基于支持向量機(jī)的結(jié)構(gòu)損傷識(shí)別研究*
2012-05-17 08:08:40吳思瑤姜紹飛傅大寶
海峽科學(xué) 2012年8期
吳思瑤 姜紹飛 傅大寶
?
基于支持向量機(jī)的結(jié)構(gòu)損傷識(shí)別研究*
吳思瑤 姜紹飛 傅大寶
福州大學(xué)土木工程學(xué)院
支持向量機(jī)(SVM)是一種針對分類和回歸問題的統(tǒng)計(jì)學(xué)習(xí)理論,能有效地解決模式識(shí)別中的分類問題。該文提出了基于支持向量機(jī)的結(jié)構(gòu)損傷識(shí)別方法:以歸一的頻率變化比()和歸一的損傷指標(biāo)()作為特征參數(shù),訓(xùn)練支持向量機(jī)進(jìn)行損傷識(shí)別。用一個(gè)12層鋼混框架有限元數(shù)值模型進(jìn)行驗(yàn)證,同時(shí)分析了影響SVM模型性能的主要因素。結(jié)果表明,本文提出的方法具有較高的損傷識(shí)別能力,而核參數(shù)的選擇對識(shí)別精度有較大影響。
支持向量機(jī) 損傷識(shí)別 核函數(shù) 參數(shù)選擇
近年來,建筑物使用性能的退化和各種災(zāi)害的頻繁發(fā)生,使得對大型結(jié)構(gòu)進(jìn)行健康監(jiān)測和安全性評(píng)估成為國內(nèi)外研究的熱點(diǎn)。結(jié)構(gòu)健康監(jiān)測系統(tǒng)的研發(fā)雖然為之提供了保障,但是如何利用海量、不確定的數(shù)據(jù),進(jìn)而尋求有效的損傷識(shí)別方法仍是急需解決的難題。
由Vapnik的統(tǒng)計(jì)學(xué)習(xí)理論[1]發(fā)展而來的支持向量機(jī)克服了人工神經(jīng)網(wǎng)絡(luò)的局限性且具有結(jié)構(gòu)簡單、推廣能力好等優(yōu)點(diǎn),能夠解決非線性、高維數(shù)問題,已被成功地應(yīng)用于模式識(shí)別的眾多領(lǐng)域,如交通異常診斷[2]、文本識(shí)別[3]、人臉檢測[4]等。基于此,本文提出了一種基于支持向量機(jī)的損傷識(shí)別方法,并用一個(gè)數(shù)值算例驗(yàn)證了所提方法的有效性,探討了噪聲、核函數(shù)及核參數(shù)的選擇對SVM模型性能的影響。
1 基本原理
支持向量機(jī)(SVM)[5]是一種針對分類和回歸問題的統(tǒng)計(jì)學(xué)習(xí)理論,能有效解決模式識(shí)別中的分類問題。通過在支持向量機(jī)中引入核函數(shù),將輸入空間的非線性可分的訓(xùn)練樣本集映射到高維特征空間,再在其中求得最優(yōu)分類面來分離訓(xùn)練樣本點(diǎn),可以有效解決非線性分類問題。
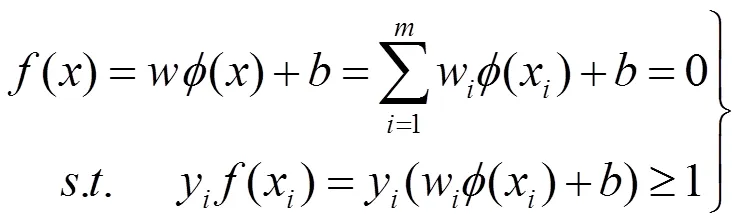

式中:為懲罰參數(shù),表示訓(xùn)練模型對錯(cuò)分樣本的懲罰程度,越大,則對數(shù)據(jù)的擬合程度越高,但泛化能力將降低,當(dāng)C增加到一定值后,泛化能力不再隨C的變化而變化。
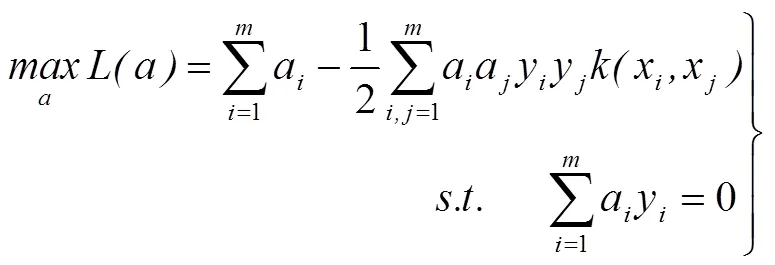

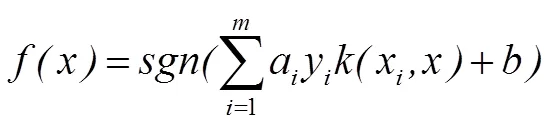
以上可以解決SVM的二分類問題,而SVM的多分類問題(分類,>2)是以二分類問題為基礎(chǔ)的,主要有一對一、一對多和有向無環(huán)圖方法。本文采用的是一對一的方法,就是在樣本中構(gòu)造所有可能的2類分類器,共(一1)/2個(gè),對未知樣本進(jìn)行測試時(shí),分別使用(一1)/2個(gè)分類器對其進(jìn)行判別,并采取MaxWins投票策略,即如果屬于第類,則在第類的投票上加1,否則在第類的投票上加1,直到所有分類器分類完成,得票最多的類為測試樣本所屬的類。
核函數(shù)的選擇和參數(shù)的確定是支持向量機(jī)的核心內(nèi)容,不同的核函數(shù)和參數(shù)將產(chǎn)生不同的分類效果。本文所用的核函數(shù)有:
線性核函數(shù)(LKF):

高斯徑向基核函數(shù)(RBF):

2 結(jié)構(gòu)損傷識(shí)別方法
本文提出了一種4階段結(jié)構(gòu)損傷識(shí)別方法,包括數(shù)據(jù)預(yù)處理、特征參數(shù)提取、SVM分類和結(jié)果輸出(見圖1)。

圖1 結(jié)構(gòu)損傷識(shí)別方法
2.1 數(shù)據(jù)預(yù)處理與特征參數(shù)提取
為了消除測量數(shù)據(jù)中包含的噪聲和誤差,在預(yù)處理階段,將采集到的信號(hào)進(jìn)行數(shù)模變換,再用閾值法、平均法等技術(shù)來進(jìn)行初步處理。
特征參數(shù)在結(jié)構(gòu)健康監(jiān)測和損傷識(shí)別中發(fā)揮著重要作用。為此,在特征提取階段,本文采用歸一的頻率變化比(和歸一的損傷指標(biāo)(作為特征參數(shù)[6]:
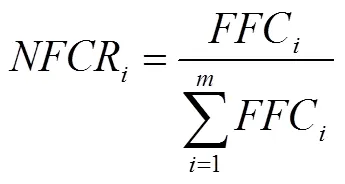

2.2 SVM分類和結(jié)果輸出
(1)選擇合適的核函數(shù),并確定懲罰參數(shù)和相應(yīng)核參數(shù)的值。
(2)利用libsvm工具箱[7],用訓(xùn)練樣本對SVM進(jìn)行訓(xùn)練,得到模型文件。
(3)應(yīng)用訓(xùn)練好的SVM模型對檢驗(yàn)樣本進(jìn)行檢驗(yàn),并輸出識(shí)別結(jié)果。
3 數(shù)值算例
3.1 12層鋼筋混凝土框架
應(yīng)用SM Solver建立一個(gè)12層鋼混框架模型(見圖2),圖2中的數(shù)字為節(jié)點(diǎn)編號(hào)。底層柱與地面為剛性連接,梁柱節(jié)點(diǎn)為剛性連接,每個(gè)節(jié)點(diǎn)具有三個(gè)自由度,分別為水平、豎向和轉(zhuǎn)動(dòng)方向。彈性模量=3×104MPa,泊松比=0.3,密度=2500kg/m3。柱截面500mm×500mm,慣性矩I=5.21×109mm4,質(zhì)量m=625kg/m;梁截面250mm×600mm,慣性矩I=4.5×109mm4,質(zhì)量m=375kg/m。通過減少柱的剛度來模擬損傷,共三種損傷模式。模式1:節(jié)點(diǎn)1、2間柱單元?jiǎng)偠冉档?5%;模式2:節(jié)點(diǎn)34、35間柱單元?jiǎng)偠冉档?5%及節(jié)點(diǎn)1、2間柱單元?jiǎng)偠冉档?%;模式3:節(jié)點(diǎn)34、35間柱單元?jiǎng)偠冉档?5%。

圖2 12層鋼混框架模型
通過SM Solver計(jì)算出模型健康和損傷時(shí)的前12階頻率及第一振型在12個(gè)節(jié)點(diǎn)(2、4、6、13、19、24、31、35、38、25、33、30)的水平、豎向、轉(zhuǎn)動(dòng)位移分量,按照以下公式添加噪聲:


每一個(gè)模式隨機(jī)產(chǎn)生200個(gè)測量數(shù)據(jù)集,前100個(gè)用來訓(xùn)練分類器模型,后100個(gè)則用來檢驗(yàn)?zāi)P停瑒t每個(gè)噪聲水平分別產(chǎn)生300個(gè)訓(xùn)練和檢驗(yàn)?zāi)B(tài)參數(shù)樣本。
3.2 損傷識(shí)別模型的建立
特征參數(shù)提取:對添加噪聲后的模態(tài)參數(shù)樣本,按照式(7)、(8)生成和,得到48個(gè)特征參數(shù),所以訓(xùn)練和檢驗(yàn)樣本的大小分別為300×48。
SVM模型建立:利用libsvm工具箱[7],核函數(shù)選用RBF核函數(shù),設(shè)置誤差懲罰參數(shù)=10,核參數(shù)=0.01,然后將訓(xùn)練樣本輸入SVM進(jìn)行訓(xùn)練。這樣,RBFSVM模型便訓(xùn)練完成。
結(jié)果輸出:將檢驗(yàn)樣本輸入SVM模型進(jìn)行識(shí)別,便可得到分類結(jié)果。其中,檢驗(yàn)樣本與訓(xùn)練樣本具有相同的噪聲水平。
3.3 識(shí)別結(jié)果與比較
3.3.1識(shí)別結(jié)果
用損傷識(shí)別精度()定義檢驗(yàn)樣本中正確識(shí)別的樣本數(shù)和全部檢驗(yàn)樣本數(shù)量的比率,各噪聲水平下的識(shí)別結(jié)果見表1。

表1 檢驗(yàn)樣本識(shí)別結(jié)果(RBFSVM)
可以看出,支持向量的個(gè)數(shù)隨著噪聲水平的增加而逐漸增多,表明SVM模型的復(fù)雜程度提高了;檢驗(yàn)樣本的平均識(shí)別精度隨著噪聲水平的提高呈現(xiàn)下降的趨勢,模式1、3的樣本相互錯(cuò)分。其中,模式1被錯(cuò)分到模式3的比例為0%(=0.2%)、0%(=1.0%)、4%(=1.8%)、12%(=2.6%)、25%(=3.6%)、17%(=4.0%);模式3被錯(cuò)分到模式1的比例為0%(=0.2%)、0%(=1.0%)、3%(=1.8%)、1%(=2.6%)、11%(=3.6%)、18%(=4.0%)。這是由于模式1屬于小損傷,頻率和模態(tài)都與無損傷時(shí)非常接近,因此對噪聲的敏感程度要比其它兩種模式大,模式3屬于中損傷,加噪后各樣本的特征參數(shù)變化不大,這樣就造成模式1和模式3的樣本在加噪后變得相似,從而導(dǎo)致了模式1、3的樣本相互錯(cuò)分。而模式2屬于大損傷,對噪聲的敏感程度最小,所以識(shí)別精度都很高,當(dāng)噪聲程度較小時(shí)(=0.2%、=1.0%、=1.8%),識(shí)別精度為100%;當(dāng)噪聲程度較大時(shí)(=2.6%、=3.6%、=4.0%),模式1、3各樣本的特征參數(shù)變化大于模式2的樣本,造成模式2的個(gè)別樣本和其它兩種模式的樣本在加噪后變得相似,從而導(dǎo)致了模式2的個(gè)別樣本被錯(cuò)分到模式1或模式3中。
3.3.2比較與討論
下面對影響SVM模型性能的幾個(gè)主要因素進(jìn)行分析。
3.3.2.1 噪聲水平
噪聲水平不同,各損傷模式下特征參數(shù)的可區(qū)分性也不一樣,特征參數(shù)的二維平面投影圖,可以在一定程度上反映3種損傷模式的可區(qū)分性。選取噪聲水平為0.2%、1.8%、4.0%的檢驗(yàn)樣本,分別提取第一、第二主成分,觀察樣本的可分性,如圖3所示。

可以看出:當(dāng)噪聲水平比較小(=0.2%)的時(shí)候,3種損傷模式的主成分比較容易區(qū)分,所以SVM模型的識(shí)別精度很高。但是隨著噪聲水平的增加(=1.8%、=4.0%),各主成分開始出現(xiàn)相互滲透的現(xiàn)象,從而增加了損傷識(shí)別的復(fù)雜程度,這就是識(shí)別精度會(huì)隨著噪聲水平的增加而降低的原因。
3.3.2.2 SVM核函數(shù)選擇
為了分析SVM核函數(shù)對SVM模型性能的影響,采用線性核函數(shù)進(jìn)行比較。按照3.2節(jié)中的步驟,核函數(shù)選擇線性核函數(shù),設(shè)置誤差懲罰參數(shù)=10,然后建立LKFSVM模型并對檢驗(yàn)樣本進(jìn)行預(yù)測。各噪聲水平下的識(shí)別結(jié)果見表2和圖4。

表2 檢驗(yàn)樣本識(shí)別結(jié)果(LKFSVM)

圖4 檢驗(yàn)樣本識(shí)別結(jié)果
與表1比較可知,在相同噪聲水平時(shí),LKFSVM模型的支持向量數(shù)都少于RBFSVM模型,分別減少了38個(gè)(=0.2%)、71個(gè)(=1.0%)、81個(gè)(=1.8%)、103個(gè)(=2.6%)、108個(gè)(=3.6%)、97個(gè)(=4.0%),表明RBF核函數(shù)的復(fù)雜程度明顯大于線性核函數(shù);但是,在相同噪聲水平時(shí),除了=0.2%、=1.0%的情況,LKFSVM模型的識(shí)別精度都低于RBFSVM模型,分別降低了2.00%(=1.8%),5.33%(=2.6%),6.00%(=3.6%)、8.00%(=4.0%)。有關(guān)研究表明[8],無論低維、高維,大樣本還是小樣本,RBF核函數(shù)均具有較好的識(shí)別能力。因此,一般SVM分類模型中首選RBF核函數(shù)。
3.3.2.3 SVM參數(shù)選擇
為了分析懲罰參數(shù)對識(shí)別精度的影響,本文選取了噪聲水平在1.0%、2.6%和4.0%時(shí)的樣本,按照本文3.2節(jié)中的步驟,設(shè)置不同的懲罰參數(shù),分別建立RBFSVM模型和LKFSVM模型(=0.01),并對檢驗(yàn)樣本進(jìn)行預(yù)測,識(shí)別結(jié)果見表3。

表3 懲罰參數(shù)C對分類精度的影響
可以看出,懲罰參數(shù)對LKFSVM模型和RBFSVM模型的分類精度影響較小。當(dāng)取0.1、1、10、100、1000時(shí),LKFSVM模型識(shí)別精度的最大差值分別為0.00%(=1.0%)、6.67%(=2.6%)、2.66%(=4.0%);RBFSVM模型識(shí)別精度的最大差值分別為1.33%(=1.0%)、5.33%(=2.6%)、6.34(=4.0%)。
為了分析RBF的核參數(shù)對識(shí)別精度的影響,本文選取了噪聲水平在1.0%、2.6%和4.0%時(shí)的樣本,按照本文3.2節(jié)中的步驟,設(shè)置不同的核參數(shù),建立RBFSVM模型(=10),并對檢驗(yàn)樣本進(jìn)行預(yù)測,識(shí)別結(jié)果見表4。

表4 核參數(shù)g對分類精度的影響
可以看出,核參數(shù)對RBFSVM模型的分類精度有較大影響。當(dāng)取0.001、0.01、0.1、1、10、100、1000時(shí),其識(shí)別精度的最大差值分別為66.67%(=1.0%)、61.67%(=2.6%)、52.34%(=4.0%)。原因是核參數(shù)的改變實(shí)際上是隱含地改變映射函數(shù),從而改變樣本數(shù)據(jù)子空間分布的復(fù)雜程度,進(jìn)而影響識(shí)別精度的大小。
3.3.2.4 對比BPN模型
為了分析SVM模型的識(shí)別能力,建立BP神經(jīng)網(wǎng)絡(luò)模型進(jìn)行比較。BPN模型的建立過程與SVM模型相似,只是把SVM模型中的SVM分類換成了BP神經(jīng)網(wǎng)絡(luò)分類。LKFSVM模型、RBFSVM模型和BPN模型的識(shí)別結(jié)果見圖4。
可以看出,RBFSVM模型的識(shí)別精度最高,LKFSVM模型次之,BPN模型最低。BPN模型的識(shí)別精度比RBFSVM模型分別降低了0.00%(=0.2%),0.67%(=1.0%),2.34%(= 1.8%),8.67%(=2.6%),11.66%(=3.6%),13.67%(=4.0%)。且BP神經(jīng)網(wǎng)絡(luò)的計(jì)算結(jié)果與隱層神經(jīng)元個(gè)數(shù)、隱層層數(shù)、初始閾值和權(quán)值有很大的關(guān)系,但這些參數(shù)目前還沒有很好的方法能夠確定。
4 結(jié)論
(1)本文提出的損傷識(shí)別方法具有良好的分類和抗噪聲能力。
(2)在SVM分類模型中,首選RBF核函數(shù)。通過本文的研究和數(shù)值分析發(fā)現(xiàn),懲罰參數(shù)的選擇對SVM的分類性能影響較小,而核參數(shù)的選擇對模型的分類精度影響較大。
可見,本文提出的基于支持向量機(jī)的損傷識(shí)別方法,充分發(fā)揮了其優(yōu)點(diǎn),在結(jié)構(gòu)損傷識(shí)別領(lǐng)域?qū)?huì)有良好的前景。數(shù)值算例初步證明了該方法的可行性和有效性,但還需要更多的試驗(yàn)結(jié)果和工程實(shí)踐來檢驗(yàn)。同時(shí),在SVM參數(shù)的選擇方面,許多研究者給出了不同的方法[5,9],通過對SVM參數(shù)的合理選擇,不僅可以提高SVM模型的識(shí)別能力和推廣能力,而且還可以大大降低模型的復(fù)雜度和計(jì)算成本。因此,需要進(jìn)一步研究更有效的SVM參數(shù)優(yōu)化方法。
[1] Vapnik Vladimir N. The Nature of Statistical Learning Theory[M]. Springer-Verlag, New York, Inc, 2000.
[2] Zhang B, Yang J H, Wu J P, et al. Diagnosing Traffic Anomalies Using a Two-Phase Model[J]. Journal of Computer Science and Technology, 2012, 27(2): 313-327.
[3] 劉斌, 張楠. 基于LS-SVM的在線文本識(shí)別方法[J]. 微電子學(xué)與計(jì)算機(jī), 2009, 26(3): 192-199.
[4] Pu X R, Zhou Y, Zhou R Y. Face Recognition on Partial and Holistic LBP Features[J]. Journal of Electronic Science and Technology, 2012, 10(1): 56-60.
[5] 楊娜. 基于統(tǒng)計(jì)理論的結(jié)構(gòu)非線性特征提取與結(jié)構(gòu)損傷識(shí)別方法研究[D]. 福州: 福州大學(xué), 2011: 18-41.
[6] 姜紹飛. 基于神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)優(yōu)化與損傷檢測[M]. 北京: 科學(xué)出版社, 2002.
[7] Chang C C, Lin C J. LIBSVM: a Library for Support Vector Machines[EB/OL]. http://www.csie.ntu.edu.tw/~cjlin/libsvm, 2009-02-27.
[8] 范瑞雅. 支持向量機(jī)核函數(shù)的參數(shù)選擇方法[D]. 重慶:重慶大學(xué), 2011: 4-18.
[9] 董春曦, 饒鮮, 楊紹全, 等. 支持向量機(jī)參數(shù)選擇方法研究[J]. 系統(tǒng)工程與電子技術(shù), 2004, 26(8): 1117-1120.
國家自然科學(xué)基金項(xiàng)目(50878057);國家“十二五”科技支撐計(jì)劃(2012BAJ14B05);高等學(xué)校博士點(diǎn)基金項(xiàng)目(20093514110005)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
