基于共同模式挖掘的時間序列相似性度量方法
2011-07-24 12:32:58賈湖,朱博
統計與決策 2011年21期
賈 湖,朱 博
(天津大學 管理與經濟學部,天津 300072)
0 前言
時間序列相似性度量在數據挖掘領域有著廣泛的應用,如頻繁模式聚類,關聯規則挖掘等。時間序列的相似性度量包括兩個子序列的相似性度量和整個序列的相似性度量。對相似性這一概念的定義取決于實際問題中所要處理的時間序列的特點和數據挖掘的目的,例如對于每日的股票收盤價這一時間序列數據,兩只股票的價格可能相差數倍,但卻有著大致相同的走勢。對投資者而言,這樣的股票應該是相似性比較高的,而不是股價接近,走勢卻完全相反的股票。因此,在進行相似性研究時,要針對不同的數據和挖掘目標,使用不同的相似性度量方法。影響序列相似性的因素主要有:噪聲,水平移動,振幅伸縮,線性偏移,不連續性等。本文將以股票價格數據為基礎,對各種時間序列的相似性度量方法進行比較,并針對整個時間序列的相似性問題提出一種新的基于共同模式挖掘的度量方法。
1 時間序列相似性度量方法
1.1 直接距離法
通過計算兩個序列之間的距離來衡量兩序列的相似性是一種很容易理解的方法,距離越大則說明兩序列相似性越小,反之則越大,文獻[1]對這種方法有詳細的介紹。這種方法首先應該解決的問題便是如何定義兩序列的距離,有三種函數可用于描述兩序列的距離:曼哈坦距離、名可夫斯基距離、歐式距離。其中最常用的是歐式距離,歐式距離的定義為:
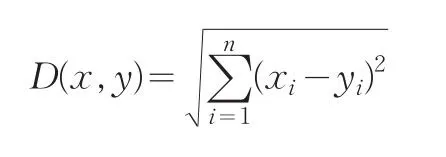
x和y分別代表兩個時間序列,xi和yi分別是x和y中的第i個點。歐式距離是一種簡單且直觀的距離測定方法,其計算復雜度與時間序列的復雜度成線性關系。對于股票價格這樣長度較大的時間序列來說其歐式距離會是一個很大的值,而且兩只股票價格的相對高低會對其影響很大,因此不適于做股票價格時間序列的相似性度量。
1.2 傅立葉變換法[2]
傅立葉變換的基本思想是將時間信號分解成一系列不同頻率的正弦波的疊加,其實質是將序列從時間域轉到頻率域,然后再進行處理。對于有限序列,傅立葉正變換為:
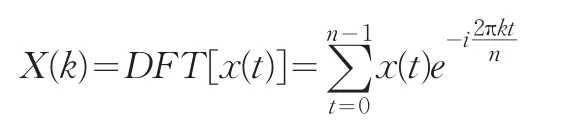
經過傅立葉變換的信號能夠保持原來的能量不變,而且在頻域空間中,序列的能量通常集中在幾個主要頻率上。可以將能量較低的頻率過濾掉,濾波后的序列和原序列仍然是很相似的,即傅立葉變換能夠有效的將序列進行壓縮。采用傅立葉變換后的歐式距離度量相似性,其拒識率一般比時域空間中的歐式距離法低。在這里,拒識率指的是原本很相似的序列計算出的相似性度量值卻很低的概率。利用傅立葉變換處理后的數據再用歐式距離進行相似性度量能大大降低需要計算的數據量。
(3)動態時間扭曲法
動態時間扭曲法(DTW)是Berndt和Clifford[3]引入時間序列研究中的,該方法首先用長度為m和n的兩個序列構造一個m×n的距離相異矩陣D。然后尋找一條由矩陣中滿足一定條件中路徑,使其連接矩陣的始末兩點。該模型可以度量長度不同的序列,同時對于噪聲、振幅變化等具有一定的魯棒性,但是該方法的計算量相當大,尤其不利于長度較大的序列的相似性度量。文獻[4]提出ASEAL和SEA方法在處理復雜時間序列和提高算法效率方面比DTW法更加優越。
(4)基于規范變換的方法
Agrawal[5]等認為如果兩個序列有足夠多的、不相互重疊、按時間順序排列且相似的子序列,則這兩個子序列相似。其基本思想是采用寬度為w的滑動窗口將序列分成若干個原子序列,對每個原子序列W=(w1,w2,…,wn),先按照如下的方法進行偏移變化和幅度縮放:
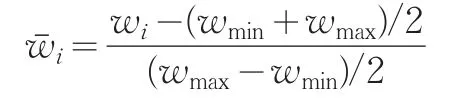
其中wi是窗口序列W中的第i個元素,wmax和wmin分別是窗口中最大和最小元素,為變化后序列元素。對兩個原子序列 W1=(w11,w12,w1n)和 W2=(w21,w22,w2n),若所有的序列元素滿足:
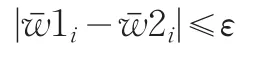
則稱兩子序列相似,當兩個序列的相似子序列達到一定數量時,可以判定兩序列相似,并用相似子序列的對數與窗口數的比值作為相似性的度量值。該方法考慮了幅度伸縮、偏移等問題,但是窗口大小和限定參數的設置仍然是困難的。本文不再將序列按照固定的窗口進行分割,而是采用大小可變的窗口,這樣就能避免將不再同一趨勢模式內的點硬性分到同一窗口所造成的誤差。
除此以外,還有神經網絡法[6],基于離散小波變換[7],相關性測度法[1],界標模型法[8]等度量方法。
2 算法概述
在對時間序列進行關聯規則挖掘和模式聚類時,需要將整個時間序列分成若干子序列,然后對具有相同特性的子序列進行頻繁模式挖掘,發現具有共同特點的頻繁子序列集。本文在總結前人對時間序列相似性研究的基礎上,提出了一種新的基于共同模式挖掘的相似性度量方法。序列分割一般采用的方法是等長分割,這種方法最大的好處是分割后的各個子序列是同步的,但子序列的長度的確定是一個難題,而且強制分割必然破壞潛在模式的完整性,損失大量信息。鑒于此,本文采用了不等長的分割方法。股票價格數據是一種特殊的時間序列,投資者更關心某一個模式的漲跌幅度和持續時間。所以在對序列進行分割時,我們針對每個子序列進行線性回歸,當子序列的回歸判定系數大于某個給定的閾值r時,將下一個點加入子序列中繼續計算;反之,將該子序列保留,從下一個點開始搜尋下一個子序列,直至整個序列搜索完畢。
回歸判定系數計算公式:
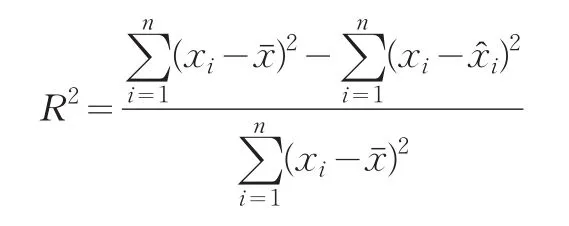
其中為回歸估計值為平均值。在對兩個序列進行分割之后,原序列變成了包含若干個子序列的集合,比較兩個集合中的各個子序列相似性,如果兩個子序列的相似度sim超過給定的閾值時,記兩子序列相似。計算相似子序列的對數,除以兩個序列子序列數中的較大者,所得結果即為兩序列的相似度S。該算法的Matlab實現流程簡介如下:
算法名:find_similarity
功能:發現兩序列的相似度S。
輸入:兩序列A,B,時滯閾值ΔT,子序列相似性閾值θ,子序列個數差異閾值ε,子序列回歸判定系數r;
輸出:兩序列相似度S:
第一步:將兩序列A和B分割成子序列集series_A和series_B(回歸判定系數閾值r);
第二步:判斷series_A和series_B中元素個數的差值是否小于閾值ε。若小于,則繼續,否則,兩序列無法匹配,結束程序;
第三步:計算子序列集中相似子序列對的個數count

第四步:計算兩序列的相似度S=count/max(|series_A|,|series_B|)。
算法結束。
其中,子序列的相似度sim的計算方法為:設兩子序列分別為兩個向量a和b,其序列的斜率和長度分別用向量的方向和模長來表示,子序列的相似度即兩向量的相似度為:
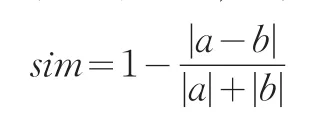
3 算法中的參數
該算法需要提供的參數為:時滯閾值ΔT,子序列相似性閾值θ,子序列個數差異閾值ε,子序列回歸判定系數r。其中很明顯子序列個數差異閾值ε對于進行相似性度量的時間序列具有篩選作用,考慮到大多數提供用于比較的序列長度應相差不大,因此該變量對算法準確性的影響并不大。下面主要討論一下ΔT、θ和r對相似性度量的影響。
從上證交易所上市的化工行業股票中選擇兩只股票sh600110和sh600281,截取其從2009-4-13到2010-7-9日共300天的股票收盤價數據進行序列相似性度量。首先對兩組時間序列數據進行預處理,將由于停盤導致的兩組數據時間不一致的點通過添加或刪除對齊。然后得到兩組共600個對稱的數據,進行相似性比較,默認參數值為:ΔT=5,θ=0.9,r=0.8,
計算過程在Matlab中編程實現。通過改變參數的值,測定不同參數值下的相似度S,得到參數ΔT、θ和對相似度S的影響。最后結果在圖1,圖2和圖3中表示。
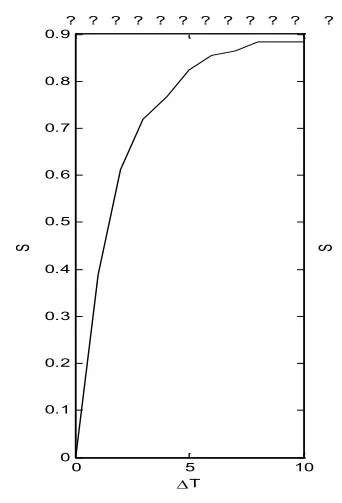
圖1
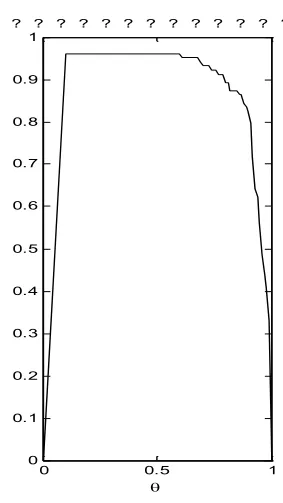
圖2
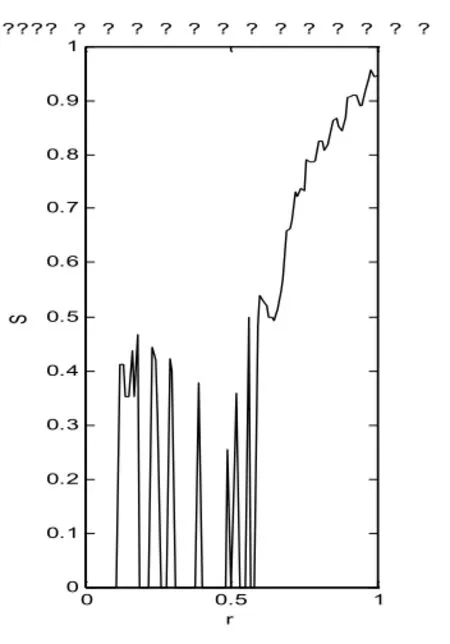
圖3
從圖1我們可以看出,相似度隨著ΔT的增長而增長,同時在ΔT<4時,S增長較快,超過0.5之后則增長明顯放緩。圖2中θ在0.6之前沒有變化,保持一個很高的相似度值,這是因為子序列相似性閾值比較小時,對其起不到篩選作用,而太大(超過0.9)又會變得十分苛刻,使得相似度急劇下降。圖3表明當相關性判定系數r小于0.6時,相似性的度量值顯示出很差的穩定性,當r超過0.6之后,相似性有一個連續上升的過程。但r不應過大,否則會導致只有很少的點能被加入到子序列中,最終會造成序列被過度分割。綜上所述,以上三個參數應在一下范圍內應用:ΔT~[3,5],θ~[0.7,0.9],r~[0.7,0.9]。當然,這樣給出的范圍帶有一定的主觀性,在具體應用時可以根據個人偏好進行適當調整。
4 時間序列相似性影響因素
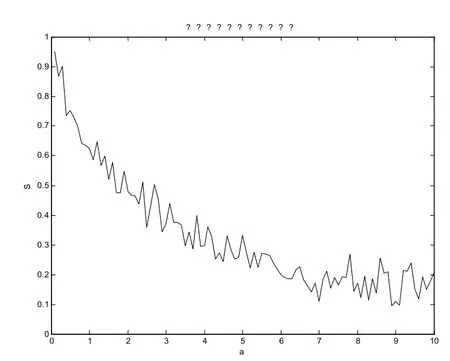
圖4
在對算法中各個參數進行考量之后,我們得出了3個參數的可用值的范圍,現在取 ΔT=5,θ =0.9,r=0.8,對影響時間序列形似性的各個因素進行敏感性研究。
4.1 噪音(NOISE)
設Y為觀測值,y為真實值,a代表噪音震蕩幅度,σ為隨機變量,范圍是[0,1]。噪音的影響可用公式表示為:
Y(t)=y(t)+a?σ(t)
以上文提到的sh600281的數據為原始序列,對原始序列y(t)加入噪音,使其變為Y(t)。通過改變加入噪音的震蕩幅度a(從0到10),計算出不同大小的噪音對序列Y(t)和y(t)的相似度S的影響。很明顯,當a=0時,S=1,結果如圖4所示:當噪聲幅度較小時,對相似度S的影響很大,隨著噪聲的增加急劇降低;當a大于4時,S變化變得緩慢,基本維持在一個較低的值附近上下波動,此時兩序列幾乎沒有相似性。
4.2 水平移動(HORIZONTAL MOVE)
兩序列在水平方向的相對移動是另外一個重要的因素,它可以用以下的公式來表示:
Y(t)=y(t+b),其中b為水平移動步數,它代表某個模式和它相似的模式之間可能有幾天的超前或滯后。取b從1到10,計算出的相似度S變化如圖5所示,可以看出在b=5時S有較大幅度的降低,這一點和我們所設定的ΔT=5的默認值有關系。當b<5時,b的變化對相似性幾乎沒有影響,因為這一影響可以被ΔT=5的判定閾值所覆蓋;當b≥5時,b的變化引起了相似度的大幅波動,但是S仍維持在0.7以上,說明b對S的影響并不是很大。
4.3 振 幅(AM?PLITUDE)
定義振幅A>0,對于相似模式而言,振幅改變了子序列的斜率,但并不影響子序列的水平距離和長度,其公式為:
Y(t)=A?y(t)
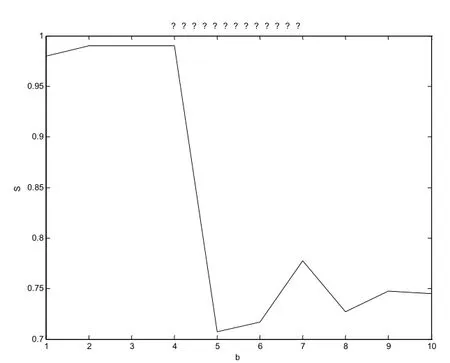
圖5
如圖6所示:振幅在1附近時對相似度S沒有影響,S保持為1。隨著A增加,S逐漸減小至一個較低值,可見,當A大于2時,A是影響S的一個很重要的因素。
此外,還有一些因素如:序列不連續性,線性偏移,水平伸縮等會對序列相似性起到一定的影響,篇幅所限,本文不再一一贅述。可以推斷,對于股票數據來說,噪音、振幅應該是影響相似性的重要因素。因為面對同樣的宏觀環境的影響,不同行業,不同地域,不同規模的公司所受的影響是有差異的,這也就解釋振幅的增加所造成的股票序列相似性的降低。對于不同的公司處理突發事件的能力不同,同時市場的震蕩和眾多投資者所產生的羊群效應也會干擾個別股票的表現,這些又造成了影響股票序列的噪音。不同序列的同一模式所受到的作用力的釋放需要一定的時間,但這并不影響共同模式的發生,因此可以解釋序列相似性對于水平位移的不敏感性。
5 應用
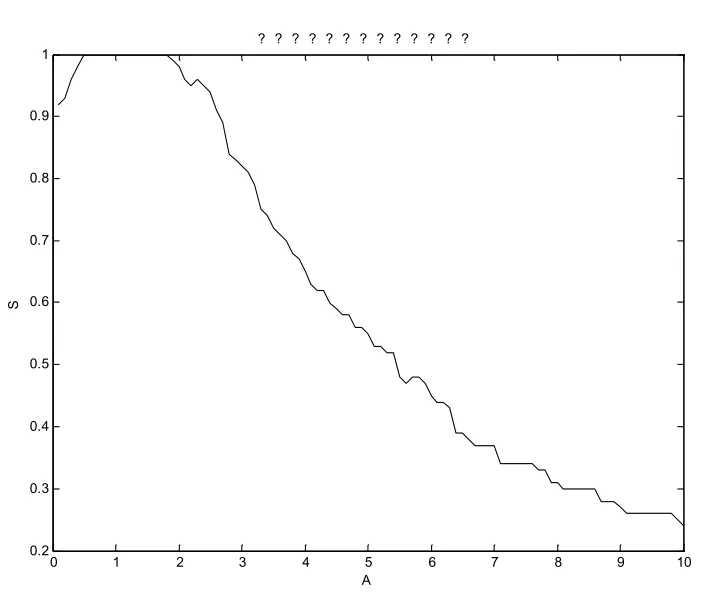
圖6
如前所述,在對時間序列進行數據挖掘過程中,序列相似性對于尋找頻繁模式,發掘關聯規則有著重要的意義,這是時間序列相似性度量的主要應用領域。股票價格數據是一種典型的時間序列數據,受隨機因素的影響很大,而且不同行業的股票價格受同一因素的影響可能是截然相反的。即使是同一行業內的股票,受同一作用機制的影響所做出的反應也不相同。本文提出的相似性度量方法在序列分割時充分考慮了子模式的發展趨勢和模式發生的時滯性,因此能夠很好的體現在同一因素作用下兩只股票序列的表現,從而進一步可以為投資者合理分配資金,建立可靠的投資組合,分散風險提供依據。以上文提到的sh600110的數據為例,尋找同一行業中與其相似的股票進行相似性度量,發現有較好的區分度,獲得最大相似度的股票為sh600281(S=0.85),最小的相似度為sh600319(S=0.53)。
6 總結
在對時間序列(以股票市場數據為研究對象)相似性研究中,提出了一種新的度量股票市場序列相似性的方法。該方法基于對時間序列的共同模式的挖掘,找出兩個序列的相似子模式或稱子序列,通過共同模式發生的頻繁度來度量整個序列的相似性。根據這種思想,本文作者利用Matlab完成的算法的實現過程,并對算法中相應的參數的設置進行了考量。通過對某支股票的數據所組成的時間序列加入干擾因素:噪音,水平移動,振幅等,得出該方法對于時間序列中的噪音和振幅變化有較強的敏感度,但對于時間序列的水平移動或者子序列的時滯差異表現地較為寬容。
[1] 王曉曄.時間序列數據挖掘中相似性和趨勢預測的研究[D].天津大學,2004.
[2] 馬超群,蘭秋軍,陳為民等.金融數據挖掘[M].北京:科學出版社,2007.
[3] Berndt D,Clifford J.Using Dynamic Time Warping to Find Patterns in Time Series[A].In:AAA-94 Workshop on Knowledge Discovery in Databases,KDD-94[C].Seattle,Washington,359~370.
[4] Bachir Boucheham.Reduced Data Similarity-based Matching for Time SeriesPatternsAlignment[J].PatternRecognitionLetters,2010 ,31(7).
[5] Agrawal R,Lin K I,Sawhney H S,et al.Fast Similarity Search in the Presence of Noise,Scaling,and Translation in Time Series Database[A].In:Proceedings 1995 Int’l Conference on very Large Database(VLDB’95)[C].1995.
[6] 史中植.知識發現[M].北京:清華大學出版社,2002.
[7] P.K.Dasha,Maya Nayaka,M.R.Senapatia,I.W.C.Leeb.Mining for Similarities in Time Series Data Using Wavelet-based Feature Vectors and Neural Networks[J].Engineering Applications of Artificial Intelligence,2007,20(2).
[8] Peng C,Wang H,Zhang S R,et al.Landmarks:A New Model for Similarity-based Pattern Querying in Time Series Databases[A].In:Processing of the 16th IEEE Int’l Conference on Data Engineering[C].2000.
猜你喜歡
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
媽媽寶寶(2017年3期)2017-02-21 01:22:28
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
