標號樹編解碼的線性算法
2013-12-29 00:00:00王鐫嚴坤妹
中國信息技術教育 2013年12期
摘要:標號樹的編碼是一串能夠映射一棵標號樹結構的標號序列,由于在現代優化算法中便于運算而常常被采用。本文對四種常見的標號樹的編解碼方法進行了綜述,并就標號樹直觀的邊集表示和編碼表示之間的轉換算法進行討論,實現了四種標號樹編解碼的線性算法。
關鍵詞:標號樹;Prufer編碼;Nevile編碼;DM編碼
● 引言
標號樹是計算機領域中常見的一種數據組織形式,它的傳統存儲方法通常有雙親表示法、孩子表示法、孩子兄弟表示法、邊集表示法等,這些表示方法,在遺傳、粒子群等現代優化算法中,由于很難進行運算,所以很少被使用。而標號樹的編碼是一串可以映射一棵標號樹的標號序列,由于其存儲簡單、便于運算,常常被采用,因而對于標號樹編碼的深入討論,無論在計算機的理論還是應用上,都有著十分重要的意義。
1918年Prufer在證明Cayley定理時,最先提出了Prufer編碼,1953年Neville提出了三種編碼方法,其中第一種和Prufer碼一樣,后兩種稱之為Neville2碼、Neville3碼,近年來Deo和Micikevicius又提出了一種新的編碼方法。我們將上述四種編碼簡稱為PR、N2、N3、DM碼。
根據編碼定義,以上四種編碼除DM編解碼的算法時間為О(n),其他三種都為О(n2)。近年來一些文獻用算法語言給出了它們的線性算法思想。本文在綜述上述四種編解碼規則之后,用C語言,就標號樹直觀的邊集表示和編碼表示之間的轉換,給出了編碼和解碼的線性算法。
● 標號樹的編碼
1.編碼方法
總的來說,四種編碼方法都是以葉節點的刪除為基礎,直至只剩下一條邊為止,按照n-2個葉節點的刪除順序,依次將其在刪除前的鄰接點編號組成一個數字序列,就是其標號樹的編碼。四種編碼的不同在于葉節點的刪除順序不同。
(1)PR編碼
刪除標號樹中最小編號的葉節點;重復第一步,直至該標號樹剩一條邊。
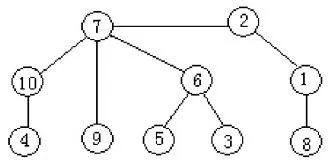
如圖1所示的標號樹,PR編碼的葉子節點刪除順序應為3、4、5、6、8、1、2、9,其相應的鄰接點順序為(6,10,6,7,1,2,7,7)。
(2)N2編碼
按升序將標號樹的葉節點整批刪除;在修正過的標號樹上重復第一步,直至該標號樹剩一條邊。
如圖1,N2編碼的葉子節點刪除順序應為第一層的3、4、5、8、9和第二層的1、6、10,其相應的鄰接點順序為(6,10,6,1,7,2,7,7)。
(3)N3編碼
從最小葉節點開始,逐個刪除其所在鏈上的節點,直至該鏈被刪除;重復第一步,直至該標號樹剩一條邊。
如圖1,N3編碼的葉節點刪除順序應為第一條鏈3,第二條鏈4、10,第三條鏈5、6,第四條鏈8、1、2,其相應的鄰接點順序為(6,10,7,6,7,1,2,7)。
(4)DM編碼
按升序將標號樹的葉節點整批刪除;對修正過的標號樹按照其葉節點出現的先后順序進行整批刪除;重復第二步,直至該標號樹剩一條邊。
如圖1,DM編碼的葉子節點刪除順序應為第一層的3、4、5、8、9和第二層的10,6,1,其相應的鄰接點順序為(6,10,6,1,7,7,7,2)。
2.編碼算法
(1)存儲結構
typedef struct node
{ int data;
struct node *next;
} Node;
typedef Node LTree[N+1];
LTree t;
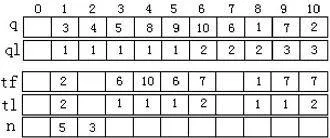
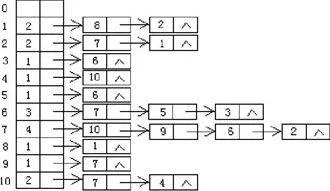
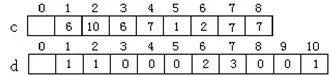
標號樹的存儲結構采用了圖的鄰接表存儲形式,其說明語句如上,標號樹的鄰接表存儲示意圖見圖2。將標號樹中每個節點i的度數存放在t[i]的data域中,將與該節點i相鄰的所有鄰接點,以鏈表鏈接在t[i]的next域中,為了節點i和t數組下標的一致,這里數組的長度定義為N+1。
(2)PR編碼算法
PR編碼算法的思想:在鄰接表t中順序查找出第一個度數為1的節點j(t[j].data=1),當前最小的葉節點u=j,求出和u相鄰的節點v,寫入編碼數組,刪除最小葉節點u(t[u].data--,t[v].data--);比較v和j,如果v PR編碼算法實現見函數PR( ),c數組存放標號樹的PR編碼;函數GetAdjvex( )實現標號樹t中求解u節點的鄰接點運算。 PR( LTree t,int c[] ) { int i,j,u,v; u=v=j=0; for(i=1;i * { if(v //找編號最小的葉子節點u else { while(t[++j].data!=1) ; u=j; } v=GetAdjvex(t,u); // 找葉子u相鄰節點v c[i]=v; //將節點v寫入c數組 t[u].data--; t[v].data--; // 刪除邊(u,v) } } int GetAdjvex(LTree t ,int u ) { Node *p=t[u].next; while( t[p->data].data==0) p=p->next; //相鄰點度數為0,表該節點已刪除 return p->data; } 函數形式上雖然是二層循環,但while循環所遍歷的t數組沒有回溯,在整個編碼過程中只遍歷了一遍;另外求鄰接節點GetAdjvex函數中雖然也有循環,但整個編碼過程中鄰接節點的探查,最多為2N個,所以該編碼算法時間效率是線性的。 (3)N3編碼算法 N3編碼算法的實現參見函數PR(),只要在第五行打“*”的條件語句中去掉v (4)DM編碼算法 DM編碼是按層處理葉節點的,所以這里借用一個隊列q數組進行分層處理。 將標號樹的所有葉節點升序加入隊列q中,之后對q進行出隊運算,求隊頭節點u的相鄰節點v,刪除節點u后的v節點如變成葉子,則加入q隊列中。重復出隊運算直至隊列q為空。 (5)N2編碼算法 N2編碼和DM編碼相似,也是按層處理葉節點的,但每層葉子都要升序排列。這里設計了5個輔助數組(見圖3),其中隊列q數組的作用仍是分層處理,ql數組存放q數組中對應節點的層數(開始為1層,以后逐層加1),數組tf[u]存放u節點的相鄰節點,數組tl[u]存放u節點的層次,數組n[i]存放第i層節點的統計個數。 在分層處理結束后,遍歷數組tf中的數據一次,將每個非0數據tf[i],根據其在數組中的先后位置、數組tl[i]中的層次及數組n[tl[i]]中該層的統計個數,可以計算出該數據在最后編碼的位置,其編碼算法效率也是線性的。 ● 解碼 1.解碼方法 根據編碼序列,還原標號樹的邊集數據稱之為解碼。由于編碼序列中的數據是和刪除葉節點對應的鄰接點,所以只要找出葉節點的刪除順序,就可以還原出每條刪除的邊,也就可以還原出原來的標號樹結構。 將編碼中的節點按編碼順序依次存放在集合P中,將不在集合P中的節點按升序整理到集合NP中,則NP中的節點即為開始時的葉節點。 (1)PR解碼 分別取集合P和NP中最左邊的數據u、v連接成邊加入到樹中;刪除u、v,如P中不再出現u則把u按升序加入到NP中;重復第二步驟,直到P為空;將NP中剩下兩節點編號連接成邊,加入到樹中。 (2)N2解碼 將NP中所有節點依次和P中左邊數據連接成邊加入到樹中,然后分別從P和NP中刪除所有使用過的節點,將P中刪除掉的而在后邊不再出現的節點按升序加入NP中;重復第二步驟,直到P為空;將NP中剩下兩節點編號連接成邊,加入到樹中。 (3)N3解碼 分別取集合P和NP中最左邊的數據u、v連接成邊加入到樹中;刪除u、v,如P中不再出現u則把u插入到NP中最前頭;重復第二步驟,直到P為空;將NP中剩下兩節點編號連接成邊,加入到樹中。 (4)DM解碼 將NP中所有節點依次和P中左邊數據連接成邊加入到樹中,然后分別從P和NP中刪除所有使用過的節點,將P中刪除掉而在后邊不再出現的節點按順序加入NP中;重復第二步驟,直到P為空;將NP中剩下兩節點編號連接成邊加入到樹中。 2.解碼算法 (1)存儲結構 以PR編碼(6,10,6,7,1,2,7,7)的解碼為例,將編碼數據存放在c數組中,統計編碼中各節點i出現的次數,將其寫入數組d中(如圖4),則數組d中數據為0的下標,即為不在編碼中的節點;每找到一條邊,將兩端節點在數組d中對應的數據減1,當數據為-1時,表示該節點在NP集合中已刪除,當數據減為0時,表示該節點由P集合進入NP集合中。 (2)PR解碼算法 PR解碼算法的思想和編碼相同:在數組d中順序查找出第一個數據為0的下標j,則當前最小的葉節點u=j,其相鄰節點v從c數組中順序讀取,將邊(u,v)寫入邊集數組e中,刪除u節點(d[u]--,d[v]--);比較v和j,如果v PR解碼算法實現見函數PRDecode( ),在第二個for循環中,內部的while循環由于沒有回溯,所以時間效率為線性。 void PRDecode(int c[],int e[][2]) { int d[N+1]={0}, u=0,v=0,i,j; for(i=1;i<=N-1;i++) d[c[i]]++; //統計編碼中各節點的個數 for(i=1,j=0;i<=N-2;i++) * { if(v else { while(d[++j]) ; u=j;} v=c[i]; e[i][0]=u; e[i][1]=v;//將邊(u,v)存入e數組 d[u]--; d[v]--; // 刪除u,v節點 } j=0; // 找NP集合中最后2節點 while(d[++j]); u=j; while(d[++j]); v=j; e[i][0]=u; e[i][1]=v; } (3)N3解碼算法 N3解碼算法的實現參見函數PRDecode( ),只要在第七行打“*”的條件語句中去掉v (4)DM解碼算法 DM解碼思想和編碼一樣是按層處理葉子節點的,所以在算法實現中引入一個隊列q進行分層處理。DM解碼算法效率是線性的。 (5)N2解碼算法 N2解碼算法思想和DM解碼算法相似,也是按層處理葉子節點的,但每層葉子需要重新升序排序。 和N2編碼算法設計一樣,N2解碼設計了4個輔助數組,隊列q數組、ql數組、tl數組、n數組,它們的作用和N2編碼算法中的輔助數組一樣。由于編碼順序即為刪除葉節點的鄰接節點順序,所以這里無需數組tf。N2解碼算法的也是線性的。 ● 結束語 本文給出了標號樹常用的四種編碼的線性算法,其中DM編解碼的線性算法可以根據定義直接求得,而其他三種編碼的線性算法借鑒了基數排序的思想,帶有一定的技巧性。 參考文獻: [1]王曉東,吳英杰.Prufer編解碼的最優算法[J].小型微型計算機系統,2008,04:687-690. [2]林志慶,吳英杰,王曉東.Neville編解碼問題的線性時間算法[J].小型微型計算機系統,2010,10:1984-1988. [3]Saverio Caminiti,Irene Finocchi,Rossella Petreschi et al. On coding labeled trees[J].Theoretical Computer Science,2007,382(2):97-108. [4]Paulius Micikevicius,Saverio Caminiti,Narsingh Deo et al. Linear-time Algorithms for Encoding Trees as Sequences of Node Labels[C]. Congressus Numerantium vol.183.2006:65-75.
