基于語義的監控系統的應用研究
2010-10-17 07:47:04邱澤國唐季華
哈爾濱商業大學學報(自然科學版) 2010年2期
邱澤國,唐季華
(哈爾濱商業大學計算機學院,哈爾濱150076)
基于漢語主題詞表和各學科或專業主題詞表,建立一個以主題詞為骨架、輔以全面的自由詞面的自由詞,并標示出包括所有主題詞和自由詞之間的用、代、屬、分、參關系,可形成內容比較完善的后控詞表[1].它不僅可以適應用戶輸入的非規范化用詞,提高查全率和檢索效率,通過詞間概念等級關系和族性關系,方便地進行上、下位詞的檢索從而實現擴檢和縮檢,還可在一定程度上實現語義關聯檢索,充分發揮主題詞檢索的優越性.但是,建立后控詞表是一項技術難度和工作量都比較大的工作,而且隨著時間的推移,新詞不斷呈現,詞表如何自動更新,即詞表自學習功能也一直是一個難題.
目前,后控制詞表中的參照關系,主要是依據漢語主題詞表或各學科專業的主題詞表中收錄的“參”關系設置的[2].此種設置方式有兩大不足:一是收入的參照關系有限,二是詞間的參照關系過于嚴密,無論是主題詞之間或是主題詞與自由詞之間,被參照的詞往往還是不夠“自由”,帶有比較重的書面色彩[3].這就給概念的相關檢索和參照檢索帶來一定難度.
1 整體結構
為了滿足安全和訪問要求等相關需求,必須在每個生產主機的產品用戶下部署UserAgent,用于對產品進程的直接操作,這樣不用考慮提供主機系統用戶/密碼等;
同時在生產環境中獨立部署服務器(獨立的物理主機),并在其上部署通訊中間件和運維服務進程等;
服務器上不部署DB,需要存取的數據記錄為數據文件方式,同時考慮到平臺支持,應該可做快速移植;
需要的所有配置信息(操作主機配置、操作員用戶/密碼、任務計劃定義等)都可以存放到其中的配置數據文件中;
UserAgent,服務Server和終端Terminal都通過通訊中間件相互連通,見圖1.
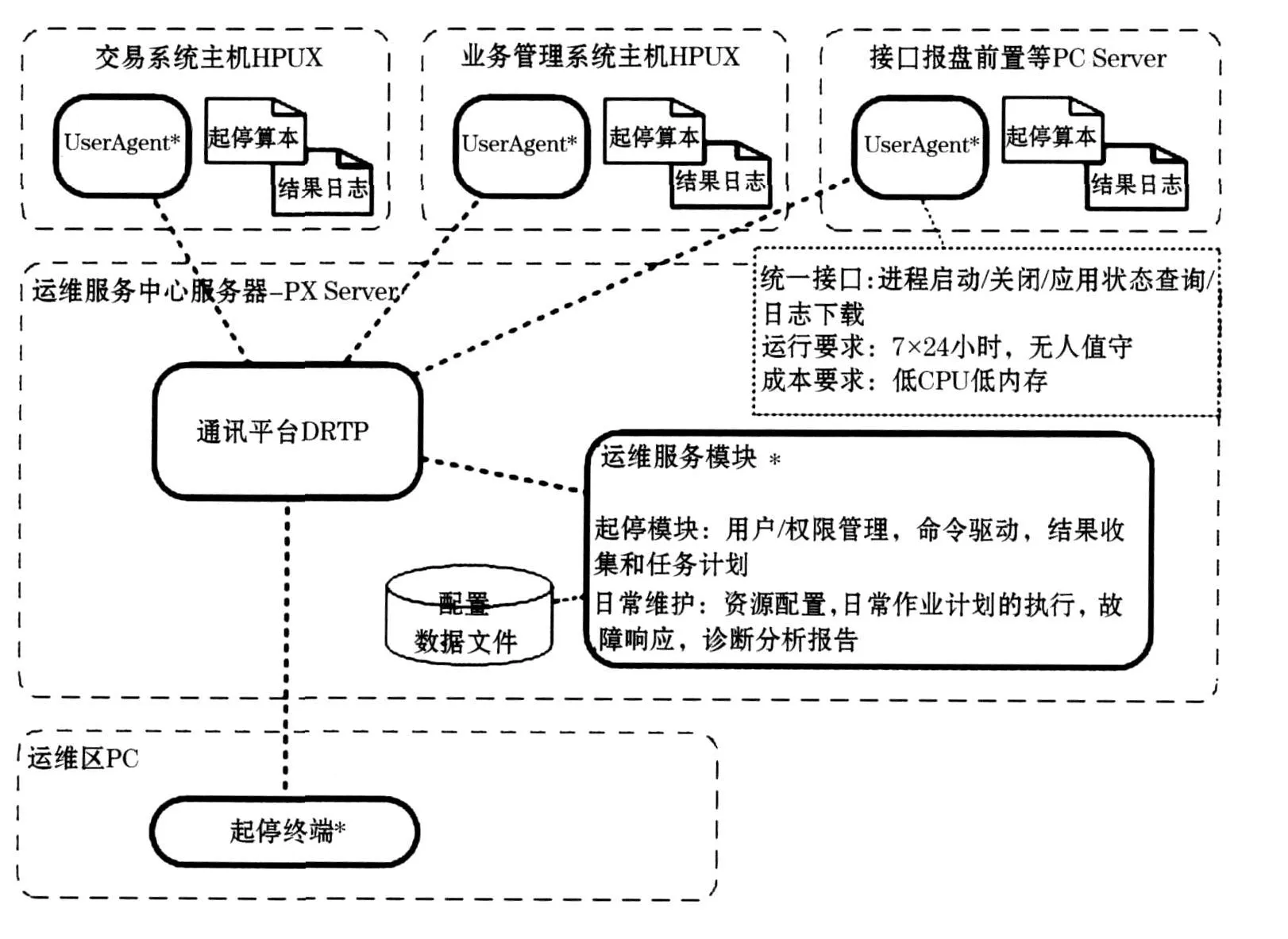
圖1 整體結構示意圖
UserAgent和服務都必須要求可以7×24小時運行,同時自身非常穩定,另外UserAgent因為被直接部署在生產主機上為此必須十分穩定且資源消耗小和平穩;
在Windows平臺下,UserAgent應該是以Service方式運行的,并可隨機器一道啟動;
在UNIX平臺下,UserAgent應該是以DAEMON方式運行的,并可隨機器一道啟動.
2 軟件設計與實現
由于UserAgent可直接訪問當前用戶下的資源,所以為了方便開發和管理維護,在UserAgent上需要開發一系列可靠簡易的調用接口,建議做法是:
Shell腳本調用接口,定義Shell腳本的名稱和調用要求,并要求Shell腳本將輸出結果或信息反饋到某確定文本(結果日志)中,調用者UserAgent可以在Shell腳本調用結束后,通過讀取結果信息日志文本獲得最可靠的結果回應[4].
回應結果的解讀必須是嚴格可靠的,為此需要設定嚴謹的消息格式,這樣可以保證解析的結果信息準確可信.而對結果的實際解析可以不由UserAgent負責,可以回應給服務的模塊來完成.
UserAgent的開發必須完全統一,即在不同平臺或主機下,只能有一種UserAgent的實現,盡量不要開發不同個性功能的Useragent實現,這樣才能很好保證其可靠和穩定性,同時也能大大簡化開發工作量,為此UserAgent不能過于關心功能的差異性細節[5],見圖2.
為此在功能設計方面我們可以借鑒Ant的思路,在服務模塊規劃和定義Target,每個Target包含若干需要順序執行的Task,而每個Task需要定義如下信息:UserAgent的標識,即AgentID或請求功能號;任務參數,可能需要的請求參數;每個任務調用都有返回結果,為了統一調用接口,建議各種任務的請求參數和返回結果都使用固定字段.

圖2 軟件設計與實現示意圖
這樣在服務模塊里,任何操作就是一個Target,而執行Target時就是順序執行其下的一系列事先定義好的Task,每個Task都有請求和應答,如果在一個Target的執行過程中,任何一個Task失敗,那么整個Target就失敗.
3 目標任務調用模式
對于每個被調用Task,其UserAgent都會轉化為一個實際的Shell腳本的運行,由于執行Shell腳本存在時間周期等待的可能,而等待時間也會有很多差異,為此如果采用請求/應答的完全同步模式可能不夠穩定,所以可以考慮將一個任務的完成過程分為兩步驟來進行:
第一階段為任務發起準備,由服務發送任務準備執行指令(一般需要設定一個惟一的任務流水號,便于未來做跟蹤和檢查)給某UserAgent,UserAgent收到后,做執行Shell腳本前的準備和檢查工作,如果可以執行就應答給服務為準備就緒,如果有問題則應答準備失敗;這個應答由于檢查和準備工作很少,所以可以快速給予回應;服務受到相應應答后就可以作出該任務的執行狀態更新或相關工作;
第二階段為任務執行和結果匯報,由UserAgent在準備完成后可迅速開始進行Shell腳本的執行,待腳本執行完成后,同時對執行結果收集好后,獲得當前該執行任務的反饋結果信息,就把該信息發服務(返回信息里必須包含當前任務的唯一流水號),服務通過該回饋信息可以迅速更新對應任務狀態,這樣可以驅動任務所在目標流程的后續任務驅動;
通過這種兩階段異步模式,可以使目標流程和各個任務的執行情況得到迅速跟蹤,并且可以避免請求/應答方式下長時間等待,為此還需要UserAgent提供一些相關的任務查詢接口,如按任務流水號查詢某任務的執行狀態或情況.任務流水號可以由UserAgentID+任務標識+日期+時間值等來全局惟一表示,而且該號可以用于其他用途.
另外對于一個任務,其對象狀態大致可以為:初始Init、執行中Running、執行成功Success、失敗Failure;如圖3所示.
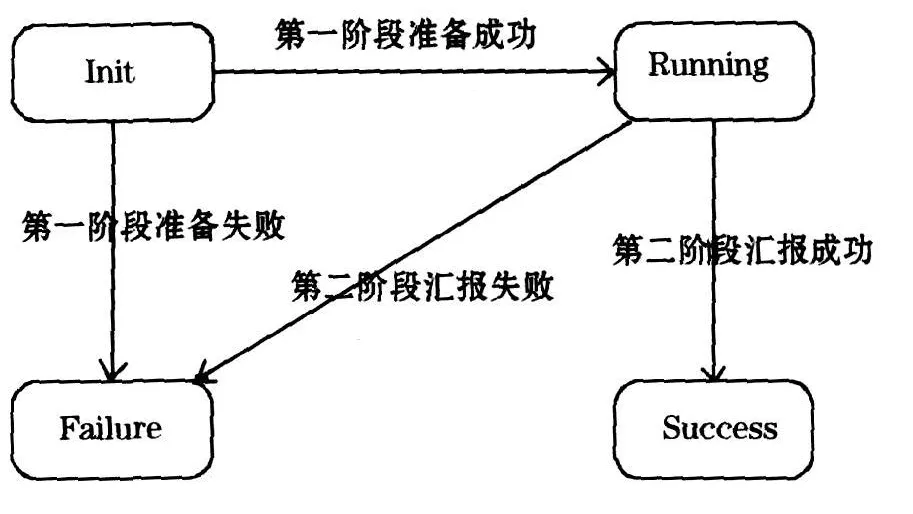
圖3 目標任務調用模式示意圖
在任務對象執行管理的基礎上,目標流程的定義管理就相對清晰了.一般可嚴格要求,任何流程都是沒有分支的,就象以前用Ant腳本編寫的Target一樣,而且不允許服務同時執行多個目標流程,這樣便于我們隔離錯誤和問題,防止出現不可預估的情況.
本實驗選用Protégé3.0作為本體建模工具,Protégé3.0是由斯坦福大學的Stanford Medical Informatics開發的一個開放源碼的本體編輯器[6],它是用Java編寫的.其界面風格與普通Windows應用程序風格一致,易學易用[3].在Protégé3.0編輯器中,本體結構以樹形的層次目錄結構顯示,用戶可以通過點擊相應項來編輯或增加類、子類、屬性、實例等本體元素,另外,用戶可以不用考慮具體的本體描述語言,而在概念層次上設計領域本體模型.
在構建本體和組織存儲實例數據之后,就需要在應用程序中對其進行解析和應用.在本體數據讀取、語義推理和信息檢索時,ISearch系統主要采用了惠普實驗室開發提供的Jena 2.1API接口方法.
Jena是一種用來構建語義萬維網應用的Java框架,它提供了有關操作RDF、RDFS和OWL的接口方法以及基于規則的推理引擎編程環境,而且Jena還是一個開源項目,目前由惠普語義網絡實驗室負責開發,在Jena框架中主要提供了以下的一些Java包、接口和方法.
?RDF應用編程接口;
?提供讀寫各種語法形式的RDF文件,包括RDF/XML、N3等格式;
?提供操作OWL文件的應用編程接口;
?提供基于內存和持久存儲兩種方式;
?提供了一種RDF實例數據查詢語言——RDQL;
在ISearch系統中主要使用了Jena中的如下兩個包中的方法:
?com.hp.hpl.jena.rd f.model——其中提供了大量有關創建和操作RDF圖的方法;
?com.hp.hpl.jena.vocabulary——其中包含了在RDF和OWL規范中,所定義的Resource對象和Property對象,如RDF類和OWL類等[5].
為了實現系統中表示層和邏輯處理層之間的分離,在設計人機界面時,ISearch系統采用Velocity模板語言.
Velocity是一個基于Java的模板引擎(temp late engine).它允許任何人可以通過簡單的使用模板語言(temp late language)來引用在Java代碼中所定義的對象實例.當Velocity應用于Web開發時,界面設計人員可以和Java程序開發人員同步開發一個遵循MVC架構的Web站點,也就是說,頁面設計人員可以只關注頁面的顯示效果,而由Java程序開發人員關注業務邏輯編碼.Velocity真正的做到了系統控制層和人機交互界面的分離,這種分層的設計模式有利于web站點的長期維護.
?采用Servlet、HTML、JavaScript、Applet、XML實現界面表示層功能.
?采用Session Bean實現業務邏輯層功能.
?利用應用服務器的JDBC(Java Database Connectivity)驅動實現數據訪問層功能.
?采用JMS(Java Messaging service)實現消息服務.
4 結 語
根據用戶檢索需求的特點并結合了語義網的相關知識,提出了一種基于特定問題的概念關聯檢索思路,目前從技術上實現起來主要有以下難點:
相關領域本體的構建.本體是共享概念模型的明確的形式化規范說明,而領域本體的目標是捕獲相關的領域的知識,提供對該領域知識的共同理解,確定該領域內共同認可的詞匯,并從不同層次的形式化模式上給出這些詞匯(術語)和詞匯之間相互關系的明確定義.而構建具有良好的概念層次結構和對邏輯推理的支持,能在基于語義的檢索中有廣泛應用的領域本體是一個復雜的工程,檢索領域目前應用較多的還是比較初級的詞表等形式.
擴展參照檢索的算法.由于參照的是一個主題模式而不是幾個相關的詞,因此對模式的匹配需要有新的策略,而模式本身的復雜的概念體系也要求檢索過程必須采取一定的策略,如關聯層級限制,來保證輸出結果集的精練.
結果排序.由于不再是基于關鍵詞的匹配,其輸出結果需要按照語義相關度來排序.文中目前提供的排序方式還只是一種基于位置的簡單處理,很難從語義層面體現相關性的重要程度.
概念檢索主要包含了兩個方面的內容,即同義擴展檢索和相關概念聯想.因此,相關概念的關聯和參照檢索是概念檢索的重要研究內容.基于問題的語義關聯的擴展參照檢索,實際上是一種概念關聯檢索.要構建出實用的概念關聯檢索系統,還必須進一步結合語義網、本體論以及AI領域的NLP等語義層面的表示及推理技術
[1]HANAN U.Information Filtering:Overview of Issues,Research and Systems[J].User Modeling and User-Adapted Interaction 2001,11:203-259.
[2]COHENW.Fast effective rule induction[C]//Machine Learning:Proceedings of the Twelfth International Conference,Lake Taho,California,Mongan Kanfmann,1995:115-123.
[3]QUINLAN JR.Induction of decision trees[J].Machine Learning,1986,(1):81-106.
[4]于 玲,吳鐵軍.集成學習:Boosting算法綜述[J].模式識別與人工智能,2004,17(1):52-59.
[5]王海川,張麗明.一種新的Adaboost訓練算法[J].復旦學報:自然科學版,2004,43(1):27-32.
[6]黃萱菁.基于向量空間模型的文本過濾系統[J].軟件學報,2002,13(4):15.
[7]郭 聳,洪炳镕,陳鳳東.基于嵌入式Linux和Web服務器的網絡視頻監控系統[J].哈爾濱商業大學學報:自然科學版,2005,21(6):736-738.
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
商周刊(2017年9期)2017-08-22 02:57:56
現代語文(2016年21期)2016-05-25 13:13:44
