魯棒視覺詞匯本的自適應(yīng)構(gòu)造與自然場(chǎng)景分類應(yīng)用
2010-03-27 06:55:10楊丹李博趙紅
電子與信息學(xué)報(bào) 2010年9期
楊 丹 李 博 趙 紅
①(重慶大學(xué)軟件學(xué)院 重慶 400030)
②(重慶大學(xué)計(jì)算機(jī)學(xué)院 重慶 400030)
1 引言
自然場(chǎng)景分類是機(jī)器視覺、模式識(shí)別、多媒體信息管理等領(lǐng)域的熱點(diǎn)問題。傳統(tǒng)方法通常是將色彩、紋理和形狀等圖像低層特征直接與監(jiān)督學(xué)習(xí)方法結(jié)合的“先對(duì)象再場(chǎng)景”識(shí)別模式。近年來,為克服低層視覺特征與高層語(yǔ)義之間的“語(yǔ)義鴻溝”,避免識(shí)別過程大量的人工標(biāo)注,基于中間層語(yǔ)義特征的場(chǎng)景建模方法得到了廣泛關(guān)注。這類方法的核心在于中間層語(yǔ)義特征的定義、提取和描述。文本分析中的主題模型被成功應(yīng)用于語(yǔ)義場(chǎng)景分類。該模型用視覺詞袋(Bag-of-visual Words,BoW)的方式描述圖像,再用概率潛在語(yǔ)義分析(Probabilistic Latent Semantic Analysis,PLSA)或潛在狄利克雷分布(Latent Dirichlet Allocation,LDA)等主題分析模型提取圖像蘊(yùn)含的主題,從而根據(jù)圖像在主題空間的概率分布實(shí)現(xiàn)語(yǔ)義場(chǎng)景分類。BoW將圖像投影到生成的視覺詞匯本(visual codebook)中,為圖像低維結(jié)構(gòu)化描述、語(yǔ)義分析等提供了新的研究思路,在機(jī)器人導(dǎo)航[1]、Web圖像搜索[2]、語(yǔ)義建模[3,4]、場(chǎng)景分類[5?8]等領(lǐng)域取得了良好的應(yīng)用效果。
制約圖像BoW模型應(yīng)用效果的關(guān)鍵在于如何構(gòu)建高效的視覺詞匯本。Sungho[9],Yang[10]等研究了基于分類信息的視覺詞匯本生成算法;Farquhar等[11]基于最大化后驗(yàn)概率構(gòu)造了面向圖像類的視覺詞匯本;Moosmann等[12]用隨機(jī)森林聚類算法構(gòu)造了具有良好判別力的視覺詞匯本;Yu-gang等[13]評(píng)估了影響視覺詞匯本性能的因素,包括特征檢測(cè)、詞匯本大小、加權(quán)策略等。這些成果從不同方面提出了視覺詞匯本的優(yōu)化,但仍存在以下不足:(1)特征整合仍是在海量數(shù)據(jù)中進(jìn)行,大量不穩(wěn)定和噪聲特征影響了詞匯本的構(gòu)造效率和表征性能;(2)現(xiàn)有的特征整合往往直接在高維空間中進(jìn)行,計(jì)算復(fù)雜度高;(3)視覺詞匯量化過程中,初始代表點(diǎn)往往是隨機(jī)選取,使得算法對(duì)初始值較為敏感,降低了算法的性能和適用價(jià)值。
針對(duì)以上不足,本文根據(jù)視覺詞匯本構(gòu)造的“特征提取、表達(dá)與整合”3個(gè)階段分別提出了優(yōu)化策略:(1)運(yùn)用數(shù)值分析中的條件數(shù) (Condition Number,CN) 理論定量評(píng)估低層特征的穩(wěn)定性,篩選病態(tài)的干擾特征,獲得良態(tài)的魯棒視覺特征;(2)通過分析高維空間中的降維與特征整合的內(nèi)在聯(lián)系,提出了具有聚類功能的自適應(yīng)局部線性嵌入算法,獲得具有聚類結(jié)構(gòu)信息的視覺特征的低維表示;(3)針對(duì)LBG(Linde-Buzo-Gray)詞匯本構(gòu)造方法[14]只能得到局部最優(yōu)和初始類代表點(diǎn)隨機(jī)選取的不足,采用Silhouette指標(biāo)改進(jìn)原目標(biāo)函數(shù),然后,基于前一過程得到低維聚類結(jié)構(gòu)信息,通過類內(nèi)樣本點(diǎn)提供的支持度自適應(yīng)決定初始類中心,從而自適應(yīng)生成視覺詞匯本。最后采用PLSA技術(shù)[6]將本文的視覺詞匯本應(yīng)用于自然場(chǎng)景分類。
2 基于條件數(shù)的視覺特征穩(wěn)定性評(píng)估
在視覺詞匯本生成階段,訓(xùn)練圖像的海量性決定了特征的海量性,同時(shí)初始特征往往受到噪聲、位移、光照等因素影響,包含了大量不穩(wěn)定特征,現(xiàn)有的研究往往基于視覺的方式定性分析它們的可靠性。然而在很多情況下,這種方法無法克服由于噪聲和圖像的病態(tài)帶來的誤差影響。在矩陣論中,矩陣內(nèi)的元素aij往往帶有誤差δij,擾動(dòng)矩陣的存在對(duì)計(jì)算A的特征值產(chǎn)生的影響程度是用條件數(shù)來刻畫的,這種擾動(dòng)正對(duì)應(yīng)了圖像處理中的噪聲影響。因此條件數(shù)為定量分析圖像噪聲的影響程度提供了新途徑。特征x對(duì)于變換H的條件數(shù)CH定義為[15]
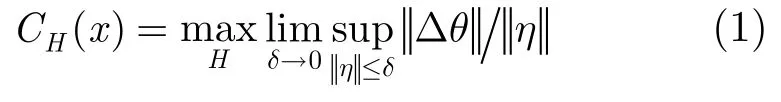
η為圖像的噪聲,Δθ為噪聲所引起的模型變換誤差,||*||表示向量的2-范數(shù)。實(shí)際應(yīng)用中,條件數(shù)可由下式逼近:

A和M分別是N×2和N×N的矩陣,A中的元素由以點(diǎn)x為中心的一個(gè)矩形區(qū)域內(nèi)的所有像素的水平和豎直兩個(gè)方向上的梯度組成。權(quán)重矩陣M是一個(gè)對(duì)角陣,Mii的值對(duì)應(yīng)A中第i行元素在以x為中心的高斯窗口中的加權(quán)系數(shù)。對(duì)任意的M,都有其中CTrans,CRST和CAffine分別表示平移變換、旋轉(zhuǎn)+尺度+平移變換和仿射變換下的條件數(shù)。該式說明,如果圖像特征對(duì)于平移變換模型來說是病態(tài)的,那么它對(duì)RST和仿射變換也是病態(tài)的[15]。基于此性質(zhì),只需采用計(jì)算簡(jiǎn)單的平移變換的條件數(shù)來定量分析特征的穩(wěn)定性,如果特征點(diǎn)的條件數(shù)的下界大于給定閾值,則該點(diǎn)為病態(tài)點(diǎn),予以排除。
通過條件數(shù)對(duì)初始特征提取過程中的各種病態(tài)影響的定量分析,刪除不穩(wěn)定特征,有效地克服因噪聲、圖像變化等因素引起的誤差影響,降低海量數(shù)據(jù)的處理難度,從而提高了后續(xù)視覺詞匯本生成的效率和魯棒性。
3 具有聚類結(jié)構(gòu)信息的低維視覺特征表示
為提高視覺特征的表征性能,往往對(duì)特征設(shè)計(jì)較高維數(shù)的描述子,如128維的SIFT描述子。然而訓(xùn)練樣本的海量性加之特征描述向量的高維性,加劇了算法的計(jì)算負(fù)荷。同時(shí),高維的特征向量中,存在弱相關(guān)、不相關(guān)、冗余的特征分量。有效進(jìn)行維數(shù)約簡(jiǎn),將為后續(xù)視覺特征整合提供簡(jiǎn)潔高效的訓(xùn)練樣本。局部線性嵌入(Locally Linear Embedding, LLE)[16]基于局部線性假設(shè),旨在保持原高維數(shù)據(jù)的局部幾何結(jié)構(gòu)條件下獲得數(shù)據(jù)的低維表示。該算法的特征降維與特征聚類有著內(nèi)在聯(lián)系:基于特征分量不同的表征能力,聚類結(jié)果反映為同類特征在特征分量上具有大致相同的區(qū)分度,不同類特征在特征分量上存在較大差異的區(qū)分度。所以對(duì)聚類后的特征進(jìn)行降維,提取最具有類間區(qū)分度的特征分量,變的更加合理高效;而LLE獲得的低維特征,保留了高維數(shù)據(jù)原有的結(jié)構(gòu)信息,根據(jù)區(qū)分度最好的特征分量能更有效的細(xì)化聚類結(jié)果。
LLE算法對(duì)每個(gè)樣本點(diǎn)都取k個(gè)近鄰點(diǎn)構(gòu)成局部重建區(qū)域,這樣設(shè)定的局部區(qū)域往往不是對(duì)樣本分布的最佳分割。本文提出了聚類與降維統(tǒng)一框架下的近鄰參數(shù)自適應(yīng)選擇LLE算法(Adaptive-LLE,ALLE),新的算法旨在根據(jù)數(shù)據(jù)的真實(shí)分布,為每個(gè)樣本點(diǎn)設(shè)計(jì)最佳的近鄰搜索空間,自適應(yīng)選取鄰近點(diǎn)及其個(gè)數(shù)k,從而準(zhǔn)確構(gòu)建權(quán)值重建矩陣。與Jing等[17]提出的鄰域收縮和鄰域膨脹的兩階段自適應(yīng)局部線性嵌入相比,本文算法簡(jiǎn)單易行,具有良好的聚類功能,更適合于視覺詞匯本的應(yīng)用。
本文ALLE算法首先用仿射傳播聚類(Affinity Propagation Clustering,APC)[18]獲得高維數(shù)據(jù)的聚類結(jié)構(gòu)。由N個(gè)樣本特征構(gòu)成的N×N 的相似度矩陣為算法開始時(shí)將所有的特征都視為潛在的聚類中心,其作為類代表點(diǎn)的可能性由偏向參數(shù)p=s(k, k)度量,可將所有樣本點(diǎn)的p設(shè)置為相似度的均值。基于消息傳遞的思想,算法按式(3)-式(5)不斷在數(shù)據(jù)間交換聚類信息:

為避免迭代中的數(shù)值振蕩,引入阻尼因子λ, λ∈[0,1),實(shí)驗(yàn)中設(shè)置為0.5。設(shè)當(dāng)前迭代次數(shù)為t,r(i, k)和a(i, k)的更新結(jié)果由當(dāng)前迭代值和上步迭代值加權(quán)得到:特征k搜集的證據(jù)越強(qiáng)(即r(i, k)與a(i, k)越大),其作為最終聚類中心的可能性就越大。將各特征點(diǎn)xi按xk分配給最近的類中心xk所屬的類,獲得m個(gè)簇。
將聚類結(jié)果以及初始相似度矩陣作為L(zhǎng)LE降維的輸入,對(duì)每個(gè)特征僅在其所在的類中學(xué)習(xí)一個(gè)局部重建權(quán)值矩陣,產(chǎn)生最適合的重建矩陣。新算法在高維空間中的誤差函數(shù)重新定義為


損失矩陣L=(I?W)Τ(I?W)是一個(gè)N×N的對(duì)稱矩陣,要使損失函數(shù)值達(dá)到最小, 則取Y為L(zhǎng)的最小d個(gè)非零特征值所對(duì)應(yīng)的特征向量,通常將最小的第2~d+1個(gè)特征值所對(duì)應(yīng)的特征向量作為尋求的低維嵌入。
通過聚類和降維的統(tǒng)一計(jì)算過程,得到了具有聚類結(jié)構(gòu)信息的低維視覺特征表示,這些聚類中心可視為后續(xù)視覺詞匯本量化的初始詞匯。
4 視覺詞匯本的自適應(yīng)生成算法ALBG
在特征整合階段,流行的LBG算法[14]首先從訓(xùn)練樣本X={xn:n=1,2,…,N}中隨機(jī)選取M個(gè)初始點(diǎn),產(chǎn)生初始詞匯本V={vm:m=1,2,…,M},M?N,然后將訓(xùn)練樣本分配到最近的視覺詞匯vm代表的第m個(gè)類中,?xn∈X:計(jì)算所有類的平均離差D=J是每個(gè)類的特征個(gè)數(shù)。迭代達(dá)到收斂條件則計(jì)算每個(gè)類的中心作為最終視覺詞匯。LBG算法產(chǎn)生詞匯本具有兩個(gè)固有局限:(1)局部最優(yōu):采用近鄰準(zhǔn)則搜索聚類結(jié)構(gòu)和以類內(nèi)的平均離差作為最優(yōu)收斂準(zhǔn)則,決定了LBG算法只能得到局部最優(yōu);(2)對(duì)初始類代表點(diǎn)選取敏感:LBG算法需要隨機(jī)選取初始聚類中心作為初始詞匯本,迭代速度較慢,難以得到高質(zhì)量的詞匯本。
針對(duì)以上不足,本文提出自適應(yīng)選擇初始中心的視覺詞匯本生成算法(Adaptive—LBG,ALBG)。首先采用Sil指標(biāo)作為迭代目標(biāo)函數(shù),以達(dá)到全局最優(yōu)的聚類效果,平均Sil指標(biāo)越大表示聚類質(zhì)量越好。用a(x)表示類Ci,(i=1,2,…,M)中的樣本x與類內(nèi)其他樣本的平均不相似度;d(x, Cj)表示x到另一個(gè)類Cj的所有樣本的平均相似度,記b(x)=min{d(x, Cj)},x∈Ci,j=1,2…M, j≠i ,則:Sil(x)=(b(x)?a(x))/max{a(x), b(x)}。
然后利用ALLE得到的信息量r和a,定義特征xi的鄰域支持度為:NS(i)=r(i, i)+a(i, i),其值越大說明該點(diǎn)作為類代表點(diǎn)的適合程度越大。因此利用降維過程得到的鄰域支持度,自適應(yīng)選取M個(gè)支持度最大的特征作為初始聚類中心,通過迭代得到平均Sil值最優(yōu)的聚類結(jié)構(gòu),計(jì)算每類的中心生成最終詞匯本V。出現(xiàn)頻率過高和過低的單詞往往具有較低的信息量,可定義在樣本集中出現(xiàn)頻率高于和低于設(shè)定閾值的視覺詞匯為停止詞,也可將一定百分比的高頻和低頻詞匯定義為停止詞,從視覺詞匯本中刪除,進(jìn)一步降低視覺詞匯本維數(shù)。本文詞匯本生成算法ALBG流程如圖1所示。
5 自然場(chǎng)景分類實(shí)驗(yàn)與分析
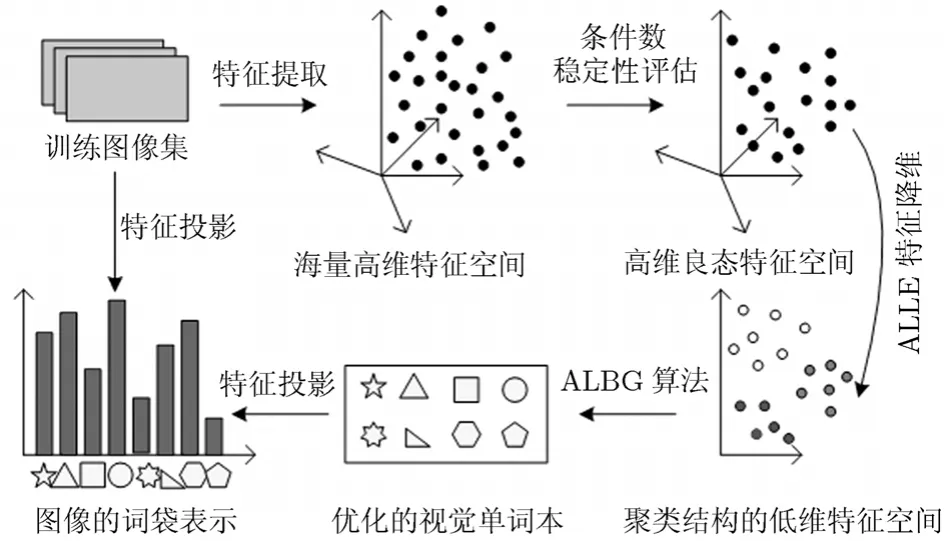
圖1 本文詞匯本生成算法ALBG流程圖
為驗(yàn)證本文算法構(gòu)造視覺詞匯本的高效性,在13類場(chǎng)景圖像庫(kù)[15]進(jìn)行分類實(shí)驗(yàn)。該圖像庫(kù)包括13類自然場(chǎng)景的3759張圖片:C1:Highway,C2:Inside City,C3:Tall Building,C4:Street,C5:Suburb Residence,C6:Forest,C7:Coast,C8:Mountain,C9:Open Country,C10:Bedroom,C11:Kitchen,C12:Living room,C13:Office。從每類場(chǎng)景圖像中隨機(jī)選擇100幅圖像作為訓(xùn)練集,剩余圖像作為測(cè)試集。運(yùn)用本文算法在訓(xùn)練圖像集上構(gòu)建視覺詞匯本,并訓(xùn)練每個(gè)場(chǎng)景類的PLSA模型,最后用SVM分類器進(jìn)行場(chǎng)景分類。
表1是用DOG算子檢測(cè)出的每類場(chǎng)景圖的平均初始特征點(diǎn)個(gè)數(shù),與本文條件數(shù)篩選的穩(wěn)定特征個(gè)數(shù)的對(duì)比。每類場(chǎng)景的平均特征個(gè)數(shù)等于在該類所有圖像上提取的特征點(diǎn)個(gè)數(shù)總和,除以該類包含的圖像數(shù)。通過本文條件數(shù)評(píng)估,剔除了大量病態(tài)不穩(wěn)定特征,整個(gè)場(chǎng)景圖像的平均特征點(diǎn)從1277個(gè)減少到539個(gè),降低了初始特征的海量性,提高了樣本特征的噪聲魯棒性和穩(wěn)定性。

表1 條件數(shù)篩選后的平均穩(wěn)定特征個(gè)數(shù)比較
聚類表現(xiàn)是評(píng)估降維算法性能的一個(gè)重要準(zhǔn)則。為驗(yàn)證本文ALLE算法的自適應(yīng)性和降維效果,本文在ORL標(biāo)準(zhǔn)人臉庫(kù)上進(jìn)行降維實(shí)驗(yàn),用Sil指標(biāo)、類別數(shù)和正確聚類率量化評(píng)價(jià)聚類結(jié)果。從ORL人臉庫(kù)中隨機(jī)選取10個(gè)人,每個(gè)人取10張圖像,首先對(duì)112×92的高維圖像用不同參數(shù)下的LLE算法和本文的ALLE算法降維,然后進(jìn)行聚類。從表2可以看出:原始LLE算法的降維效果受制于近鄰參數(shù)k的選取,而本文的ALLE算法實(shí)現(xiàn)了參數(shù)的自適應(yīng)選取,能夠得到最優(yōu)的降維效果,即最高的Sil值0.980和準(zhǔn)確的聚類數(shù)10,以及最高正確聚類率80.83%。雖然用原始LLE算法在k=15時(shí)能夠得到最高的Sil值0.989,但是此時(shí)獲得錯(cuò)誤的聚類數(shù)7。

表2 不同算法在ORL人臉庫(kù)上的降維效果對(duì)比
表3是將本文的視覺詞匯本優(yōu)化算法與原始算法在運(yùn)行時(shí)間和應(yīng)用效果方面的對(duì)比。在特征提取階段,本文采用條件數(shù)篩選了大量病態(tài)特征,在特征降維階段,本文的ALLE同時(shí)考慮了特征空間的聚類結(jié)構(gòu)信息,得到了更加準(zhǔn)確的低維特征描述,在視覺詞匯的量化階段,本文ALBG算法不依賴于初始值的隨機(jī)選取,從而提高了單詞本構(gòu)造的效率(124813 s vs. 180627 s),提高了視覺詞匯本對(duì)分類圖像的表征性能,在13場(chǎng)景類識(shí)別中獲得了更高的分類準(zhǔn)確率(73.5% vs. 69.3%)。

表3 本文算法與原始算法的實(shí)現(xiàn)效率和分類性能對(duì)比
表4給出了本文方法在13-場(chǎng)景類上的分類混淆矩陣。混淆矩陣的第i行j列表示第i類圖像被分為第j類圖像的比例,對(duì)角線上元素的值代表了每類場(chǎng)景的分類準(zhǔn)確率。圖2(a)是可視化的混淆矩陣,不同的灰度代表不同的分類率,灰度值越大代表的分類率越高。圖2(b)圖是對(duì)13類場(chǎng)景的平均分類率的直方圖統(tǒng)計(jì),整體場(chǎng)景分類的平均準(zhǔn)確率73.4615%即是各類場(chǎng)景的分類率的平均值。

圖2 可視化混淆矩陣及場(chǎng)景平均分類率的直方圖統(tǒng)計(jì)

表4 13-類場(chǎng)景分類的混淆矩陣

表5 本文方法與其他方法的13類場(chǎng)景分類比較
表5比較了本文方法與文獻(xiàn)[5-8]的4種代表性方法在13類場(chǎng)景圖像上的特征維數(shù)、詞匯本大小、潛在主題個(gè)數(shù)和平均分類率。實(shí)驗(yàn)中對(duì)整個(gè)圖像庫(kù)進(jìn)行10次隨機(jī)劃分,生成相應(yīng)的訓(xùn)練集和測(cè)試集圖像,將10次劃分得到的分類率的均值作為最終的平均分類準(zhǔn)確率。綜合考慮建模的準(zhǔn)確性和實(shí)現(xiàn)的效率,本文通過實(shí)驗(yàn)將視覺詞匯本的大小取為500,潛在主題數(shù)目為40,從而訓(xùn)練PLSA模型,最后用SVM分類器進(jìn)行分類識(shí)別,得到高于Fei-Fei et al.[7]的分類準(zhǔn)確率(73.5% vs. 65.2%),同時(shí)在最低的特征維數(shù)64-dim下,本文方法的分類率與其他方法接近,從而驗(yàn)證了本文算法構(gòu)造的視覺詞匯本的有效性。
6 結(jié)束語(yǔ)
已有研究結(jié)果表明Bag-of-Words是一種有效的圖像表示方法,而視覺詞匯本的構(gòu)造、優(yōu)化成為這一問題的關(guān)鍵環(huán)節(jié)。本文從特征穩(wěn)定性篩選、特征低維描述、詞匯本自適應(yīng)生成方面提出了相應(yīng)的優(yōu)化策略。改進(jìn)的視覺詞匯本生成算法具有聚類和降維的統(tǒng)一計(jì)算功能、良好的魯棒性和自適應(yīng)優(yōu)化等特性,通過充分的對(duì)比實(shí)驗(yàn)驗(yàn)證了本文算法的高效性,并在13-類場(chǎng)景圖像庫(kù)上取得了73.46%的平均分類率。在研究中發(fā)現(xiàn),視覺詞匯本的大小,以及潛在主題的個(gè)數(shù)對(duì)分類識(shí)別會(huì)產(chǎn)生一定影響,進(jìn)一步分析這兩個(gè)因素與分類結(jié)果間的數(shù)值關(guān)系,建立一種參數(shù)的自適應(yīng)優(yōu)化選擇算法,將是提高視覺詞匯本性能的又一研究方面。
[1] Cummins M and Newman P. FAB-MAP: Probabilistic localization and mapping in the space of appearance[J]. The International Journal of Robotics Research, 2008, 27(6):647-665.
[2] Zhong W, Qifa K, Michael I, and Jian S. Bundling features for large-scale partial-duplicate web image search[C]. IEEE Conference on Computer Vision and Pattern Recognition,Miami, 2009: 25-32.
[3] 李志欣, 施智平, 李志清, 史忠植. 圖像檢索中語(yǔ)義映射方法綜述[J]. 計(jì)算機(jī)輔助設(shè)計(jì)與圖形學(xué)學(xué)報(bào), 2008, 20(8):1085-1096.Li Zhi-xin, Shi Zhi-ping, Li Zhi-qing, and Shi Zhong-zhi. A survey of semantic mapping in image retrieval[J]. Journal of Computer Aided Design & Computer Graphics, 2008, 20(8):1085-1096.
[4] 石躍祥, 朱東輝, 蔡自興, Benhabib B. 圖像語(yǔ)義特征的抽取方法及其應(yīng)用[J]. 計(jì)算機(jī)工程, 2007, 33(19): 177-179.Shi Yue-xiang, Zhu Dong-hui, Cai Zi-xing, and Benhabib B.Extraction of image semantic attributes and its application[J].Computer Engineering, 2007, 33(19): 177-179.
[5] Rasiwasia N and Vasconcelos N. Scene classification with low-dimensional semantic spaces and weak supervision[C].IEEE Conference on Computer Vision and Pattern Recognition, Alaska, 2008: 1-6.
[6] Bosch A, Zisserman A, and Munoz X. Scene classification via pLSA [C]. European Conference on Computer Vision,Austria, 2006: 517-530.
[7] Li Fei-fei and Perona P. A Bayesian hierarchical model for learning natural scene categories[C]. IEEE Conference on Computer Vision and Pattern Recognition, San Diego, 2005:524-531.
[8] Lazebnik S, Schmid C, and Ponce J. Beyond bags of features:Spatial pyramid matching for recognizing natural scene categories[C]. IEEE Conference on Computer Vision and Pattern Recognition, New York, 2006, 2: 2169-2178.
[9] Kim S and Kweon I S. Simultaneous classification and visual word selection using entropy-based minimum description length[C]. IEEE International Conference of Pattern Recognition, Hong Kong, 2006: 650-653.
[10] Liu Yang, Rong Jin, Sukthankar R, and Jurie F. Unifying discriminative visual codebook generation with classifier training for object category recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, Alaska, 2008:1-8.
[11] Farquhar J, Szedmak S, Meng H, and Taylor J S. Improving bags-of-keypoints image categorization[R]. Tech report,University of Southampton, 2005.
[12] Moosmann F, Triggs B, and Jurie F. Fast discriminative visual codebooks using randomized clustering forests[C]. In Neural Information Processing Systems, Vancouver, 2006:985-992.
[13] Jiang Yu-gang, Chong-Wah N, and Yang Jun. Towards optimal bag-of-features for object categorization and semantic video retrieval[C]. ACM International Conference on Image and Video Retrieval, New York, 2007: 494-501.
[14] Linde Y, Buzo A, and Gray R M. An algorithm for vector quantizer design[J]. IEEE Transactions on Communications,1980, 28(1): 84-95.
[15] Kenney C, Manjunath B S, and Zuliani M. A condition number for point matching with application to registration and post-registration error estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(11):1437-1454.
[16] 馬瑞,王家廞,宋亦旭. 基于局部線性嵌入(LLE)非線性降維的多流形學(xué)習(xí)[J]. 清華大學(xué)學(xué)報(bào)(自然科學(xué)版), 2008, 48(4):582-585.Ma Rui, Wang Jia-xin, and Song Yi-xu. Multi-manifold learning using locally linear embedding (LLE) nonlinear dimensionality reduction[J]. Journal of Tsinghua University(Science and Technology), 2008, 48(4): 582-585.
[17] Wang Jing, Zhang Zhen-yue, and Zha Hong-yuan. Adaptive manifold learning[C]. Advances in Neural Information Processing Systems, Cambridge, 2005: 1473-1480.
[18] Frey B J and Dueck D. Clustering by passing messages between data points[J]. Science, 2007, 315: 972-976.
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
