改進的快速復值FastICA算法研究
2012-03-12 03:38:20趙立權于軾群
東北電力大學學報 2012年2期
關鍵詞:信號
趙立權,于軾群
(1.東北電力大學信息工程學院,吉林吉林132012;2.中國聯通哈爾濱分公司,哈爾濱150001)
獨立分量分析(Independent Component Analysis,ICA)是解決盲源分離問題的主要方法之一,它僅利用信源信號非高斯相互統計獨立的假設條件,從接收到的混合信號中估計出信源信號。復值ICA算法是針對復值域信號的一種新的信號處理方法,目前主要應用于盲解卷積、無線通信、功能性核磁圖像處理、陣列信號處理等方面[1-4]。隨著ICA算法理論的逐漸發展和成熟,近些年來,復值ICA算法受到了越來越多學者的廣泛關注,涌現出許多優秀的算法[3-11]。復值快速獨立分量分析(Fast Independent Component Analysis,FastICA)一種典型的批處理固定點復值ICA算法[5],后來的許多復值ICA算法都是在它的基礎之上發展起來的,典型的改進算法就是基于Huber M估計函數的復值ICA算法[7],該算法相對原算法性能更好,為了進一步提高算法的性能,本文從復值ICA代價函數所采用的非線性函數角度出發,對穩健性更好Tukey雙權函數進行修正后作為代價函數的非線性函數,推導出運算速度更快的改進的復值ICA算法。
1 復值ICA數學模型
復值ICA的基本數學模型如下:

ICA的基本假設條件只是為了保證ICA算法有解,但是畢竟信源信號S和混合矩陣A都未知,因此通過ICA算法得到的信源信號的估計Y相對信源信號S存在一定的不確定性。例如式(1)可以寫成如下形式:
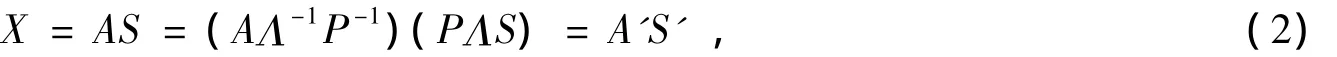
式中:Λ=diag(a1ejθ1,a1ejθ2,…,anejθn),an和θn為任意不為零的值;Λ-1是Λ的逆矩陣;P是任意可逆的單位置換矩陣;P-1是P的逆矩陣。矩陣Λ和P是任意的,那么得到A'=AΛ-1P-1和S'=PΛS也是任意的,但是A'S'得到的混合信號X是固定的,所以復值ICA對接收到的信號X進行分離,得到的對信源信號的估計信號可能是S'或者S,S'和S的幅度、相位和順序不一樣,因此產生了復值ICA對信源信號估計的不確定性。在ICA研究中,人們更多關注的是信號的波形,只要分離信號和信源信號的波形一樣,就認為算法是有效的。
2 復值FastICA算法
復值FastICA算法是由赫爾辛基工業大學的Bingham和Hyv?rine仿照實值FastICA算法,提出的一種經典的針對復數信號ICA算法[5]。該算法是一種批處理的固定點迭代算法,算法不需要設置學習速率,收斂速度快。
復值FastICA算法和其它批處理ICA方法一樣,都需要對接收數據進行預處理。設n維接收信號X=[x1,x2,…,xn]T,為了簡便,假設接收信號X經過預處理后得到的白化信號為Z=BX,B為白化矩陣。對于白化后的信號的盲分離,復值FastICA算法選擇“自下而上”的ICA方法構造代價函數,在代價函數中采用非線性函數近似高階統計量。其代價函數定義為:

式中:G為非線性函數;W=[w1,w2,…,wn]T為n維的復值分離向量;Z為白化后的信號滿足E{ZZH}=I。在復值獨立分量分析中一般假設信源信號的幅值為1,WHZ是對信源信號的估計,因此也應滿足幅值為1的條件,即E{WHZ2}=E{WHZZHW}=WHW=1,W滿足歸一化條件。
在E{WHZ2}=WHW=I的約束條件下,復值FastICA算法代價函數為:
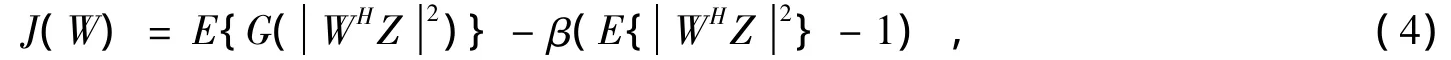
式中:β為拉格朗日乘子;采用牛頓迭代算法對代價函數式(4)進行優化,得到分離向量的迭代公式:
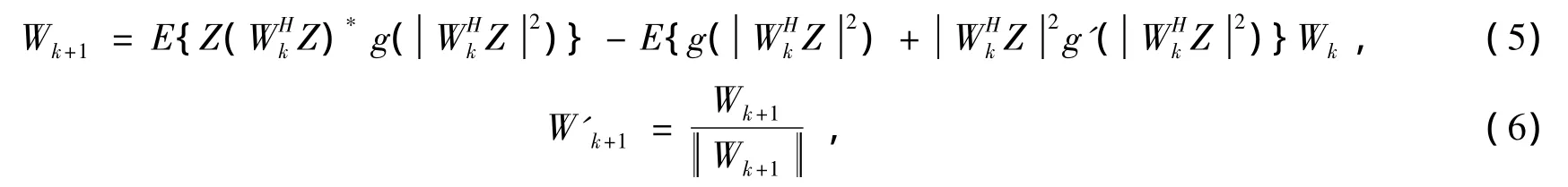
式中:g是G的導數,g'是g的導數。可選擇的三種非線性函數的具體表示式如下[5]:
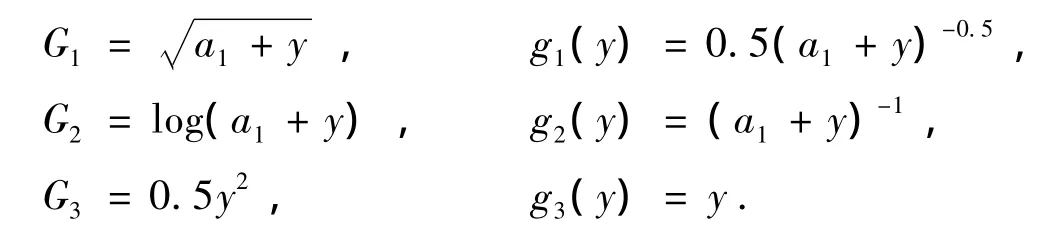
3 改進的復值FastICA算法
復值FastICA算法的穩健性好壞取決于所采用的非線性函數,為了提高算法性能,文獻[7]提出了一種改進的復值FastICA算法,該算法采用Huber M估計函數作為代價函數中的非線性函數,相對原FastICA算法穩健性更好。其所采用的Huber M估計函數及其一、二階導數表達式如下:
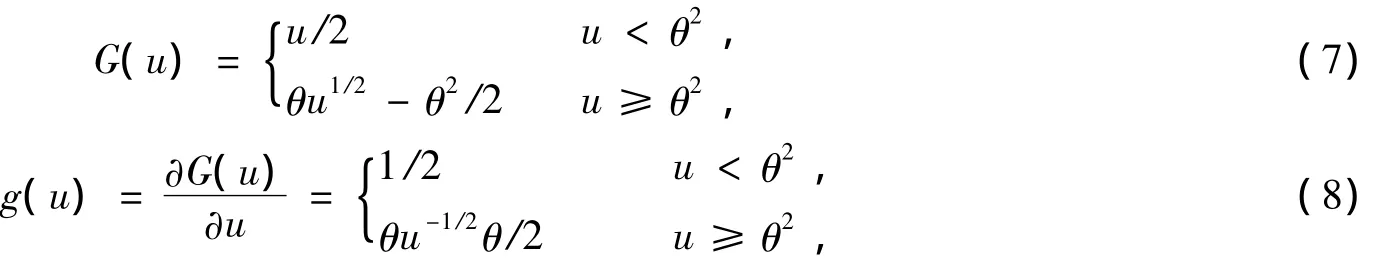
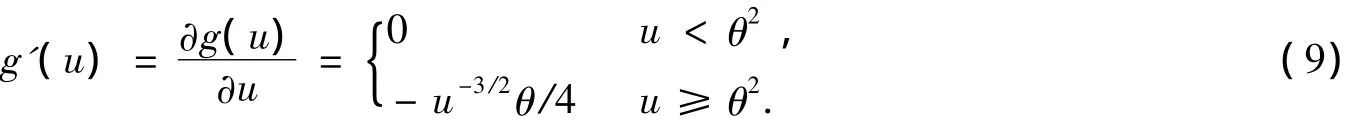
雖然文獻[7]中采用的非線性函數結構簡單,但是由于其二階導數中存在求矩陣的逆,即“u-3/2”項,工程上實現矩陣逆運算比較復雜,而且增加了計算量。
為了避免矩陣求逆運算,減少計算量,提高算法運算速度,本文采用Tukey函數作為代價函數中的非線性函數[12]。在式(3)和式(5)式中,非線性函數均以估計函數的平方作為變量,為此本文對Tukey函數進行修正,將原變量看作是修正后變量的平方,即修正后的Tukey函數為

其中:g(u)和g'(u)分別為G(u)的一階和二階導數。從上式數學表達式可以看出,修正后的Tukey函數的導數不含有矩陣求逆運算,因此減少了計算量。
圖1是Tukey函數和Huber函數及其一階和二階導數,其中Tukey函數閾值a=2,Huber函數閾值θ=0.9(文獻[7]中取θ=0.9性能比較理想)。從圖中可以看出,Tukey函數及其導數在超過閾值后為常數,因此對超過閾值的奇異值點有較好抑制性。而Huber函數超過閾值后為直線,因此對奇異值點抑制性能較差。
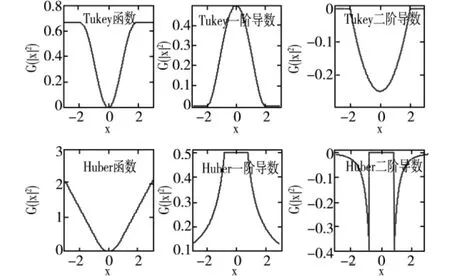
圖1 非線性函數及其導數
4 實驗仿真和結果分析
實驗仿真中,采用獨立分量分析算法中常用的
性能指標(Performance Index,PI)作為評價函數,用來度量算法誤差大小的標準,其具體表達式如下:
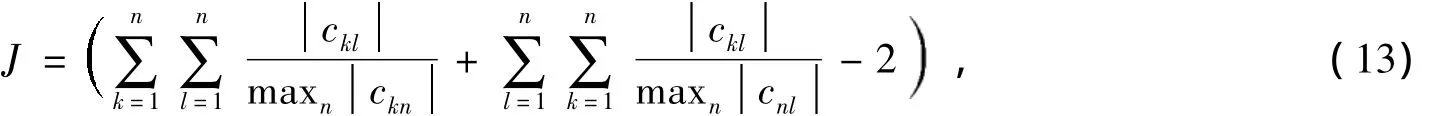
式中:C=WHBA,W是白化后信號的分離矩陣,B是白化信號,A是混合矩陣。性能指標J的取值越小,表示分離誤差越小。
實驗1驗證算法的有效性。
信源信號為一個exp(j100πt)、一個BPSK信號和一個QAM信號,采樣點為1 000點,隨機產生復值混合矩陣A為:

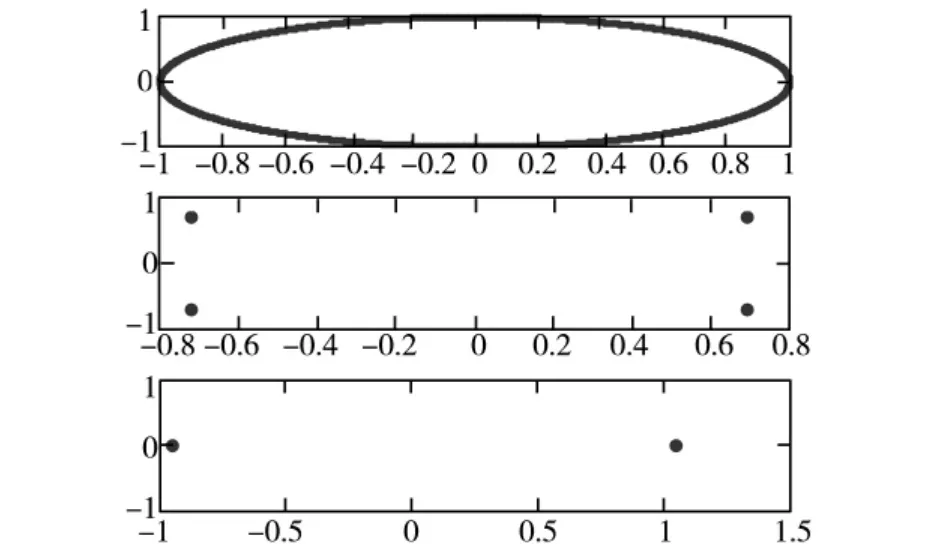
圖2 信源信號
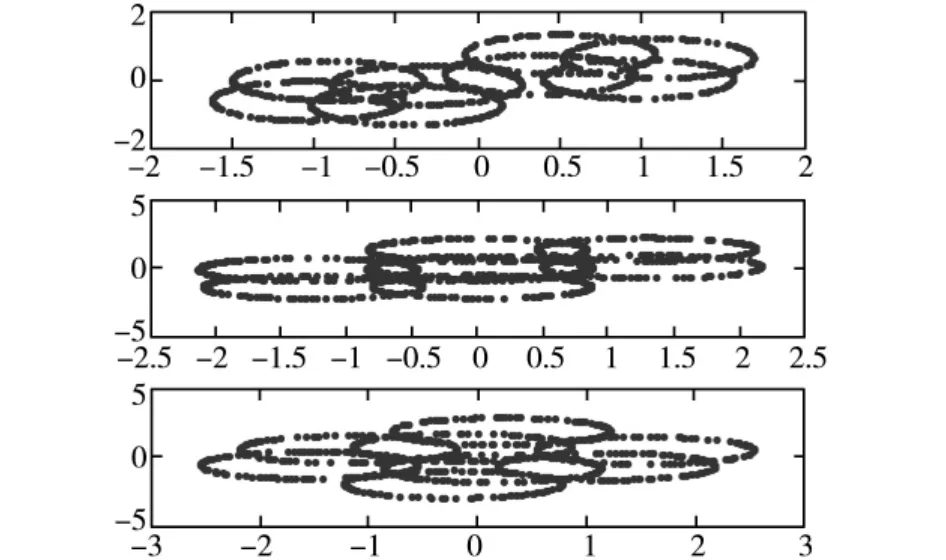
圖3 復值混合信號
圖2是信源信號的波形圖,圖3是混合信號,圖4是從復值混合信號中分離出的信號,即信源信號的估計信號。圖4第一個圖和圖2的第二個圖對應、圖4的第二個圖和圖2的第三個圖對應、圖4的第三個圖和圖2的第一圖對應。對比圖4和圖2可以看出,分離信號和信源信號波形基本一樣,證明了算法的是有效的,同時二者之間存在順序、相位的不確定性,該不確定性是復值ICA固有不確定性,通過進一步處理后并不影響實際應用。
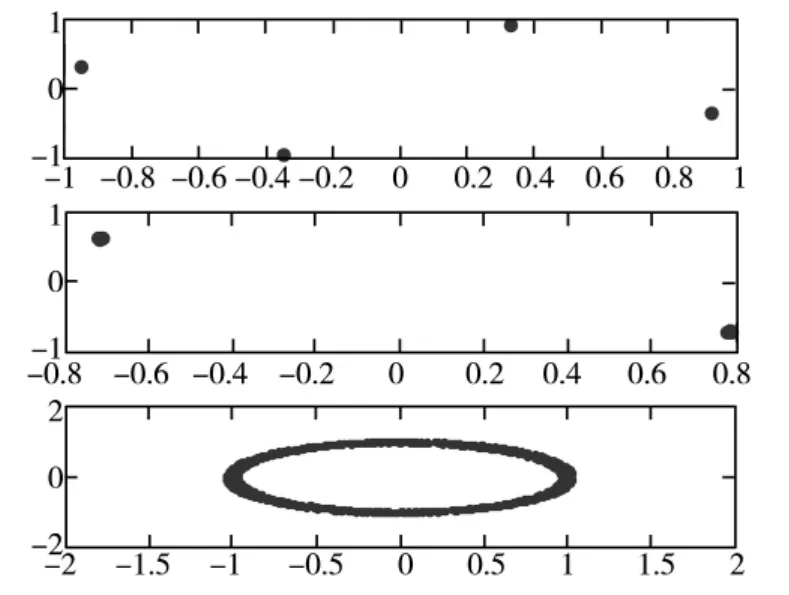
圖4 信源信號的估計信號
實驗2驗證算法的性能。
為了從統計角度驗證算法的性能,在實驗1信源信號的基礎上,進行1 000次運算取平均值,每次運算的復值混合矩陣都隨機產生,其中基于Huber函數的FastICA算法門限值取θ=0.9,原FastICA算法采用G1(y)=(a+y)0.5,因為文獻[7]仿真證明此時這個兩種算法性能比較好。本文提出的基于Tukey函數的FastICA算法門限取。
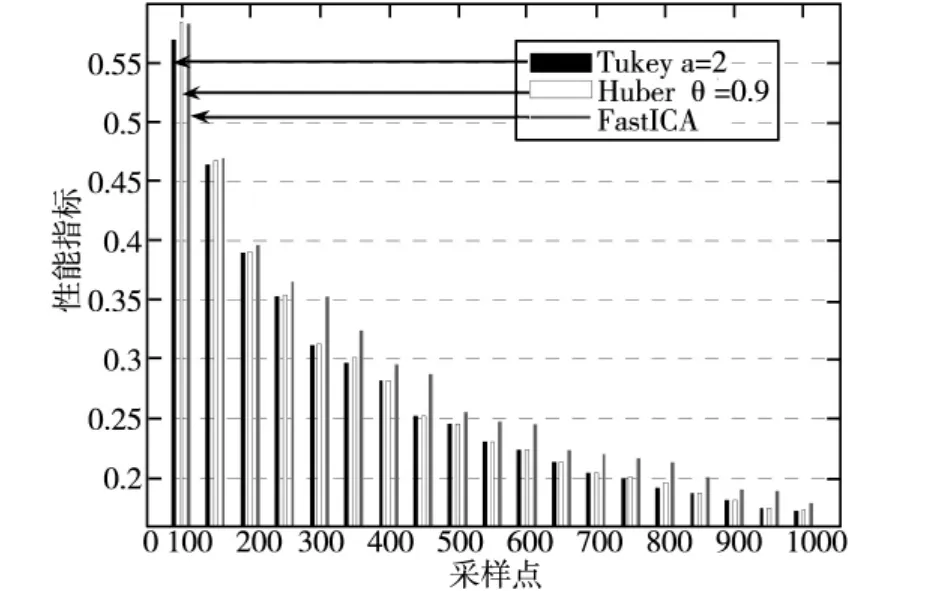
圖5 采樣與性能指標直方圖
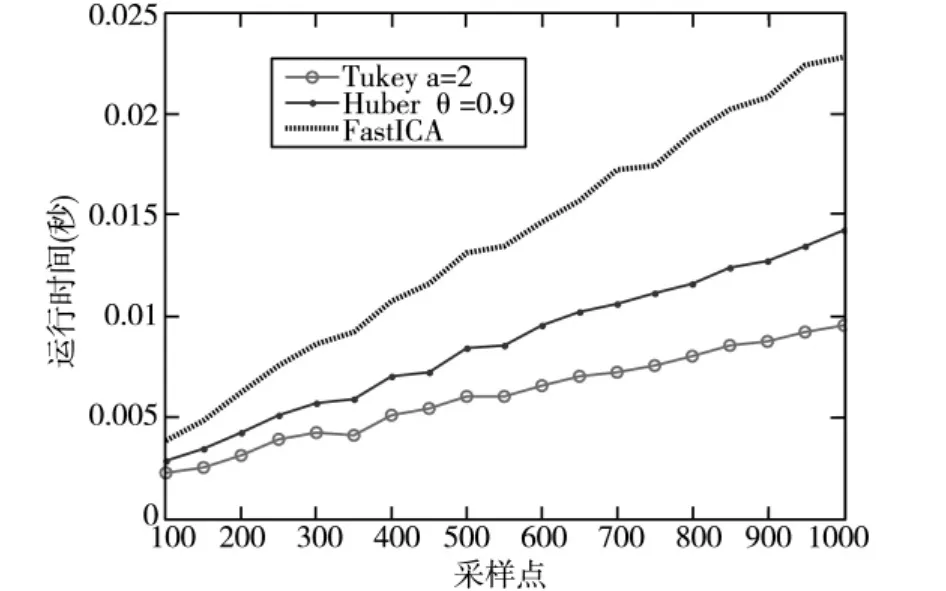
圖6 采樣點與運行時間關系曲線
圖5是采樣點與性能指標關系直方圖。從圖中可以看出,在較低采樣點時本文提出基于Tukey函數的復值ICA算法誤差新能要好于其它算法,但是隨著采樣點數量的增加,本文算法誤差性能與基于Huber函數的復值ICA算法基本一樣,但是始終都比原FastICA算法性能要好。
圖6是得到圖5性能時算法收斂所需的平均運行時間與采樣點關系曲線,從曲線可以看出三種算法中,本文算法的運行時間最短,證明了本文算法的計算量小。綜合圖5和圖6可得,本文算法誤差性能與基于Huber函數的復值ICA算法性能相當,但是比其運行時間短,也就是計算量小。而且在低采樣時,本文算法誤差最小。
4 結束語
本文在復值FastICA算法的基礎上,提出了一種改進的復值FastICA算法。本文算法誤差性能好于原復值FastICA算法,與基于Huber函數的復值ICA算法相比,本文算法在采樣點較少時誤差性能更好,大采樣點時基本一樣,但是本文算的運算時間明顯小于原FastICA算法及基于Huber函數的復值ICA算法,即本文算法的計算量更小。
[1]H Li,M Correa.Application of Independent component analysis with adaptive density model to complex-valued FMRI data[J].IEEE Transactions on biomedical engineering,2011,58(10):2794-2803.
[2]L Wang,H Ding,F Yin.Combining superdirective beamforming and frequency-domain blind source separation for highly reverberant signals[J].EURASIP Journal on Audio,Speech,and Music Processing,2010(1):1-13.
[3]H shen,M Kleinsteuber.Complex blind source separation via simultaneous strong uncorrelating transform[C].LVA/ICA'10 Proceedings of the 9th international conference on Latent variable analysis and signal separation.Belin Heidelberg,2010:287-294.
[4]付衛紅,楊小牛,劉乃安,等.通信偵查中通信復信號的盲源分離算法[J].四川大學學報,2008,40(1):118-121.
[5]E Bingham,E Hyvarinen.A fast fixed-point algorithm for independent component analysis of complex valued signals[J].Internation Journal of Neural Neural Systems,2000,10(1):1-8.
[6]Eriksson J,Koivunen V.Complex random vectors and ICA models:identifiability,uniqueness,and separability[J].IEEE Transactions on Information Theory,2006,52(3):1017-1029.
[7]C Jih-cheng,S Douglas.A Robust complex FastICA algorithm using the Huber M-Estimator Cost function[C].ICA2007,UK,London,2007:152-160.
[8]S Javidi,P Mandic.Complex blind source extraction form noisy mixtures using second-order statistics[J].IEEE transaction on circuits and systems,2010,57(7):1404-1416.
[9]Novey M.Adali T.Complex ICA by Negentropy Maximization.Neural Networks[J].IEEE Transactions on neural networks,2008,19(4):596-609.
[10]付衛紅,楊小牛,劉乃安,等.基于變步長最優化的EASI盲源分離算法[J].四川大學學報,2008,40(1):118-121.
[11]林秋華,李鏡.基于ICA-R的復值信號抽取方法[J].大連理工大學學報,2008,48(6):919-925.
[12]A Asad,F Muhammad.A modified m-estimator for the detection of outliers[J].PJSOR,2005,1(1):49-64.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
