基于云計算環(huán)境下Apriori算法的設(shè)備故障診斷技術(shù)研究*
2014-07-18 11:56:18江雄心涂海寧
組合機床與自動化加工技術(shù) 2014年4期
邱 昕,甘 超,江雄心,涂海寧,顧 嘉
(南昌大學(xué) 機電工程學(xué)院,南昌 330031)
基于云計算環(huán)境下Apriori算法的設(shè)備故障診斷技術(shù)研究*
邱 昕,甘 超,江雄心,涂海寧,顧 嘉
(南昌大學(xué) 機電工程學(xué)院,南昌 330031)
故障診斷是保障設(shè)備安全運行的重要手段。文章采用結(jié)構(gòu)化存儲的故障數(shù)據(jù)模型,考慮到故障數(shù)據(jù)的特點,以及傳統(tǒng)Apriori算法的瓶頸,提出了一種改進的Apriori算法,應(yīng)用于MapReduce計算框架,減少了算法的掃描次數(shù),提高了算法的執(zhí)行效率。在云計算環(huán)境下對故障數(shù)據(jù)進行關(guān)聯(lián)規(guī)則挖掘,找出發(fā)生故障時各設(shè)備檢測狀態(tài)的關(guān)聯(lián)關(guān)系,為設(shè)備維修和管理提供可靠依據(jù)。最后給出了該方法的可行性實例驗證。
云計算;故障診斷;數(shù)據(jù)挖掘;Apriori算法
0 引言
故障數(shù)據(jù)挖掘是故障診斷技術(shù)的重要研究內(nèi)容之一。關(guān)聯(lián)規(guī)則是數(shù)據(jù)挖掘的研究重點,Apriori算法是最經(jīng)典的關(guān)聯(lián)規(guī)則算法[1]。近年來,國內(nèi)外對Apriori算法的改進和優(yōu)化取得了很大的成就。高宏賓等[2]提出了樹形結(jié)構(gòu)來存儲事務(wù)項集數(shù)據(jù),有效提高數(shù)據(jù)量巨大時算法的性能;苗苗苗等[3]利用了一種基于數(shù)組和矩陣壓縮的Apriori改進算法,按照相關(guān)性質(zhì)對事務(wù)矩陣進行壓縮,以減少算法的運算量;BRIN等[4]采用動態(tài)模式計數(shù)法DIC,通過分段增加候選頻繁模式集,簡化了支持率的計算;劉興濤等[5]利用二維數(shù)組標志位進行事務(wù)壓縮和利用項集有序性進行項目壓縮,優(yōu)化Apriori算法的運行效率。
盡管Apriori算法具有很多改進方法,但用于設(shè)備故障診斷在算法效率和可行性上還不是很理想。基于故障數(shù)據(jù)的特點,為了進一步提高算法的效率,本文提出了一種云計算環(huán)境下Apriori算法的設(shè)備故障診斷方法。云計算(Cloud Computing)是一種新興的計算模型,是分布式計算、并行計算和網(wǎng)格計算的發(fā)展[6]。處理海量數(shù)據(jù)和并行計算是云計算技術(shù)的優(yōu)勢所在。
1 故障數(shù)據(jù)模型
1.1 故障數(shù)據(jù)的特點
隨著檢測技術(shù)的發(fā)展以及企業(yè)對設(shè)備診斷的重視,制造企業(yè)能收集到大量的原始故障數(shù)據(jù)。這些故障數(shù)據(jù)有以下特點[7-8]:
(1)大量性。隨著設(shè)備使用時間的推移,會產(chǎn)生大量的故障數(shù)據(jù);
(2)動態(tài)性。近年來,多功能型設(shè)備不斷增多,故障機理具有多樣性和突發(fā)性的特點。由于設(shè)備處于不停的運行狀態(tài),采集的故障數(shù)據(jù)具有大量的動態(tài)信息;
(3)冗余性。設(shè)備發(fā)生故障時需要記錄大量的狀態(tài)參數(shù)、故障信息、設(shè)備信息等,這些信息具有一定的冗余性;
(4)噪音大。故障數(shù)據(jù)具有比較大的噪音。
1.2 模型的數(shù)據(jù)結(jié)構(gòu)
在大量的原始故障數(shù)據(jù)中,可以通過每次維修行為的維修單號來識別,其中一次維修行為可能存在多個狀態(tài)檢測信息。為了便于采用關(guān)聯(lián)規(guī)則挖掘思想,將原始故障數(shù)據(jù)中所有的記錄按照維修單號進行合并,得到所需的數(shù)據(jù)模型。
(1)由于涉及維修單、備件、故障代碼、維修人員、設(shè)備狀態(tài)等信息,元素比較多,數(shù)據(jù)量很大,為了便于管理和維護,采用結(jié)構(gòu)化存儲方式,如圖1所示;
(2)每條記錄由唯一的維修單號標識,某條記錄中的狀態(tài)信息都與某次維修行為相關(guān),不存在相同維修單號的兩條記錄;
(3)每條記錄用
2 MapReduce計算框架
MapReduce[9-10]是Google實驗室提出的為多臺計算機并行處理大量數(shù)據(jù)而設(shè)計的并行計算框架。它通過“Map(映射)”和“Reduce(化簡)”這兩個函數(shù)處理運行于大規(guī)模集群上的并行計算。Map階段的功能是將輸入的子數(shù)據(jù)集解析出一個鍵值對
如圖2是MapReduce計算框架的執(zhí)行過程。
3 算法描述
3.1 Apriori算法改進描述
Apriori算法使用的是一種逐層搜索的迭代算法,通過對頻繁K項集的剪枝、連接操作,搜索得到頻繁(K+1)項集。
在設(shè)備故障診斷中,隨著設(shè)備使用壽命的推移和監(jiān)控時間的積累,數(shù)據(jù)庫存儲了海量的故障數(shù)據(jù)和狀態(tài)數(shù)據(jù)。傳統(tǒng)的Apriori算法有一下幾個劣勢[11-12]:
1)重復(fù)掃描數(shù)據(jù)庫,數(shù)據(jù)庫開銷大,診斷速度緩慢;
2)迭代次數(shù)多,算法適應(yīng)性差;
3)需要高配置的計算機,加劇企業(yè)在故障診斷方面的經(jīng)濟開銷。
為了提高設(shè)備故障診斷中Apriori算法的效率和伸縮性,提高算法的運行速度和挖掘效率,本文在云計算環(huán)境下對Apriori算法加以改進,由于云計算可支持算法的并行執(zhí)行,具有分布性的特點,為Apriori算法的改進提供了可能。算法的思路如下:
1)將故障數(shù)據(jù)庫分為數(shù)據(jù)量相當?shù)腗個數(shù)據(jù)子集,發(fā)送到M個工作站點,掃描每個工作站點的數(shù)據(jù)子集,分別產(chǎn)生一個局部的候選K項集,每個候選項的支持數(shù)設(shè)為1;
2)通過一定的函數(shù)和方法將M個工作站點中相同的候選項和支持數(shù)發(fā)送到R個站點;
3)R站點累加相同項的支持數(shù),并與最小支持數(shù)比較,得到局部頻繁K項集;
4)合并R個站點的輸出,得到最終的頻繁K項集。
3.2 改進的Apriori算法用于MapReduce計算框架
采用MapReduce計算框架,對Apriori算法加以改進包括五個階段,分別是Input階段、Map階段、Shuffle & Sort階段、Reduce階段、Output階段。具體步驟如下:
(1)Input階段:MapReduce庫將故障數(shù)據(jù)庫水平劃分,分為數(shù)據(jù)量相當?shù)腗個數(shù)據(jù)子集。并將數(shù)據(jù)子集以
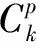
(3) Shuffle & Sort階段:由于故障數(shù)據(jù)量巨大,Map函數(shù)產(chǎn)生的中間
然后利用分區(qū)函數(shù)Separater將Combiner函數(shù)的輸出結(jié)果分成R個不同的分區(qū),將相同項的中間結(jié)果存儲在同一個分區(qū)上,并分配到指定的Reduce函數(shù)。Separater函數(shù)的蘊含式如下:
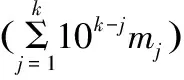
其中mj為k項集對應(yīng)的項在故障數(shù)據(jù)庫中的序數(shù)。
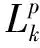
(4) Output階段:合并每個工作站點的局部頻繁K項集,得到最終頻繁K項集Lk..接著找頻繁K+1項集。
改進的Apriori算法用于MapReduce計算框架的偽代碼如下:
輸入:故障數(shù)據(jù)庫D,最小支持數(shù)minSupport,工作站點數(shù)M,工作站點數(shù)R;
輸出:頻繁K項集Lk..
1: 劃分故障數(shù)據(jù)庫為M個數(shù)據(jù)子集;
2: Convert to
3: Map (Tid , List(value)); //Tid為故障數(shù)據(jù)庫中的維修單號,List(value)為維修單對應(yīng)的設(shè)備狀態(tài)信息;
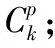
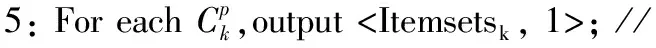
6: Combiner< Itemsetsk, list(1)>; // Itemsetsk為K項集,list(1)為1列表;
7: int count = 0;
8: For each item in list(1) // 循環(huán)每個相同項;
9:count +=1;
10: Output (Itemsetsk, count); // count為該項的支持總數(shù);
11: 利用分區(qū)函數(shù)Separater將Combiner函數(shù)的輸出結(jié)果分成R個不同的分區(qū), 并分配到指定的Reduce函數(shù);
12: Reduce(Itemsetsk, List(Count)) // Itemsetsk為K項集,List(Count)為支持數(shù)列表;
13: int support = 0;
14: for each Count in list// 循環(huán)每個相同項;
15: support += Count;
16: Output (Itemsetsk, support);
17: support與最小支持數(shù)minSupport比較,合并比較之后每個Reduce函數(shù)的輸出,得到頻繁K項集Lk..
改進的Apriori算法結(jié)合MapReduce計算框架主要有兩個優(yōu)勢:①減少故障數(shù)據(jù)庫的掃描次數(shù);②查找頻繁項集K項集和查找頻繁K+1項集是完全獨立的,可以并行計算,提高了算法的執(zhí)行效率。
4 實例驗證
表1為某汽車企業(yè)故障數(shù)據(jù),由于數(shù)據(jù)量巨大,為了便于表述,本文只提取了部分故障數(shù)據(jù)。信號(Itemset)表示機械設(shè)備發(fā)生故障時可供檢測的信號。共檢測了5種信號,分別為轉(zhuǎn)速信號、轉(zhuǎn)矩信號、壓力信號、溫度信號、振幅信號,這里分別用A、B、C、D、E表示。

表1 某汽車企業(yè)部分故障數(shù)據(jù)
假設(shè)最小支持數(shù)minSupport= 3,工作站點數(shù)M= 2,工作站點數(shù)R= 3。本文以計算頻繁2項集為例。
把故障數(shù)據(jù)水平劃分,分成兩個數(shù)據(jù)子集D1和D2:
D1 = { R107-20071115-1 , R107-20071015-2 , R107-20071116-2};
D2 = { R107-20071121-3 , R107-20051024-3 , R107-20051210-1};
將數(shù)據(jù)子集D1和D2發(fā)送給兩個Map工作站點,并將數(shù)據(jù)子集以
Map工作站點0:
< R107-20071115-1,{A,B,D}> , < R107-20071015-2 , {B,C,D}> , < R107-20071116-2,{B,C}>;
Map工作站點1:
< R107-20071121-3,{A,B,D,E}> , < R107-20051024-3,{A,B,C,D}> , < R107-20051210-1 , {B,E}>;
執(zhí)行Map(key , value)函數(shù),每個候選項的支持數(shù)計為1,得到局部候選2項集:
Map工作站點0:
Map(R107-20071115-1,{A,B,D})→<{A,B},1>,<{A,D},1>,<{B,D},1>;
Map(R107-20071015-2,{B,C,D})→<{B,C},1>,<{B,D},1>,<{C,D},1>;
Map(R107-20071116-2,{B,C})→<{B,C},1>;
Map工作站點1:
Map(R107-20071121-3,{A,B,D,E})→<{A,B},1>,<{A,D},1>,<{A,E},1>,<{D,E},1>,<{B,D},1>,<{B,E},1>;
Map(R107-20051024-3,{A,B,C,D})→<{A,B},1>,<{A,C},1>,<{A,D},1>,<{B,C},1>,<{B,D},1>,<{C,D},1>;
Map(R107-20051210-1,{B,E})→<{B,E},1>;
執(zhí)行Combiner(Itemsetsk,list(1))函數(shù),合并Map函數(shù)相同項的輸出:
Map工作站點0:
Combiner({A,B},list(1))→<{A,B},1>;Combiner({A,D},list(1))→<{A,D},1>;Combiner({B,D},list(1,1))→<{B,D},2>;Combiner({B,C},list(1,1))→<{B,C},2>;Combiner({C,D},list(1))→<{C,D},1>;
Map工作站點1:
Combiner({A,B},list(1,1))→<{A,B},2>;Combiner({A,D},list(1,1))→<{A,D},2>;Combiner({A,E},list(1))→<{A,E},1>;Combiner({D,E},list(1))→<{D,E},1>;Combiner({B,D},list(1,1))→<{B,D},2>;Combiner({B,E},list(1,1))→<{B,E},2>;Combiner({A,C},list(1))→<{B,D},1>;Combiner({B,C},list(1))→<{B,C},1>;Combiner({C,D},list(1))→<{C,D},1>;
執(zhí)行分區(qū)函數(shù)Separater函數(shù),將Combiner函數(shù)的輸出結(jié)果分成3個不同的分區(qū)(其中A、B、C、D、E的序數(shù)分別為1,2,3,4,5):
Separater({A,B})=(1+10*2)mode3=0;同理可得:Separater({A,D})=2;Separater({A,E})=0;Separater({D,E})=0;Separater({B,D})=0;Separater({B,E})=1;Separater({A,C})=1;Separater({B,C})=2;Separater({C,D})=1;
所以,{A,B},{A,E},{D,E},{B,D}分配到第0個Reduce工作站點,{A,C},{C,D},{B,E}分配到第1個工作站點,{A,D},{B,C}分配到第2個工作站點。
執(zhí)行Reduce函數(shù),累加其接收的候選2項集的支持數(shù):
Reduce工作站點0:
Reduce({A,B},list(1,2))→<{A,B},3>;Reduce({A,E},list(1))→<{A,E},1>;Reduce({D,E},list(1))→<{D,E},1>;Reduce({B,D},list(2,2))→<{B,D},4>;
Reduce工作站點1:
Reduce({B,E},list(2))→<{B,E},2>;Reduce({A,C},list(1))→<{A,C},1>;Reduce({C,D},list(1,1))→<{C,D},2>;
Reduce工作站點2:
Reduce({A,D},list(1,2))→<{A,D},3>;Reduce({B,C},list(2,1))→<{B,C},3>;
與最小支持數(shù)minSupport=3相比較,得到局部頻繁2項集:
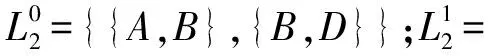
合并每個工作站點的局部頻繁2項集,得到頻繁2項集:
同理可以得到,頻繁3項集L3= {{A,B,D}};
由此可以分析出設(shè)備發(fā)生故障時,設(shè)備狀態(tài)信息的關(guān)聯(lián)關(guān)系。為設(shè)備維修和故障診斷提供決策支持。
5 總結(jié)
故障診斷是提高設(shè)備可靠性和穩(wěn)定性的重要手段。本文提出了基于云計算環(huán)境下Apriori算法的設(shè)備故障診斷方法。采用結(jié)構(gòu)化存儲的故障數(shù)據(jù)模型,通過對Apriori算法的改進,結(jié)合MapReduce計算框架,采用并行計算求出頻繁項集,提高了傳統(tǒng)Apriori算法的計算效率,找出設(shè)備發(fā)生故障時設(shè)備檢測狀態(tài)信息的關(guān)聯(lián)關(guān)系,為維修決策和設(shè)備管理提供可靠依據(jù),并預(yù)測設(shè)備的運行趨勢,提高設(shè)備的使用效率和管理水平。
[1] Agrawal R, Imielinski T, Swami A. Mining association rules between sets of items in large databases[A]. Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, May 26 - 28 1993[C]. Washington, DC, United states: Publ by ACM, 1993:207-216.
[2] 高宏賓, 潘谷, 黃義明. 基于頻繁項集特性的Apriori算法的改進[J]. 計算機工程與設(shè)計, 2007,(10): 2273-2275,2378 .
[3] 苗苗苗, 王玉英. 基于矩陣壓縮的Apriori算法改進的研究[J]. 計算機工程與應(yīng)用, 2013(1): 159-162.
[4] Brin S, Motwani R, Ullman JD, 等. Dynamic itemset counting and implication rules for market basket data[A]. Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, May 13, 1997-May 15, 1997[C]. Tucson, AZ, USA: ACM, 1997:255-264.
[5] 劉興濤, 石冰, 解英文. 挖掘關(guān)聯(lián)規(guī)則中Apriori算法的一種改進[J]. 山東大學(xué)學(xué)報(理學(xué)版), 2008,(11): 67-71.
[6] 陳全, 鄧倩妮. 云計算及其關(guān)鍵技術(shù)[J]. 計算機應(yīng)用, 2009,29(9): 2562-2567.
[7] 褚建立, 陳步英. 基于數(shù)據(jù)挖掘的機械設(shè)備故障診斷的研究[J]. 微計算機信息, 2007(19): 208-209,171
[8] 劉繁茂. 面向故障過程的多設(shè)設(shè)可靠性分析與維修決策[D]:武漢: 華中科技大學(xué), 2011.
[9] Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008,51(1): 107-113 .
[10] 陳康, 鄭緯民. 云計算:系統(tǒng)實例與研究現(xiàn)狀[J]. 軟件學(xué)報, 2009,20(5): 1337-1348.
[11] 崔貫勛, 李梁, 王柯柯, 等. 關(guān)聯(lián)規(guī)則挖掘中Apriori算法的研究與改進[J]. 計算機應(yīng)用, 2010,30(11): 2952-2955.
[12] 朱其祥, 徐勇, 張林. 基于改進Apriori算法的關(guān)聯(lián)規(guī)則挖掘研究[J]. 計算機技術(shù)與發(fā)展, 2006(7): 102-104.
(編輯 趙蓉)
Equipment Fault Diagnosis Technology Based on Apriori Algorithm in Cloud Computing Environment
QIU Xin, GAN Chao, JIANG Xiong-xin, TU Hai-ning, GU Jia
(School of Mechanical Engineering,Nanchang University,Nanchang 330031,China)
Equipment fault diagnosis is an important means to ensure safe operation of equipment. Structured storage of the fault data model is used in this paper. And an improved Apriori algorithm is proposed according to the characteristics of fault data and the deficiency of Apriori algorithm, combining the MapReduce programming model, which reduces the number of scanning and improves the efficiency of the algorithm. The correlation is exhumed among equipment inspection status by mining the association rules of fault data in cloud computing environment, which provides reliable support for equipment maintenance and management. At last an example is given to prove the feasibility.
cloud computing; fault diagnosis; data mining; apriori algorithm
1001-2265(2014)04-0045-04
10.13462/j.cnki.mmtamt.2014.04.012
2013-08-06;
2013-08-28
國家自然科學(xué)基金(50905083)
邱昕(1989—),女,江西贛州人,南昌大學(xué)碩士研究生,主要從事制造過程與管理方面的研究,(E-mail)crazy28@qq.com。
TH166;TG65
A
猜你喜歡
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
財經(jīng)(2017年2期)2017-03-10 14:35:35
汽車維護與修理(2016年10期)2016-07-10 08:17:41
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
重慶工商大學(xué)學(xué)報(自然科學(xué)版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
