領(lǐng)域Web文本采集與分類系統(tǒng)研究
2012-06-01 06:58:40洛陽(yáng)理工學(xué)院衛(wèi)莉莉
電子世界 2012年21期
洛陽(yáng)理工學(xué)院 衛(wèi)莉莉 王 煜
領(lǐng)域Web文本采集與分類系統(tǒng)研究
洛陽(yáng)理工學(xué)院 衛(wèi)莉莉 王 煜
本文以機(jī)械領(lǐng)域挖掘機(jī)為主題,介紹了一種面向領(lǐng)域的Web文本采集與分類系統(tǒng)實(shí)現(xiàn)方法,將專業(yè)詞庫(kù)與特征選擇相結(jié)合,逐步篩選和更新主題特征詞,擴(kuò)充專業(yè)詞庫(kù),通過(guò)由主題特征詞構(gòu)成的向量來(lái)明確表示主題;采用基于內(nèi)容分析的方法抽取網(wǎng)頁(yè)正文,去掉干擾主題相關(guān)度判斷與文本分類的廣告、導(dǎo)航等干擾文本;根據(jù)現(xiàn)有的機(jī)械主題類別信息,采用基于KNN的機(jī)械主題文本分類算法對(duì)文檔集合進(jìn)行多子類分類。
主題爬蟲(chóng);特征提取;文本分類;向量空間模型
1.引言
隨著互聯(lián)網(wǎng)的大規(guī)模普及和各行業(yè)信息化程度的提高,與行業(yè)領(lǐng)域相關(guān)的Web文本信息快速積累,如何從這些海量信息中定向提取符合需要的知識(shí),是當(dāng)前信息處理研究領(lǐng)域的一個(gè)研究熱點(diǎn),該問(wèn)題涉及到對(duì)領(lǐng)域Web文本信息的采集和對(duì)采集到的信息進(jìn)行處理和數(shù)據(jù)挖掘兩方面的內(nèi)容。在采集領(lǐng)域相關(guān)網(wǎng)頁(yè)的過(guò)程中,主題描述及網(wǎng)頁(yè)內(nèi)容的相關(guān)性判斷,都需要用到文本預(yù)處理技術(shù),信息采集成功后,又需要通過(guò)文本預(yù)處理和分類技術(shù)對(duì)領(lǐng)域文本進(jìn)行分類。本文對(duì)系統(tǒng)設(shè)計(jì)中的一些關(guān)鍵問(wèn)題進(jìn)行了研究,并以機(jī)械領(lǐng)域挖掘機(jī)為主題,實(shí)現(xiàn)了一個(gè)機(jī)械領(lǐng)域Web文本采集與分類原型系統(tǒng)。
2.主題爬蟲(chóng)的主題確立
對(duì)領(lǐng)域Web文本的采集,其實(shí)質(zhì)就是設(shè)計(jì)針對(duì)某一領(lǐng)域的網(wǎng)絡(luò)爬蟲(chóng)。專業(yè)領(lǐng)域用戶一般只關(guān)心與其領(lǐng)域相關(guān)的一些資源,垂直搜索,專精化,行業(yè)化。主題爬蟲(chóng)技術(shù)可根據(jù)一定的分析方法和搜索策略,選擇性的獲取與主題相關(guān)的Web頁(yè)面。主題爬蟲(chóng)系統(tǒng)一般包括種子模塊、主題確立模塊、爬蟲(chóng)爬行模塊和主題相關(guān)性分析模塊四個(gè)部分。設(shè)計(jì)高質(zhì)量主題爬蟲(chóng)的關(guān)鍵問(wèn)題是如何保證抓取的網(wǎng)頁(yè)中與主題無(wú)關(guān)的網(wǎng)頁(yè)盡可能的少,對(duì)待抓取的主題的準(zhǔn)確描述是設(shè)計(jì)主題網(wǎng)絡(luò)爬蟲(chóng)的首要任務(wù),也是一項(xiàng)關(guān)鍵任務(wù),這點(diǎn)對(duì)于主題相關(guān)性判斷影響重大。常用的主題描述方法一般有兩種,一種是根據(jù)人工經(jīng)驗(yàn),由用戶直接給出一組關(guān)鍵字來(lái)描述主題,這種方式簡(jiǎn)單,也比較準(zhǔn)確,但是對(duì)用戶的專業(yè)領(lǐng)域知識(shí)要求較高。
另外,當(dāng)知識(shí)更新較快時(shí),極有可能出現(xiàn)漏選的情況。另一種方法為主題代表性文檔特征抽取。通過(guò)用戶提供或者選擇一些相關(guān)主題的實(shí)例文檔,由爬蟲(chóng)從中提取用戶主題,其實(shí)質(zhì)是通過(guò)學(xué)習(xí)相關(guān)領(lǐng)域文檔并進(jìn)行自動(dòng)特征提取的過(guò)程。優(yōu)點(diǎn)是定義精確,但要求所選取的文檔和頁(yè)面必須具有代表性和概括性,否則可能出現(xiàn)偏差。
3.網(wǎng)頁(yè)正文提取研究
網(wǎng)頁(yè)正文提取是網(wǎng)頁(yè)解析模塊的一個(gè)難點(diǎn),也是最為核心的部分。大多數(shù)網(wǎng)頁(yè)中除了包含有用信息(正文)外,還包含網(wǎng)站導(dǎo)航信息、廣告、腳本語(yǔ)言等許多噪聲信息,如果提取不當(dāng),則提取結(jié)果可能慘不忍睹,根本沒(méi)有使用價(jià)值。只有真正提取出的正文文本,才是最有價(jià)值的,后續(xù)的網(wǎng)頁(yè)相關(guān)性判別和網(wǎng)頁(yè)文本分類才更加準(zhǔn)確。
目前已存在一些網(wǎng)頁(yè)正文提取的方法,比較典型的有基于Dom樹(shù);基于數(shù)據(jù)挖掘或機(jī)器學(xué)習(xí);基于模板、規(guī)則;基于網(wǎng)頁(yè)內(nèi)容分塊等。Dom樹(shù)方法雖直觀有效,但其樹(shù)的建立,要求html必須合乎規(guī)范,且時(shí)空復(fù)雜度高,樹(shù)的遍歷方法也不具通用性,需根據(jù)html標(biāo)簽的不同而變化。用數(shù)據(jù)挖掘或機(jī)器學(xué)習(xí)的方法來(lái)解決該問(wèn)題,又把簡(jiǎn)單問(wèn)題復(fù)雜化了。總體來(lái)說(shuō),這些方法大多不具備通用性,或?qū)崿F(xiàn)起來(lái)較為復(fù)雜,準(zhǔn)確度不高。
4.領(lǐng)域文本分類
領(lǐng)域文本具有不同于普通文本的特點(diǎn)。1)分詞困難。領(lǐng)域文本專業(yè)性較強(qiáng),常常包含大量的專業(yè)詞匯,這使得領(lǐng)域文本的分詞較普通文本而言更具復(fù)雜性。如何設(shè)計(jì)分詞算法,使得專業(yè)詞匯能夠盡可能小的不被劃分開(kāi)來(lái),對(duì)后續(xù)操作影響重大。通過(guò)設(shè)計(jì)專業(yè)詞庫(kù)可以解決這一問(wèn)題。專業(yè)詞庫(kù)的制定應(yīng)確保其權(quán)威性和完整性。本文中所采用的機(jī)械專業(yè)詞庫(kù)中的詞條主要來(lái)源于機(jī)械專業(yè)詞典、由機(jī)械設(shè)計(jì)制造研究人員收工錄入,還有部分來(lái)源于搜狗實(shí)驗(yàn)室,經(jīng)過(guò)選擇,去重得到的。2)已標(biāo)記樣本較少。在機(jī)械類別的文本中,由于沒(méi)有通用的用于機(jī)械領(lǐng)域文本分類研究的實(shí)驗(yàn)語(yǔ)料,本研究主要的語(yǔ)料來(lái)源為主題爬蟲(chóng)程序所采集到的網(wǎng)頁(yè)文本,一部分專業(yè)文檔資料和少量電子版用戶需求文檔。
5.領(lǐng)域web文本采集與挖掘系統(tǒng)設(shè)計(jì)
根據(jù)上述研究?jī)?nèi)容,本文設(shè)計(jì)了一個(gè)面向機(jī)械領(lǐng)域產(chǎn)品用戶需求信息的web文本采集與挖掘系統(tǒng)。系統(tǒng)結(jié)構(gòu)如圖1所示。

圖1 系統(tǒng)結(jié)構(gòu)圖

圖2 文本挖掘界面運(yùn)行圖
5.1 機(jī)械產(chǎn)品信息的主題描述
本系統(tǒng)主題描述步驟如下:
Step1.由領(lǐng)域?qū)<胰斯そo出一組主題詞及其對(duì)應(yīng)權(quán)值(t1,ω1:t2,ω2:……:tn,ωn)。本文附錄給出了一個(gè)由領(lǐng)域研究人員提供的機(jī)械領(lǐng)域?qū)I(yè)關(guān)鍵詞庫(kù),可以直接從里面篩選。
Step2.收集有代表性的主題相關(guān)度較高的文本文檔,進(jìn)行文本預(yù)處理,采用向量空間模型將文本表示出來(lái),對(duì)這些文本資料進(jìn)行特征選擇,獲得共同擁有的特征作為主題特征詞集合。這里的特征選擇方法采用基于關(guān)聯(lián)規(guī)則的專業(yè)特征選擇方法,通過(guò)改進(jìn)的灰色關(guān)聯(lián)公式進(jìn)行關(guān)聯(lián)度計(jì)算將多個(gè)文檔表示信息組合在一起,計(jì)算非專業(yè)術(shù)語(yǔ)與專業(yè)術(shù)語(yǔ)的灰色關(guān)聯(lián)度,獲得專業(yè)術(shù)語(yǔ)的關(guān)聯(lián)度矩陣;對(duì)關(guān)聯(lián)度矩陣進(jìn)行加權(quán)計(jì)算,提取出需求的專業(yè)術(shù)語(yǔ)得到專業(yè)的需求描述。
Step3.爬蟲(chóng)程序根據(jù)主題詞ti進(jìn)行爬行,采集與之相關(guān)的網(wǎng)頁(yè),對(duì)這些網(wǎng)頁(yè)進(jìn)行文本特征提取,選擇出權(quán)重高的特征詞,判斷是否已包含在專業(yè)特征詞庫(kù)中,若沒(méi)有,則加入專業(yè)特征詞庫(kù)。即更新主題候選詞集。
Step4.將得到的主題詞存放在topic.txt中。
通過(guò)以上步驟,得到主題特征。整個(gè)過(guò)程是一個(gè)不斷學(xué)習(xí)更新的過(guò)程,從而實(shí)現(xiàn)對(duì)主題詞集合的不斷擴(kuò)充,提高主題描述的精確度。
5.2 頁(yè)面采集模塊
通過(guò)HTTP,HtmlParser,Parser類對(duì)從待爬隊(duì)列waitingQueue取得的URL對(duì)應(yīng)的網(wǎng)頁(yè)解析,得到網(wǎng)頁(yè)上的所有鏈接并通過(guò)循環(huán)對(duì)鏈接對(duì)應(yīng)的網(wǎng)頁(yè)解析。首先通過(guò)MannerGahter類進(jìn)行禮貌采集判斷,服務(wù)器允許采集則可解析出網(wǎng)頁(yè)上的對(duì)應(yīng)P標(biāo)簽和Title標(biāo)簽的文檔信息,然后通過(guò)Segment類對(duì)文檔分詞。
對(duì)標(biāo)題及正文的特征項(xiàng)的選取是通過(guò)分詞后與主題集合匹配,并通過(guò)詞頻計(jì)算特征選擇來(lái)得到與主題向量維數(shù)相等的標(biāo)題向量和正文向量。
計(jì)算相關(guān)性。首先公式1計(jì)算兩個(gè)表示文本的向量之間的相似度。
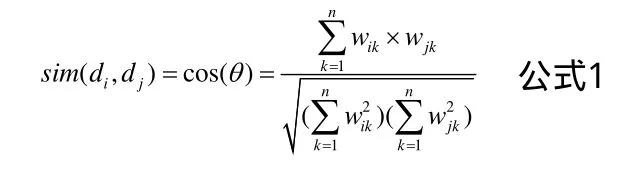
分別計(jì)算出主題和標(biāo)題、主題和正文的相關(guān)度,然后標(biāo)題與正文以4:1的比重計(jì)算出整個(gè)網(wǎng)頁(yè)與主題的相關(guān)度,即4*主題和標(biāo)題的相關(guān)度+1*正文與主題相關(guān)度。通過(guò)詳細(xì)計(jì)算,設(shè)定相關(guān)度閾值為75%,網(wǎng)頁(yè)與主題的相關(guān)度大于75%則認(rèn)為該網(wǎng)頁(yè)是與主題相關(guān)的。最后系統(tǒng)運(yùn)行界面如圖2所示。
6.結(jié)語(yǔ)
本文探討了面向領(lǐng)域的Web文本采集與分類問(wèn)題,對(duì)主題網(wǎng)絡(luò)爬蟲(chóng)設(shè)計(jì)中的主題確定,種子URL選擇、相關(guān)性分析、網(wǎng)頁(yè)解析與正文提取和搜索策略等問(wèn)題予以研究,分析行業(yè)領(lǐng)域文本的特點(diǎn),進(jìn)行恰當(dāng)?shù)闹黝}描述,選擇KNN算法來(lái)構(gòu)造領(lǐng)域文本分類器,設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)機(jī)械主題Web文本采集與分類原型系統(tǒng)。
[1]J.Han et al..Mining frequent patterns without candidate generation.In Proceedings of the 2000 ACM SIGMOD Conference on Management of Data,Dallas,TX,2000:1-12.
[2]魏松,鐘義信,王翔英.中文Web文本挖掘系統(tǒng)WebTextMiner開(kāi)發(fā)[J].計(jì)算機(jī)應(yīng)用研究,2005(6)211-213.
[3]沈記全,唐菁,楊炳儒.Web文本挖掘系統(tǒng)及其分類算法的研究與實(shí)現(xiàn)[J].計(jì)算機(jī)工程,2009.03(2):13-14.
[4]CHAKRABARTI S,BERG DEN VAN M.Focused Crawling:A new approach to Topic-Specif i c Web Resourse Discovery[C].In Proceedings of the 8th International WWW conference,Toronto,Canada,1999.
[5]劉國(guó)靖,康麗,羅長(zhǎng)壽.基于遺傳算法的主題爬蟲(chóng)策略[J].計(jì)算機(jī)應(yīng)用,2007,27(12):172-179.
[6]Chakrabati S,Punera K,Subram anyam M.Accelerated focused crawling through online relevance feedback,WWW2002,May 7-11,2002,Honolulu,Hawaii,USA.http//www.csberkeley.edu/-soumen/doc/www2002m/p336-chakrabarti.pdf(Accessed Nov.8,2006)
[9]M.Ehrig,A.Maedche.Ontology-focused Crawling of Web Documents.In Proceedings of the 2003 ACM symposium on Applied computing,Melbourne,Florida,June 2003:1174-1178.
河南省教育廳自然科學(xué)研究計(jì)劃項(xiàng)目(No.12B520033)。
衛(wèi)莉莉(1980—),碩士,講師,主要研究方向:數(shù)據(jù)挖掘,自然語(yǔ)言處理。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
當(dāng)代工人(2020年8期)2020-05-25 09:07:38
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小溪流(畫(huà)刊)(2017年12期)2018-01-10 16:07:29
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
科技知識(shí)動(dòng)漫(2016年8期)2016-07-29 20:40:09
兒童故事畫(huà)報(bào)·發(fā)現(xiàn)號(hào)趣味百科(2015年12期)2016-01-25 00:41:49
