843. html.
[8]Puro L,Eieh J E T,Wallenius H,et al.Borrower Decision Aid for People-to-people lending[J].Decision Support System,2010(1).
[9]王會娟,廖理.中國P2P網絡借貸平臺信用認證機制研究—來自“人人貸”的經驗證據[J].中國工業經濟,2014(1).
[10]方匡南,吳見彬,謝邦昌.基于隨機森林的保險客戶利潤貢獻度研究[J].數理統計與管理,2014(6).
[11]Chawla N V,Bowyer K W,Hall L O,et al.Smote:Synthetic Minority Over-sampling Technique[J].Journal of Artificial Intelligence Research,2002(1).
[12]石曉軍.Logistic違約率模型最優樣本配比與分界點的模擬分析[J].數理統計與管理,2006(6).
F832
A
1672-3805(2016)06-0011-07
2016-10-12
國家自然科學基金項目“小微企業互聯網平臺融資模式研究—基于雙向拍賣和信號博弈雙重視角”(71503210)
周玉琴(1990-),女,西南財經大學金融智能與金融工程四川省重點實驗室博士研究生,研究方向為金融風險管理、金融工程。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
