基于知識融合的CRFs藏文分詞系統
2015-04-14 07:50:42洛桑嘎登楊媛媛趙小兵
中文信息學報 2015年6期
洛桑嘎登,楊媛媛,趙小兵
(1.中央民族大學信息工程學院,北京100081;2.中央民族大學少數民族語言文學系,北京100081;3.中央民族大學國家語言資源監測中心少數民族語言分中心,北京100081)
1 引言
藏文自動分詞可以看作是計算機自動辯識藏文文本字符流中的詞,并在詞與詞之間加入明顯的詞切分標記符的過程[1]。藏文自動分詞的主要目的是確定藏文信息處理的基本語言單位,為進一步開展藏文智能分析和處理做好前期準備工作。目前藏文分詞技術的研究方法大體可以分成兩類,一種是基于藏文自身的語法特點,首先將文本通過標點分成句子,其次通過格助詞將句子分成組塊,最后再對組塊內部通過匹配等方法將詞與詞分開;另一種是基于統計的方法,將在中文分詞中取得不錯效果的統計自然語言的方法移植到藏文自然語言處理過程中,例如隱馬爾科夫,最大熵,條件隨機場等。
2 相關研究
藏語分詞作為藏文信息處理中重要的基礎工作,迄今為止已經有不少學者進行了研究。最早的關于藏文分詞系統的研究可以追溯到1997年,江荻進行了規則分詞技術研究,提出藏語最大匹配算法、任意詞和句尾詞分詞匹配校驗等設計方案。1999年,羅秉芬、江荻等從12萬詞條和500萬字藏語真實文本語料分詞的實踐中歸納出了藏文計算機自動分詞的36條基本規則,并提出了藏文分詞的基本框架[2]。同年扎西次仁基于5 000多個常用詞詞表,利用最大匹配法和人工校對的方式實現了分詞功能,但是由于詞庫和方法上的局限性,該系統僅僅具備演示效果,不具備實用性[3]。2003年,陳玉忠從藏文的語法接續規則出發,提出了基于格助詞和接續特征的書面藏語自動分詞方案[4],并依據該分詞方案的總體設計思路,陳玉忠等闡述了書面藏語自動分詞系統的具體實現過程[5]。該方案在將藏文句子分塊的過程中增加了藏文語法中接續規則,一定程度上提高了分詞的準確性,但是無法切分的塊,采取加標記但不切分的“謹慎”策略,并默認其屬于未登錄詞。這樣的做法顯然對未登錄詞的識別不夠精確。2009年,才智杰設計了“班智達藏文分詞系統”[6],此系統分三步實現分詞功能,首先將文本分成句子,再通過格助詞將句子分成組塊,塊內再通過詞典匹配切分成詞,并對詞典搜索算法進行了改進,既對詞典進行按照詞長排序,以提高搜索速度。但是此方法針對在分詞中存在的歧義問題,沒有給出合理的處理方法。
以上系統實現的技術思路主要是根據藏語中的接續特征[7],字、詞、句各級語言單位之間的自然切分標記,先利用字切分特征、字性庫“認字”,再用標點符號、關聯詞“斷句”,用格助詞“分塊”,最后通過詞典匹配“認詞”。該技術方案進一步發展為組塊分詞策略,即充分利用藏語豐富的句法形式標記,通過各類名物化標記、格標記、指代詞、連詞、動詞語尾、構詞詞綴等形式標記構建不同的藏語句法組塊類型,并建立相應的組塊規則,分詞時先根據形式標記和規則分塊,然后在塊內進行分詞。在具體操作時采取最大正向匹配法、最大逆向匹配法或者是最大雙向匹配法等不同的策略。
隨著漢語分詞開始使用各種統計機器學習模型,如隱馬爾科夫模型、最大熵馬爾科夫模型、條件隨機場模型等,基于統計的藏語分詞研究成果也逐漸多起來。2011年,史曉東、盧亞軍率先把統計方法引入藏語分詞研究,他們開發的央金藏文分詞系統把漢語分詞系統Segtag的技術移植到藏語分詞中,實現了藏語的分詞標注一體化[8]。該系統主要采用的隱馬爾科夫模型,使用了約2.7M文本作為訓練語料,其分詞結果F值為91.115%。2012年,劉匯丹等在研究分析了藏文分詞中的格助詞分塊、臨界詞識別、詞頻統計、交集型歧義檢測和消歧等問題之后,設計實現了一個藏文分詞系統SegT[9],該系統采用雙向切分檢測交集型歧義字段進行消歧處理,在系統分詞的正確率上得到了很大的提升。此外,江荻[10]、羊毛卓么[11]、扎西加[12]等學者還對藏文詞語詞形變體識別規則、詞組結構以及詞性標注等方面進行了研究,總體上推進了藏文分詞以及文本分析研究的進展。
3 基于條件隨機場的藏文自動分詞
3.1 條件隨機場相關介紹
條件隨機場(Conditional Random Fields,CRFs)是一種基于統計的序列標記識別模型,它由John Lafferty,Andrew McCallum和Femando Peerira在2001年首次提出[10-11]。它是一種無向圖模型,對于指定的節點輸入值,它能夠計算指定的節點輸出值上的條件概率,其訓練目標是使得條件概率最大化[11]。線性鏈是CRFs中常見的特定圖結構之一,它由指定的輸出節點順序鏈接而成。一個線性鏈與一個有限狀態機相對應,可用于解決序列數據的標注問題。下面,如果不加說明,CRFs均指線性的CRFs。用x=(x1,x2,…,xn)表示要進行標注的數據序列,y=(y1,y2,…,yn)表示對應的結果序列。例如,對于藏文分詞任務,x可以表示一個藏文句子則表示該句子中每個音節所在位置的序列y=(B,E,B,I,Eg,S,S,B,I,I,E,S,B,E,B,I,E,S,S,S,B,E,B,I,E,S,S,S)
對于(X,Y),C由局部特征向量f和對應的權重向量λ確定。對于輸入數據序列x和標注結果序列y,條件隨機場C的全局特征表示為式(1)。
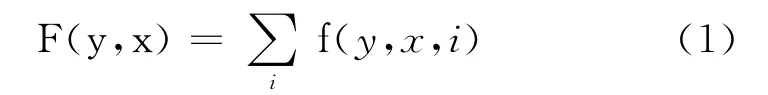
其中i遍歷輸入數據序列的所有位置,f(y,x,i)表示在i位置時各個特征組成的特征向量。于是,CRFs定義的條件概率分布為式(2)。

其中:
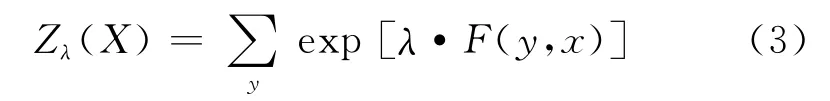
給定一個輸入數據序列X,標注的目標就是找出其對應的最可能的標注結果序列,即式(4)。
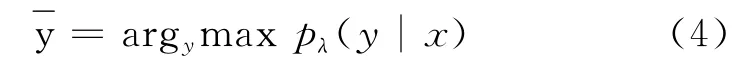
由于Zλ(X)不依賴于y,因此有式(5)。
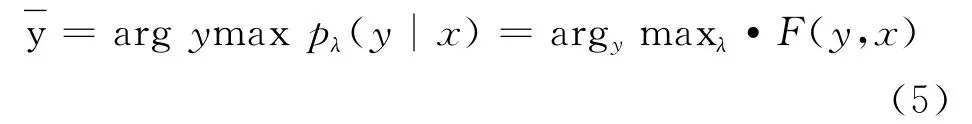
CRFs模型的參數估計通常采用L-BFGS算法實現,CRFs解碼過程,也就是求解未知串標注的過程,需要搜索計算該串上的一個最大聯合概率,解碼過程采用Viterbi算法來完成。
CRFs具有很強的推理能力,能夠充分地利用上下文信息作為特征,還可以任意地添加其他外部特征,使得模型能夠獲取的信息非常豐富。CRF模型沒有隱馬爾可夫模型(Hidden Markov Model,HMM)的強獨立性假設條件,因此可以加入更多的文本信息特征;而且CRFs模型計算的是全局而非局部最優輸出結點的條件概率,正因如此它解決了最大熵模型(Maximum EntroPy Model,MEM)的標記偏置問題。CRFs模型能更容易的融合客觀世界數據的真實特征,因此,此模型被廣泛用于自然語言處理的很多領域。
3.2 基于CRFs的藏文分詞
3.2.1 總體流程
如圖1所示,我們對整個實驗的流程做簡單的陳述,

圖1 基于CRF和規則的藏文分詞的流程圖
第一步,首先將從西藏新聞網、人民網藏語頻道和青海藏語廣播網爬取的語料進行預處理,通過詞典匹配分詞,再先后經過三次的人工校正,形成訓練語料。將訓練語料進行標注轉換后,利用CRFs模型對轉換后的語料進行訓練,最終生成模型參數。
第二步,對來自新華網的語料進行預處理,進行詞典匹配分詞,再先后經過三次的人工校正,形成測試語料。
第三步,通過測試語料反復測試結果,確定特征模板。
第四步,通過分析CRFs分詞結果中的典型錯誤設計規則,在上一步識別的基礎上,進行二次識別,最終得到分詞結果。
3.2.2 藏文自動分詞標注集的選擇
我們首先定義條件隨機場模型的訓練所需要的標準集,標注集的目的是確定某個音節在藏文詞的位置,以此確定某個藏文詞的邊界。而藏文文本存在其特有的黏著詞,所以在對音節標注時,對于非單個音節構成的詞的右邊界和單音節構成的詞需要區分是黏著形式還是非黏著形式,因此目前研究者在基于條件隨機場的藏文分詞的標注集的選擇上分為兩種方法,第一種是先標注黏著詞,即在分詞之前先通過二元標注集(Y/N)標注當前詞是否為黏著形式,再進行分詞[12];第二種方法是直接在標注音節位置的同時增加兩個新的標簽,即五元標注集(B,I,E,S,SS,ES)[13]。本文使用第二種方法。以藏文的每個音節為對象,標注集中主要定義了藏文詞匯的開始音節、內部音節、結尾音節、黏著形式的單字和黏著形式的結尾音節,共五種類型,如表1所示。

表1 藏文分詞標注集
3.2.3 藏文自動分詞特征集的選擇
使用CRFs進行藏文分詞的過程就是給定一個藏文句子x=(x1,x2,…,xn),通過Viterbi解碼算法找出其對應的每個音節的位置信息的結果序列y=(y1,y2,…,yn),使得條件概率Pλ(y|x)最大。而在基于CRFs的標注分類問題中,特征函數的選擇通常起著關鍵性作用,特征選擇的好壞直接決定著CRFs標注結果的優劣。CRFs最大的優點之一就是特征的選擇很靈活,根據要解決的問題,能夠融入任意的特征。選擇不同的特征,所得到的實驗結果是不相同的。在本實驗中,對于特征的選擇,利用了詞的上下文信息,這里所謂的“上下文”可以看作是以當前詞為基線的、包括其前后若干詞的一個“觀測窗口”(w-n,w-(n-1),…,w0,…,wn-1,wn)。本文采用的特征模板如表2所示。

表2 藏文分詞模型的特征模板
3.2.4 未登錄詞的處理
雖然我們的訓練語料足夠大,但是對人名、地名、組織機構名等的命名實體的覆蓋面有限,不可避免地會遇到一些在訓練語料中沒有出現的詞,在這里把這類詞稱之為未登錄詞。未登錄詞的正確標注是分詞的一個難點,其標注結果的好壞,會直接影響到整個分詞的正確率。解決未登錄詞正確標注的方法有兩種,第一種是在訓練語料中覆蓋足夠多的人名、地名、組織機構名;第二種方法是通過總結規則來提高未登錄詞標注的準確率。本文基于以上兩種思想,在人民網藏語頻道2014年的全年的共6 000多篇藏文文章中提取了14 077條人名,5 359條地名,6 899條組織機構名,共26 335條命名實體加入訓練集中,同時整理了藏語常用地名、人名、組織機構名實體庫。
3.3 基于知識融合的藏文分詞
我們通過總結CRFs分詞結果的錯誤,并對錯誤進行分析,歸納總結了基于藏文自身知識的分詞規則,并通過這些知識對CRFs的結果進行校正。主要針對非藏文字符切分錯誤,藏文黏著詞識別錯誤,停用詞切分錯誤,一些典型的人名、地名、組織機構名的識別錯誤等問題分別總結了規則。首先列舉幾個基于CRFs的識別結果中的典型例句和經過模型識別后的錯誤標注序列以及其正確的標注序列,然后針對這些典型例句錯誤標注序列進行分析。
3.3.1 非藏文字符的識別錯誤修正
CRFs切分結果:

正確的切分結果:

切分錯誤:65應切分/65
導致該類錯誤的原因是有兩種,一是由于語料中存在一定量的非藏文字符,而本文所采用的基于CRFs的方法是對藏文音節序列的標注,我們將未分詞的藏文語料按照音節序列交給CRFs模型參數去識別時,會存在藏文字符和非藏文字符組合當成一個音節,這樣訓練集中不存在這樣的音節而導致錯誤;二是訓練集中本身就存在藏文字符和非藏文字符的組合當成一個音節的現象而導致分詞錯誤。
針對該類錯誤我們定義如下規則:設S表示待切分的藏文句子,S={w0,w1......wi......,wn},(0<i<n),wi表示每一個音節。U={D,E,C,P},用U表示非藏文字符集合,用uj(0<j<n)表示非藏文字符集合U中的元素,其中D是時間和數字的集合,例如,“123”,“3.14”,“30%”等,E、C分別表示英文和中文字符,P表示標點符號,包括中英文標點符號、半全角標點符號。
規則1
如果wi∈U(i≠0);則將wi單獨從集合S中切分出來。
在未分詞的語料按照每個音節分開之前先通過該規則將所有非藏文字符單獨切分出來,這樣避免了交給CRFs模型參數去識別時,藏文字符和非藏文字符的組合當成一個音節而導致的錯誤。在得到CRFs分詞的結果之后,再通過該規則處理一次,這樣避免了訓練集中本身就存在藏文字符和非藏文字符的組合當成一個音節的現象而導致分詞錯誤。
3.3.2 黏著詞的識別錯誤修正
CRF切分結果:

正確的切分結果:

導致該類錯誤的原因是對藏文中黏著詞的識別不準確,針對這類錯誤我們首次引入了詞頻的信息。首先我們統計了在大規模的訓練語料中出現的所有包含黏著詞的音節的出現頻次,在我們的訓練集中總共出現了101 265條包含黏著詞的音節,去重后僅有305條不重復的包含黏著詞的音節,從中不難發現這些包含黏著詞的音節的重復率很高。我們分別計算了每個包含黏著詞的音節在訓練語料中所占的比例fc。fc的計算方法如式(6)所示。

我們以前十個出現次數最多的包含黏著詞的音節作為例子,如表3所示。
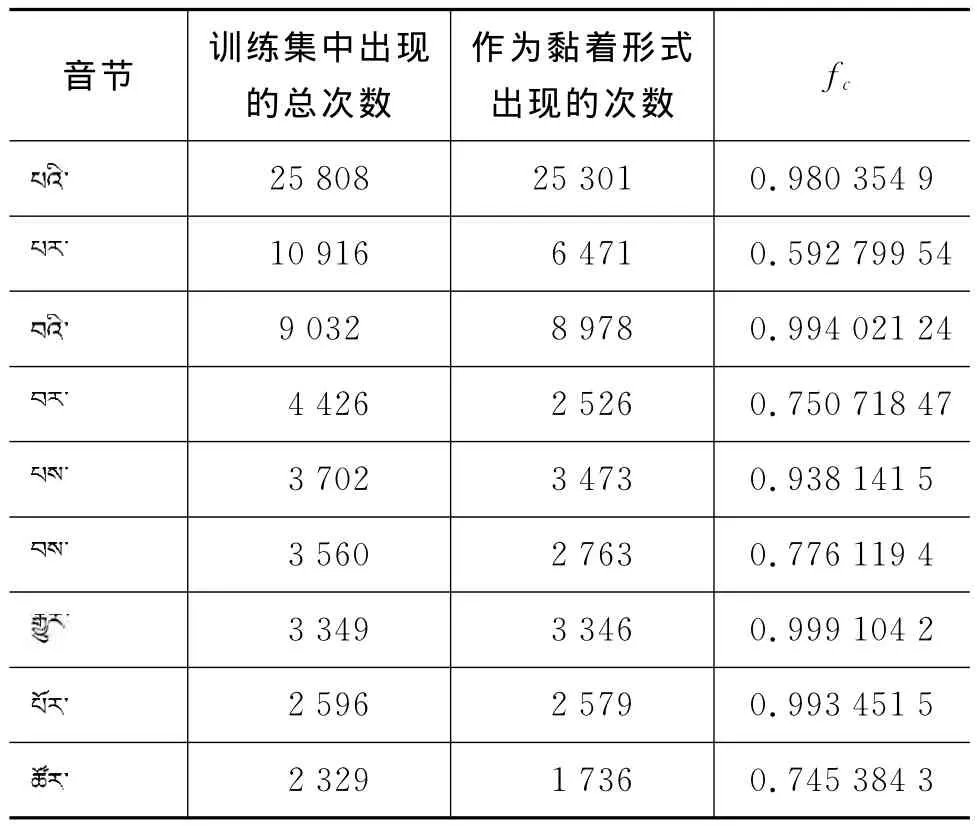
表3 前十個出現次數最多的包含黏著詞的音節
我們對不同的fc值進行了實驗,圖2給出了fc對黏著詞判斷的影響:
從該表我們不難發現,這幾個音節在文本中作為黏著形式的詞的概率fc都很高。我們定義以下規則:將所有符合fc>f的音節加入集合N,N表示常用包含黏著詞的音節集合,nj表示集合N中包含的元素。其中f是我們自定義的閾值,從實驗數據可以得出f取值為55時效果最佳。
規則2
如果wi∈N(i≠0)且fc>f,則將wi判斷為帶有黏著形式的藏文音節。
3.3.3 停用詞的分詞錯誤修正
由于目前還沒有學界公認的藏文停用詞表,本文所指的停用詞包括如下內容。無歧義的藏文格助詞:例如等;

圖2 fc取值對黏著詞識別的效果圖
CRFs切分結果:

正確的切分結果:

該類錯誤是本該分開的格助詞在CRF識別結果中沒能分開。例如等。針對這類錯誤我們整理了藏語常用停用詞表。對于這類詞我們定義如下規則:設SW(stop words)表示停用詞集合。
規則3
如果:wi∈SW(i≠0),則將wi單獨從集合S中分出來。
3.3.4 未登錄詞識別錯誤修正
CRF切分結果:

正確的切分結果:

導致該類錯誤的原因是因為訓練集中不包含這個命名實體,從而CRFs未能識別出來。針對該類錯誤,我們整理了藏語常用人名、地名、組織機構名實體庫。對于這類詞我們定義如下規則,設T表示常用實體庫,tj表示集合T中的元素。
規則4
如果wi∈T(i≠0),則將wi單獨從集合S中分出來。
4 實驗結果
4.1 實驗數據
雖然對藏文信息處理已進行了多年的研究,但至今沒有公開的語料庫,因此本實驗的訓練集語料數據來源是西藏新聞網、人民網藏語頻道、青海藏語廣播網和新華網等主流媒體的藏語網站。所涉及的領域范圍包括新聞、娛樂、詩歌、文化、宗教不同類別的文章。具體的實驗數據如表4所示。
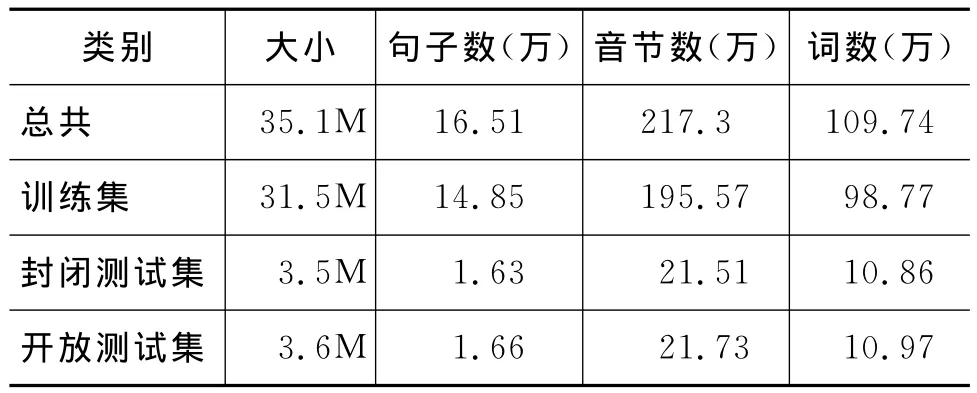
表4 實驗數據詳細情況
4.2 實驗平臺
本文實驗都是在PC機環境下完成的,操作系統是Win7,使用條件隨機場模型進行訓練和測試,采用的是CRF++0.58。CRF++是一個實現了條件隨機場模型的工具,被大量應用于序列數據的標注和分割,具有良好的通用性,現在已經被廣泛運用于自然語言處理各個領域的研究和應用中,例如,分詞、詞性標注、命名實體識別、信息抽取等。
4.3 評測指標
我們用R、P、F分別表示召回率、正確率、F值。則R、P、F的計算方法公式如式(7)~(9)所示。

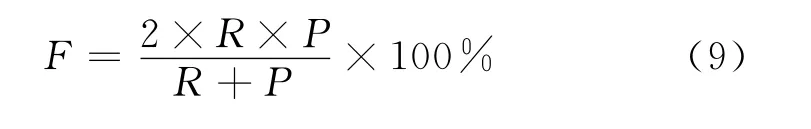
4.4 藏語分詞結果
我們分別對僅使用CRF模型的分詞結果和使用規則校正后的分詞結果做了比較,如表5所示。
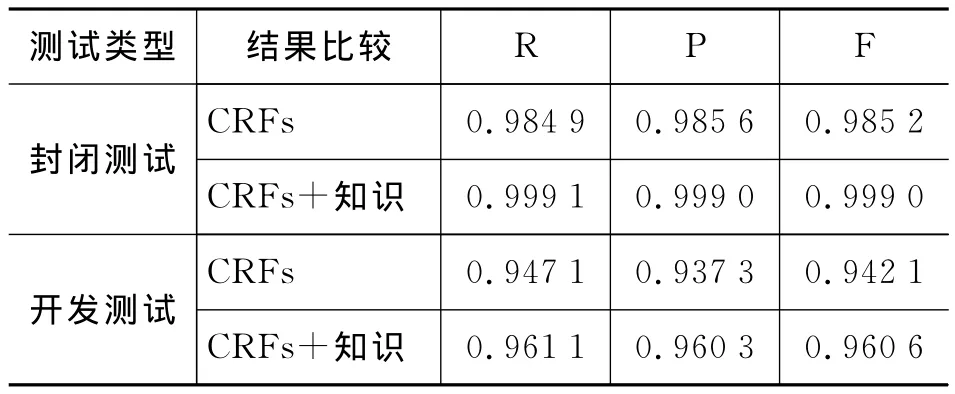
表5 CRFs和規則相結合分詞結果
從上表我們可以看出加入本文總結的規則對基于條件隨機場模型的藏文分詞進行校正之后,比起僅使用CRF模型在分詞的R、P、F都有了明顯提高。主要是對非藏文字符的切分和黏著詞的再識別以及停用詞的再切分都對分詞的準確率的提升起到了很好的作用。
在開放測試中,采用本文的CRF和規則相結合的方法,分詞的R、P、F等指標值均達到了96%,說明基于本文的藏語分詞方法可以取得較好的分詞效果。在封閉測試中,分詞的各項指標均超過了99%,雖然是在實驗條件下的分詞結果,但是可以說明利用條件隨機場和規則相結合的分詞方法對于藏語分詞有理想的預期效果。
經過與其他學者的藏文分詞研究結果比較可以看出,本文提出的條件隨機場和規則相結合的分詞方法的分詞結果在各項指標上均有提升。
4.5 總結
本文在前人研究的基礎上根據藏語的特點實現了一種基于CRF和規則相結合的藏語分詞系統,通過基于字標注的CRF模型分詞方法和依照藏文獨特的語法特點,使用規則對CRF分詞結果進行校正,取得了很好的分詞效果。分析分詞錯誤的結果集發現,大部分錯誤都集中在未登錄詞的識別錯誤上,接下來,我們希望通過加入更多的藏語語法規則來減少分詞系統中對于人名、地名、機構名等命名實體的識別錯誤。
[1] 孫茂松,鄒嘉彥.漢語自動分詞研究評述[J].當代語言學,2001,3(1):22-32.
[2] 羅秉芬,江荻.藏文計算機自動分詞的基本規則[C]//中國少數民族語言文字現代化文集.北京:民族出版社,1999
[3] 扎西次仁.一個人機互助的藏語分詞和詞登錄系統的設計[C]//中國少數民族語言文字現代化文集.北京:民族出版社,1999.
[4] 陳玉忠,李保利,俞士汶,等.基于格助詞和接續特征的藏文自動分詞方案[J].語言文字應用,2003,(01):75-82.
[5] 陳玉忠,李保利,俞士汶.藏文自動分詞系統的設計與實現[J].中文信息學報,2003,17(03):15-20.
[6] 才智杰.班智達藏文自動分詞系統的設計與實現[J].青海師范大學民族師范學院學報,2010,21(02):75-77.
[7] Norbu S,Choejey P,Dendup T,et al.Dzongkha word segmentation[C]//Proceedings of the 8th Workshop on Asian Language Resources.2010:95-102.
[8] 史曉東,盧亞軍.央金藏文分詞系統[J].中文信息學報,2011,25(4):54-56.
[9] Liu Huidan,Nuo Minghua,Ma Longlong,et al.Tibetan Word Segmentation as Syllable Tagging Using Conditional Random Field[C]//Proceedings of the PACLIC.2011:168-177.
[10] 洪銘材,張闊,唐杰等.基于條件隨機場(CRFs)的中文詞性標注方法[J].計算機科學,2006,33(10):146-151.
[11] 魏歐,孫玉芳.基于非監督訓練的漢語詞性標注的實驗與分析[J].計算機研究與發展,2000,37(4):477-482.
[12] 李亞超,加羊吉,宗成慶等.基于條件隨機場的藏語自動分詞方法研究與實現[J].中文信息學報,2013,27(04):52-58.
[13] 康才畯.藏語分詞與詞性標注研究[D].上海師范大學博士學位論文.2014.5.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技信息(2016年14期)2016-07-31 21:16:32
