海量遙感數(shù)據(jù)的GPU通用加速計(jì)算技術(shù)
2014-03-27 09:03:14周松濤石婷婷
地理空間信息 2014年3期
洪 亮,周松濤,羅 伊,石婷婷,胡 飛
(1.湖北省航測遙感院,湖北 武漢 430074;2. 武漢大學(xué) 國際軟件學(xué)院,湖北 武漢 430070;3. 湖北省基礎(chǔ)地理信息中心,湖北 武漢 430074;4.安陸市國土資源局,湖北 安陸 432600)
遙感數(shù)據(jù)多為圖像數(shù)據(jù),對它們的處理涉及大量特征數(shù)據(jù)的計(jì)算、統(tǒng)計(jì)等。對這些數(shù)據(jù)的運(yùn)算往往是基于分塊的算法,即將柵格數(shù)據(jù)的局部按某種經(jīng)緯格網(wǎng)裁剪出來進(jìn)行計(jì)算,然后將結(jié)果寫回?cái)?shù)據(jù)庫。在單一工作站上,這一運(yùn)算往往是一個(gè)串行的過程,因此效率比較低。目前的高性能計(jì)算主要是采用并行計(jì)算技術(shù)來實(shí)現(xiàn)[1]。在硬件體系結(jié)構(gòu)上,并行計(jì)算機(jī)主要分為3種形式:多處理機(jī)系統(tǒng)、多計(jì)算機(jī)系統(tǒng)和集群計(jì)算技術(shù)。但考慮到成本、安全及使用頻度、運(yùn)算效率等問題,基于網(wǎng)絡(luò)的多計(jì)算機(jī)系統(tǒng)和集群運(yùn)算并不合適,而簡單的多處理機(jī)系統(tǒng)運(yùn)算能力有限。基于GPU的加速計(jì)算技術(shù)為海量遙感數(shù)據(jù)處理效率的提高帶來了新的手段。GPU最初是針對圖形渲染,但在其上的通用計(jì)算技術(shù)顯然非常適合類似于圖像這類數(shù)據(jù)的計(jì)算與處理。在面向GPU的通用計(jì)算技術(shù)中,CUDA技術(shù)是發(fā)展最早、目前相對完善、普及的一種技術(shù)。
1 CUDA技術(shù)簡介
與早期的圖形處理器不同,現(xiàn)代的圖形處理器往往具有可編程單元,用于處理龐大而復(fù)雜的三維圖形數(shù)據(jù)。通常,一個(gè)GPU內(nèi)部有兩個(gè)可編程單元,即頂點(diǎn)著色器和像素著色器,這兩個(gè)單元包含有幾十個(gè)甚至幾百個(gè)流處理器,可并行處理圖形的頂點(diǎn)和像元數(shù)據(jù),有很強(qiáng)的浮點(diǎn)運(yùn)算能力。目前國際上兩大圖形處理器廠商——NVIDIA和AMD,都在自己的GPU基礎(chǔ)上,構(gòu)建了一套通用數(shù)學(xué)運(yùn)算的機(jī)制,即NVIDIA的CUDA技術(shù)和AMD的STREAM技術(shù),其中CUDA技術(shù)應(yīng)用比較成熟和廣泛[2]。
CUDA是一個(gè)通用的并行計(jì)算架構(gòu),將GPU強(qiáng)大的并行計(jì)算能力充分調(diào)動(dòng)起來,使之在解決復(fù)雜計(jì)算問題上發(fā)揮其先天優(yōu)勢。開發(fā)人員僅使用C語言,就能在基于CUDA架構(gòu)的GPU上編寫程序,在支持CUDA的處理器上以超高性能運(yùn)行。不僅如此,CUDA還是免費(fèi)的開源技術(shù),任何開發(fā)人員都能通過最新的NVIDIA GPU,在個(gè)人計(jì)算機(jī)上實(shí)現(xiàn)高性能計(jì)算,解決復(fù)雜的科學(xué)運(yùn)算問題。
與英特爾的X86架構(gòu)不同,CUDA基于GPU,但不拘于GPU,而是取長補(bǔ)短,將CPU的串行計(jì)算和GPU的并行計(jì)算融合,開啟“CPU+GPU協(xié)同計(jì)算”的全新時(shí)代,即“異構(gòu)計(jì)算”。“異構(gòu)計(jì)算”真正實(shí)現(xiàn)了系統(tǒng)整體計(jì)算能力的最大化利用:GPU和CPU協(xié)同工作,GPU處理大量的圖形和并行處理,CPU處理操作系統(tǒng)和指令的邏輯控制。兩者的協(xié)同比單純CPU運(yùn)算高出幾十倍甚至幾百倍、上千倍,使得PC和工作站具有超級計(jì)算的能力,使得個(gè)人超級計(jì)算機(jī)的普及成為可能。
目前,采用GPU進(jìn)行通用運(yùn)算越來越普及,一些常用軟件,如Photoshop、3DMax以及一些視頻處理軟件已大量使用該技術(shù)。從應(yīng)用的效果來看,均有幾倍或幾十倍的效率提升,前景非常廣闊。有鑒于此,在GPU基礎(chǔ)上,NVIDIA又進(jìn)一步開發(fā)了Tesla處理器。該處理器外觀跟顯卡非常相似,只是沒有顯示輸出接口。這種“顯卡”的主要作用就是“多塊并聯(lián)”,通過CUDA來進(jìn)行科學(xué)運(yùn)算。和傳統(tǒng)服務(wù)器/工作站相比,塔式Tesla主機(jī)也有CPU等常規(guī)硬件,只是內(nèi)部有多塊“顯卡”組多路SLI,如圖1所示。通過Tesla處理器構(gòu)建的個(gè)人高性能計(jì)算機(jī),利用多路顯卡的強(qiáng)大并行處理能力,使一些以往主要依靠CPU計(jì)算的領(lǐng)域大大提速,甚至使部分依靠CPU無法完成的計(jì)算成為可能。

圖1 帶有Tesla處理器的個(gè)人超級計(jì)算機(jī)

圖2 CUDA中運(yùn)算任務(wù)的邏輯劃分
2 GPU環(huán)境下柵格數(shù)據(jù)并行計(jì)算模型
GPU作為一種圖形運(yùn)算單元,具有對紋理圖像的各種優(yōu)化運(yùn)算功能,支持柵格數(shù)據(jù)的并行運(yùn)算。
2.1 任務(wù)調(diào)度與劃分
在CUDA運(yùn)算中,每個(gè)GPU的運(yùn)算單元被映射成一個(gè)網(wǎng)格(Grid),每個(gè)網(wǎng)格單元在邏輯上被分為多個(gè)Block,每個(gè)Block被分為若干Thread,Thread作為最新運(yùn)算邏輯單元存在(如圖2)。在與硬件的對應(yīng)關(guān)系上可以近似地認(rèn)為,每個(gè)網(wǎng)格對應(yīng)一個(gè)GPU(或一塊Tesla處理器),一個(gè)Block對應(yīng)一個(gè)SM(streaming multiprocessor),而一個(gè)Thread則對應(yīng)硬件上的一個(gè)運(yùn)算單元,即一個(gè)SP(streaming processor)。之所以說這種對應(yīng)關(guān)系是近似的,是因?yàn)闉榱朔乐乖贗/O等過程中運(yùn)算單元閑置,GPU會(huì)對不同的任務(wù)分組進(jìn)行優(yōu)化處理和調(diào)度。例如在一個(gè)Block中,32個(gè)Thread會(huì)被分為一組并執(zhí)行,稱為一個(gè)Wrap。如果發(fā)生任務(wù)閑置的情況,則換另外一組,從而導(dǎo)致Thread和SP之間并沒有嚴(yán)格的一一對應(yīng)關(guān)系。
可參照這一邏輯模型對柵格數(shù)據(jù)分塊進(jìn)行處理。可參照柵格數(shù)據(jù)的邏輯模型(一個(gè)2維矩陣),將柵格數(shù)據(jù)作2維的邏輯任務(wù)劃分,與圖2中所示模型一致。實(shí)際應(yīng)用中,柵格數(shù)據(jù)的塊狀劃分可根據(jù)應(yīng)用情況進(jìn)行處理。例如,一些空間數(shù)據(jù)庫在對柵格數(shù)據(jù)存儲過程中進(jìn)行了分塊索引,那么檢索到客戶端的柵格數(shù)據(jù)也是自然分塊的。分析處理中,這個(gè)數(shù)據(jù)塊可根據(jù)其大小,映射到一個(gè)Grid單元或一個(gè)Block單元進(jìn)行計(jì)算,避免對柵格數(shù)據(jù)的重新規(guī)劃以及重新分塊。
在一個(gè)Block內(nèi)部,涉及到如何將一塊柵格數(shù)據(jù)分布到不同的Thread中執(zhí)行運(yùn)算的問題。實(shí)際操作中,這一部分的劃分不是按照矩陣的邏輯模型,而是按照條帶的方式,即將一個(gè)數(shù)據(jù)塊中的不同行放到不同的Thread中進(jìn)行處理。同一行數(shù)據(jù)以及相鄰行數(shù)據(jù)在存儲空間連續(xù),便于地址空間的管理,也便于運(yùn)算結(jié)果的寫回。
2.2 數(shù)據(jù)存儲模型
在CUDA中,與開發(fā)者密切相關(guān)的存儲器類型主要有兩種,即全局存儲(global memory)和共享存儲(shared memory),見圖3。全局存儲是在一個(gè)運(yùn)算設(shè)備上全局共享存儲區(qū)域,一般來講就是顯存的一部分,用戶與CUDA之間的數(shù)據(jù)傳輸可通過這部分存儲區(qū)間完成。圖3中,Host是用戶在CPU中執(zhí)行的代碼。共享內(nèi)存是在一個(gè)Block中共享存儲區(qū)域,其作用可看作是高速緩存,存取速度雖然很快,但大小受限,在目前的硬件水平上一般不超過16 K。在柵格數(shù)據(jù)的任務(wù)調(diào)度中,盡量將數(shù)據(jù)放到共享存儲區(qū)域進(jìn)行處理,這樣效率會(huì)較高。在CUDA模型中,將數(shù)據(jù)放到共享存儲區(qū)域的過程是一個(gè)需要用戶干預(yù)的過程。用戶在開發(fā)過程中,需要指定全局存儲中的數(shù)據(jù)如何組織到共享存儲中。CUDA的內(nèi)建函數(shù)也提供了一些指令,用于不同線程間共享存儲數(shù)據(jù)的同步。
采用CUDA技術(shù)進(jìn)行海量數(shù)據(jù)的并行運(yùn)算,其效率除了受并行線程數(shù)量影響以外,還受存儲器的訪問效率影響。GPU訪問顯存的效率要遠(yuǎn)遠(yuǎn)高于CPU訪問內(nèi)存的效率,主要是因?yàn)樗趲捄皖l率上都要高于CPU所在系統(tǒng)的總線。而在CUDA層面,對數(shù)據(jù)的訪問則可以考慮全局和共享存儲兩個(gè)層面。對于單個(gè)線程,在計(jì)算比較復(fù)雜、涉及的數(shù)據(jù)量大時(shí),可不使用共享存儲單元;而在運(yùn)算簡單、數(shù)據(jù)運(yùn)算局部性比較強(qiáng)時(shí),可先將一個(gè)Block中的線程需要訪問的數(shù)據(jù)組織到共享存儲單元中,然后再以共享存儲單元的訪問為基礎(chǔ)進(jìn)行計(jì)算。
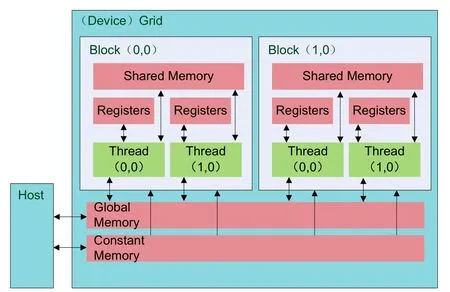
圖3 CUDA的存儲模型
2.3 海量遙感數(shù)據(jù)的分布式調(diào)度
上述存儲及調(diào)度模型是基于單機(jī)任務(wù)的,如果存在海量遙感數(shù)據(jù),則需要在單機(jī)模式基礎(chǔ)上,建立一個(gè)支持分布式或在單一節(jié)點(diǎn)上存在多處理器的分布式運(yùn)算模型[3,4]。
在一個(gè)基于GPU的運(yùn)算集群環(huán)境下,柵格數(shù)據(jù)處理任務(wù)劃分可參照圖4中的邏輯模型,將柵格數(shù)據(jù)作2維的邏輯任務(wù)劃分。柵格數(shù)據(jù)的塊狀劃分可根據(jù)應(yīng)用情況進(jìn)行處理。例如,一些空間數(shù)據(jù)庫在對柵格數(shù)據(jù)存儲過程中進(jìn)行了分塊索引,那么,檢索到客戶端的柵格數(shù)據(jù)也是自然分塊的。分析處理中,這個(gè)數(shù)據(jù)塊可根據(jù)其大小映射到一個(gè)GPU設(shè)備(即一個(gè)Grid)單元或一個(gè)線程塊(Block)單元中進(jìn)行計(jì)算,從而避免對柵格數(shù)據(jù)的重新規(guī)劃以及重新分塊處理[5]。
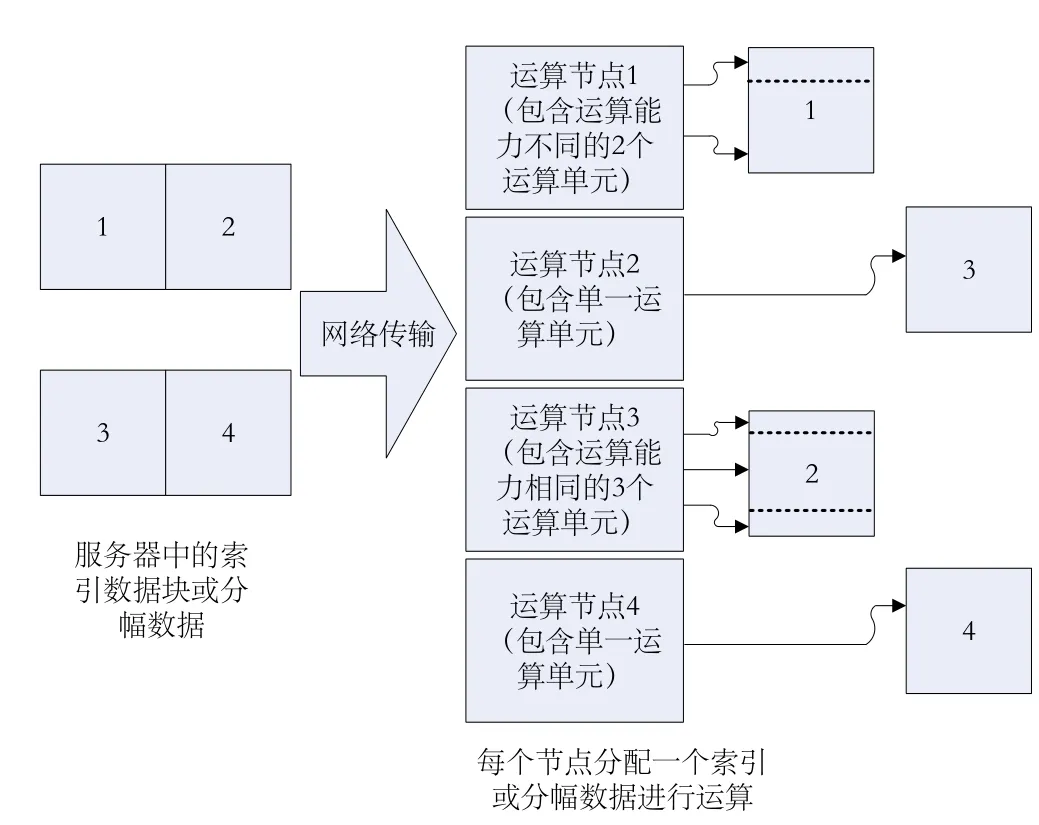
圖 4 海量柵格數(shù)據(jù)在分布式環(huán)境下任務(wù)處理的邏輯模型
圖4中,假設(shè)有4個(gè)運(yùn)算節(jié)點(diǎn)工作站對數(shù)據(jù)庫中的柵格數(shù)據(jù)進(jìn)行處理。為了避免重新對數(shù)據(jù)進(jìn)行任務(wù)劃分,可令每個(gè)節(jié)點(diǎn)計(jì)算機(jī)處理一塊數(shù)據(jù)。在獲取到數(shù)據(jù)后,節(jié)點(diǎn)計(jì)算機(jī)可根據(jù)其自身處理能力對數(shù)據(jù)進(jìn)行再次劃分。例如,運(yùn)算節(jié)點(diǎn)1中包含有運(yùn)算能力不同的兩個(gè)處理單元,則在任務(wù)劃分中,將待處理數(shù)據(jù)按運(yùn)算能力的大小分為兩個(gè)部分。實(shí)際處理中,這種劃分僅僅是一個(gè)偏移地址的處理,處理時(shí)間可以忽略不計(jì)。
3 柵格數(shù)據(jù)運(yùn)算效率的比較
為了客觀評價(jià)CUDA技術(shù)在柵格數(shù)據(jù)加速運(yùn)算過程中的效率,本文分別通過相關(guān)曲面、Sobel算子以及標(biāo)準(zhǔn)差計(jì)算來比較[6-8]。
3.1 相關(guān)曲面的計(jì)算
由于相關(guān)曲面模板大小為可變的,且其寬和高往往較一般卷積算子大,受共享存儲單元大小的限制,不便于放在其中運(yùn)算。因此,這部分的測試是基于全局存儲訪問進(jìn)行的。測試過程中,在不同尺寸的數(shù)據(jù)和匹配模板下分別用CPU和GPU進(jìn)行計(jì)算,并比較二者的效率,見表1。
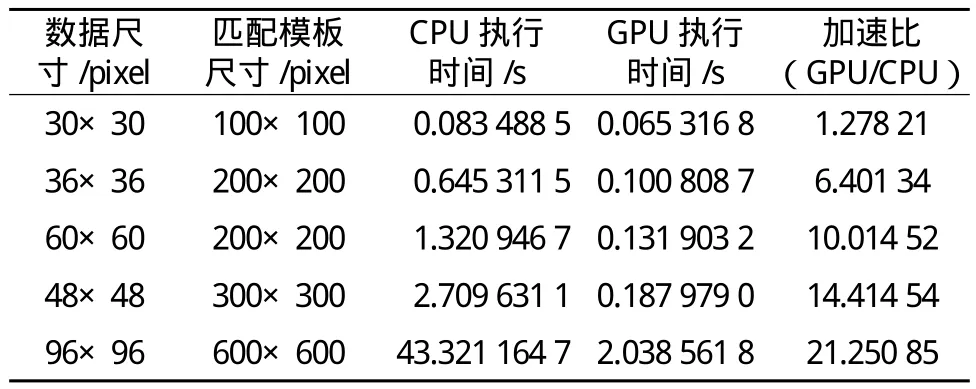
表1 GPU和CPU環(huán)境下相關(guān)曲面計(jì)算比較
從表中可以看出,在數(shù)據(jù)量比較小的情況下,GPU計(jì)算并無多大的優(yōu)勢。隨著數(shù)據(jù)量的加大,GPU相對于CPU計(jì)算的加速比逐漸變大。可見,在海量柵格數(shù)據(jù)的處理中,GPU通用計(jì)算的優(yōu)勢非常明顯。
3.2 Sobel算子的計(jì)算
這一測試的目的是檢測基于GPU的全局存儲和共享存儲進(jìn)行計(jì)算的差別,因此,Sobel算子的測試并沒有在CPU下進(jìn)行運(yùn)算測試。由于Sobel算子卷積的運(yùn)算量較小,運(yùn)算速度較快,為了使結(jié)果比較客觀,兩種卷積運(yùn)算各循環(huán)運(yùn)算100次,然后求平均值。
在GPU采用Geforce GT 420 M的條件下,計(jì)算Sobel算子全局存儲訪問運(yùn)算的平均時(shí)間為0.000 023 s,共享存儲訪問的平均時(shí)間為0.000 017 s,共享存儲訪問方式下的運(yùn)算效率要高于全局存儲。因此,對于柵格數(shù)據(jù)的相關(guān)算法,應(yīng)盡量尋求在共享存儲訪問模式下運(yùn)算,以充分發(fā)揮GPU的優(yōu)勢。
3.3 標(biāo)準(zhǔn)差的計(jì)算
為了反映未進(jìn)行任務(wù)劃分條件下CPU和GPU計(jì)算能力的差異,對一個(gè)數(shù)組進(jìn)行標(biāo)準(zhǔn)差統(tǒng)計(jì)。測試中,分別在CPU單線程、GPU單線程以及GPU多線程條件下進(jìn)行。其中,GPU單線程指的是未對任務(wù)進(jìn)行任何劃分,直接把整塊數(shù)據(jù)放到GPU中運(yùn)算,同一時(shí)刻只有GPU的一個(gè)運(yùn)算單元參與;GPU多線程則是將計(jì)算平均值以外的部分進(jìn)行并行計(jì)算。數(shù)組大小為5 000個(gè)浮點(diǎn)數(shù),計(jì)算結(jié)果見表2。

表2 標(biāo)準(zhǔn)差計(jì)算在不同計(jì)算條件下的時(shí)間比較
由此可見,如果不對任務(wù)進(jìn)行劃分,單純靠GPU本身對任務(wù)調(diào)度計(jì)算,其計(jì)算能力甚至遠(yuǎn)遠(yuǎn)落后于CPU。僅對其中一部分的計(jì)算適當(dāng)并行,GPU計(jì)算的效率則有明顯改觀。但是,標(biāo)準(zhǔn)差的計(jì)算是一個(gè)基于全局的運(yùn)算,整個(gè)算法在實(shí)現(xiàn)過程中只有部分可實(shí)現(xiàn)并行計(jì)算,因此,類似算法如果要提高效率,還需要在算法上進(jìn)行重構(gòu),不能僅僅依靠硬件性能。
另外,一次運(yùn)算的數(shù)據(jù)規(guī)模也是影響運(yùn)算效率的因素之一。GPU運(yùn)算不像CPU,首先需要將運(yùn)算數(shù)據(jù)傳輸?shù)紾PU存儲器(顯存),并進(jìn)行一些數(shù)據(jù)結(jié)構(gòu)的準(zhǔn)備,再啟動(dòng)內(nèi)核計(jì)算。這些必要工作同樣消耗運(yùn)行時(shí)間,而且與運(yùn)算規(guī)模無關(guān)。因此,在GPU中進(jìn)行數(shù)據(jù)處理,輸入規(guī)模越大,GPU中可并行的線程就越多,并行運(yùn)算優(yōu)勢就越明顯。圖5是CPU和GPU并行計(jì)算效率的比較,橫坐標(biāo)表示運(yùn)算規(guī)模,縱坐標(biāo)表示時(shí)間消耗,單位為s。可見,當(dāng)輸入數(shù)據(jù)量在131 072(即217)左右時(shí),CPU和GPU耗時(shí)相當(dāng);大于217時(shí),GPU表現(xiàn)出時(shí)間上的優(yōu)勢。
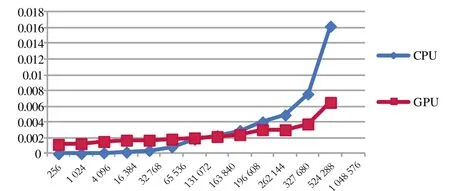
圖5 不同運(yùn)算規(guī)模下標(biāo)準(zhǔn)差計(jì)算的CPU-GPU效率比較
4 結(jié) 語
本文實(shí)驗(yàn)證實(shí),在海量柵格數(shù)據(jù)處理中,GPU通用計(jì)算技術(shù)確有優(yōu)勢。因此,適當(dāng)?shù)馗牧棘F(xiàn)有柵格數(shù)據(jù)的算法,使之適應(yīng)于GPU通用運(yùn)算環(huán)境,是提高柵格數(shù)據(jù)運(yùn)算效率的有效途徑。但是,由于GPU架構(gòu)以及開發(fā)形式的特殊性,實(shí)際應(yīng)用中往往很難使程序具有通用性,尤其是在大規(guī)模并行計(jì)算的環(huán)境下,而硬件條件往往比較統(tǒng)一,在允許的情況下可針對特定的GPU硬件進(jìn)行優(yōu)化,以達(dá)到效率最大化。
[1]Kirk D B,Hwu W W.大規(guī)模并行處理器編程實(shí)戰(zhàn)[M].北京:清華大學(xué)出版社,2010
[2]張舒,禇艷利.GPU高性能運(yùn)算之CUDA[M].北京:水利水電出版社,2009
[3]Sanders J, Kandrot E.CUDA范例精解——通用GPU編程[M].北京:清華大學(xué)出版社,2010
[4]多相復(fù)雜系統(tǒng)國家重點(diǎn)實(shí)驗(yàn)室多尺度離散模擬項(xiàng)目組. 基于GPU的多尺度離散模擬并行計(jì)算[M].北京:科學(xué)出版社,2009
[5]林一松,楊學(xué)軍,唐滔,等. 一種基于關(guān)鍵路徑分析的CPUGPU異構(gòu)系統(tǒng)綜合能耗優(yōu)化方法[J].計(jì)算機(jī)學(xué)報(bào),2012(1):123-133
[6]盧風(fēng)順,宋君強(qiáng),銀福康,等.CPU/GPU協(xié)同并行計(jì)算研究綜述[J].計(jì)算機(jī)科學(xué),2011(3):5-9
[7]許洪騰.圖像變換與表示技術(shù)及其在影像資料修復(fù)與增強(qiáng)中的應(yīng)用[D].上海:上海交通大學(xué), 2013
[8]盧麗君,廖明生,張路.分布式并行計(jì)算技術(shù)在遙感數(shù)據(jù)處理中的應(yīng)用[J].測繪信息與工程,2005,30(3):1-3
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年14期)2020-09-11 07:57:42
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
時(shí)代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛(wèi)生(2014年11期)2014-11-12 13:11:32
