基于 XML 的 WEB信息自動抽取方法的研究
2010-10-22 06:59:38劉艷柳顧軍華
河北工業大學學報 2010年5期
宋 潔,張 娜,劉艷柳,顧軍華
(河北工業大學 計算機科學與軟件學院,天津 300401)
隨著互聯網的迅猛發展,WEB信息量呈爆炸式的增長,對信息抽取技術提出了更高的要求,如何直接而準確地從海量信息中抽取出用戶感興趣的數據變得尤為重要.基于本體實現表格信息抽取方法[1-2]不依賴于所抽取的WEB頁面的設計格式,也沒有對其內容提出任何表示限制,但該方法只適用于一定的應用領域,當應用領域改變時相應的本體需要重新構造.基于樣本實例的抽取方法[3]不依賴于網頁的結構特征,但這種方法需要較多的樣本實例,增加了用戶負擔.基于網頁結構特征分析的方法[4-5]采用統計聚類的思想,查全率較高,但在抽取信息時具有一定的盲目性,經常抽取出大量的無用信息.可見,現有的信息抽取技術難以同時滿足網頁信息自動抽取中查全率與查準率高、抽取信息量大、用戶負擔輕和無關于應用領域等要求.
通過對現有信息抽取方法的研究,本文提出了一種基于XML的WEB信息自動抽取方法,采用標準的XML技術來解決信息抽取問題.通過頁面清洗技術將HTML文檔標準化,利用歸納學習算法得到公共路徑,獲得用戶感興趣的目標區域,形成抽取規則庫,從而實現對其它同類頁面信息的自動抽取.該方法將網頁結構特征分析與歸納學習相結合,具有較高的查全率與查準率;需要的樣本實例少,減輕了用戶負擔;使用標準的XSLT作為信息抽取規則,復用性高、抽取結果具有自描述性.
1 信息抽取框架
本文提出的基于XML的WEB信息自動抽取框架,包括4個功能器:頁面清洗器、頁面結構分析器、規則學習器、抽取器,如圖1所示.其中頁面清洗器包括網頁URL、XHTML文檔;頁面結構分析器主要是構建網頁分析樹;規則學習器包括學習樣本實例、構建XPATH;抽取器包括XSLT模板規則庫、抽取信息.
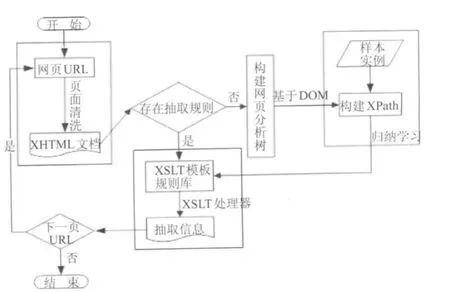
圖1 Web信息自動抽取構架Fig.1 Automatic extraction of web information architecture
2 基于XML的信息自動抽取方法
基于XML的信息抽取方法在待抽取的數據源網頁URL已獲得的前提下,通過頁面清洗器將源HTML文檔標準化,過濾無用元素.如果該頁不存在抽取規則,利用頁面結構分析器將該頁解析成一棵網頁分析樹,并根據樣本實例學習公共的 XPATH,從而形成該頁的抽取規則.如果已存在抽取規則,則直接進行抽取.由于待抽取的信息大都是通過后臺數據庫產生,即所謂的隱藏網頁[6],一般有著較為統一的結構,因此依據生成的抽取規則,可以將網站中全部需要的信息抽取出來.
2.1 頁面清洗
目前WEB上的數據大多都是HTML格式的,該標記語言缺乏對數據本身的描述,不含清晰的語義信息,對隱藏其中的數據難以檢索或抽取.許多HTML文檔沒有完全遵守W3C網頁標準,結構混亂,甚至含有錯誤,無法被轉換成一棵網頁解析樹,因此在信息抽取前有必要進行頁面的整理工作.
可擴展超文本標記語言(Extensible HyperText Markup Language,XHTML)是萬維網聯合會提出的新一代網頁標準,從根本上解決了WEB文檔和其他資源描述所面臨的問題.因此在過濾腳本信息、圖像信息等無用元素的基礎上,將不規范HTML文檔轉換成標準的XHTML文檔是頁面清洗中的一項重要工作.
現有的WEB數據轉換工具Tidy容錯功能比較差,直接使用Tidy工具轉換為XHTML文檔后,解析比較困難,難以進行后續工作[7].本文給出了一種HTML頁面清洗算法,主要實現步驟如下.
1)利用HTML解析器把HTML文檔解析成一棵HTMLDOM樹,并獲得該樹的根元素.
2)為文檔添加XML文檔聲明和XSLT規則轉換文件.
3)從樹根開始,遞歸遍歷HTMLDOM樹,根據節點類型進行判斷處理.
若是文本節點,則用實體引用代替特殊字符,并打印文本節點.
若是元素節點,則需判斷節點類型是否是無用元素.若是無用節點,如Script、META、STYLE等,則直接過濾;否則,在取出元素節點之前先打印“<”,利用DOM中的get Node Name()方法獲得元素節點名稱,同時將其名稱小寫化.
在抽取時有些元素節點的屬性值是必須的,如鏈接元素的屬性值有利于獲得下一頁網頁地址;而有些屬性值只是用于字體樣式,對抽取工作是無用的.因此,必須對元素節點的屬性值進行優化處理.本方法判斷元素類型是否為鏈接元素,若是,則提取鏈接元素所有的屬性值.在XHTML中,屬性值必須使用引號,并且必須有值.因此,在輸出鏈接元素的屬性時,首先打印一個引號,并取得屬性值,對其進行特殊字符轉換、小寫化,再打印結束引號,最后打印“>”.
如果元素節點有子節點,則以同樣方式遞歸打印出所有孩子節點,直到遍歷結束,關閉元素節點.
4)待整個HTMLDOM樹遍歷結束,則形成了規范的XHTML文檔.
例如,針對某網站經過該轉換算法標準化后的XHTML文件片斷如圖2所示.
2.2 構建網頁分析樹
對XHTML文檔進行解析,使用JTREE構建可視化的XML文檔,以便獲得實例樣本,減輕用戶負擔.
構建網頁分析樹思想如下:
1)將頁面清洗得到的XHTML文檔解析成XMLDOM樹,獲得該樹的根節點ROOT.
2)深度優先遍歷該XMLDOM樹.獲得根節點的名稱,如果該節點有孩子節點,遞歸處理該節點的孩子節點.如果該節點沒有孩子節點,則直接加到當前節點下.最后把所有子節點加載到JTREE的根節點中生成整棵樹.
3)顯示整棵樹.將圖2中 XHTML文檔構建網頁分析樹,其結果如圖3所示.

圖2 經過轉換算法標準化后的XHTML文件片斷Fig.2 the standard XHTML document segment
2.3 歸納學習XPATH
在獲得樣本實例的XPATH表達式的基礎上,通過歸納學習得到公共XPATH.由于本方法只需獲得樣本實例的 XPATH的表達式,不需構建每個節點的XPATH,故執行速度較快.
1)生成樣本XPATH
XPATH路徑表達式可以看成定位XML文檔各個節點的步驟順序,這些步驟以“/”分開.如圖3選中的節點,其XPATH表達式為“/html[1]/head[1]/title[1]”,表示選擇“html”元素下“head”元素的“title”元素的葉子節點值,結果是圖中的“筆記本電腦類目2,商品,盡在拍拍”節點.為了準確的定位信息點位置,本文提出了一種新的學習XPATH算法用于生成樣本實例的XPATH,描述如下:


圖3 使用JTREE構建的網頁分析樹Fig.3 Web analytics tree constructed by JTREE

2)學習公共XPATH
獲得所有的樣本實例后,通過學習算法歸納出公共 XPATH,本文涉及兩種情況:網頁級抽取和記錄級抽取.本文中的網頁級抽取是簡單而有效的,主要目標是提取主題信息,而不是細粒度的數據.比如招聘信息一般可得到記錄級的招聘列表,每個招聘信息都會有一個鏈接,以說明詳細的招聘事宜,本文只需抽取出詳細的招聘事宜即可.
若為記錄級抽取,則至少需要2個樣本實例.本方法利用網頁分析樹獲得樣本實例的 XPATH,并歸納學習出待抽取信息的公共路徑.對于兩個樣本實例的XPATH表達式,從樹根開始比較,如果節點名稱和位置序號都相同,則記入公共XPATH表達式,若某個節點的節點名稱相同,而位置序號不同,則說明待抽取信息位于以該節點表示的樹節點及其兄弟為根的子樹中,此時獲得該節點的所有兄弟節點數,將該節點的孩子序號置為0,并寫入公共XPATH表達式中;依次比較到XPATH表達式結束.有的頁面需要學習多條XPATH,那么繼續將樣本實例的XPATH與已經得到的公共XPATH比較,從根節點開始,直到全部樣本實例比較完畢,由此可得到全部樣本實例的公共XPATH表達式.若抽取多個信息點則需要學習各個信息點的XPATH表達式.
若為網頁級抽取,則樣本實例至少需要1個.若為1個樣本實例,它的公共XPATH就為此節點本身的XPATH表達式;若為多個樣本實例,生成公共XPATH的方法和記錄級抽取的生成方法相同.
2.4 抽取規則優化處理
由于XSLT具有強大靈活的語法結構,易于理解、修改和操縱文檔中的數據,本文使用標準的XSLT作為信息抽取規則.通過對歸納學習得到的公共XPATH添加、合并或更新,生成抽取規則庫,形成XSLT文件,利用其中的XPATH構件定位文檔中節點的位置,從而實現了一次編寫,多次重用.
在信息抽取中,一般記錄條數較多,而在XSLT中,當XSLT處理器為執行轉換而處理樣式表的時候,它的值每次都可能發生變化.但是,一旦在某個轉換中設定了這個值,就不再發生變化.因此,要把所有的記錄條數全部抽取出來,必須使用模板遞歸調用.首先定義3個變量,保存起始孩子節點序號,孩子節點數以及步長值.然后設置公共路徑里的參數,初始值為起始孩子節點序號,模板運行一次后將起始孩子節點序號按步長值增加,得到的結果作為參數遞歸調用模板,完成多條記錄數的自動抽取.
在生成抽取規則時可以定制待抽取節點的節點名稱,使其作為結果XML文件的元素名稱,保證了抽取結果具有自描述性.
2.5 抽取信息
根據抽取規則庫里的規則,利用XSLT和XPATH在數據轉換和數據定位方面的優勢,通過輸出文件函數實現信息抽取.將抽取結果存入XML文件中,用于觀察數據抽取的正確性和二次處理.
3 實驗結果及分析
利用基于XML的WEB信息自動抽取方法,采用JAVA語言開發了信息抽取原型系統.該系統界面簡單友好,在頁面結構發生變化時,也能利用原型系統快速構建新的抽取規則庫,具有較高的查準率和查全率.
本文利用原型系統進行了4個網站26個頁面的實驗,如表1和表2所示,其中待抽取數據共423個,由于2688網店和卓越亞馬遜的信息點具有兩種格式,當其提供的樣本實例數為2個時,實際抽出共366個,正確抽出共360個,平均F值為75.23%;當其提供的樣本實例為3個時,平均查全率為99.17%,平均查準率為99.17%,平均F值為99.17%.對于一般網站而言,一個信息點本方法最多提供3個樣本實例,便可完成較高查全率和查準率的抽取.基于上述試驗結果,本文的信息抽取方法是有效且可行的.

表1 測試原型系統的網站Tab.1 test prototype website
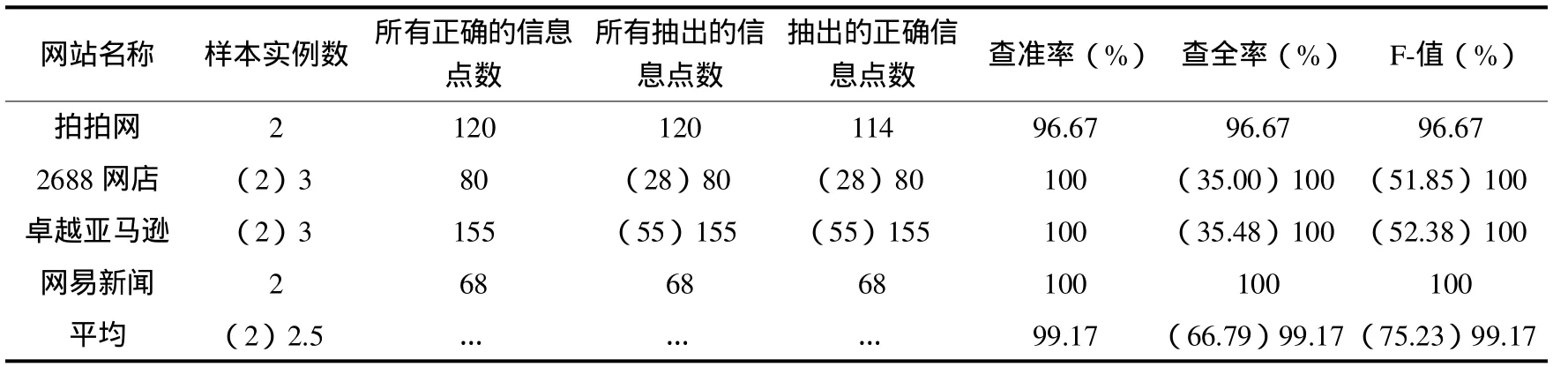
表2 抽取測試效果的評價Tab.2 Evaluation of test results
4 結束語
本文給出的基于XML的WEB信息自動抽取方法,利用XML的標準技術,通過數據轉換算法和XPATH學習算法獲得公共路徑,并結合XSLT和XPATH在數據轉換和信息定位方面的優勢,實現了對WEB信息的自動抽取.實驗結果表明,該方法查全率和查準率高,抽取結果具有自描述性,易于建立各個領域的數據抽取系統.
[1]王放,顧寧,吳國文.基于本體的WEB表格信息抽取 [J].小型微型計算機系統,2003,24(12):2142-2146.
[2]畢蕾,沈潔,徐法艷,等.領域本體指導的Web商品信息抽取 [J].計算機工程與設計,2008,29(24):6393-6396.
[3]張紹華,徐林昊,楊文柱,等.基于樣本實例的WEB信息抽取 [J].河北大學學報(自然科學版),2001,21(4):431-437.
[4]David Buttler,Ling Liu and Calton Pu.A fully automated object extraction system for the world wide web[C].International Conference on Distributed Computing Systems,2001.
[5]于魯波,陳超.互聯網商品信息抽取技術 [J].計算機工程,2008,34(5):274-276.
[6]Raghavan S,Garcia-Molina H.Crawling the Hidden Web[EB/OL].(2000-12-08).http://dbpubs.stanford.edu:8090/pub/2000-36.
[7]軒艷艷.基于XML的WEB信息抽取研究與實現 [D].武漢:武漢理工大學,2008.
猜你喜歡
數學物理學報(2020年2期)2020-06-02 11:29:10
安順學院學報(2020年1期)2020-04-05 10:57:20
現代計算機(2019年6期)2019-04-08 00:46:50
電子制作(2018年10期)2018-08-04 03:24:38
電子制作(2017年2期)2017-05-17 03:54:56
電子測試(2015年18期)2016-01-14 01:22:58
高中生學習·高三版(2014年3期)2014-04-29 06:11:18
高中生學習·高三版(2014年3期)2014-04-29 06:10:49
計算機與網絡(2014年7期)2014-03-25 10:57:07
商(2012年11期)2012-07-09 19:07:55
