面向知識服務的引文索引數據組織研究(Ⅱ)*——引文索引數據架構與編碼設計
2013-11-08 03:11:24朱云霞蘇新寧
圖書與情報 2013年5期
朱云霞 蘇新寧
(1.南京大學信息管理學院 江蘇南京 210093)
(2.南京郵電大學計算機學院 江蘇南京 210023)
1 引言
文獻通過引用建立關聯,這種關聯蘊含著豐富的知識,對引用關系進行分析可以揭示知識的關聯,幫助發現隱藏的知識與科學規律。信息技術的發展推動了引文數據的開發利用,早從20世紀60年代開始,就研制出了以SCI為代表的一系列引文索引系統。當前人們對知識服務的需求不斷提升,引文索引已不再是簡單的檢索工具,人們希望能從中獲取更多的知識。如何借助引文索引實現知識服務?如何從引文索引中發現科學研究規律和和潛在學術價值?這就需要我們對引文索引結構與組織進行深入探討,使之充分體現引文索引價值,滿足知識服務對引文索引的要求。
2 研究背景
文獻間的引證關系始于19世紀西方科學界形成的嚴格科學傳統,引文索引正是利用這種引證關系創建而成。國外最早出現的是1961年計算機編制的《遺傳學引文索引》,其后在尤金·加菲爾德的帶領下,先后誕生了SCI、SSCI、A&HCI等一批優秀的引文索引。國內對引文索引的研究始于80年代末期,陸續誕生了CSCD、CSTPC、CSSCI等一批引文索引系統。郭麗芳、王婧對中外引文索引的功能進行了比較研究。從大量文獻可以看到,國內對于引用關系的研究多集中于引文數據的分析利用,而對于引文索引及其數據組織關系的研究則鳳毛麟角。南京大學蘇新寧教授撰寫多篇文章詳細介紹了CSSCI的數據組織結構與應用價值,為國內引文索引的設計與研究工作奠定了良好的基礎。在此基礎之上,也陸續產生了一些針對專業領域的引文索引系統。
傳統的引文索引以文獻為單位,強調的是文獻的檢索,對于文獻內部蘊含的知識以及知識間的關聯不能全面、深刻的進行反映,從而不能滿足廣大用戶的知識獲取需求。本文以知識服務為視角,闡述了新型引文索引的構建思路,并在此基礎上對面向知識服務的引文索引的架構設計、數據庫結構以及索引編碼設計進行了詳細的介紹。
3 面向知識服務的引文索引構建思考
文獻之間的引用本質上是知識間的關聯,這些關聯知識也正是提供知識服務的前提與基礎。引文索引是一種典型的關系類知識工具,在文獻引用過程中,各類實體間的關聯是廣泛而復雜的。知識服務是一種用戶目標驅動的服務,是面向知識內容、面向解決方案的服務,貫穿于用戶進行知識析取、集成、創新全過程的服務,因此引文索引的數據組織也應當以科學研究的需要、學者的需求為目標。
3.1 引文索引的知識服務類型
科學、有效的數據組織是提供知識服務的有利保證,知識服務是數據組織的最終目的。為了更深刻的理解引文索引功效,發揮引文索引在知識服務中的重要作用,我們歸納了引文索引能提供的知識服務類型(見表1)。

表1 引文索引知識服務類型及應用說明
傳統的引文索引以檢索型服務為主,以文獻作為信息傳遞單元。雖然大多索引都具有分類統計功能,也提供了較多的檢索途徑,但知識服務功能相對較弱,對于更宏觀、更全面的分析、評價和預測功能則卻鮮見。
根據上述五種知識服務類型,我們按照知識需求的層次從低到高進行劃分:檢索統計型提供最低級的知識服務,其次是特征分析型和資源評價型,知識發現型和學術預測型是最高層次的知識服務類型。不同類型的知識服務對引文索引的設計要求也不同,層次高的知識服務需要有更大規模的數據和更先進的分析技術作為支撐,同時也希望基礎的數據組織架構能夠表達實體間更多的關聯,為知識服務提供更好的數據基礎。根據對不同類型知識服務的需求分析,我們對新型引文索引系統的設計目標總結為:①結構科學合理,發揮各數據屬性功用,增加檢索途徑;②科學組織數據,呈現科學特征、規律,為數據挖掘和知識發現打下基礎;③實現數據代碼化,為科學地、多角度地統計分析提供精準數據;④注重數據間的關聯,為展現對象間的多重關聯提供途徑和實現手段;⑤數據的組織能夠易于系統功能的擴展。
3.2 知識服務引文索引系統模型
為達到上述系統目標,按照數據工作流程,我們將整個引文索引系統組織分為五大層次,依次為基本業務層、基礎數據層、數據模式層、知識服務層和用戶層(見圖1)。

圖1 知識服務引文索引系統模型
基本業務層的主要工作是相關數據的采集。包括:資源的選定(如期刊引文索引中的來源期刊的選定),對采集的數據輸入、整理、清洗、標引和分類工作等。
基礎數據層是引文索引的實體部分,主要提供文獻檢索和一般性知識查詢服務。這一層重點關注數據庫的架構、細節化的庫結構設計以及元數據的表達等,它是整個索引系統提升知識服務的基礎數據來源,也是一般性統計分析的重要基礎。
在數據模式層中,主要建立數據中各類關聯,為知識服務奠定基礎。該層的數據組織主要依據用戶需求,建立面向主題域的知識倉庫。知識倉庫的數據來自于基礎數據庫,其數據關聯來自于用戶需求和科研領域的需要,并能夠充分體現對象間的多維關聯。
知識服務層由是完成知識服務功能的系統組成,它根據用戶需求,并對基礎數據層和數據模式層提供的數據進行統計、分析、挖掘等工作,并提供用戶知識服務。在這一層面,要求功能模塊可以根據需要擴展,系統功能的開發可以完全獨立于數據庫的物理存儲結構,提升系統的邏輯獨立性。
用戶層的作用是對用戶的信息需求進行分析,將用戶的需求分解成對應的知識服務功能模塊,由知識服務層啟動相關功能模塊為用戶提供知識服務。
上述分析可以看到,引文索引必須以滿足用戶的需求為目標,以更深入的分析和輔助決策功能為特色,以良好的數據組織和架構設計為基礎,以信息知識化、方法科學化、分析智能化為核心動力,是知識服務又一新型載體。
4 引文索引的基礎數據組織
4.1 框架構建
基礎數據的組織是整個系統的基礎,它直接關系到索引系統的執行效率和系統的穩定性。我們將基礎數據分為9個組成部分,分別是:來源文獻庫、被引文獻庫、來源作者信息庫、期刊目錄庫、期刊沿革庫、機構信息庫、機構變化庫、關鍵詞索引庫、公共字典編碼庫(見圖2)。
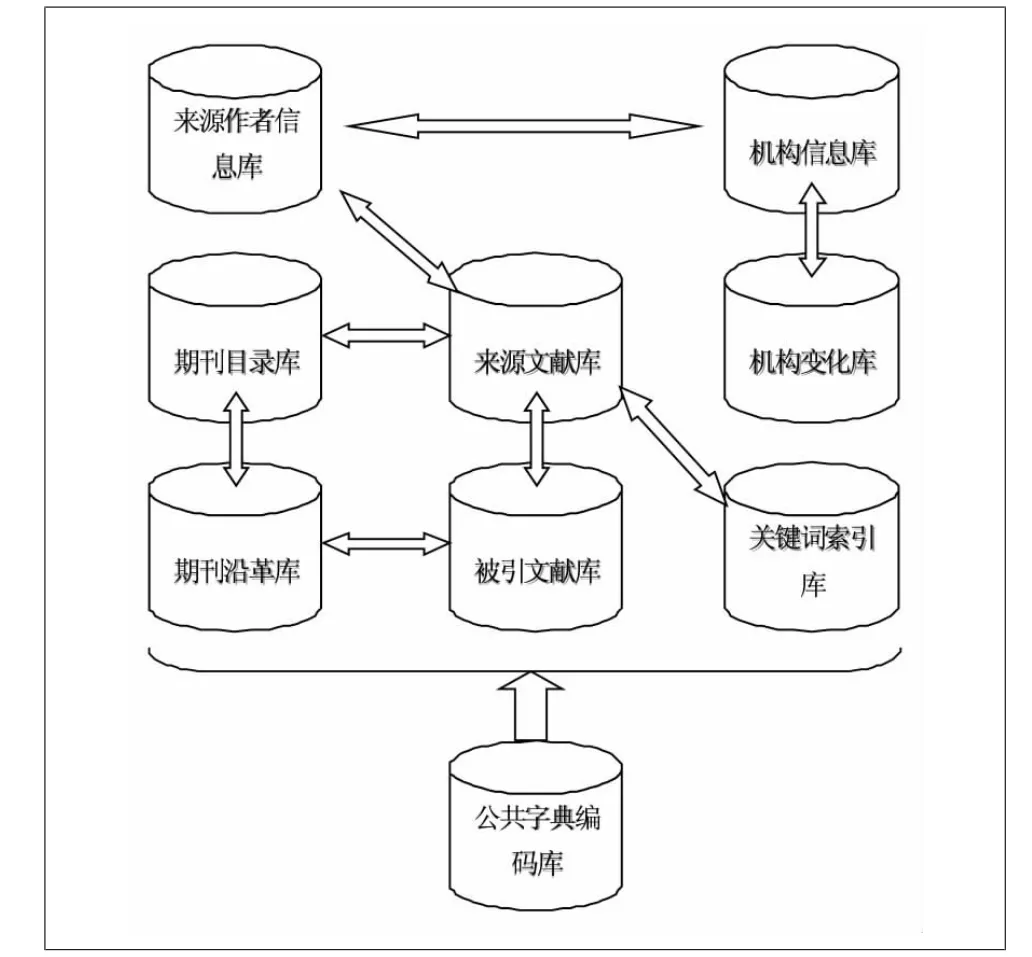
圖2 基礎數據組織架構圖
在引文索引系統的開發中,數據庫設計應遵循必要的數據庫范式理論,以減少冗余、保證數據的完整性與正確性,如此設計的引文索引組織架構特點在于:
(1)提供更多的檢索途徑。將來源文獻與被引文獻分不同的庫存放,用戶既可以從來源文獻角度追蹤其被引文獻,也可以從被引文獻角度回溯其來源文獻,提高了服務的靈活性。
(2)減少數據的冗余。由于一篇論文往往有多個作者,一個作者又常常會標注多個機構,為了節約存儲空間,減少數據冗余,在來源文獻數據庫中只描述文獻信息,對作者及其機構信息單獨建立作者信息庫。
(3)將機構、期刊名稱進行統一。改革開放以來,特別是近十幾年來,我國高校的機構名稱發生了很大變化,另外很多地區的高校進行了合并,一些原有機構已不復存在,這對以機構名稱為單位的統計工作造成了很大影響,因此特別增加了機構變化庫,詳細記錄各機構名稱的變化情況。同樣的情況,對于期刊的歷史變遷則專門建立了期刊沿革庫,以記錄期刊名稱變化的情況。
(4)編碼知識化。在設計過程中專門設置公共字典編碼庫,用于存放各項類型的編碼,如地區編碼、機構類型編碼、引文類型編碼等,公共字典編碼庫作為代碼化的知識工具對各數據庫數據起到統一、規范和關聯的作用。
(5)提供關鍵詞方面的檢索和分析。設計的關鍵詞索引能夠極大提高檢索的效率,同時對基于關鍵詞頻的學科熱點分析、關鍵詞共現分析等,均提供了良好的數據基礎。
4.2 庫結構及關系描述
(1)來源文獻庫:用于記錄引文索引所收錄的每一篇文獻的詳細信息,字段包括:文獻號、中文篇名、英文篇名、中文關鍵詞、英文關鍵詞、期刊代號、語種代碼、發表年份、卷期、頁碼、各種分類號、文章類型、基金類型代碼、基金內容、出版日期、參考文獻數量等。對于一些更為完善的引文索引,可能還會增加人工標引的主題詞、中英文摘要等信息。
(2)來源作者信息庫:用于記錄來源文獻每一位作者的基本信息,主要字段應有:文獻號、作者序號、作者姓名、機構名稱、機構類型編碼、地區代碼、通訊地址、備注等。設置作者序號,有利于進行“第一作者”檢索,備注字段用于存儲作者的個人情況,比如性別、出生日期、研究方向等,這些信息都能夠為深層次的知識服務提供分析用數據。
(3)被引文獻庫:用于記錄被引文獻的基本信息,字段包括:文獻號、引文序號、引文篇名、引文語種代碼、引文類型代碼、被引作者、引文期刊名稱、出版社、出版年、卷期、起止頁碼、被引形式、被引角色、備注等。
(4)期刊目錄庫:用于記錄被收錄期刊的基本信息,該庫主要與來源文獻庫相關聯的關鍵字是期刊代號。主要字段有:期刊代號、期刊中文名稱、期刊英文名稱、ISSN號、國內刊號、出版周期、出版單位、主辦單位、期刊分類、創刊時間、郵發代號、通信地址、郵政編碼、網址等。
(5)期刊沿革庫:用于記錄期刊名稱變化的情況,主要用于統計中的數據歸并處理,也可用于期刊引用網絡構建時的刊名統一化處理。該庫的主要字段有:期刊代號、期刊中文名稱、之前名稱、更名時間等。
(6)機構信息庫:用于記錄發文作者所在機構的基本信息,主要與來源作者信息庫相關聯,該庫的主要字段包括:機構名稱、機構英文名稱、機構類型代碼、國家代碼、地區代碼、通訊地址、郵政編碼等。
(7)機構變化庫:用于記錄機構的名稱變化信息,該庫的主要字段包括:機構名稱、機構類型代碼、變化原因、之前名稱、更名時間等。
(8)關鍵詞索引庫:用于存儲所有收錄文獻的關鍵詞,并建立倒排索引,主要目的用于檢索和進行關鍵詞統計,通過對關鍵詞的統計,可以分析學科研究熱點和發展趨勢。該庫的主要字段包括:關鍵詞、關鍵詞詞頻、來源文獻號集合等。
(9)公共字典編碼庫:幾乎和引文索引中的所有庫都具有聯系,該庫包括7張編碼表(國家與地區編碼表、國內地區編碼表、機構類型編碼表、基金類型編碼表、語種類型編碼表、分類體系對照表和引用類型公共編碼表),是整個基礎數據架構的連接和紐帶,同時其特有的編碼設計也為知識服務提供了有力的保證。
4.3 公共字典庫的代碼設計
編碼是對數據進行知識化和規范化的過程,編碼本質上是對象的抽象表達,優秀的編碼規則能夠使系統發揮更大的效能。我們在公共字典庫中設置了7種編碼,使各項數據之間建立起知識化的關聯,下面介紹幾種主要的編碼。
(1)國內地區編碼。地區編碼主要針對作者的機構所在的地區信息進行的編碼,編碼的目的是能夠以省或市為單位對國內各地區進行成果的統計和分析,甚至可以進行同級別城市(如各省會城市)的科研成果數量比較。通過地區編碼,我們既可以很方便地以省為單位集中統計,也可以很方便地對各省內的城市進行相關統計分析。更重要的是,地區編碼能夠提升地區統計的準確性和效率。
由于目前各期刊對作者的地區標引沒有統一的規定,文獻中作者的地區數據顯得非常凌亂,有的只標注省份,有的標注省和市,有的僅給出了城市名,有的甚至沒有地區標注。另外,隨著中國城鎮化建設步伐的加快,地區名稱也常常出現變更的情況,因此編碼為解決這類地區名稱變化帶來的統計上的困難提供了有效途徑,它實際上起到了地區名稱規范化、統一化的作用。地區編碼需要注意地區間的從屬關系以及地區信息表示的粒度問題,既要能突出表現將省內城市聚合成以省為單位的粗粒度,也要能夠表示省內所轄城市為單位的細粒度。以江蘇省及其所轄市為例,既要能夠通過編碼從大量的文獻中提取出江蘇省作者發表的論文,也能夠統計江蘇省內各地級市作者發表的論文。這樣的編碼設計可以依據不同用戶的需求,靈活的設置地區級別。此外,通過區縣級的編碼還能夠從細節上發現小區域的經濟特色和優勢產業,為科技服務產業提供了良好的數據資源。
具體的地區編碼策略為:采用6位數字編碼方式,其中1-2位為省級行政區域編碼(包括省、直轄市、自治區和特別行政區),3-4位為市級編碼,省會城市的編碼統一為“01”,若是直轄市這兩位代表它們的區縣,第5-6位為區縣級編碼,包括下屬的縣級市、區和縣。依據這樣的編碼規則,北京的編碼為 “010000”,江蘇南京的編碼為“160100”,依次類推。
(2)機構類型編碼。發文機構數量龐大、類型眾多,對機構編碼的過程,實質上是對眾多發文機構進行歸類整序的過程,同時也是知識化的過程。經過機構編碼,引文索引可以根據用戶不同的知識需求,對編碼進行組配查詢,來達到特殊要求的統計分析結果。例如欲分析對比全國“211”師范院校的科研實力,在沒有編碼前需要羅列這些學校,然后逐一檢索獲得相關數據。而科學的編碼,可使這類繁瑣的工作變得簡單高效。
從科學分析角度針對科研機構分類,我們可以將所有機構劃分:高等院校、科研院所、黨政機關、文化團體、企業、軍隊系統、非高校教育單位和其他8種類型,分別用數字1-7、9表示(我們在整個編碼系統中,對于其他類別統一都用數字9表示),對于每種類型再根據具體情況編制下級機構類型代碼。
例如:對于高校,可以將其劃分為“985”工程院校、“211”院校、教育部直屬院校、中央其他部門所屬院校、地方本科院校、高職(專科)院校6種類別,分別用數字1-6表示;再下一級可以表示高校的專業特征,如:綜合性院校、師范類院校、醫學類院校、工科類院校、體育類院校、藝術類院校、軍事類院校、財經類院校和其他專業院校9種類別,用數字1-9表示。當然,也可以根據實際情況增加院校類別。有些高校可能會對應多個編碼,本編碼規定一律高靠,比如,南京大學可能對應的機構類型編碼有“111”“121”和“131”三種,本編碼系統只為南京大學取“111”作為編碼,可在進行統計分析時,通過一定算法來區分。在對某一類學校進行統計對比時,我們只要借助編碼就可以方便的進行統計分析。例如,當對全國財經類院校進行統計分析時,我們就可以利用代碼“1x8”抽取相關數據完成統計,其中“x”可以為任何數字,也可以是指定某幾個數字。
對于科研院所也可以劃分三級進行編碼,如:國家所屬、省部所屬、專業學會所屬、其他等;然后再將其細分:自然科學類、工程科學類、醫藥學類、社會科學類、其他,等等。如,中國社會科學院為國家所屬的社會科學院科研機構;再如,江蘇省中醫藥研究院為江蘇省所屬的醫藥學類研究所。
其他類機構都可以按縱橫兩個方面再劃分兩級編碼,縱是指行政上的上下級或所屬關系,如,國家級、省市級等等;橫是指機構的類別或屬性,如高校按學科劃分等。所有機構類型編碼均由三位數字組成。在實際的機構編碼過程中,可以根據資源涉及的機構狀況,根據實際需要來設置自己的機構編碼。
(3)基金類型編碼。其他中研究院術情報所化論、轉化論與融合輪將用戶的需求分解成基金類型編碼用于為各類資助基金進行編碼,以反映各類基金的科研成果狀況,進而分析各類基金在科學研究中發揮的作用。目前,基金項目類型眾多,從縱向看,有國家級、部委級、省市級、以及各單位的資助項目;從橫向看,有攻關計劃、重大項目、重點項目、一般項目、青年項目、國際合作與交流項目等等,所以基金項目類型編碼同樣采用分層編碼的方式。如,縱向分別用1-3,9表示國家級、省部級、市級、其他;對國家級項目再劃分:國家自然科學基金項目、國家社會科學基金項目、國家863和973項目、國家其他項目計劃(如科技基礎條件平臺建設計劃、政策引導類科技計劃等),并分別用1-3,9表示;第三層再劃分重大項目、重點項目、專項項目、一般項目、青年項目、其他等。
同樣,部委級、省市級基金項目也可進一步劃分為:自然科學基金項目、社會科學基金項目等;第三層再劃分重大項目、重點項目、專項項目、一般項目和青年項目等。通過分層編碼,將眾多繁雜的基金項目進行了有序的歸類和標引,為進一步的分析比較以及深度的知識服務做好數據基礎。例如,通常情況下重大項目代表了各個研究領域的最前沿技術、最高的科研水準或國家、地區急需解決的科研問題。
通過對基金項目的編碼,我們可以很方便的調出有關基金項目的成果。例如,若想通過引文索引查找或統計所有國家級重大項目的科研成果,只需要利用基金類型編碼“1x1”對引文索引中來源文獻進行檢索即可以獲得。
5 結語
任何知識的創新都是在前人研究基礎上進一步努力的結果,沒有繼承就沒有創新。文獻間的引用填補了知識沿時間和空間的互補性需要。引文索引是對文獻信息資源進行管理的有效工具之一,經過50年的發展,引文索引對整個科學領域的研究產生了重要的影響,引文索引系統也逐步擺脫信息檢索的單一形象,在對期刊的評價、科研成果評價、人才的培養、學科的發展過程中都起到了關鍵的導向作用。
通過對國內多個引文索引系統的使用分析可以看到,目前我國引文索引建設還存在著明顯的不足:一是功能簡單,一般只提供檢索與簡單的統計分析功能;二是數據來源不同,檢索的結果差距較大,各索引系統因開發單位不同,存在重復勞動情況,沒有能夠形成類似于WOS的統一檢索平臺;三是深層次的知識服務功能還非常稀缺,數據的統計分析都是以文獻為單位,沒有能夠深入具體引用的內容部分,缺乏語義層面的分析。
有效的數據組織是進行知識服務的前提,引用關系是文獻間最普遍最直接的聯系,我們的任務不僅僅是表示這種關聯,更要能從引用中發現更多知識,提供深層次的知識服務。數據的組織是知識服務的基礎與關鍵,引文索引的研究不僅僅是個別人、個別單位的事情,應該是全社會集思廣益、不斷深入的過程,引文索引也不能是一個固定僵化的系統,要能夠適應社會的發展和人們知識需求的變化。
[1]馬智峰.參考文獻的引用及影響引用的因素分析[J].編輯學報,2009,21(1):23-25.
[2]郭麗芳.中外五大引文索引系統比較分析[J].現代圖書情報技術,2005,(1):36-39.
[3]王婧,華薇娜.國內外文科引文索引數據庫檢索功能比較[J].新世紀圖書館,2011,(1):42-44,73.
[4]蘇新寧.中國社會科學引文索引設計[J].情報學報,2000,19(4):290-295.
[5]蘇新寧.中文社會科學引文索引(CSSCI)的設計與應用價值[J].中國圖書館學報,2012,(38):95-102.
[6]紀蔚蔚.基于 Web引文索引數據庫建設方略[J].現代圖書情報技術,2004,(12):45-50.
[7]陳建青等.中文生物醫學期刊引文數據庫(CMCI)的研制特色[J].現代圖書情報技術,2005,(3):63-65.
[8]柴永紅.論信息服務與知識服務[J].情報雜志,2004,(4):74-75,78.
