構建數據倉庫過程中的數據清洗研究*
2013-11-08 03:11:24劉喜文鄭昌興王文龍湯剛強
圖書與情報 2013年5期
劉喜文 鄭昌興,2 王文龍 湯剛強
(1.南京大學信息管理學院 江蘇南京 210093)(2.南京政治學院基礎部 江蘇南京 210003)
1 引言
隨著計算機信息系統在各行各業的普及,產生了大量的數據,怎樣對這些數據進行有效的組織是當前研究的熱點之一。數據倉庫作為一種有效的數據組織方式,得到了廣泛的應用。數據倉庫是面向主題的、集成的、隨時間變化的、非易失的數據集合,用于支持管理層的決策過程。數據倉庫不僅是一種語義一致的數據存儲,充當決策支持數據模型的物理實現,并存放企業戰略決策所需要的信息,也是一種體系結構,將異構數據源中的數據集成在一起而構建,為企業的決策者提供知識支持。
利用數據倉庫對大量數據進行有效的組織,避免出現”garbage in,garbage out”的情況,則必須保證數據倉庫中的數據的準確性、一致性、完整性、時效性、可靠性和可解釋性,即數據是高質量的數據,才能使OLAP分析或挖掘的結果具有較高的精確性和可信度。但由于種種原因,現實中的數據都是臟數據,要提高數據的質量,不僅要在事前對數據進行嚴格定義與約束,而且還要在事后使用特定算法對數據進行檢測與處理。
國外對數據清洗的研究起源于上世紀50年代的美國,是從糾正全美社會保險號開始,主要是處理西文數據,其研究主要集中以下幾個方面:(1)異常數據的檢測與處理;(2)數據重復的檢測與處理;(3)面向特定領域的數據清洗;(4)與領域無關的數據清洗;(5)數據的集成。數據清洗也必須考慮數據集成問題,即將數據源中的結構和數據映射到目標結構與域中,而數據的多義性和結構對數據集成提出了巨大的挑戰,數據集成包括:實體識別、冗余與相關分析、元組重組和數據值沖突的檢測與處理。國外關于中文的數據清洗的研究較少,且由于語種的差異性,能夠適應英文數據清洗的方法不一定能適合中文數據清洗。比較成熟的方案有IBM公司提出的基于InfoSphere Quality Stage 的中文數據清洗。
國內對于數據清洗的研究較晚,并且針對中文的數據清洗研究的成果也不多。當前國內對數據清洗的研究主要集中在改進西文算法應用到中文領域,取得了一些成果。復旦大學的周傲英教授團隊、沈陽航空工業學院的夏秀峰教授、李蜀瑜博士、東南大學的董逸生教授的團隊均對數據重復問題進行了研究;北京大學的楊冬青教授的團隊、武漢理工大學的袁景凌副教授、東南大學的董逸生教授團隊、復旦大學的周傲英教授團隊等對數據的集成問題進行了研究;中科院的劉清、山東理工大學的王曉原教授、西安理工大學張璟教授、上海寶鋼公司的王永紅、東北大學的于戈教授團隊、西北大學的李戰懷教授團隊、遼寧大學的宋寶燕教授團隊、貴州大學的李少波教授團隊、沈陽航空航天大學的夏秀峰教授團隊均對面向特定領域的數據清洗進行了研究。
本文將對臟數據的類型與出現原因進行總結,對數據清洗的國內外研究現狀進行分析,提出數據清洗的定義與對象,重點闡述屬性級異常數據的檢測與處理的算法、記錄級重復數據的檢測與處理的算法,并對算法的優缺點及適用范圍做簡要說明,并指出當前數據清洗技術的研究不足以及未來研究的方向。
2 臟數據的類型與出現原因
臟數據的類型有許多種類,且每種臟數據出現的原因也不一樣,本文從單數據源的臟數據類型與出現原因和多數據源的臟數據類型與出現原因進行描述,根據復旦大學周傲英教授對臟數據的分類,將臟數據分為單數據源模式層問題、單數據源實例層問題、多數據源模式層問題和多數據源實例層問題四種類型,表1列出了“臟數據”類型、實例與出現原因。
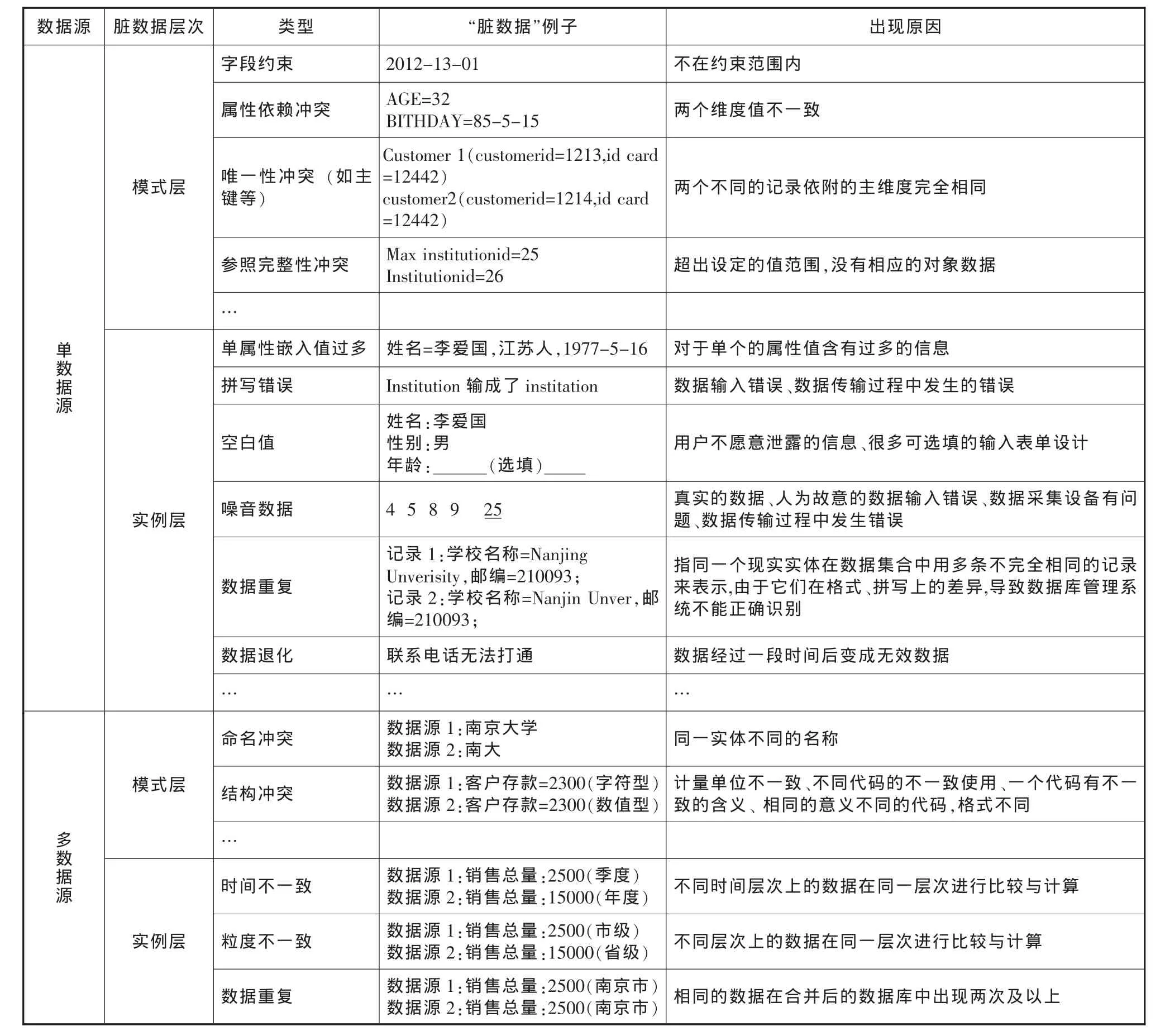
表1 “臟數據”類型、實例與出現原因
如表1所示,“臟數據”的類型有很多種,在實例層來說,單數據源的“臟數據”就是不完整數據、不正確數據、不可理解數據、過時數據、數據重復等,單數據源的數據清洗主要是指在屬性上對數據進行檢測與處理;多數據源的“臟數據”更為復雜,主要指大量的重復數據、數據沖突,多數據源的數據清洗主要指是對重復數據的檢測與處理、解決數據冗余和數據沖突問題。
3 數據清洗的定義與對象
3.1 數據清洗的定義
數據清洗不僅應用在數據倉庫中,也應用在數據挖掘和全面數據質量管理領域,不同的領域中數據清洗的定義也不相同,數據清洗沒有統一的定義。本文借用南京理工大學的王曰芬教授對數據清洗的定義:
數據清洗為清除錯誤和不一致數據的過程,并需要解決孤立點和元組重復問題。數據清洗并不是簡單地對臟數據進行檢測和修正,還涉及在屬性級上維度的整合與分解,及數據的整合與分解。
3.2 數據清洗的對象
借鑒復旦大學周傲英教授和南京理工大學王曰芬教授對數據清洗對象的分類,按照數據清洗對象的來源領域與產生原因對數據清洗對象進行分類,對象的來源領域因素屬于宏觀層面劃分,而產生原因屬于微觀層面劃分。
(1)來源領域:很多領域涉及到數據清洗,包括數字化文獻服務、圖書借閱、搜索引擎、金融領域、政府機構、商品零售、射頻識別領域等,數據清洗的目的是為信息系統提供準確而有效的數據。現在研究比較多的領域有:
①射頻識別(Radio Frequency Identification,RFID)領域的數據清洗研究:由于RFID硬件設備固有的限制和環境噪聲的影響,RFID閱讀器存在漏讀、多讀和臟讀等現象,降低了RFID數據的可用性,如何識別部分信息丟失的數據、重復閱讀的數據、未正確閱讀的數據以及模糊的數據是研究人員關注的,對于這些臟數據需要經過數據清洗的方法進行檢測及糾正是必要的。國內外已經有很多學者對射頻識別領域的數據清洗問題展開了研究,并已經取得了一些成果。
②Web領域的數據清洗研究:搜索引擎為人們在Web上查找信息提供了方便,返回網頁與用戶查詢主題的貼切程度并不讓人滿意,這是因為對網頁索引的效果比較差,需要在索引時對網頁的內容進行清洗。按照網絡數據清理的粒度不同,現有的解決思路大致分為兩類,Web頁面級別的數據清理和基于頁面內部元素級別的數據清理,前者以Google公司提出的PageRank算法和IBM公司Clever系統的基石HITS算法為代表;而后面一個思路則集中體現在作為MSN搜索引擎核心技術之一的 VIPS 算法上。
③面向特定領域的數據清洗:主要是金融領域、保險領域、零售領域、政府機構、交通領域等,這些領域的臟數據包括錯誤數據、不一致數據、重復數據以及業務邏輯錯誤的數據。
④數字化文獻服務領域,在進行數字化文獻資源加工時,OCR軟件有時會造成字符識別錯誤,或由于標引人員的疏忽而導致標引詞的錯誤等,解決這些問題是數據清洗需要完成的任務。
(2)產生原因:在微觀方面,數據清洗對象分為模式層和實例層數據清洗。數據清洗的任務是過濾或者修改那些不符合要求的數據,主要包括不完整數據、不正確數據、不可理解數據、不一致數據和重復數據等幾類。
4 數據清洗算法
對于數據清洗算法,一些研究機構提出了數據預處理、排序鄰居方法、多次遍歷數據清洗方法、采用領域知識進行清洗、采用數據庫管理系統的集成數據清洗等算法。基于中文數據和西文數據的差異性,中文數據清洗除了移植西文數據的清洗方法外,也有自己特有的清洗方法。
4.1 屬性級異常數據的清洗
無論西文數據還是中文數據的屬性級異常情況都有空白值、噪音數據、不一致數據等,異常數據的檢測方法與處理方法如圖1所示。

圖1 屬性級異常數據的檢測與處理方法
如圖1所示,人工檢測的方法,需要花費大量的人力、物力和時間,而且這個過程本身很容易出錯,所以需要利用更高效的方法自動檢測數據集中的屬性錯誤,這些方法包括統計學方法、模式識別方法、聚類方法,、基于鄰近性的方法、基于分類的方法、基于關聯規則的方法等。這些方法的主要思想、優點、缺點的比較如表2所示。
如表2所示,西文數據的自動檢測屬性級錯誤數據的方法主要有6種方法,我們可以把這些方法分成監督方法、半監督方法和無監督方法。研究比較多的是統計學方法、聚類方法、基于鄰近性(距離)的方法和基于關聯規則的方法,統計學方法包括參數方法(基于正態分布的一元離群點檢測、多元離群點檢測和使用混合參數分布)和非參數方法(盒圖、直方圖),基于鄰近性(距離)的方法包括基于距離的異常值檢測與嵌套循環方法、基于網格的方法和基于密度的方法。
我們處理的屬性級錯誤主要是實例層的錯誤數據,包括空缺值的處理方法、噪音值的處理方法和不一致值的處理方法。
⑴空缺值的清洗方法主要有:忽略元組;人工填寫空缺值;使用一個全局變量填充空缺值;使用屬性的中心度量(均值、中位數等);使用與給定數據集屬同一類的所有樣本的屬性均值、中位數、最大值、最小值、從數等;使用最可能的值;或更為復雜的概率統計函數值填充空缺值。
(2)噪音值的清洗方法主要有:分箱(Binning),通過考察屬性值的周圍值來平滑屬性的值。屬性值被分布到一些等深或等寬的“箱”中,用箱中屬性值的平均值、中值、從數、邊緣值等來替換 “箱”中的屬性值;回歸(regression),用一個函數擬合數據來光滑數據;計算機和人工檢查相結合,計算機檢測可疑數據,然后對它們進行人工判斷;使用簡單規則庫檢測和修正錯誤;使用不同屬性間的約束檢測和修正錯誤;使用外部數據源檢測和修正錯誤。
(3)不一致數據的清洗方法。對于有些事務,所記錄的數據可能存在不一致。有些數據不一致,可以使用其他材料人工加以更正。例如,數據輸入時的錯誤可以使用紙上的記錄加以更正。知識工程工具也可以用來檢測違反限制的數據。知道屬性間的函數依賴,可以查找違反函數依賴的值。此外,數據集成也可能產生數據不一致。表3給出屬性級錯誤數據清洗的方法比較情況。
上述檢測與處理的算法對中文屬性級異常數據也適用,但需要對算法進行改進,因為中文是雙字節編碼,并且沒有明顯分隔符,存在大量同音字,對屬性級上數據清洗帶來一定的困難,也是研究中文數據清洗的重點與難點之一。中文屬性級異常數據清洗研究主要集中在數據重復檢測方面。中文數據重復檢測的方法有:(1)字符串匹配方法,又有5種不同的方法:單個字符的匹配方法、漢語自動分詞方法、特征詞匹配方法、詞法分析得到的字符串匹配方法和中文縮寫的回歸字段匹配方法;(2)拼音匹配方法,中文經常會出現同音字的現象,為了增大匹配的幾率,有些時候需要用匹配單位的字符拼音進行匹配,目的是解決漢語中一音多字的問題,拼音匹配方法可作為字符串匹配方法的一種輔助方法,提高匹配精確度;(3)字段的相似度匹配方法,通過相似度計算公式進行相似度計算,從而判斷相似性,主要有編輯距離方法。

表2 自動檢測屬性級錯誤數據的方法的主要思想及方法比較
4.2 記錄級異常數據的清洗
記錄級異常數據主要指記錄數據的重復,對重復記錄數據的處理包括重復記錄檢測和重復記錄數據的處理。對重復數據的檢測的算法主要有基本的字段匹配算法,遞歸的字段匹配算法,Smith-Waterman 算 法,編輯距 離、Cosine 相 似 度函 數,表4給出了各種算法的比較。
對記錄級的數據處理的思想是“排序和合并”,先將數據庫中的記錄排序,然后通過比較鄰近記錄是否相似來檢測記錄是否重復。消除重復記錄的算法主要有:優先隊列算法、 近鄰排序 算 法 (Sorted-Neighborhood Method,SNM)、 多 趟 近 鄰 排 序 (Multi-Pass Sorted-Neigh bor2hood,MPN)。 表 5 給出了重復記錄清洗算法的比較情況。
上述記錄級數據重復的檢測與處理方法不僅適用于西文數據,也適用于中文數據,而且中文數據也有自己的獨特的方法,是上述各種算法的變異,包括:①有序鄰接點算法,其思想是:首先對整個數據集按照用戶定義的鍵進行排序,然后將可能匹配的記錄相鄰排列在一起,從而檢測出疑似重復記錄,此算法的缺陷主要表現在兩個方面,第一,對于關鍵字的依賴過大,關鍵字選取的好壞直接影響到匹配的效率和精度;第二,對于固定窗口的選取不當,可能會造成匹配精度的下降和匹配時間的增加;②Fuzzy Match/merge算法,其主要思想是對各個屬性數據進行規范化處理之后,對于所有記錄兩兩進行比較,比較時采取一些模糊的策略,最后將比較結果合并,此算法的缺陷主要是所需的時間較長,以及對于計算機空間的要求較高。

表3 屬性級錯誤數據的方法比較
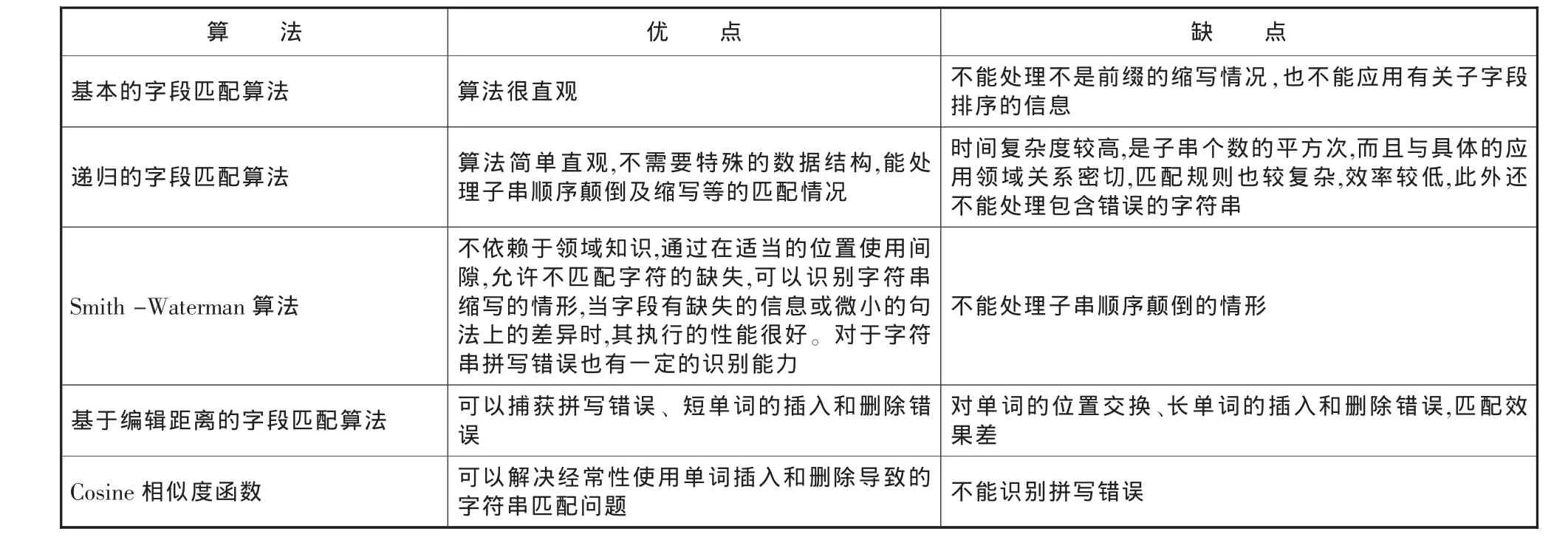
表4 重復記錄檢測的算法比較

表5 重復記錄清洗的算法比較
5 數據清洗研究的不足與展望
國外對西文數據清洗的研究比較成熟,對中文數據的研究比較少;國內對中文數據清洗的研究主要集中在對算法的改進,原創性算法還比較少,取得的成果也不多。因此,對于中文數據清洗的研究還存在很大的發展空間,具有很好的應用前景和理論價值。
無論是對西文數據清洗的研究還是對中文數據清洗的研究都存在著很多不足之處,主要表現在以下幾個方面:(1)數據清理研究主要集中在西文數據上,中文數據清理與西文數據清理有較大的不同,中文數據清理還沒有引起重視;(2)現今對于中文數據清洗的研究主要針對的是實例層的數據,比如在數值型、字符串型字段中的研究,而對于模式層的數據清洗研究比較少;(3)對重復數據的識別效率與識別精度問題的解決并不令人滿意,特別是在記錄數據非常多時,耗時太多;(4)以前數據清理主要集中在結構化的數據上,而現在清洗的對象主要是非結構化數據或半結構化的數據;(5)數據清洗工具或系統都提供了描述性語言,但基本上都是經過某種已有語言根據自己需要經過擴展實現的,不能很好地滿足數據清理中大致匹配的需要,不具有互操作性,需要加強數據清洗工具之間的互操作性研究;(6)現今的數據清洗大多數是面向特定領域。
依據現今數據清洗的研究的不足,數據清洗未來主要的研究方向有:(1)中文數據清理工具的研究和開發;(2)數據挖掘方法在數據清理領域應用做深入研究;(3)重復記錄識別的效率需要進一步提高;(4)非結構化數據的清洗;(5)數據清洗工具之間的互操作性;(6)數據清理方案的通用性。后續將對中文數據清洗技術的改進和優化做進一步的研究。
[1]William H.Inmon.王志海,等譯.數據倉庫(第 4 版)[M].北京:機械工業出版社,2006:20.
[2]Lee M,Lu H,Ling T W,etal.Cleansing data for mining and warehousing[A].Proceedings of the 10th International Conference on Database and Expert Systems Applica tions[C].1999:751-760.
[3]Jiawei Han,Micheline Kamber,Jian Pei.DATA MINING Concepts and Techniques[M].北京:機械工業出版社出版社(第三版),2012:84,92-99,543-572.
[4]Dasu T,Johnson T.Exploratory data mining and data cleaning[M].John wiley,2003.
[5]Galhardas H,Florescu D.An Extensible Framework for Data Cleaning[A].Proceedings of the 16 th IEEE Inter national Conference on Data Engineering.San Diego[C].California,2000:312-312.

[7]俞榮華,田增平,周傲英.一種檢測多語言文本相似重復記錄的綜合方法[J].計算機科學,2002,29(1):118-121.
[8]邱越峰,田增平,李文 等.一種高效的檢測相似重復記錄的方法[J].計算機學報,2001,24(1):69-77.
[9]劉哲,夏秀峰,宋曉燕等.一種中文地址類相似重復信息的檢測方法[J].小型微型計算機系統,2008,29(4):726-729.
[10]石彥華,李蜀瑜.聚類反饋學習的數據清洗研究[J].計算機工程與應用,2011,47(30):127-131.
[11]韓京宇,徐立臻,董逸生.一種大數據量的相似記錄檢測方法[J].計算機研究與發展,2005,42(12):2206-2212.
[12]方幼林,楊冬青,唐世渭等.數據轉換過程的串行化方法[J].計算機工程與應用,2003,39(17):184-187.
[13]袁景凌,徐麗麗,苗連超.基于XML的虛擬法異構數據集成方法研究 [J].計算機應用研究,2009,26(1):172-174.
[14]韓京宇,胡孔法,徐立臻等.一種在線數據清洗方法[J].應用科學學報,2005,(3):292-296.
[15]郭志懋,俞榮華,田增平等.一個可擴展的數據清洗系統[J].計算機工程,2003,(3):95-96,183.
[16]張晉輝,劉清.基于推理機的 SCI地址字段數據清洗方法設計[J].情報科學,2010,28(5):741-746.
[17]王曉原,張敬磊,吳芳.交通流數據清洗規則研究[J].計算機工程,2011,37(20):191-193.

[19]王永紅.定量專利分析的樣本選取與數據清洗[J].情報理論與實踐,2007,30(1):93-96.
[20]馬茜,谷峪,張天成等.一種基于多閱讀器數據冗余的高效RFID數據清洗策略[J].小型微型計算機系統,2012,33(10):2158-2163.
[21]谷峪,于戈,胡小龍等.基于監控對象動態聚簇的高效RFID數據清洗模型[J].軟件學報,2010,21(4):632-643.
[22]谷峪,李曉靜,呂雁飛等.基于RFID應用的綜合性數據清洗策略[J].東北大學學報(自然科學版),2009,30(1):34-37.
[23]潘巍,李戰懷,聶艷明等.一種有效的多數據源RFID冗余數據清洗技術[J].西北工業大學學報,2011,29(3):435-442.
[24]王妍,宋寶燕,付菡等.引入卡爾曼濾波的RFID數據清洗方法[J].小型微型計算機系統,2011,32(9):1794-1799.
[25]潘偉杰,李少波,許吉斌.自適應時間閾值的RFID數據清洗算法[J].制造自動化,2012,34(7 上):24-27,36.
[26]夏秀峰,玄麗娟,李曉明.分流機制下的RFID不確定數據清洗策略[J].計算機科學,2011,38(10A):22-25.
[27]郭志懋,周傲英.數據質量和數據清洗研究綜述[J].軟件學報,2002,13(11):2076-2082.
[28]王曰芬,章成志,張蓓蓓等.數據清洗研究綜述[J].現代圖書情報技術,2007,(12):50-56.
[29]Sullivan L.RFID implementation challenges persist,all this time later[J].Information Week,2005,1059:34-40.
[30]Jeffery S R,Garofalakis M N,Franklin M J.Adaptive cleaning for RFID data streams[A].Proceedings of Vary Large Data Bases Seoul,Korea,2006:163-174.
[31]Derakhshan R,Orlowska M E,Li X.RFID data man agement:challenges and opportunities[A].Proceedings of 2007 IEEE International Conference on RFID [C].Gaylord Texan,USA,2007:175-182.
[32]Song Baoyan,Qin Pengfei,Wang Hao,et al.bSpace:a data cleaning approach for RFID data streams based on virtual spatial granularity[A].20099th International Conference on Hybrid Intelligent System.IEEE Com puter Society[C].2009,252-256.
[33]Ziekow H,Ivantysynova L.A probabilistic approach for cleaning RFID data[A].ICDE Workshop[C].2008.
[34]劉奕群,張群,馬少平.面向信息檢索需要的網絡數據清理研究[J].中文信息學報,2006,20(3):70-77.
[35]Sergey Brin and Lawrence Page,The anatomy of a large-scale hypertextual Web search engine[J].Com puter Networks and ISDN Systems,1998,30(7)107-117.
[36]JonM.Kleinberg,Authoritative sources in a hyperlinked environment[J].Journal of the ACM,1999,46(5):604-632.
[37]Deng Cai,Shipeng Yu,Ji RongWen and Wei YingMa.VIPS:a Vision based Page Segmentation Algorithm[R].Microsoft Technical Report(MSR2TR22003-79),2003.
[38]周奕辛.數據清洗算法的研究與應用[D].青島:青島大學,2005.
[39]唐懿芳,鐘達夫,嚴小衛.基于聚類模式的數據清洗技術[J].計算機應用,2004,24(5):116-19.
[40]Masek W,Paterson M A.Faster Algorithm Computing String Edit Distance[J].Journal of Computer System Science,1980,(20):18-31.
[41]周芝芬.基于數據倉庫的數據清洗方法研究[D].上海:東華大學,2004.
[42]Salon G,McgillM J.Introduction to Modern Information Retrieval[M].NewYork:McGraw-Hill Book Co,1983.
[43]Monge A,Elkan C.The Field Matching Problem:Algo rithms andApp lications[A].Proceedings of the 2nd In ternational Conference of Knowledge Discovery and Data Mining[C].Portland,Oregon,1996.
[44]Hernandez M,Stolfo S.Real World Data is Dirty:Data Cleansing and theMerge/Purge Problem[J].DataMin ing and Knowledge Discovery,1998,2(1):9-37.
[45]Hon D B,Dewi V J.Duplicate record elimination in large data files[J].ACM Transactions on Database Sys tem,1995.
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
